我用Python来爬取了小说《花千骨》……
知识就像碎布,记得“缝一缝”,你才能华丽丽地亮相。
1.Beautiful Soup
1.Beautifulsoup 简介
此次实战从网上爬取小说,需要使用到Beautiful Soup。
Beautiful Soup为python的第三方库,可以帮助我们从网页抓取数据。
它主要有如下特点:
1.Beautiful Soup可以从一个HTML或者XML提取数据,它包含了简单的处理、遍历、搜索文档树、修改网页元素等功能。可以通过很简短地代码完成我们地爬虫程序。
2.Beautiful Soup几乎不用考虑编码问题。一般情况下,它可以将输入文档转换为unicode编码,并且以utf-8编码方式输出,
2.Beautiful Soup安装
win命令行下:
pip install beautifusoup4
3.Beautiful Soup基础
大家可以参考文档来学习(中文版的哦):http://beautifulsoup.readthedocs.io/zh_CN/latest/#id8
对于本次爬虫任务,只要了解以下几点基础内容就可以完成:
1.Beautiful Soup的对象种类:
Tag
Navigablestring
BeautifulSoup
Comment
2.遍历文档树:find、find_all、find_next和children
3.一点点HTML和CSS知识(没有也将就,现学就可以)
2.爬取小说花千骨
1.爬虫思路分析
本次爬取小说的网站为136书屋。
先打开花千骨小说的目录页,是这样的。
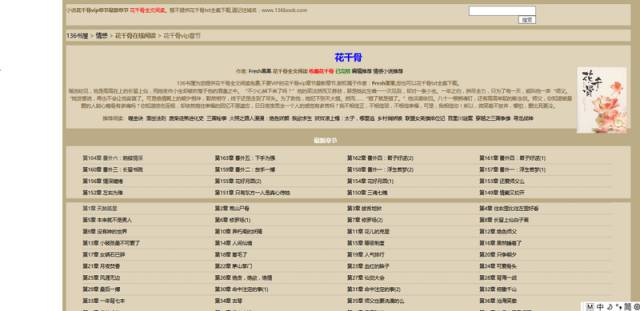
我们的目的是找到每个目录对应的url,并且爬取其中地正文内容,然后放在本地文件中。
2.网页结构分析
首先,目录页左上角有几个可以提高你此次爬虫成功后成就感的字眼:暂不提供花千骨txt全集下载。
继续往下看,发现是最新章节板块,然后便是全书的所有目录。我们分析的对象便是全书所有目录。点开其中一个目录,我们便可以都看到正文内容。
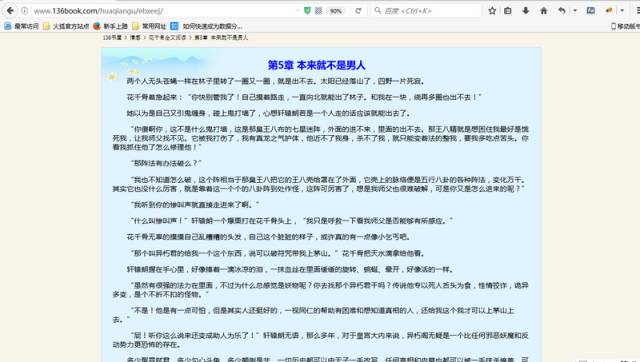
按F12打开审查元素菜单。可以看到网页前端的内容都包含在这里。
我们的目的是要找到所有目录的对应链接地址,爬取每个地址中的文本内容。
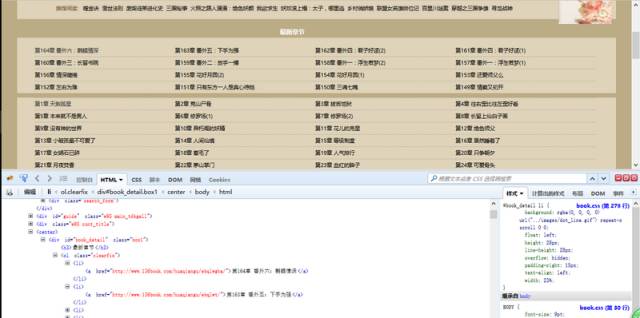
有耐心的朋友可以在里面找到对应的章节目录内容。有一个简便方法是点击审查元素中左上角箭头标志的按钮,然后选中相应元素,对应的位置就会加深显示。
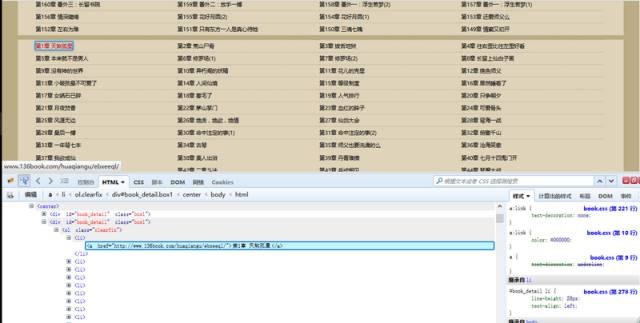
这样我们可以看到,每一章的链接地址都是有规则地存放在<li>中。而这些<li>又放在<div id=”book_detail” class=”box1″>中。
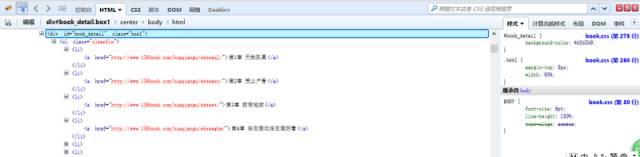
我不停地强调“我们的目的”是要告诉大家,思路很重要。爬虫不是约pao,蒙头就上不可取。
3.单章节爬虫
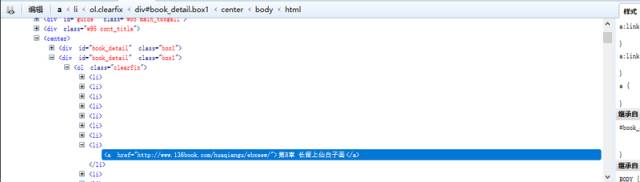
刚才已经分析过网页结构。我们可以直接在浏览器中打开对应章节的链接地址,然后将文本内容提取出来。
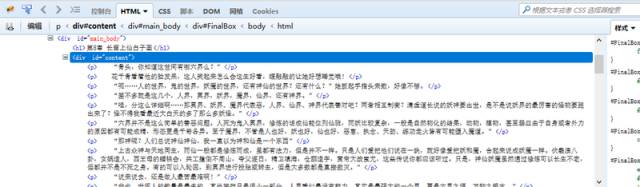
我们要爬取的内容全都包含在这个<div>里面。
代码整理如下:
from urllib import request
from bs4 import BeautifulSoup
if __name__ == '__main__':
# 第8章的网址
url = 'http://www.136book.com/huaqiangu/ebxeew/'
head = {}
# 使用代理
head['User-Agent'] = 'Mozilla/5.0 (Linux; Android 4.1.1; Nexus 7 Build/JRO03D) AppleWebKit/535.19 (KHTML, like Gecko) Chrome/18.0.1025.166 Safari/535.19'
req = request.Request(url, headers = head)
response = request.urlopen(req)
html = response.read()
# 创建request对象
soup = BeautifulSoup(html, 'lxml')
# 找出div中的内容
soup_text = soup.find('div', id = 'content')
# 输出其中的文本
print(soup_text.text)
运行结果如下:
这样,单章节内容爬取就大功告成了。
4.小说全集爬虫
单章节爬虫我们可以直接打开对应的章节地址解析其中的文本,全集爬虫我们不可能让爬虫程序在每章节网页内中跑一遍,如此还不如复制、粘贴来的快。
我们的思路是先在目录页中爬取所有章节的链接地址,然后再爬取每个链接对应的网页中的文本内容。说来,就是比单章节爬虫多一次解析过程,需要用到Beautiful Soup遍历文档树的内容。
1.解析目录页
在思路分析中,我们已经了解了目录页的结构。所有的内容都放在一个所有的内容都放在一个<div id=”book_detail” class=”box1″>中。
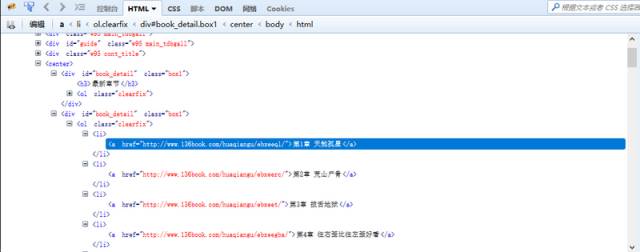
这儿有两个一模一样的<div id=”book_detail” class=”box1″>。
第一个<div>包含着最近更新的章节,第二个<div>包含着全集内容。
请注意,我们要爬取的是第二个<div>中的内容。
代码整理如下:
from urllib import request
from bs4 import BeautifulSoup
if __name__ == '__main__':
# 目录页
url = 'http://www.136book.com/huaqiangu/'
head = {}
head['User-Agent'] = 'Mozilla/5.0 (Linux; Android 4.1.1; Nexus 7 Build/JRO03D) AppleWebKit/535.19 (KHTML, like Gecko) Chrome/18.0.1025.166 Safari/535.19'
req = request.Request(url, headers = head)
response = request.urlopen(req)
html = response.read()
# 解析目录页
soup = BeautifulSoup(html, 'lxml')
# find_next找到第二个<div>
soup_texts = soup.find('div', id = 'book_detail', class_= 'box1').find_next('div')
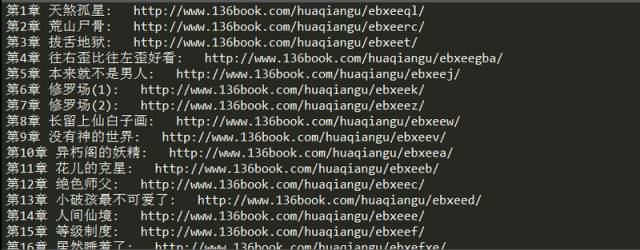
# 遍历ol的子节点,打印出章节标题和对应的链接地址
for link in soup_texts.ol.children:
if link != '\n':
print(link.text + ': ', link.a.get('href'))
执行结果如图:
2.爬取全集内容
将每个解析出来的链接循环代入到url中解析出来,并将其中的文本爬取出来,并且写到本地F:/huaqiangu.txt中。
代码整理如下:
from urllib import request
from bs4 import BeautifulSoup
if __name__ == '__main__':
url = 'http://www.136book.com/huaqiangu/'
head = {}
head['User-Agent'] = 'Mozilla/5.0 (Linux; Android 4.1.1; Nexus 7 Build/JRO03D) AppleWebKit/535.19 (KHTML, like Gecko) Chrome/18.0.1025.166 Safari/535.19'
req = request.Request(url, headers = head)
response = request.urlopen(req)
html = response.read()
soup = BeautifulSoup(html, 'lxml')
soup_texts = soup.find('div', id = 'book_detail', class_= 'box1').find_next('div')
# 打开文件
f = open('F:/huaqiangu.txt','w')
# 循环解析链接地址
for link in soup_texts.ol.children:
if link != '\n':
download_url = link.a.get('href')
download_req = request.Request(download_url, headers = head)
download_response = request.urlopen(download_req)
download_html = download_response.read()
download_soup = BeautifulSoup(download_html, 'lxml')
download_soup_texts = download_soup.find('div', id = 'content')
# 抓取其中文本
download_soup_texts = download_soup_texts.text
# 写入章节标题
f.write(link.text + '\n\n')
# 写入章节内容
f.write(download_soup_texts)
f.write('\n\n')
f.close()
执行结果显示 [Finished in 32.3s] 。
打开F盘查看花千骨文件。

爬虫成功。备好纸巾,快快去感受尊上和小骨的虐恋吧。
5.总结
代码还有很多改进的地方。例如文本中包含广告的js代码可以去除,还可以加上爬虫进度显示等等。实现这些功能需要包含正则表达式和os模块知识,就不多说了,大家可以继续完善。
来源:segmentfault.com/a/1190000010895903
------------------
明明共同关注公众号,彼此却互不认识;
明明具有相同的爱好,却无缘相识;
有没有觉得这就是上帝给我们的一个bug!
想不想认识更多写程序的小伙伴?
C++,Java,VB……应有尽有。
还等什么?赶快上车加入我们吧!
(・ิϖ・ิ)っ算法与数学之美-计算机粉丝群
我们在这里等你哟
算法数学之美微信公众号欢迎赐稿
稿件涉及数学、物理、算法、计算机、编程等相关领域。
稿件一经采用,我们将奉上稿酬。
投稿邮箱:math_alg@163.com





