【学习】 用IDCNN和CRF做端到端的中文实体识别(附代码)
转自:Guan Wang
实体识别和关系抽取是例如构建知识图谱等上层自然语言处理应用的基础。实体识别可以简单理解为一个序列标注问题:给定一个句子,为句子序列中的每一个字做标注。因为同是序列标注问题,除去实体识别之外,相同的技术也可以去解决诸如分词、词性标注等不同的自然语言处理问题。
说到序列标注直觉是会想到RNN的结构。现在大部分表现最好的实体识别或者词性标注算法基本都是biLSTM的套路。就算是上篇提到的关系抽取这种本来应该很适合CNN来做的文本分类的问题,我们也用了biGRU加字级别与句子级别的双重Attention结构解决掉了。就像Ruder在他的博客 Deep Learning for NLP Best Practices 里面说的,There has been a running joke in the NLP community that an LSTM with attention will yield state-of-the-art performance on any task.
为了换换口味,我们基于2017年7月一篇paper Fast and Accurate Entity Recognition with Iterated Dilated Convolutions, 介绍一个使用 Iterated Dilated CNN加CRF的模型来做中文实体识别的方法。
代码主要是基于开源项目zjy-ucas/ChineseNER开发,在原来biLSTM模型的基础上增加了IDCNN模型的选项,而IDCNN的模型参考了koth/kcws的实现。感谢!两位大牛都基于tensorflow写代码,虽然风格迥异,代码却都非常漂亮!
IDCNN加CRF模型
对于序列标注来讲,普通CNN有一个劣势,就是卷积之后,末层神经元可能只是得到了原始输入数据中一小块的信息。而对NER来讲,整个句子的每个字都有可能都会对当前需要标注的字做出影响。为了覆盖到输入的全部信息就需要加入更多的卷积层, 导致层数越来越深,参数越来越多,而为了防止过拟合又要加入更多的Dropout之类的正则化,带来更多的超参数,整个模型变得庞大和难以训练。因为CNN这样的劣势,大部分序列标注问题人们还是使用biLSTM之类的网络结构,尽可能使用网络的记忆力记住全句的信息来对单个字做标注。
但这带来的问题是,biLSTM毕竟是一个序列模型,在对GPU并行计算的优化上面不如CNN那么强大。如何能够像CNN那样给GPU提供一个火力全开的战场,而又像LSTM这样用简单的结构记住尽可能多的输入信息呢?
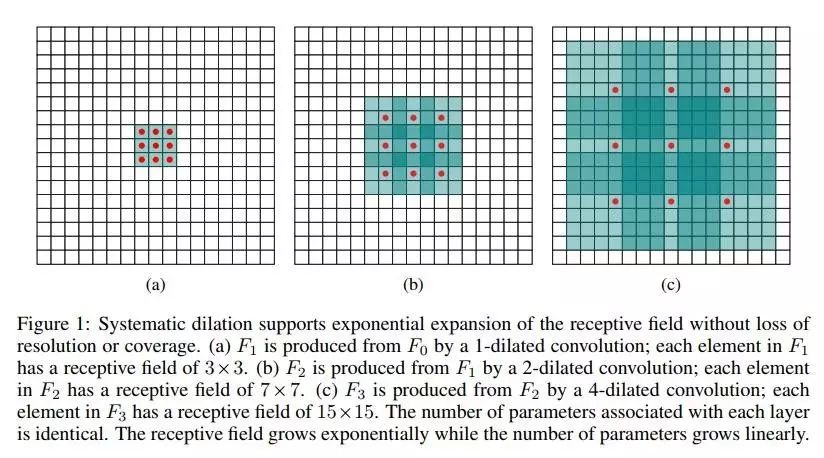
Fisher Yu and Vladlen Koltun 2015 提出了一个dilated CNN的模型,意思是“膨胀的”CNN。想法其实很简单:正常CNN的filter,都是作用在输入矩阵一片连续的位置上,不断sliding做卷积。dilated CNN为这片filter增加了一个dilation width,作用在输入矩阵的时候,会skip掉所有dilation width中间的输入数据;而filter矩阵本身的大小仍然不变,这样filter获取到了更广阔的输入矩阵上的数据,看上去就像是“膨胀”了一般。
具体使用时,dilated width会随着层数的增加而指数增加。这样随着层数的增加,参数数量是线性增加的,而receptive field却是指数增加的,可以很快覆盖到全部的输入数据。
图片来自 Fisher Yu and Vladlen Koltun 2015
原文链接:
http://www.crownpku.com//2017/08/26/用IDCNN和CRF做端到端的中文实体识别.html





