ECCV 2018论文解读 | DeepVS:基于深度学习的视频显著性方法

作者丨蒋铼
学校丨北京航空航天大学在校博士,大不列颠哥伦比亚大学联合培养博士
研究方向丨计算机视觉
本文概述了来自北京航空航天大学徐迈老师组 ECCV 2018 的工作 DeepVS: A Deep Learning Based Video Saliency Prediction Approach。全文主要贡献点有三:
建立了大规模普适视频的眼动数据库,包含了 158 子类的 538 个视频,以及详尽的数据分析;
构造了基于运动物体的静态结构 OM-CNN 用于检测帧内显著性;
构造了动态结构 SS-ConvLSTM 用于预测视频显著性的帧间转移,同时考虑到了显著性的稀疏先验和中心先验。
■ 论文 | DeepVS: A Deep Learning Based Video Saliency Prediction Approach
■ 链接 | https://www.paperweekly.site/papers/2329
■ 源码 | https://github.com/remega/OMCNN_2CLSTM

▲ 图1. 本文海报
背景
和图片显著性检测不同,现在很少有基于深度学习的视频显著性检测方法。这其中有很大一部分原因是由于缺乏眼动数据,而采集人眼在视频中的视觉关注点是一件开销很大的事情。
如图 2 所示,已有的数据普遍规模较小,且存在一些如分辨率不高,关注点采样率低的问题。而大规模眼动数据库如 Hollywood(Mathe and Sminchisescu, 2015)中的视频是任务驱使的(task-driven),均是用于动作识别任务的电影片段,而不是普适性视频(general videos)。相比于任务驱使的显著性检测,普适性视频的显著性检测有更多应用场景,然而此类显著性检测方法和数据库都十分匮乏。
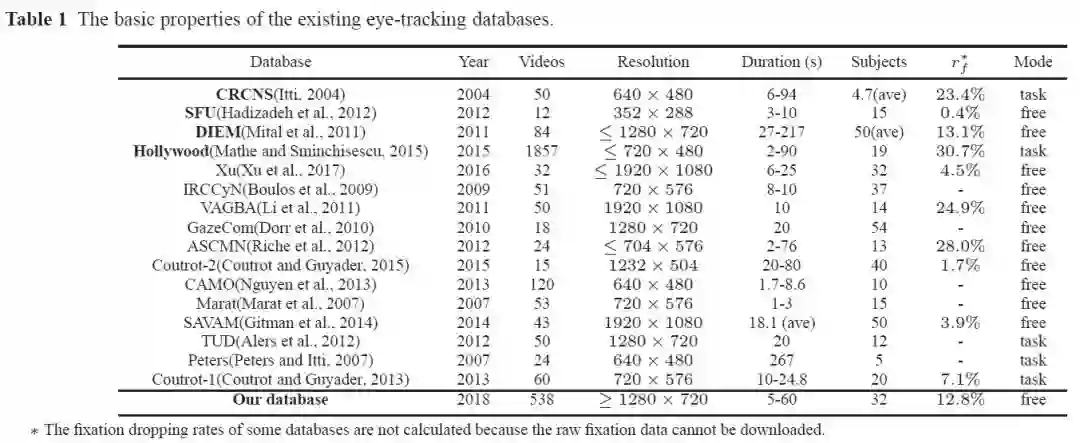
▲ 图2. 已有眼动数据库总结
数据库与分析
为了保证视频内容的丰富性,我们粗糙构造了基于视频内容关键字的动态树,并基于此在 Youtube 上下载视频,并基于实际情况修改动态树。最终动态树结构见图 3,共计 158 个视频子类,538 个视频片段(部分实例见图 4)。

▲ 图3. 动态树

▲ 图4. LEDOV视频库样例
之后,使用 Tobii TX300 眼动仪采集 32 个被试者在这些视频上的人眼视觉关注点,共计采集 5,058,178 个关注点。
基于采集到的眼动数据,我们进行了数据分析,得到了 3 个非常直观的发现:1)显著性与物体相关性较高;2)显著性与运动的物体以及物体中的运动部位相关性高;3)显著性在帧间会存在平滑的转移。数据分析见图 5。
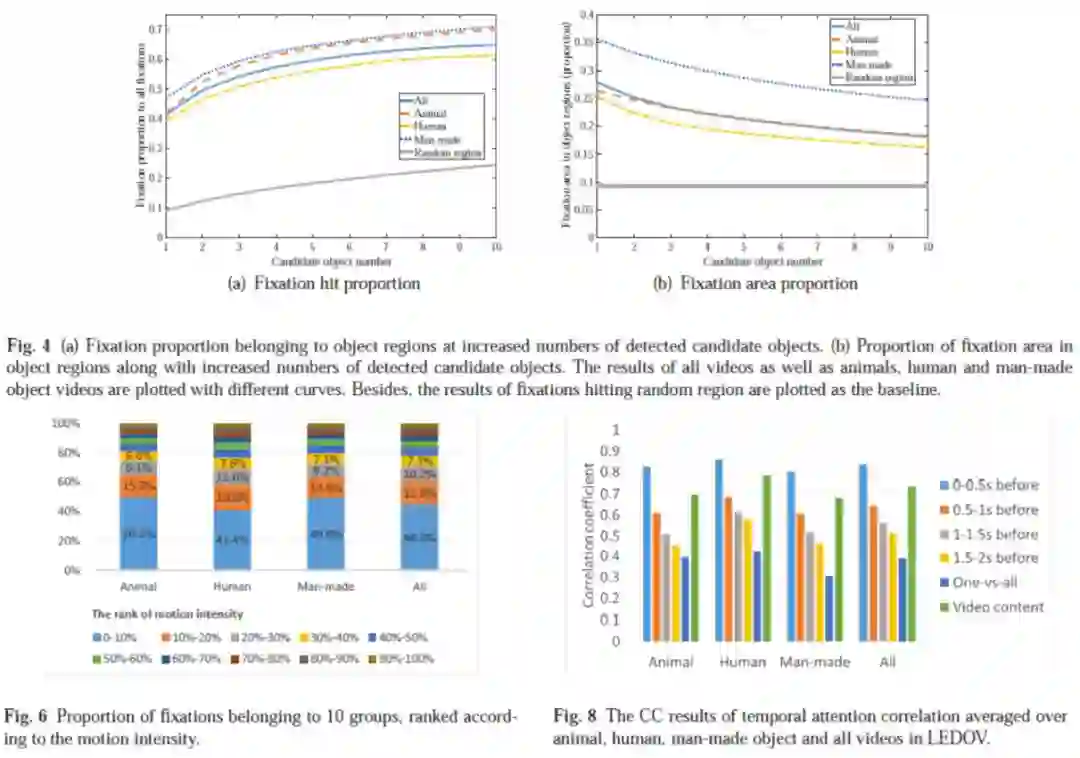
▲ 图5. 数据库分析
方法
为此,我们根据第一二点发现提出了 CNN 结构,OM-CNN(结构见图 6)。
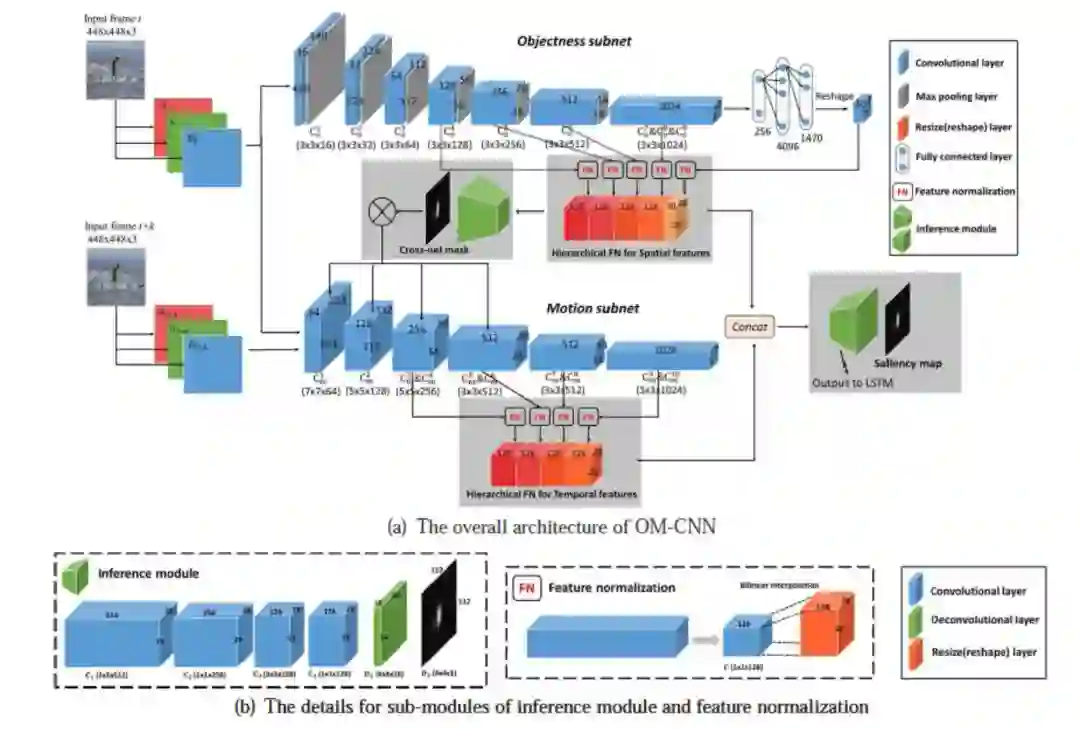
▲ 图6. OM-CNN结构
此网络由 Objectness subnet 与 Motion subnet 构成,其中 Objectness subnet 使用了 YOLO 的结构和预训练参数,用于提取带有物体信息的空间特征。Motion subnet 使用 FlowNet 的结构和预训练参数,用于提取带有运动信息的空间特征。
为了让网络在提取运动特征的时候更加关注在物体区域上(发现 2),我们利用 Objectness subnet 的输出特征作为输入,生成了一个 cross-net mask 作用在 Motion subnet 的卷积层上。我们认为,在训练过程中 cross-net mask 可以很好的表示物体区域。

▲ 图7. Cross-net mask可视化
图 7 是对 cross-net mask 的一些可视化结果,第一行是输入帧,第二行是真实人眼关注点(Ground truth),第三行使我们算法的最终输出,最后四行是在训练过程中 cross-net mask 的变化。我们可以看到,cross-net mask 能逐渐定位到物体区域,且在之后训练的过程中变化不大,与预期结果相似。
最终我们提取了两个子网络的多尺度特征,拼接在一起,来预测帧内的显著性。值得注意的是,OM-CNN 与之后的动态结构是分开训练的,此时的显著图仅用于训练 OM-CNN,而 OM-CNN 的输出特征将被用于动态结构的输入。
根据第三点发现,我们设计的动态结构 SS-ConvLSTM(见图 8)。
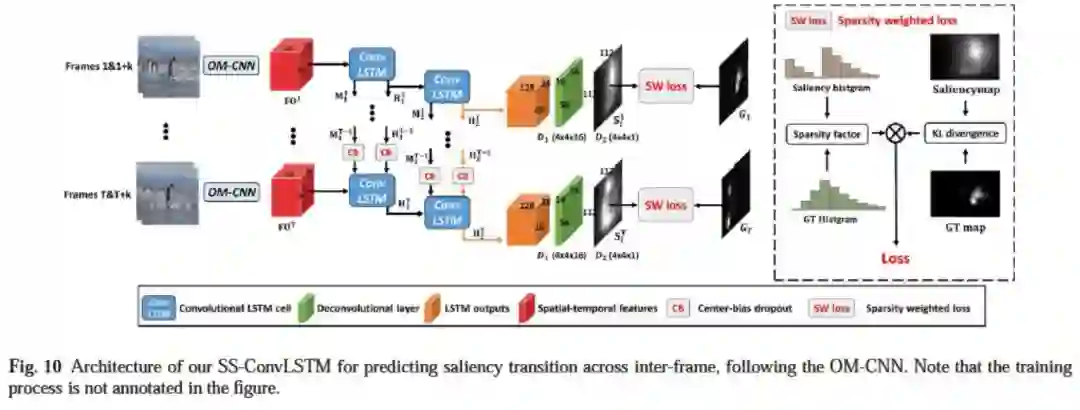
▲ 图8. SS-ConvLSTM结构
其主体结构是一个双层的卷积 LSTM,用于产生像素级的输出。和传统卷积 LSTM 不同的是,SS-ConvLSTM 考虑到了基于显著性的先验知识:中心先验和稀疏先验。中心先验指的是人们在看视频或者图片的时候往往容易关注到中心的位置。
为此,我们提出了 Center-bias Dropout(图 9,详细见原文)。
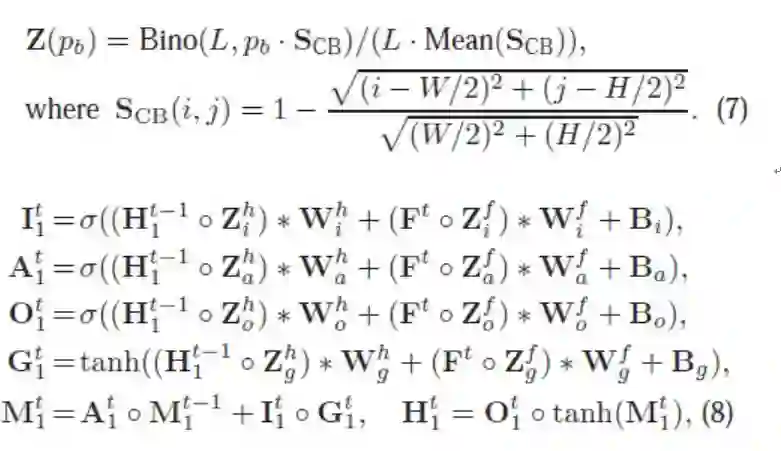
▲ 图9. Center-bias Dropout
和普通 Dropout 不同,Center-bias Dropout 中所有像素的 dropout rate 并不是相同的,而是基于一个 Center-bias map。简单来说,中心区域像素的 dropout rate 可以比边界区域的 dropout rate 低很多。
稀疏先验指的是人眼关注点会存在一定的稀疏性(见图 11 第二行),而大部分已有算法忽视了这个稀疏性(见图 11 的 4-13 行),产生过于稠密的显著图。为此,我们设计了基于稀疏性的损失函数(图 10,详细见原文)。
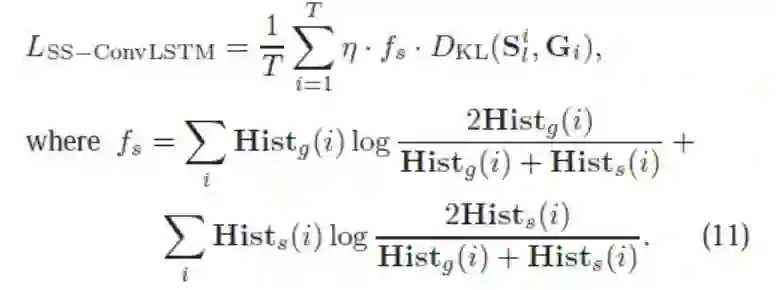
▲ 图10. 基于稀疏性的损失函数
在这个损失函数中,不仅计算了显著图和人眼关注点图的差异,同时计算了这两张图的灰度直方图分布的差异,使得训练过程中,输出显著图的稀疏度趋于真实情况。
结果
图 11 与图 12 分别展示 DeepVS 和 10 种对比算法在 LEDOV 上的主观和客观实验结果。可以看到,DeepVS 生成的显著图更加接近人眼关注点。同时,在 AUC, NSS, CC, KL 这四种评价指标上,DeepVS 也优于对比算法。

▲ 图11. 主观实验结果
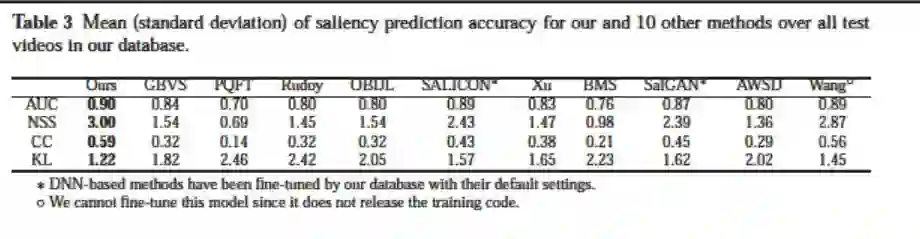
▲ 图12. 客观实验结果
原文也罗列了 DeepVS 和对比算法在另外两个常用眼动数据库 DIEM 和 SFU 上的实验结果。DeepVS 仍超过所有对比算法,有不错的泛化能力。图 13 展示了 DeepVS 的溶解实验,可以看出,DeepVS 中提出的网络结构或者组件均对最终的结果有所增益。
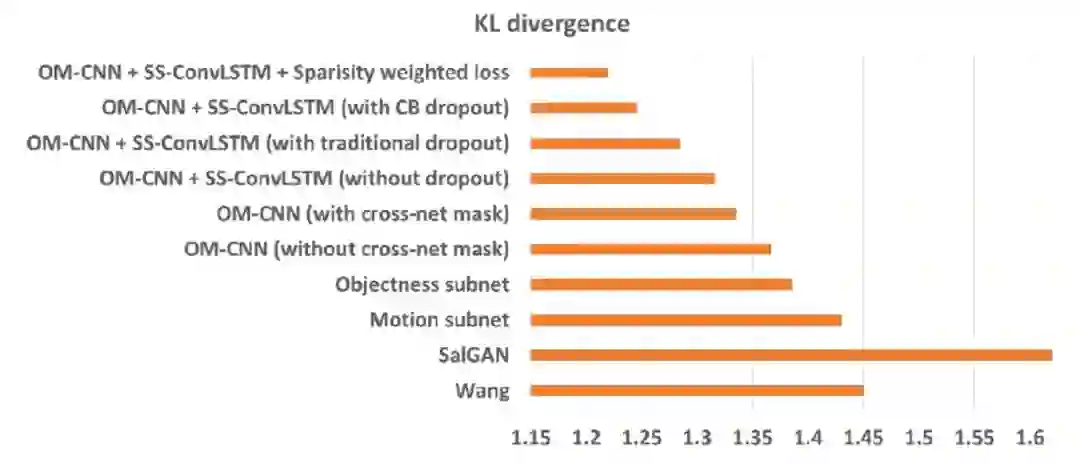
▲ 图13. 溶解实验

点击以下标题查看更多论文解读:

让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢? 答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
📝 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
📬 投稿邮箱:
• 投稿邮箱:hr@paperweekly.site
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。

▽ 点击 | 阅读原文 | 下载论文 & 源码


