WWW2022 | Recommendation Unlearning

论文:https://arxiv.org/abs/2201.06820
代码:https://github.com/chenchongthu/Recommendation-Unlearning
推荐系统通过从收集到的个人数据中学习用户的个人偏好以此来提供个性化的推荐服务。然而,在许多情况下,推荐系统也需要忘记一些训练数据。从隐私的角度来看,用户希望有一种工具可以从训练过的模型中消除他们敏感数据的影响,比如用户浏览过一些商品之后不想让模型记住这些数据。从效用的角度来看,有些脏数据需要进行剔除,系统需要忘记这些数据来提高推荐。因此将机器遗忘学习引入推荐系统很有必要。经典的机器遗忘学习模型是发表在安全领域顶级会议S&P2021上的SISA框架[1],该框架的示意图如下图所示。通过将整体数据集随机划分为 份,然后在每份子数据集上训练一个模型 ,然后将多个子数据集训练出的模型进行聚合来得到最终的模型预测结果。
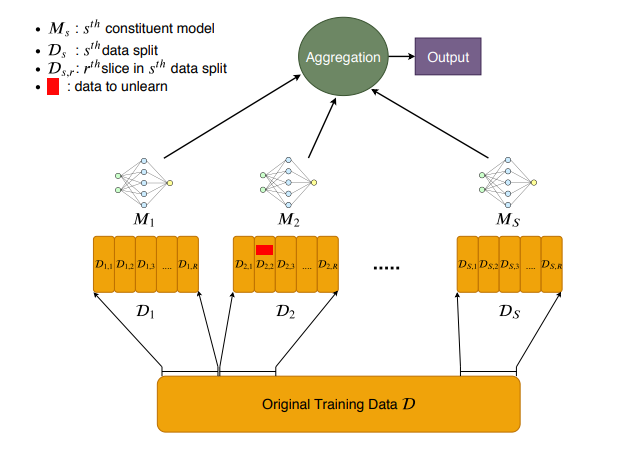
猛地一看,其框架与当前流行的联邦学习架构类似[一文梳理联邦学习推荐系统研究进展],其实还是有很大差别的。SISA框架虽然将数据划分为多个子数据集,但其训练过程仍然是在集中存储的服务器上所进行的,而联邦学习的子数据集保存在个人的终端设备中,因此需要在服务器和终端之间交互梯度而非原始数据进而更严格的保护用户的隐私。
本文所提出的RecEraser模型是在SISA框架的基础上的改进,将其应用到了推荐领域,并提出了3种划分子数据集的方法用来保护推荐数据集中的协同信息,另外提出了一种基于注意力机制的聚合机制,以此来更好的融合子模型,最后在多个数据集上验证了所提方法相比于经典的遗忘学习方法的有效性。
方法部分
本文所使用的数学符号如下。

本文所提出的RecEraser框架如下图所示,可以看出依然沿用SISA的基础架构,其在数据划分方式上进行了3种改进以保留协同信息,分别是基于用户的平衡划分方法(UBP)、基于物品的平衡划分方法(IBP)和基于交互的平衡划分方法(InBP),随后上层模块增加了基于注意力的自适应聚合模型,以此来动态的学习各个模块的参数。
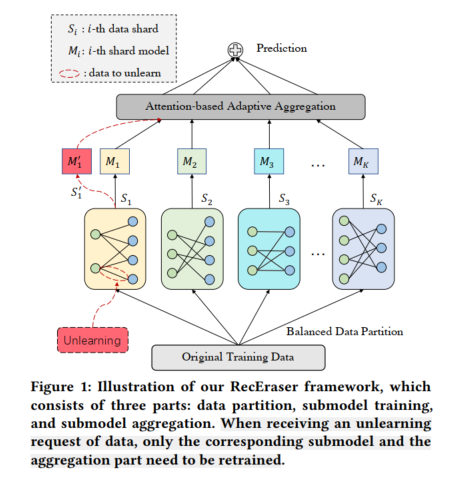
其中,基于用户的平衡划分方法(UBP)的流程图如下,首先随机选择 个锚点用户当做每个子数据集的中心(Line 1),然后分别计算每个锚点用户和其他用户的欧式距离(Line 3-Line 6),然后将每个用户根据距离来进行划分到各自的子数据集合中(Line 10- Line 14),随后更新锚点用户。值得注意的是,这里用来计算距离的用户向量是利用WMF模型预训练好的。基于物品的平衡划分方法IBP与UBP类似,在此不再赘述。

基于交互的平衡划分方法(InBP)与UBP也几乎类似,只不过在此是将交互数据进行划分,而不是将用户进行划分。

在全部数据划分成多个子数据集后,在每个子数据集 上训练对应的子模型 (包含用户隐因子矩阵 和物品隐因子矩阵 )。然后通过赋予每个子模型特定的权重 和 来加权聚合子模型的结果。
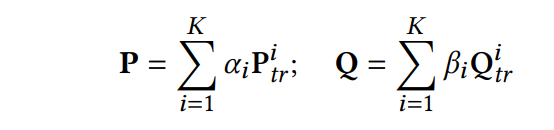
其中,权重参数 和 是通过注意力机制来进行动态学习的。随后权重系数通过softmax进行归一化。
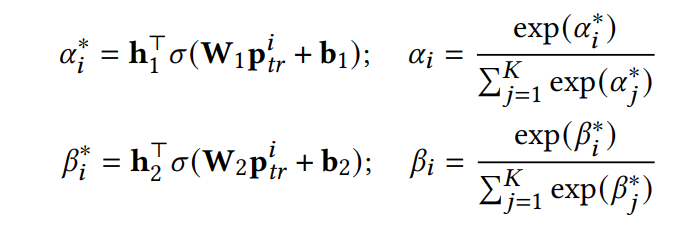
值得注意的是,权重参数通过下方的损失函数来进行训练,而模型的参数 和 在注意力训练阶段是固定不变的。
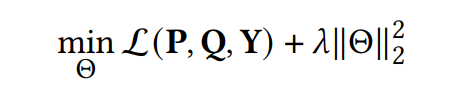
整个交互数据数据 用于训练,也可以要求部分数据进行撤回(删除)。因此,该聚合方法在收到数据的撤回请求时需要重新训练。幸运的是,本文提出的聚合方法只需要几个epoch(约10个)就可以学习到最优的注意力分数,与其他聚合方法相比,可以有效地提高推荐性能。RecEraser模型的训练过程包括两个阶段,第一阶段是利用各自的数据训练各自的子模型,第二阶段是在保持子模型参数不变的情况下训练注意力模型。
实验部分
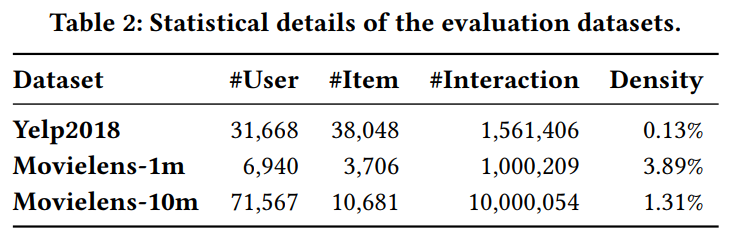
本文利用Yelp2018、Movielens-1M和Movielens-10M数据集进行验证模型的有效性。
该论文利用BPR、WMF和LightGCN作为基本框架来测试该想法的性能,随后对比了三种模型遗忘方法,分别是Retrain、SISA和GraphEraser模型。Retrain方法是一种最简单的方法,即如果有数据撤回,则重新训练整个数据集;SISA方法是经典的机器遗忘学习模型,其随机的对数据集进行划分,并利用固定的参数来聚合子模型的结果;GraphEraser模型是一种适用于图数据的模型遗忘方法。
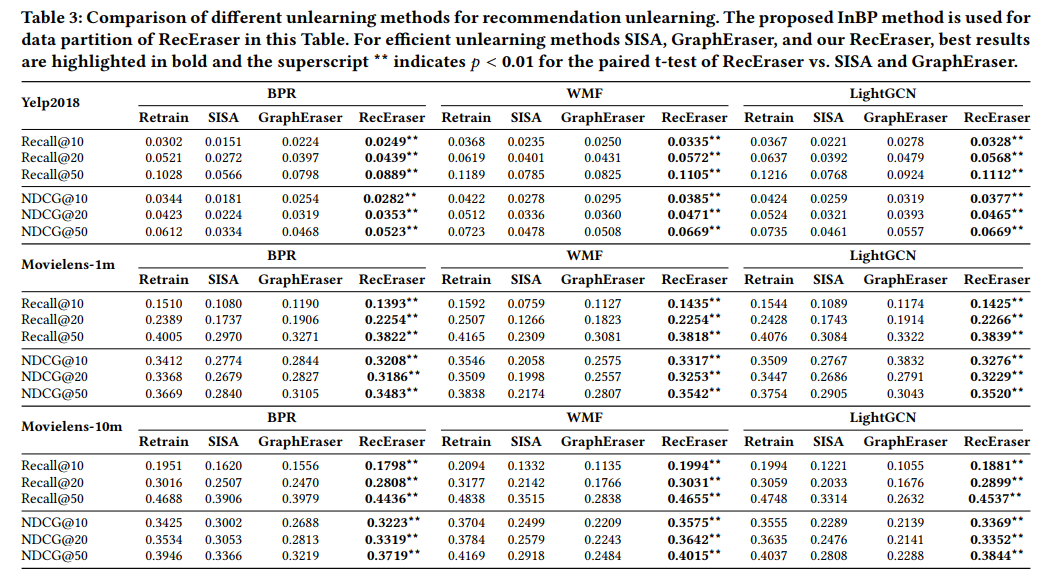
通过下图的实验表明,所提出的RecEraser模型在多种数据集(Yelp、Movielens)、以及多种评测指标(Recall和NDCG)上的性能优于多种基线方法(Retrain、SISA和GraphEraser)。
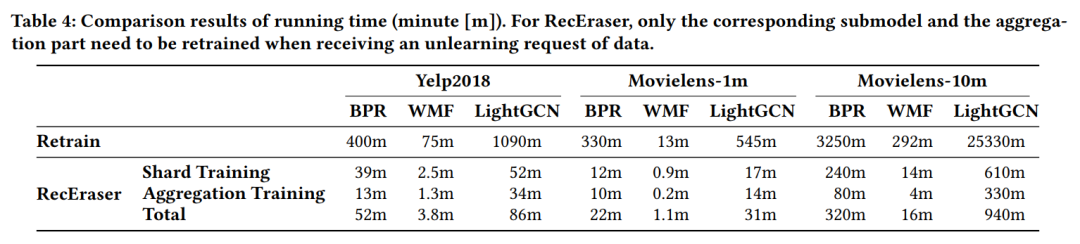
下图展示了RecEraser模型在训练时间上要显著少于Retrain基线方法。
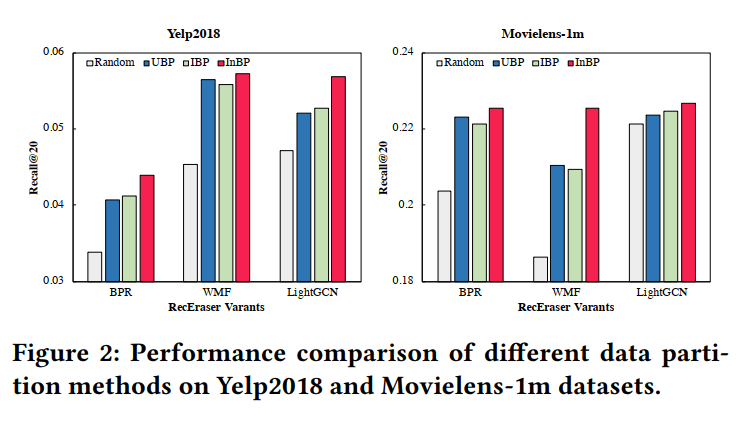
通过实验发现,在数据划分方式上来看,基于交互的平衡划分方法(InBP)要优于基于用户和物品的划分方法(UBP和IBP)。
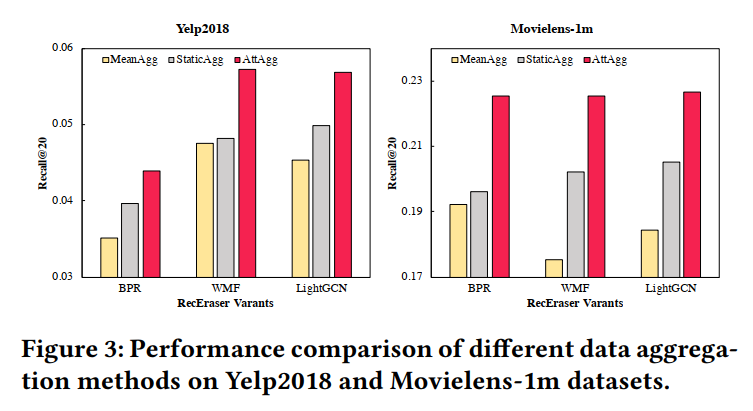
本文还分析了模型聚合机制的影响,通过实验发现,其所提出的注意力机制的性能要优于平均聚合和固定参数聚合的方式。
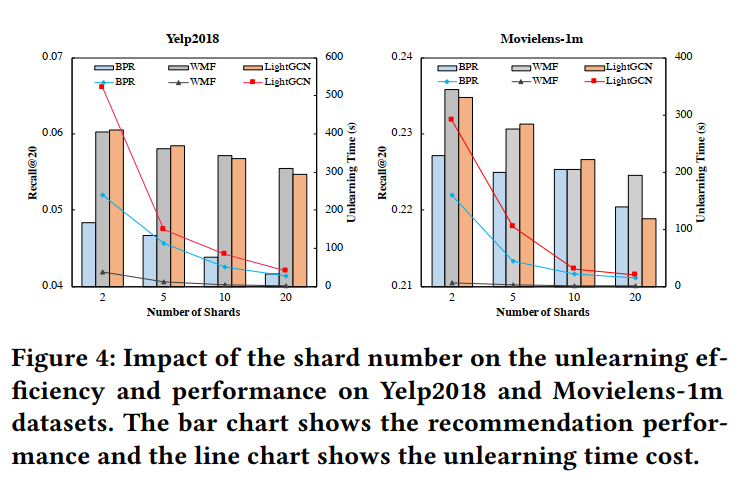
另外,通过分析所划分的子数据集数目,可以看出随着数目的增多,模型的推荐效果逐渐下降,模型的训练时间逐渐缩短。
[1] Machine Unlearning. https://arxiv.org/pdf/1912.03817.pdf
欢迎干货投稿 \ 论文宣传 \ 合作交流
推荐阅读
由于公众号试行乱序推送,您可能不再准时收到机器学习与推荐算法的推送。为了第一时间收到本号的干货内容, 请将本号设为星标,以及常点文末右下角的“在看”。
由于公众号试行乱序推送,您可能不再准时收到机器学习与推荐算法的推送。为了第一时间收到本号的干货内容, 请将本号设为星标,以及常点文末右下角的“在看”。


