16岁Kaggle老兵夺冠Kaggle地标检索挑战赛!

作者:anokas 来源:Kaggle、机器之心等
anokas 赢得了谷歌地标检索挑战赛,在 Reddit 上引起了非常多的讨论,大家都非常关心他的年龄以及是否有其他人帮助。不过在 anokas 的 Kaggle 主页中,他过去一年的活跃度非常高。虽然 anokas 这次与他的爸爸组成团队在图像检索挑战赛中获胜,但在他参与的 50 项挑战赛中有 40 项都是单独完成的。
anokas 两年前就已经开始参加 Kaggle 竞赛,在完成的 48 项竞赛中,他一共获得了 5 块金牌、7 块银牌和 5 块铜牌。除了这一项地标图像检索,他还获得了谷歌云与 YouTube-8M 视频理解挑战赛的第七名。以下是他排名比较靠前的竞赛:
除了上述获得的荣誉,anokas 昨天还在 Kaggle 分享了他们获胜的方案,如下机器之心将介绍这一份解决方案。
以下是我们团队在竞赛中所使用解决方案的细节总结,我们的解决方案包含两个主要的组件:第一个是创建一个高性能的全局描述子,以用奇异值向量表征数据集中的图像,第二个组件即构建一个高效的策略以匹配这些向量,从而搜索到最可能的匹配条目,并提交到排行榜。
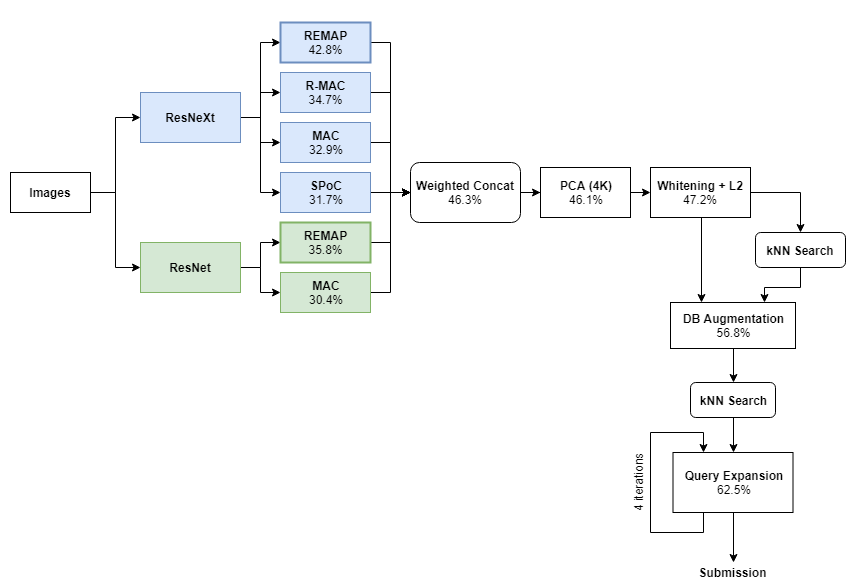
下图展示了整体的流程图,在每一个应用步骤中都标记了 LB 分数,后面我们详细介绍这些步骤。
全局描述子
我们解决方案的主要部分涉及到一些全局描述子,它们是描述整体图像的向量。整体架构首先从两个预训练的 CNN 模型开始(ResNet 和 ResNeXt),然后使用四种顶尖的聚合方法以从这些模型生成全局描述子。以下是每种方法及它们「原始」性能的简要细节,原始性能即不带查询扩展和数据库扩展等方法的性能:
基于区域熵的多层抽象池化(REMAP)[42.8% mAP]:这是我们全新设计的全局描述子,它聚合了来自不同卷积层的层级化深度特征,并训练表征多个互补的层级视觉抽象。我们计划在即将来到的 CVPR Workshop 中展示 REMAP 架构的细节。
最大卷积激活值(MAC)[32.9% mAP]:MAC 描述子编码了最后层中每一个卷积核的最大局部响应。在 MAC 架构中,ResNeXt 的最后卷积层会接一个最大池化层、L2 正则化层和 PCA+白化层。
卷积的池化和(SPoC)[31.7% mAP]:在 SPoC 流程中,ResNeXt 的最后卷积层会接一个池化求和层、L2 正则化层和 PCA+白化层。
卷积的区域最大激活值(RMAC)[34.7% mAP]:在 RMAC 中,ResNeXt 的最后卷积特征图是通过在多尺度重叠区域上做最大池化而得出。基于区域的描述子是 L2 正则化、PCA+白化和另一个 L2 正则化,描述子最后会求和汇聚到一个单描述子。
基本的 CNN 网络(ResNet 与 ResNeXt)都是在 ImageNet 数据集上进行预训练,并在地标数据集上进行精调。该地标数据集由 Babenko 等人开发,包含了大约 120k 张图像和 650 个著名的地标。
这个数据集中的图像是通过在一个图像搜索引擎进行文本查询而收集的,没有经过彻底验证。因此,它们包含大量的无关图像,我们将其过滤出来并删除了。这个过程是半自动化的,依赖于使用 Hessian-affine 检测器检测到并使用 RVD-W 描述子聚集的密集 SIFT 特征。清理完成之后,数据集中还剩下 650 个地标的 25000 张图像。
我们没有使用来自地标分类姊妹竞赛的数据来训练,因为我们想弄清楚该解决方案泛化到其它数据集的能力(相对于为该数据集而特定设计的解决方案)。
组合描述子
我们最终的全局描述子通过级联 6 个按上述方式训练调整好的全局描述子的方式来构建(下列括号中是 LB 分数):
ResNeXt+REMAP (42.8%)
ResNeXt+RMAC (34.7%)
ResNeXt+MAC (32.9%)
ResNeXt+SPoC (31.7%)
ResNet+REMAP (35.8%)
ResNet+MAC (30.4%)
我们将描述子通过固定的 L2 范数缩放,从而为每个描述子分配权重,并按下列方式级联描述子:
XG = [2× ResNeXt+REMAP; 1.5× ResNeXt+RMAC; 1.5× ResNeXt+MAC; 1.5× ResNeXt+SPoC; ResNet+MAC; ResNet+REMAP]
权重是点对点选取的,以反映每个方法的相对性能。之后,我们执行 PCA,将描述子的维度降低到 4K(不只是为了节约计算量,还为了删除噪声维度),并使用白化处理,使所有维度具备相同的方差。尽管 PCA 和白化只带来少许改进,但它将查询扩展步骤的结果提升了几个百分点。
最近邻搜索
在创建好描述子之后,每张图像都用 4096 维的描述子来表征。接下来,我们使用穷尽 k 最近邻搜索来找出每张图像的 top 2500 近邻和 L2 距离。在这一阶段提交每张测试图像的 top 100 近邻获得了 47.2% 的分数。
这一步使用优化 NumPy 代码来实现,耗时两小时为 120 万张图像中的每一张找出 top 2500 近邻(我们需要索引集执行最近邻,以备后续使用)。
数据库增强
下一步是执行数据库增强(DBA),即用图像描述子的加权组合及其 top 10 近邻来替换数据库(包括查询)中的每个图像描述子。目标是通过利用近邻特征来提高图像表征的质量。更准确地来说,我们对描述子执行加权求和,使用以下函数来计算权重:
weights = logspace(0, -1.5, 10)
有趣的是,尽管我们在其他数据集上发现,使用两个以上近邻来增强查询会损害分数,而 10 个近邻对数据集中的查询和数据库图像来说却是最好的。
我们需要注意:DBA 是该流程的最后一项,尽管它大大提高了分数,但是与查询扩展步骤结合时,改进仅有 1-2%。我们认为原因在于数据库扩展与查询扩展方法的第一级别类似。
查询扩展
查询扩展是图像检索问题中的基础技术,通常会带来性能的极大提升。它遵循该原则运行:如果图像 A <-> B、B <-> C,则 A <-> C(即使描述子 A 和 C 并非明确匹配)。一个简单的示例是有三个部分重叠的图像的情况:
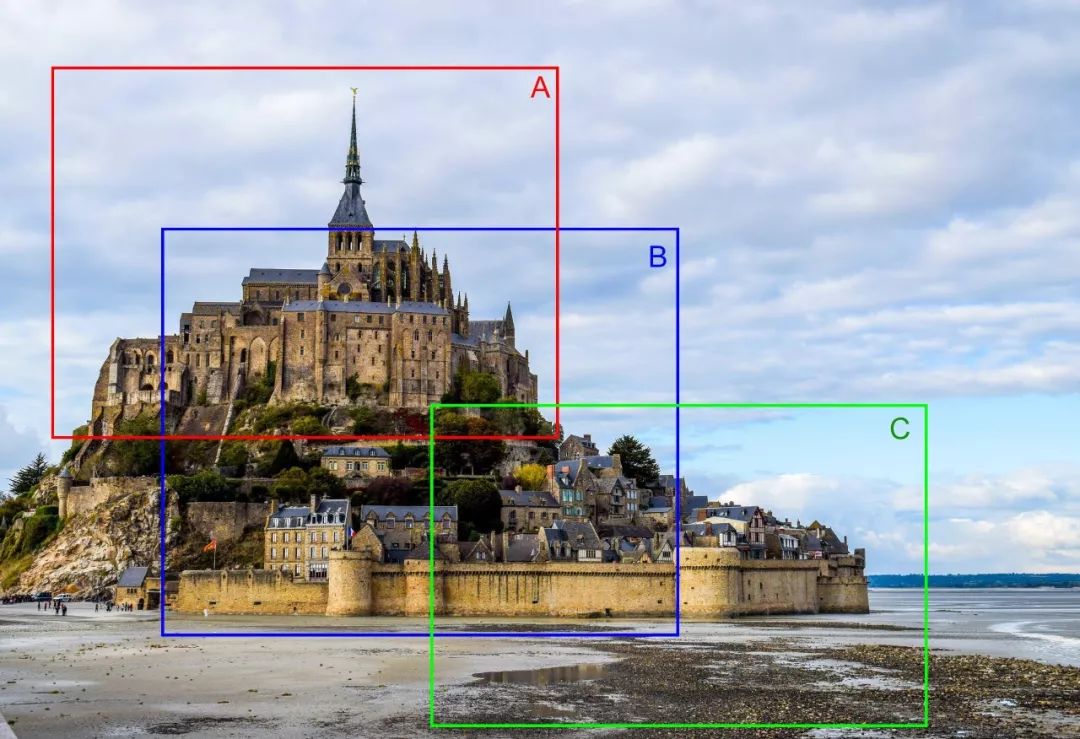
在这种情况下,查询扩展机制能够帮助我们匹配 A 和 C 在同一个场景中,尽管它们的描述子(尤其是全局描述子)可能非常不匹配。这对其他情况也有好处,比如我们有多张视角或亮度条件略微不同的图像时,中间图像可以帮助我们将它们连接起来。
在这场竞赛中,我们设计了一种新的快速技术用于查询扩展,它可以通过多个中间步骤递归地运行来捕捉图像之间的长程连接(long-distance connection)。这使得该技术非常适用于这类问题,因为很多地标有很多图像,只有一张图像需要与查询相匹配,同一地标的其它图像被附加到 top-100 列表中。
我们决定不在这里讨论具体的方法,而仅限于解释,在之后的论文中将深入介绍方法。但其基本原则和其它成熟的查询扩展技术是相同的。我们的查询扩展在运行一次迭代后带来了大约 11% 的提高,在递归运行(30 分钟的运行时)后带来了 14% 的提高(当结合 DBA 的时候有所降低)。
简化模型
在产品级机器学习环境中,由于收益递减原则,很少使用怪兽级别的多模型集成。通常使用较小规模的模型集成就可以实现大部分性能。我们期望得到原来解决方案的简化版本,其仅使用 ResNet-REMAP 和查询扩展,在从下载数据到提交结果不到 12 小时的运行时内(在 4 块 GPU 上)达到 56%~57% 的分数,由于它并不需要特定地为该竞赛进行训练,为此也带来了很多好处。

未发挥作用的方法
局部描述子(local descriptor):在竞赛中,我们对此最为吃惊。我们尝试了多种基于不同局部描述子的方法,包括使用或不使用几何验证的方法,例如用于对我们的结果重排序(降低性能),或用于遍历顶部的数千个全局近邻来寻找可靠的、被基于 CNN 的全局描述子所忽略的局部匹配(有帮助,但对性能的提高不到 0.1%)。我们很好奇其它团队是否在这场竞赛中利用了局部描述子的威力。可能基于 CNN 的全局描述子的性能太好,以至于局部描述子已经过时了?
处理旋转图像:浏览一下数据集,我们就可以发现有很多图像都经过了旋转。我们以多种方式考虑了这个问题,例如在 kNN 过程中对比旋转和非旋转描述子,并为每对图像取最接近的匹配,然而这并没有提高我们的分数。这可能是因为这个数据集有很多的干扰项,假正类的增加超过了真正类的收益。
集成:我们尝试了多种方法来结合不同的模型和方法,例如排序平均和交错预测等,然而得到的收益非常小。也许在解决方案的早期阶段进行模型集成会比在最终阶段集成更好。
原文链接:https://www.kaggle.com/c/landmark-retrieval-challenge/discussion/57855
- 加入AI学院学习 -

点击“ 阅读原文 ”进入学习


