美图在大型容器化平台日志的实践(一)选型思考篇
为了降低业务成本,提高服务器资源利用率,获得快速伸缩及弹性计算的能力,美图在今年( 2017)早些时候,就已经开始了容器化平台的建设,从服务编排平台的选型( Kubernetes, Mesos 等),服务的调度和负载均衡,网络方案的确定,到业务容器日志的收集等方方面面,我们都做了非常努力的探索。本文主要分享容器日志的收集相关方面的探索,计划分为三篇文章。
任勇全,先后在新浪微博,奇虎 360 从事基础架构研发工作,目前在美图担任高级技术经理,专注于后端技术研发,包括消息通信,分布式存储及容器虚拟化等方向。
选型思考篇:第一篇主要介绍当前日志收集的背景,以及面临的问题,这直接决定了我们最终采取的日志收集方案;
架构篇:第二篇计划给出我们日志收集系统的架构;
实践篇:第三篇讨论在现实情况下,面对各种历史遗留问题,如何以过渡的方式,一步步推进日志收集方案的落地。
如果对容器化平台的其他方面感兴趣,也请留意后续文章,美图架构的小伙伴也会在适当的时候,将我们做的一些探索和心得分享出来。
本文是容器平台日志收集方案的第一篇,主要介绍了对日志输出和日志收集的一些思考,这些思考最终促成了我们日志收集的方案和方向,让我们对日志收集功能哪些可以妥协、哪些必须坚持有了参考依据和指导思想。
容器日志收集的难点不在于做出独创性的方案,而是基于大众都知道的各种方案,有一个具备清晰参考依据的选型,然后克服历史遗留问题,不同业务的复杂性等各种困难,坚定不移的执行下去。相信在调研容器日志收集问题的同学,对应该采取的方案和未来的发展方向都有自己的思考,只是这些思考可能还不够清晰,或者在面临真实的项目的时候,无法说服项目开发人员;如果你面临这些问题,这篇文章可能就是为你准备的。如果你只是想简单了解容器化的日志收集是如何做的,这可能要等我们第二篇文章。
本篇文章更侧重于“为什么”这么做,而不是“怎么做”。如果你已经有丰富的容器化建设的经验,我们非常希望您在读完本文后,对于我们失误的地方予以指正,或分享给我们更好的建议或方案。
背景
随着系统规模越来越大,代码逻辑越来越复杂,对服务端的一个请求,可能经过多个模块和处理逻辑,在异常发生时,如何排查代码错误也会变得非常困难,当前比较有效和认可的做法就是为程序打印运行日志,将程序的关键路径,关键数据记录下来,以便日后排查问题时作为参考。
日志可以分为多个级别,比如 debug, info, warn, error 等, debug 比 info 级别具有更丰富的信息,更细粒度的日志打印。线上运行时,为了避免过多日志影响服务性能,我们通常设置日志级别为 error 或 info。
对于资源访问或 HTTP 接口,我们还期望能确认客户端的请求是否被服务端接收到,这是 error 级别的运行日志无法提供的,因为一个客户端请求在服务端没有任何错误,可能是服务端根本没有接收到客户端的请求;我们通常不会为了解决这个问题而开启 debug 级别的日志(影响性能),而是将这种类型的日志单独抽象为访问日志( access log)。访问日志一般记录了客户端的请求的资源或接口,请求耗时,响应结果(状态码)等,而这些数据除了用来排查问题,还可以用来统计服务的运行状况和性能表现,比如 QPS,平均响应时间,错误率等等。
随着大数据的兴起,我们对数据的分析解读能力越来越强,日志作为原始数据则体现出了更大的价值,运行日志可以交由大数据系统进行数据挖掘,以智能判断服务的运行状况,出错时及时触发报警等。访问日志则更适合大数据系统做统一的统计分析,比如哪些资源访问较多,资源访问耗时是多少,状态码分布规律是怎样的等等。另外,大数据本身也衍生了更多数据方面的需求,比如用户行为分析,敏感词过滤,反作弊反垃圾等等,为了提供这些数据,我们通常也是以日志的形式将这些信息打印出来。
当前的互联网系统是高度模块化的服务,从前端服务接口,到后端的处理逻辑可能跨越多个远程调用,传统的运行日志是无法将远程调用信息像本地调用栈一样打印出来,通常的做法是我们在服务的入口生成 traceid,并在每个模块的关键路径打印日志,打印的日志都携带最初生成的 traceid ;这样则可以通过 traceid 将所有调用流程关联起来。另一种方式是大家接入专门做 trace 服务的 SDK,将关键调用信息通过 SDK 发送到分布式 trace 系统。
上面我大体列举了四种类型的日志,真实的生产环境中还会有更多其他类型的日志,比如操作系统的 dmesg,语言运行时或 VM 的 gc 日志,甚至是为了某个特定用途而打印的日志等等。可以看到,上述日志其实是不同时代的产物,产生时面临的环境、要解决的问题随着时间也正在慢慢改变;这给我们带来很多思考:所有的日志都是必要的吗?日志打印的方式适合当前这个时代吗?以前的需求现在还成立吗?能否站在当下的角度抽象为更精简的几种类型的日志(而不是四种),按什么维度去抽象和精简? 在这里我无法对所有问题给出答案,但这些问题在我们设计容器化日志收集方案时,却可以提醒我们重新审视当前的日志打印和收集方式,避免落入固化思维。虽然无法对所有问题解答,但有些方面我们已经可以明显的察觉到变化。
面向机器而不是面向人
这可能是传统日志和大数据时代日志最明显的差别,传统的运行日志和访问日志,基本是为开发或运维提供排查问题的信息,是面向人去设计的,人脑天生适合处理非结构化的数据,因此日志信息非常随意,可能只是一句话,关联的数据项和格式也不固定,比如:
26109 2017-08-03 07:35:49 [DEBUG] server.go:122 Callback PostSubscribe SubTopics:<Topic:" / push / 251ac7af-8cdc-4b23-a5c6-faa6c0d4925f" QoS:1 > ClientID:"251ac7af-8cdc-4b23-a5c6-faa6c0d4925f"
这条日志是从推送服务线上运行日志摘取的,其特点很明显,日志行本身有一定的格式( pid,日志,日志级别等),但日志信息本身却是程序员(我)随意去写的,“ Callback PostSubscribe”我们知道是调用了回调函数,关联的信息格式看起来是冒号分割的 key-value,但 SubTopics 这个字段的 value 很明显又有自己的格式,比如可以理解为尖括号括起来的对象( key-object),那么问题是这里为什么是尖括号呢,为什么不是大括号圆括号呢?或者我们有没有统一的标准来表达这种 key-object 的的语义呢?答案是有的,比如 JSON 就可以做到。 大数据时代,处理日志信息的不再是人工,而是代码,只有结构化的数据才会便于代码处理。
服务与运行环境解耦
这可能是很多人还未曾察觉到的变化, SaaS、容器化、微服务等技术的发展,促使我们交付的成品不是一个独立的可运行的系统,而是高度模块化的,相互协作的服务。
容器的出现,提供了操作系统运行时的抽象,服务可以不用关心操作系统之间的差异,也就是将服务跟真实的运行环境解耦。 Docker 容器化的服务,可以作为一个独立的单位,部署在任何支持 Docker 容器的操作系统平台。
因此我们在做服务开发时,应该避免对运行环境的依赖。 一个思路是,我们将日志抽象为一个流,服务只将日志信息输出到这个流,不应该去关心日志存储的位置 (12factor https://12factor.net/zh_cn/logs)
目前这种思路已经被广泛应用,比如程序运行日志输出到 stdout(标准输出),然后由运行环境截获,比如运行在实体机上由 journald 截获,运行在容器化平台,由 Docker 的 log driver 截获。而服务只是将日志打印出来,不需要关系运行在哪个环境,是否需要落到磁盘等等。
下图就是 journald 截获的运行服务的日志:
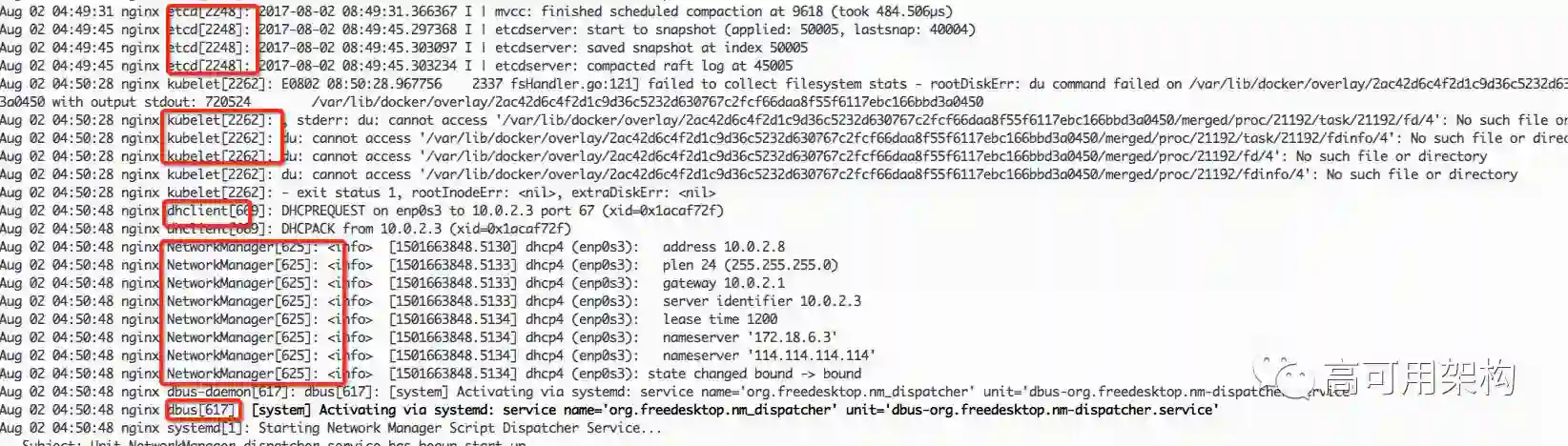
传统的日志输出
非结构化
上面提到,日志产生的背景,是便于人工排查问题,因此日志的格式一般是非结构化的,便于人类阅读的;而现在一个功能可能由多个服务组件协作完成,这些服务组件都是远程调用关系,排查问题已经不是简单的单机查看日志,而是综合整个系统的日志去分析。这样不可避免,我们需要将日志收集整合,并通过专业的分析系统进行分析和展示;比如业界通常使用的 ELK 就是实现这个功能。
输出到文件
输出到文件使得服务的开发跟运行环境耦合,开发者需要关心日志输出的路径,或者,是由运维根据实际的运行状况去配置路径。这在我们人工部署的时代是可行的,容器化后,服务的运行环境则变成未知的,不同的服务可能运行在同一个物理机上,日志的路径可能产生冲突,而为了解决冲突,我们又需要退化到人工规划路径的时代;或者通过一些手段,将容器的唯一标识作为路径的一部分,这样实际会造成反向依赖,运行服务的容器外获取到标识信息,并创建目录,通过一定的手段(配置或环境变量)传递给容器内的服务。之所有会产生反向依赖,是因为容器内运行的服务,需要感知其底层的操作系统环境。
分多个文件
我们线上习惯将不同类型的日志打印到不同的文件,这种设计思想仍然是为人服务的,另一方面,是由于我们的日志是非结构化的,也不具备统一的格式,不同的格式混杂在一起使得机器解析也变得困难。这种情况,只有我们从内心接纳了将日志输出到统一的流的概念,才能改善。比如:为了让同一个流的日志具备统一的格式,我们可能选择用 JSON 作为日志输出格式,为了在流内区分不同的组件,我们会将一些标识性的信息,比如 pid,进程名,服务名等输出到日志。 另外,我们习惯将运行日志的多个级别分别打印到不同的文件,这也是纯粹为了人的需求而选择的方案,在面向机器的时代,这是日志可以合并到一起,便于收集。
传统日志的收集
传统的日志收集 agent 并没有尝试解决日志从面向人到到面向机器的转变。而是随着日志的发展,去不断调整和适应,比如配置复杂的解析规则以应对不同格式的日志解析( Nginx, httpd 等),实现按照匹配规则来匹配日志文件等等。由于不同的日志收集方,都倾向根据自己的特殊需求提供日志收集的 agent,导致同一套服务会随同部署多套 agent 来收集日志。在这种架构下继续发展,衍生出了更加耦合的 agent 设计方案,比如为了避免集中解析日志格式, agent 会倾向在收集端做解析,通过分布式的日志处理减轻日志中心的压力。
在面向机器的时代,随着微服务化架构的流行,基于传统的解决方案继续演进,只会让日志收集变得越来越复杂,我们需要重新思考日志收集 agent 的作用,比如,划定单一的功能, agent 只做收集的事情,不关心具体业务字段的解析,这样可以抽象出一个统一的 agent;将日志内容结构化,减轻解析日志文本的压力;日志解析由日志使用方实现,这些原始的结构化的数据是有保存价值的,不同的日志使用方可以根据自己的需求去解读同一份日志(比如根据访问日志分析用户行为,或统计接口性能)。
容器化面临的挑战
从上面分析可以看到,传统的日志输出及收集方式,已经不适应大数据,微服务的发展趋势,服务容器化将这个矛盾推向高峰。 Kubernetes 将容器的运行环境抽象,并对服务进行编排和调度,不同的服务可能被调度到不同的物理机节点上;我们无法人工针对某个业务去部署和配置日志收集 agent。
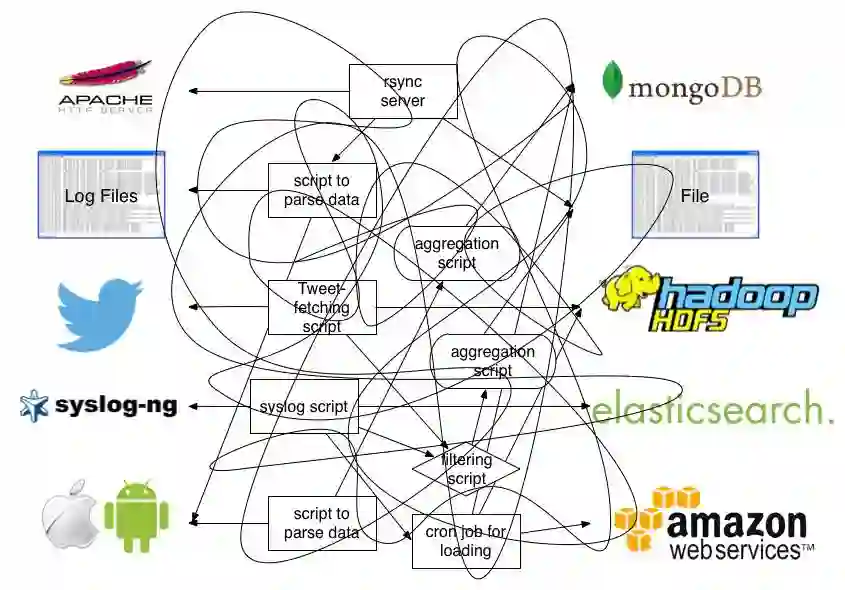
上图 ( 来自 fluentd.org) 描述了我们传统的日志收集方案衍生出来的复杂性,容器平台作为基础运行环境,需要为所有业务提供统一的日志收集方案,如果继续沿用传统的思路,将面临诸多挑战。
传统日志是面向人设计,而容器平台避免人来直接查看日志文件
传统日志输出关心运行环境,而容器平台抽象运行环境
传统日志收集将日志输出到多个文件,而容器平台期望统一截获日志流
传统日志收集将采集和解析耦合,而容器平台不关心业务如何解读日志
从上述矛盾(或挑战)可以看到,如果不对日志系统的设计思路革新,推进容器化后将会有各种复杂的情况让我们疲于应付。我们期望日志的输出具有统一的结构化的格式,服务将日志输出到标准输出或标准错误 (12factor),不需要关心日志如何落地。运行环境截获日志并由统一的日志收集 agent 将日志过滤,处理,采集,通过日志传输组件(比如 kafka)分发给不同处理程序。
我们将上述理想情况称为现代日志收集方案,因此我们的目标则是从传统日志收集方案逐步转化为现代日志收集方案。由于日志是各个业务必备的组件,其改造过程注定复杂且耗时,中间需要过渡方案来适应不同的业务场景和使用需求,因此我们期望抽象出“统一日志层”将各式各样的日志来源适配起来,发送到可能的,功能不同的日志中心
统一日志层( unified-logging-layer)
统一日志层其实是 fluentd 提出来的概念:
Unified Logging Layer: Turning Data into Action (https://www.fluentd.org/blog/unified-logging-layer)
其基本思想是将日志抽象为 Producer 和 Consumer。 Producer 与 Consumer 可以有多种多样, fluentd 通过插件系统来适配不同的 Producer 和 Consumer。
关于 fluentd 本身,我们这里就不在赘述,有兴趣的同学可以参考 fluentd 的官方文档 https://docs.fluentd.org/v0.12/articles/quickstart
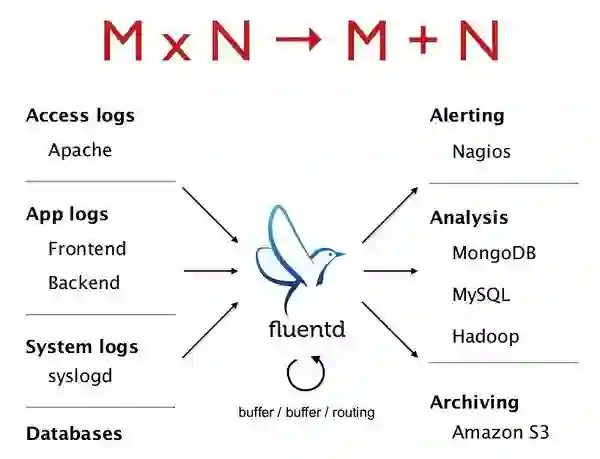
上图(来自 fluentd.org)可以看到, fluentd 抽象出日志的生产和消费之间的统一的一层,将 NxM 的复杂组合,变成 N+M。现实情况下,我们无法实现所有组件都达到“现代日志收集方案”的标准,并且在达到目标前,必定有各种各样的过渡阶段, fluentd 提供的统一日志层恰好为我们的过渡提供极大的灵活性,又能作为最终的“现代日志收集方案”,因此我们考虑引入 fluentd 作为容器化平台的日志收集组件。
fluentd 是一个成熟的开源项目,也是 Kubernetes 平台最常用的日志收集组件,其已经实现了“统一日志层”的设计思想,接下来的任务是考虑如何跟我们的业务,容器平台集成,如何落地 ...
总结
本文内容虽然比较长,但其核心思想却非常清晰,为了实现现代化的日志收集方案,我们有两个目标需要达成:
将日志打印到标准输出或标准错误,实现服务与运行环境解耦
大力推动业务日志结构化(比如 JSON),以适应日志输出从面向人,到面向机器的转变。
上述两个目标说起来比较容易,但要真正落地,还有诸多困难要克服,我们下一篇文章会讨论基于上述思路,如何设计我们日志收集方案的架构,如何实现集群级别的日志分组,如何适配不同的日志中心等,非常期待到时候跟大家一起交流。
号外
美图架构,专注于虚拟化、流媒体、云储存、通讯等基础设施建设领域,现急需相关领域爱好者加入,工作地点可自由选择北京、厦门、深圳。目前紧急岗位如下:
虚拟化底层研发工程师
Go 开发工程师
音视频编解码研究人员
有兴趣者请联系: yt@meitu.com or ryq@meitu.com
推荐阅读
本文作者任勇全,转载请注明出处,技术原创及架构实践文章,欢迎通过公众号菜单「联系我们」进行投稿。

54 个架构案例 49 位作者 2 年打磨
『高可用架构』第 1 卷 10 月上市
点击 阅读原文 抢先预订
高可用架构
改变互联网的构建方式

长按二维码 关注「高可用架构」公众号