对比学习效果差?谷歌提出弱语义负样本,有效学习高级特征!

文 | jxyxiangyu
编 | 小轶
对比学习是 2021 年几大研究热点之一了。如果说预训练模型解决了机器学习对大规模标注数据的需求问题,那么,对比学习可以说是将无监督/自监督学习推广到更一般的应用场景,为苦于标注数据不多的炼丹师们又带来了福音。
一般来说,对比学习的重点在于:使同类样本的特征表示尽可能接近,而异类样本的特征表示之间的距离尽可能变大。在实际应用场景下,正样本数量通常小于负样本的数量。在对比学习的工作中,提出的也多是正样本的增强操作。比如在 SimCSE 中,就是对样本原本的特征表示 dropout 操作获取增强的正样本。而对比学习中的负样本,则往往直接使用数据集中的其他样本(或者异类样本)作为对比学习的负样本。
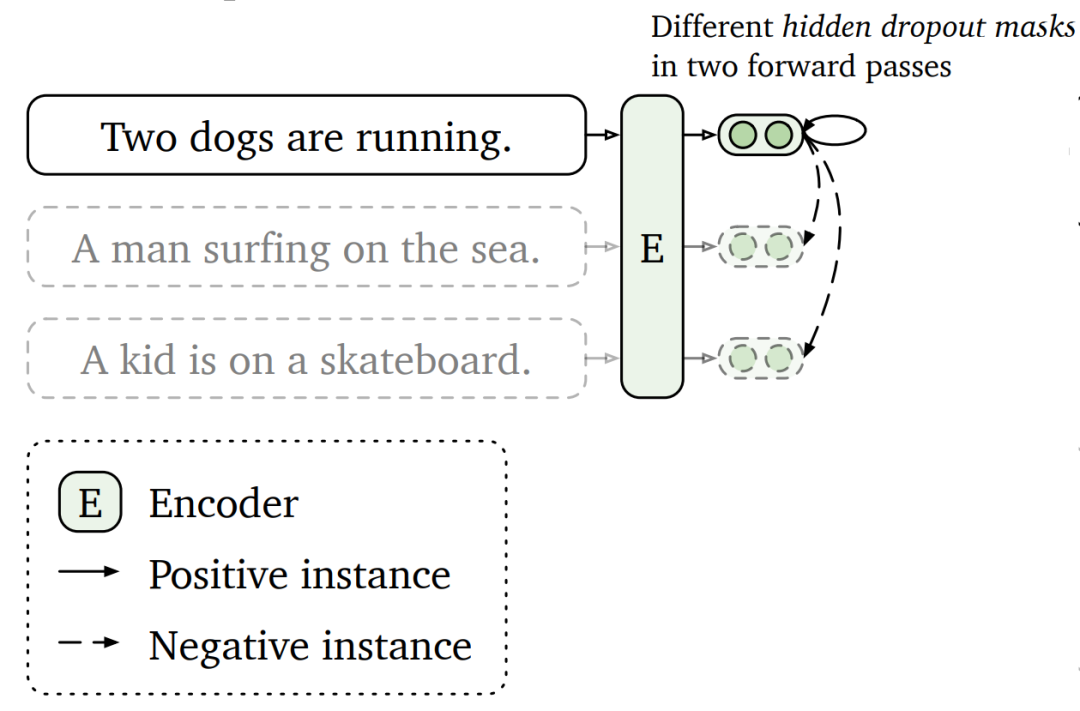
如果我们将对比学习应用到负样本对上,又会产生怎样的火花呢?最近,Maryland大学和谷歌联合研究了对比学习在负样本对上的应用,下面,让我们一起来看看吧!
论文题目:
Robust Contrastive Learning Using Negative Samples with Diminished Semantics
论文链接:
https://arxiv.org/pdf/2110.14189.pdf
![]() 对比学习
对比学习![]()
 对比学习
对比学习在解读今天这篇论文之前,先简单介绍下对比学习。
为解决标注数据不足的问题,对比学习提供了这样一种思路:分别构造相似样本对(正样本对)和不相似样本对(负样本对),并通过区分正样本对和负样本对来达到训练模型的目的。训练期间,模型会缩短正样本对之间的距离,而拉大负样本对的距离 。

达咩,一些研究表明,基于CNN的模型会过多地关注数据的低级特征,比如图片的局部 patch、纹理、甚至是人为添加的后期特征(换言之,就是模型找到了某些可以提升效果的 shortcut)。这些特征的微小变动可能会直接改变模型最终的预测。而站在人类视角来看,人们多是通过物体的形状这种更高级的特征来识别和区分物体的。谷歌最近就提出了一种方法,可以通过增强弱语义负样本,大大提升模型对比学习的鲁棒性。
![]() 弱语义负样本
弱语义负样本![]()
传统的对比学习只是粗暴地将正负样本对区分开,实验证明,这种方法构造的负样本对会驱使模型过度地依赖数据的底层特征,而忽略了底层特征组合产生的高级语义,毕竟,当我们在观看一张狗的图片的时候,更多地关注的是狗的外形、毛发,而不是其中几个patch反映出来的颜色和质感。
弱语义负样本的对比学习
文章的作者针对目前对比学习存在的问题,提出了用弱语义负样本的对比学习。给定编码模型 和图片 ,模型的输出为 ,原始样本(query sample)记作 ,相应的模型输出为 。传统的对比学习是从同一个原始样本 通过保留语义信息的数据增强方法得到正样本 ,而负样本的生成方式并不固定,以 为例,该方法是从当前 batch 的其他样本中选择得到负样本 ,正负样本的模型输出特征分别是 、 。为了减少模型对底层特征的依赖,作者引入了弱语义负样本 ,其模型输出特征为 。顾名思义,弱语义负样本指的是在输入样本中我们不希望模型学到底层非语义的低级特征。作者还给出了带噪对比估计损失函数(noise-contrastive estimation, NCE):
其中, 是超参, 是调节弱语义负样本比例的缩放因子
考虑到某些对比学习方法在loss函数设计上仅考虑了原始样本和正样本的相似度,类似的,作者也给出了相应的带弱语义负样本的loss函数:
通过最小化 或 ,模型可以学习到正样本中含有的但弱语义负样本中没有的高级语义特征。
那么,我们应该怎样构建弱语义的负样本呢?作者给出了两种构造方案:基于纹理的负样本生成方法和基于patch的负样本生成方法,下图展示了这两种方法生成的负样本。

基于纹理的负样本生成
为了生成的弱语义负样本可以很好地表示图片中诸如纹理的局部低级特征,作者首先从输入图片(query sample)采样出两个patch,一个patch取自图片的中心位置,表示图片中目标的局部特征,另一个patch取自图片中的随机位置,表示图片中其余的纹理特征,譬如目标对象的背景、轮廓等。具体地,实验中在图片大小允许的前提下,作者提取的是 大小的patch,否则提取 大小的patch;之后,用现有的纹理合成工具根据采样的两个patch生成 大小的纹理图片,为 ImageNet 数据集中的每个样本重复上述操作,可以得到 ImageNet-Texture 纹理数据集。
基于patch的负样本生成
给定图片和采样的patch大小 ,从图片的 个非重叠的随机位置中采样大小为 的patch,之后,将这些patch平铺并裁剪成 的样本。与基于纹理的负样本生成方法相比,基于patch的方法运算速度快,耗时短;另外,基于patch的方法可以做到在每次迭代训练时采用不同的patch对生成负样本,与基于纹理的方法相比,更具有随机性。
当然,这并不意味着基于patch的方法是完美的,如上图(e),所示,基于patch的方法会人为的引入一些分界线,这些分界线是由于patch间像素变化剧烈导致的,为缓解这一问题,作者先从先验分布中采样出patch大小 ,然后再基于此生成负样本,以期望模型可以学到不同尺度下的纹理特征。
两种负样本生成方法的区别
介绍完上面两种方法,相必会有小伙伴有疑问:既然两种方法都可以生成弱语义负样本,那么它们之间有什么区别呢?
作者使用官方给定的 MoCo-v2 模型在 ImageNet-1K 数据集上预训练200轮得到的模型,计算 ImageNet 训练集不同样本对之间的余弦相似度,相似度分布如下所示:
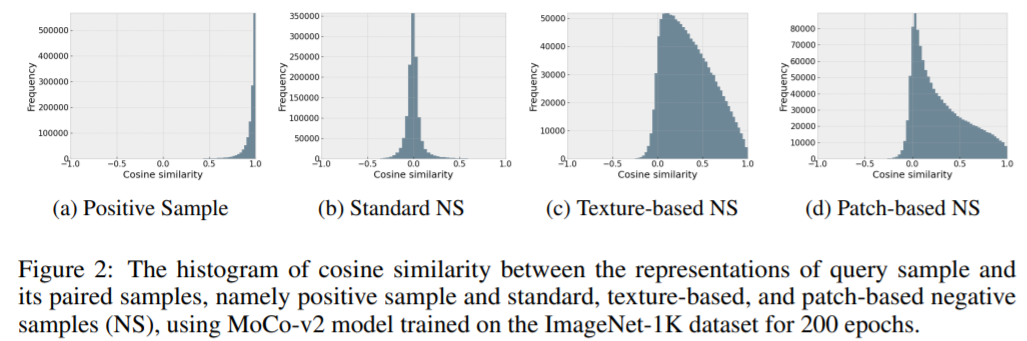
可以看到,大部分正样本对和负样本对的相似度都接近1和0,平均相似度分别为0.94257和0.00018,而基于纹理和基于patch方法生成的负样本对,其相似度分布并没有像前两者那么集中于某个点,而是分布在0~1之间,用作者的话来说,呈现出“heavy tail”的分布,平均相似度分别为0.35248和0.29503。
![]() 实验
实验![]()
作者在 ImageNet 和 ImageNet-100 数据集上分别用两种对比学习模型 MoCo 和 BYOL 对上述两种生成方法生成的弱语义负样本做了实验,用在域外数据集(out-of-domain, OOD包括ImageNet-C(orruption)、ImageNet-S(ketch)、Stylized-ImageNet和ImageNet-R(endition))上的准确度(accuracy)作为评估模型在领域偏移(domain shift)的鲁棒性。基于patch的负样本生成方法中,patch大小 服从 的均匀分布。实验结果如下:
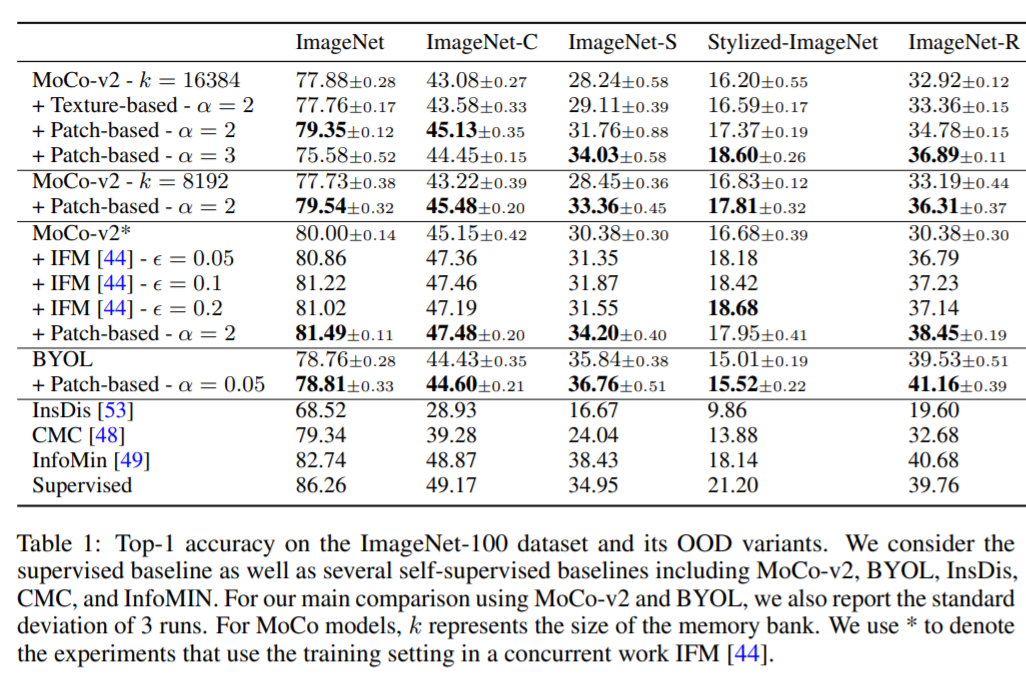
可以看到,在 MoCo-v2 模型上,无论是基于纹理还是基于patch的弱语义负样本生成方法,都可以提升在域外数据集上的泛化性。在域内数据集(ImageNet)上,当超参选择合适( )时,基于patch的方法也能带来准确率的提升。此外,基于纹理的方法带来的性能提升不如基于patch的方法的明显,可能的原因也在前面做弱语义负样本相似度对比了相应的分析。
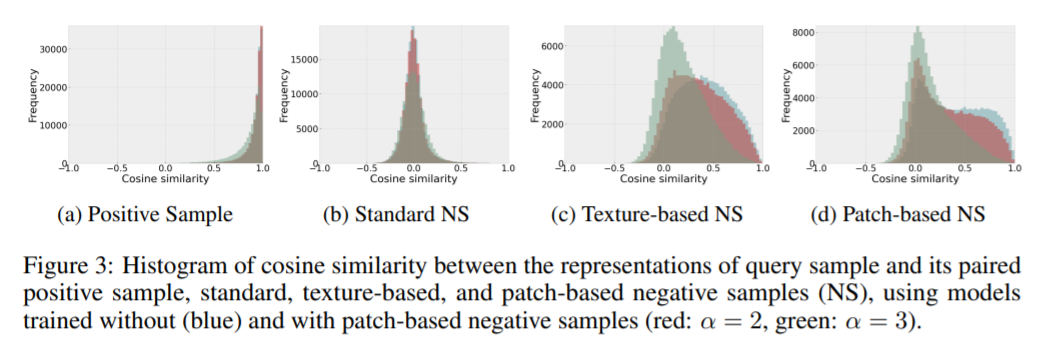
和图2类似,作者给出了是否使用基于patch的方法生成的负样本参与模型训练的样本相似度分布情况。蓝色曲线表示的是没有使用弱语义负样本训练的结果,红色和绿色曲线表示的是使用不同的 下弱语义负样本训练的结果。可以看到,在模型训练过程中加入弱语义负样本,可以降低原始样本和弱语义样本的相似度,说明模型降低了对底层特征的依赖,学到了更多高级语义特征,此外,随着 的增大,无论是基于纹理还是基于patch生成的弱语义负样本,两者的平均相似度也随之降低,但整体来看,基于patch的方法降低程度更为明显。
众所周知,基于负样本的对比学习方法存在对负样本的挖掘效率低下的问题,前人多使用大 batch size 或 memory bank 来解决这一问题。作者分别在 STL-10 和 ImageNet-100 数据集上研究了弱语义负样本是否可以缓解这一问题。实验结果如下所示:
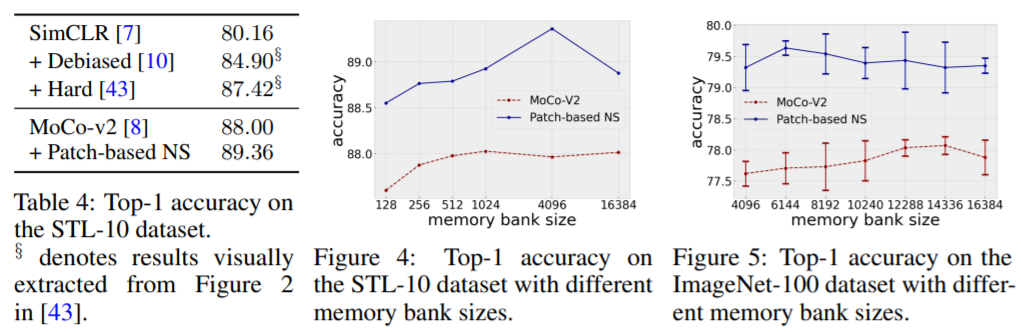
可以看到,无论 memory bank 大小如何改变,基于patch生成的弱语义负样本训练的模型都有较好的准确率,证明了弱语义负样本可以有效缓解上述问题。
作者还研究了损失函数中 对平衡高级语义和底层纹理特征的影响,在 ImageNet-100 数据集上分别用不同的 训练 MoCo-v2 模型,实验结果如下,其中图 c 展示的是在 ImageNet 验证集和 ImageNet-Sketch 数据集上不同的 值对准确率的影响:
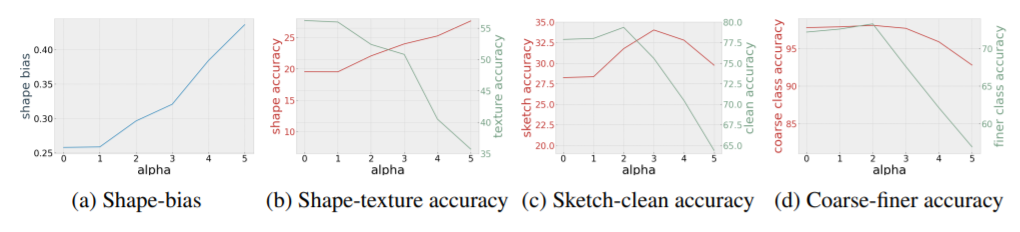
可以看到, 控制着模型中关于纹理(底层特征)和形状(高级语义)的权重比例,随着 的增大,损失函数加大了对原始样本和弱语义负样本的相似度的惩罚,模型会学到更多的语义信息,相应地,模型的预测准确率也与没有使用弱语义负样本相比有所提高。
关于形状-纹理的初步讨论表明,人类更多地依赖于形状特征,而CNN更多地依赖于纹理特征,增加形状这种高级语义信息可以提高模型的准确性和鲁棒性,然而增大形状并不总是能够提升模型的鲁棒性。因此,作者从不同的分类粒度的角度研究了ImageNet数据集中狗的图片粗粒度和细粒度下的准确率(图 d ),对于粗粒度分类,只关注图像是否为狗类,而不关心具体是哪个种类的狗,而对于细粒度分类而言,只有预测为目标种类的狗的样本才被视为预测正确。从图 d 可以看到,随着形状特征的增加,细粒度预测准确率出现更为明显的下降趋势,因此,像 ImageNet 这种细粒度分类的数据集而言,偏好纹理这种底层特征的模型能够有较高的准确度。在论文附录中,作者也展示出了仅靠几个纹理特征就可以实现模型较高的准确度。
![]() 总结
总结![]()
作者提出了用负样本丢弃掉模型不需要学习的特征,从而提高对比学习模型的泛化性的思路和方法,也为因为对比学习的火热就无脑对比学习的炼丹师们(比如我╮(╯▽╰)╭)给予了告诫:在模型训练之前,需要想清楚我们希望模型学到哪些特征。
除此之外,作者只在cv领域作了相关研究,而这些研究成果是否可以推广到其他领域,比如nlp呢?仔细想想,这岂不又是一个水论文(bushi)的方向了吗?

萌屋作者:jxyxiangyu
人工智障、bug制造者、平平无奇的独臂侠、在某厂工作的初级程序员,从事对话交互方向,坚持每天写一点bug,时常徘徊在人工智能统治未来和if-else才是真正的AI的虚拟和现实之间,希望有朝一日学术界的研究成果可以真正在工业界实现落地。
作品推荐
 萌屋作者:jxyxiangyu
萌屋作者:jxyxiangyu
后台回复关键词【入群】
加入卖萌屋NLP/IR/Rec与求职讨论群
后台回复关键词【顶会】
获取ACL、CIKM等各大顶会论文集!
![]()
[1] 对比学习(Contrastive Learning)在CV与NLP领域中的研究进展(https://zhuanlan.zhihu.com/p/389064413)
 后台回复关键词【
后台回复关键词【



