ACL 2020 | 基于多级排序学习的层次化实体标注

©PaperWeekly 原创 · 作者|龚俊民
学校|新南威尔士大学硕士生
研究方向|NLP、可解释学习

论文标题:Hierarchical Entity Typing via Multi-level Learning to Rank
论文来源:ACL 2020
论文链接:https://arxiv.org/abs/2004.02286


引言
-
在引入统一阅读理解 MRC 框架之前,NER 通常是序列标注任务。它需要模型从一段文本序列中找出实体的边界和实体的类型,以及非实体的边界。序列标注任务搜索空间很大,限制了实体的类别数量通常不会很多。 FET 做的是有层级的多标签分类任务。它的实体边界通常是已经给好了,需要从远程监督的候选标签中找出正确的、符合上下文语境的实体类型集合。它不关心给定上下文是否包含了别的实体。FET 类别有上下层级。比如位置这个一级类别下有行政区、建筑类等等,行政区二级类别下又可以分国家、省份和城市等等。子类别确定了父类别,而父类别又限定了其可能候选的子类别。
直觉上看,类别数量更少的粗粒度分类比类别更多的细粒度分类更容易。这种展平的分类方式会增大模型要预测的类别数量。还需要依赖额外的技术手段来解决类别间不独立问题,比如 AFET [1],CLSC [2]。

相关工作
FET 过往研究主要专注在以下两个方面:
1. 更好的 mention 表征:从最开始的人工二元特征 [3,4],到分布式表征 [5],再到预训练好的词向量,如 LSTMs [1], CNN [6],和 Attention [7],到后来的预训练语言模型,如 ELMo [8,9] 。本论文用的是 ELMo 的表征方法。
2. 层级标签处理:此前大部分研究都是把标注问题看成是没有用层级结构的多标签分类问题,但有部分研究除外。
AFET [1] 提出了一种适应性的排序学习方法 来让相似的类别具有更小的 margins。NFETC [10] 提出了一种层级损失来给违背层级结构的输出惩罚。[11] 提出了用下级标签的关系来约束标签特征空间的嵌入。HYENA [12] 提出了在类型层级中为某父类别下的子类别排序方法,但它不支持神经网络端对端训练。本论文的从粗到细的端到端的解码方式能严格地保证输出不违背层级特性,从而得到了更好的表现。
针对细粒度实体标注任务,研究者们提出了几种不同的规范化描述方式。比如,类别并非层级构建的 Ultra-fine Entity Typing [13],类别标签是从海量语料中抽取出的短语。也有基于知识图谱中的实体关系构建类别标签体系的 [14],和用实体链接来增强的 [15]。

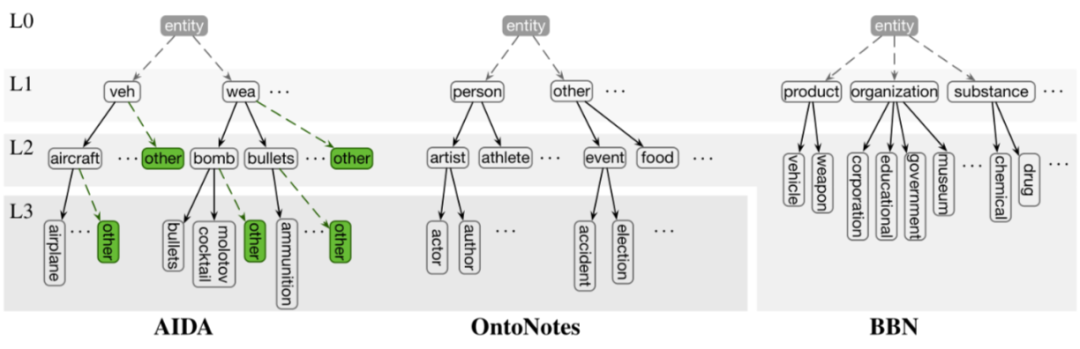
▲ 不同数据集下的层级类型树,L1,L3 分别表示第一级类别和第三级类别
我们把候选实体只能被分类为一种细粒度类别的情景称作单路径标注。这是因为从根节点到叶节点只有一条路径可走,比如 AIDA 数据集。我们把能被分类为多种类别的情景称作多路径标注,因为从根节点到多个叶节点有多条路径,比如 BBN 数据集。
在 FIGER 中,存在一级类别作为叶节点没有往下继续分的情况。但在 AIDA 数据集,又存在对该一级类别下使用特殊叶节点处理的情况,比如 /per/police/<unspecified>。这种类型路径存在两种可能解释:
-
Exclusive 互斥的: 属于类别 ,但 不是 的任何现有子类别 中的一个。比如 -
Underfined 为定义的: 属于类别 ,但它是不是 的某个子类是未知的。
比如“爱德华大夫”是医生人名,在原数据集中被标注为 /person,这是因为人名下面只有运动员、政客、娱乐明星等子类。这里“爱德华大夫”标签会被修改成 /person/other。对于未定义的情景,我们则不修改该样本在数据集中的标签。这样分开处理对结果会有显著影响。

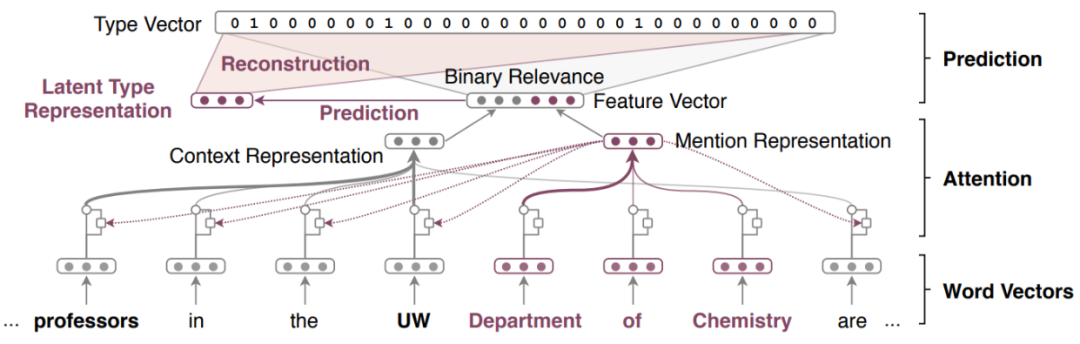
▲ 论文 [9] 中的模型架构和表征方法
Mention 的表示用的是论文 [9] 中的 ELMo 编码方法。过往研究的做法是直接把 mention 的词向量相加取平均,而忽略了 mention 中不同词对整个标注结果存在不同的影响权重。
比方说上图中 “Department of Chemistry” 为其标注为组织机构类别,起作用的词是 “Department”。我们希望模型针对这类有信息的词做更多的侧重。因此 mention 的表征应该是用不同词嵌入基于注意力权重的加权平均。

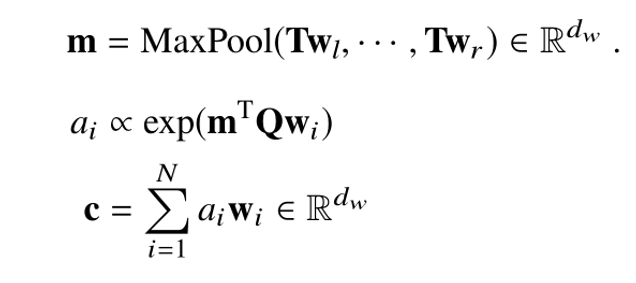
注明:这里倾向于用 ELMo 而不是 BERT 的原因在用 ELMo 表现更好。ELMo 用到了丰富的字符级嵌入信息。这种低层嵌入对 FET 任务很有用。如果是涉及高级语义特征的任务,比如机器阅读理解任务,BERT 会更合适。
4.2 Type Scorer
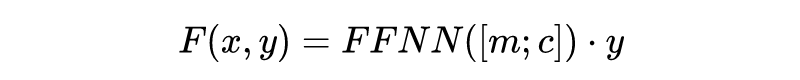
我们引入一个自创的允许多标签多层级分类的排序学习损失。首先,我们计算每个类别的 hinge loss 来把正例类别排在负例类别前面。
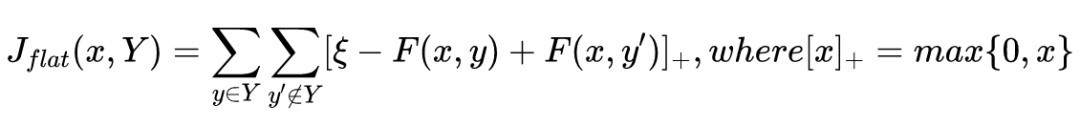
但这种方法考虑的是平展开的所有类别,而不是层次化的类别结构——所有类别被给予相同的对待而没有利用它们在类型树中的层次关系。直觉上看,粗粒度类别(更上级的类别)会比细粒度类别(更下级的类别)更容易确认。
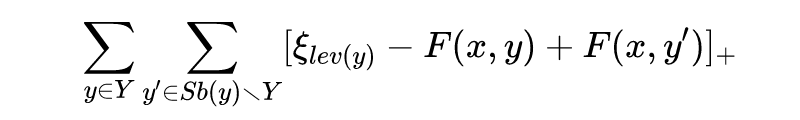
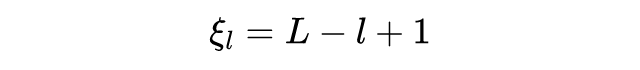
我们要如何设置正例类别相对于实体表征的相关性大于负例样本的阈值呢?我们可以像论文 [9] 那样,把阈值设置为 0 便可。这样多标签分类问题就成了一系列二分类问题。
或者,我们像论文 [16] 中那样,调出一个能根据不同类型调整适应的动态阈值。这里我们提出一个简单的解决方案。
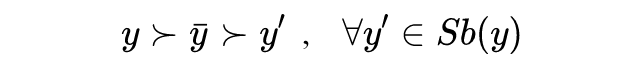
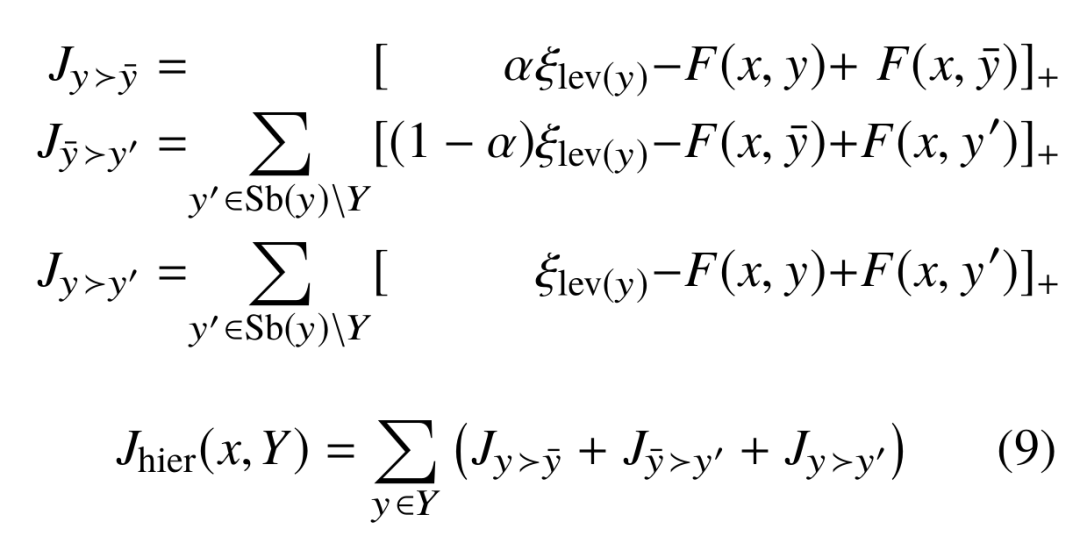

4.5 Subtyping Relation Constraint
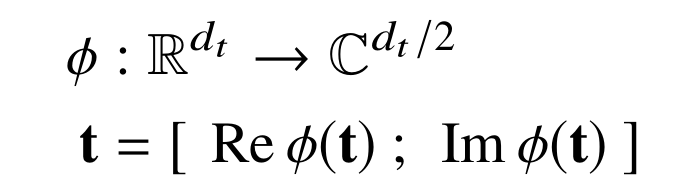
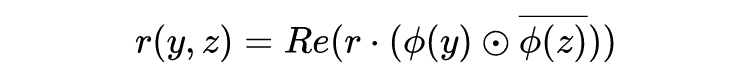
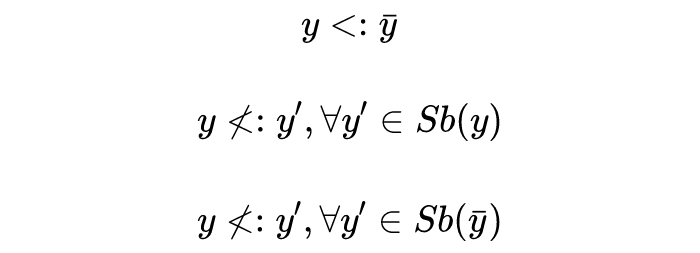
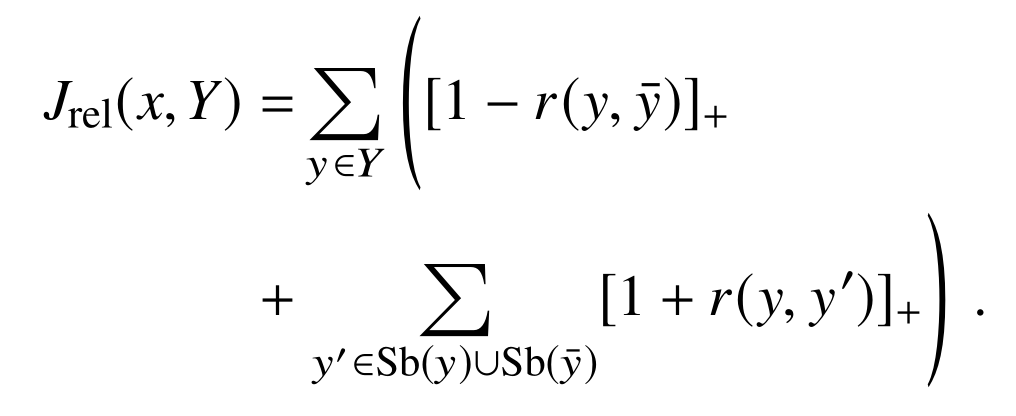
4.6 Training and Validation
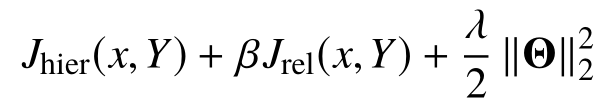

Experiments
-
strict accuracy (Acc): 全部标签分类正确样本占所有样本比。 -
macro (MaF): 计算每个类别的准召,得到各自 ,再求平均。 -
micro (MiF): 不区分类别,直接用总样本的准召计算 。
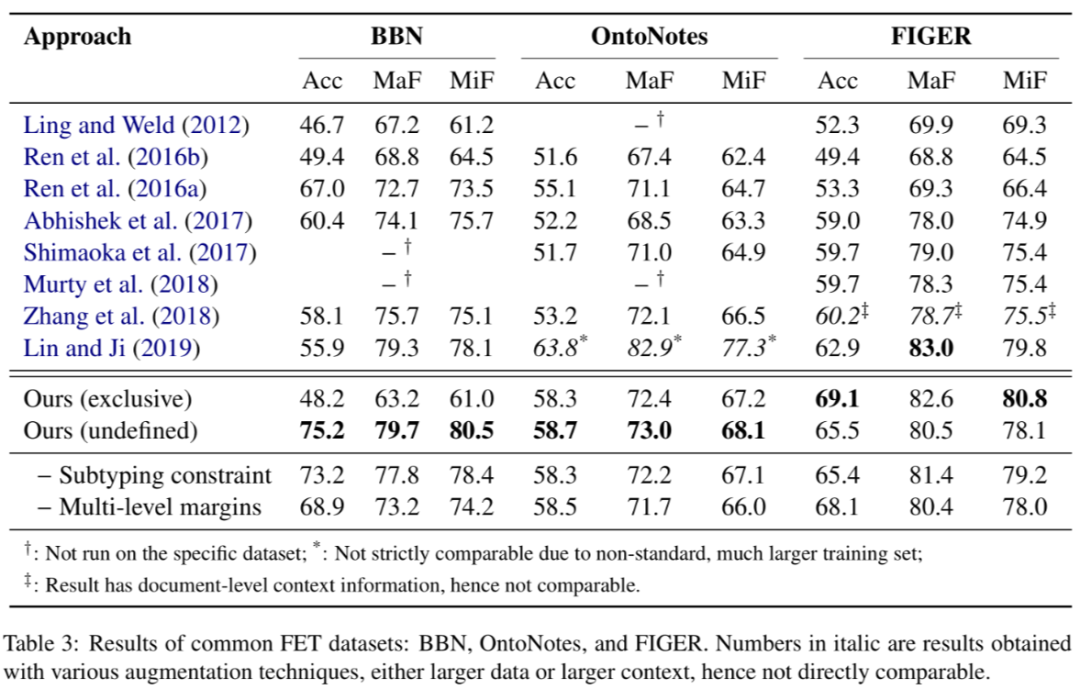
5.5 Results and Discussions
我们可以用零样本实体标注去处理这类问题。做法是用类型的名字和其描述去初始化类型嵌入。这类问题可以放在以后解决。
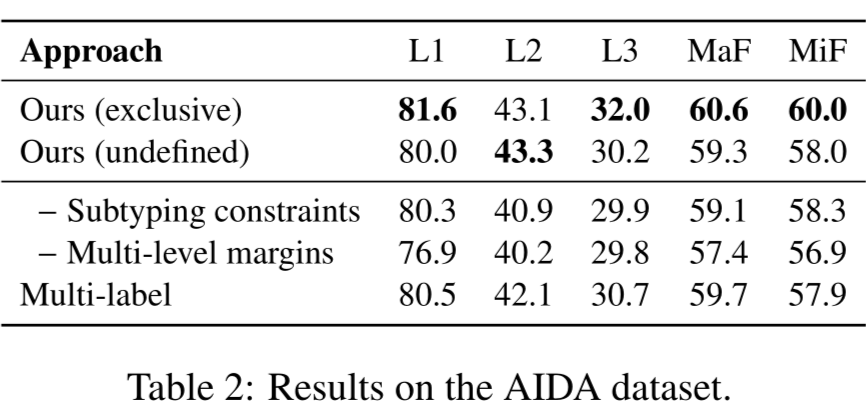
在 BBN,OntoNotes,和 FIGER 数据集上都显著好于去年的 SOTA。以上下浮动 0.5 个百分点为基准。实验表明,部分路径标签问题,用未定义的方式处理在 BBN 和 OntoNotes 数据集上都显著好于用互斥的方式去处理。
这个问题来源于数据标注阶段,取决于标注员如何理解互斥和未定义这两种类别。未来也是一个值得探究的方向。
消融实验表明,加入层次化的排序学习或类型关系约束在不同数据集上都有不同程度的提升。其中,层次化排序学习的加入带来的提升更显著。
错误分析集中在三个方面:
1. 对某些类型混淆。比如 /gpe/city 与 /location/region 混淆。这类错误是类型本身相似导致的,一般是可以容忍的。
2. 未完整的类型。比如 “Immigration and Customs Enforcement” 只标 /government agency ,却漏掉了标 /organization。这个跟数据集的分类体系构建有关。可以在类别体系构建上优化。
3. 只专注于部分 mention。“... suggested they were the work of Russian special forces assassins out to blacken the image of Kievs pro-Western authorities” 实例中,模型基于 “Russian special forces” 输出了 /org/government,但正确的标签是 /per/militarypersonnel,模型忽略了 “assassins” 这部分。这个问题与 mention 表征有关。日后引入 type-aware 类型表征或许能解决这类问题。

好的 idea 的产生来自于看待问题的角度。从新的视角将模型要学的任务规范化、简化,往往能得到新奇的效果。但思考如何实现它却是一个工程活。序列标注问题本质是一个结构化学习。
其难点在,它要为序列解码,搜索空间很大。为一个东西分十几个类别的任务肯定要比为一个序列的每个位置去分十几个类别要简单。感觉引入机器阅读理解框架的那篇 NER 论文 [19],实际也是用类似的方式把问题简化了。

参考文献
[1] Ren, X., He, W., Qu, M., Huang, L., Ji, H., & Han, J. (2016, November). AFET: Automatic Fine-Grained Entity Typing by Hierarchical Partial-Label Embedding. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing (pp. 1369-1378).
[2] Chen, B., Gu, X., Hu, Y., Tang, S., Hu, G., Zhuang, Y., & Ren, X. (2019). Improving distantly-supervised entity typing with compact latent space clustering. arXiv preprint arXiv:1904.06475.
[3] Xiao Ling and Daniel S. Weld. 2012. Fine-grained entity recognition. In Proceedings of the Twenty-Sixth AAAI Conference on Artificial Intelligence, July 22-26, 2012, Toronto, Ontario, Canada., pages 94–100.
[4] Dan Gillick, Nevena Lazic, Kuzman Ganchev, Jesse Kirchner, and David Huynh. 2014. Context-dependent fine-grained entity type tagging. CoRR, abs/1412.1820.
[5] Dani Yogatama, Daniel Gillick, and Nevena Lazic. 2015. Embedding methods for fine grained entity type classification. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing of the Asian Federation of Natural Language Processing, ACL 2015, July 26-31, 2015, Beijing, China, Volume 2: Short Papers, pages 291–296.
[6] Shikhar Murty, Patrick Verga, Luke Vilnis, Irena Radovanovic, and Andrew McCallum. 2018. Hierarchical losses and new resources for fine-grained entity typing and linking. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, ACL 2018, Melbourne, Australia, July 15-20, 2018, Volume 1: Long Papers, pages 97–109.
[7] Sheng Zhang, Kevin Duh, and Benjamin Van Durme. 2018. Fine-grained entity typing through increased discourse context and adaptive classification thresholds. In Proceedings of the Seventh Joint Conference on Lexical and Computational Semantics, *SEM@NAACL-HLT 2018, New Orleans, Louisiana, USA, June 5-6, 2018, pages 173–179.
[8] Matthew E. Peters, Mark Neumann, Mohit Iyyer, Matt Gardner, Christopher Clark, Kenton Lee, and Luke Zettlemoyer. 2018. Deep contextualized word representations. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2018, New Orleans, Louisiana, USA, June 1-6, 2018, Volume 1 (Long Papers), pages 2227–2237.
[9] Ying Lin and Heng Ji. 2019. An attentive fine-grained entity typing model with latent type representation. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 61986203, Hong Kong, China. Association for Computational Linguistics.
[10] Peng Xu and Denilson Barbosa. 2018. Neural fine-grained entity type classification with hierarchy-aware loss. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2018, New Orleans, Louisiana, USA, June 1-6, 2018, Volume 1 (Long Papers), pages 16–25.
[11] Murty, S., Verga, P., Vilnis, L., Radovanovic, I., & McCallum, A. (2018, July). Hierarchical losses and new resources for fine-grained entity typing and linking. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) (pp. 97-109).
[12] Mohamed Amir Yosef, Sandro Bauer, Johannes Hoffart, Marc Spaniol, and Gerhard Weikum. 2012. HYENA: hierarchical type classification for entity names. In COLING 2012, 24th International Conference on Computational Linguistics, Proceedings of the Conference: Posters, 8-15 December 2012, Mumbai, India, pages 1361–1370.
[13] Choi, E., Levy, O., Choi, Y., & Zettlemoyer, L. (2018). Ultra-fine entity typing. arXiv preprint arXiv:1807.04905.
[14] Hailong Jin, Lei Hou, Juanzi Li, and Tiansi Dong. 2019. Fine-grained entity typing via hierarchical multi graph convolutional networks. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 4968–4977, Hong Kong, China. Association for Computational Linguistics.
[15] Hongliang Dai, Donghong Du, Xin Li, and Yangqiu Song. 2019. Improving fine-grained entity typing with entity linking. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages6209–6214, HongKong, China.Association for Computational Linguistics.
[16] Sheng Zhang, Kevin Duh, and Benjamin Van Durme. 2018. Fine-grained entity typing through increased discourse context and adaptive classification thresholds. In Proceedings of the Seventh Joint Conference on Lexical and Computational Semantics, *SEM@NAACL-HLT 2018, New Orleans, Louisiana, USA, June 5-6, 2018, pages 173–179.
[17] ThéoTrouillon, JohannesWelbl, SebastianRiedel, ´ Eric Gaussier, and Guillaume Bouchard. 2016. Complex embeddings for simple link prediction. In Proceedings of the 33nd International Conference on Machine Learning, ICML 2016, New York City, NY, USA, June 19-24, 2016, pages 2071–2080.
[18] Ilya Loshchilov and Frank Hutter. 2019. Decoupled weight decay regularization. In 7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, May 6-9, 2019.
[19] Li, X., Feng, J., Meng, Y., Han, Q., Wu, F., & Li, J. (2019). A Unified MRC Framework for Named Entity Recognition. arXiv preprint arXiv:1910.11476.
更多阅读




#投 稿 通 道#
让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
📝 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
📬 投稿邮箱:
• 投稿邮箱:hr@paperweekly.site
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。





