独家 | creditR 的基于实践的导论:一个神奇的改良信用风险评分和验证的R包(附代码)

作者:Ayhan Dis
翻译:张睿毅
校对:丁楠雅
本文约3200字,建议阅读10+分钟。
本文介绍了关于creditR包的相关基础知识,并通过使用creditR深入研究一个全面的例子进行实际操作。
背景介绍
机器学习正在扰乱多个不同的行业。受影响最大的行业之一就是:金融业。
机器学习的主要目标是欺诈检测、客户细分、员工或客户保留等。我们将在本文中介绍信用风险评分。
“信用评分是放款人和金融机构为获得一个人的信用度而进行的统计分析。出借人通过信用评分决定是否延长或拒绝信用。”
--投资银行
机器学习算法通常被开发成挑战者模型,因为这是一个需要满足法规要求的领域。这让我思考——我如何才能让从事该领域工作的专业人员更容易理解这些模型?
creditR 包就应运而生了!它允许你在机器学习应用程序之前轻松创建信用风险评分的基本模型。此外它还含有一些可用于验证这些进程的函数。
该包旨在促进变量分析、变量选择、模型开发、模型校准、评级尺度开发和模型验证方法的应用。通过定义的函数,这些方法可以快速应用于所有建模数据或特定变量。
在本文中,我们将首先了解creditR包的基本知识。然后,我们将通过使用creditR深入研究一个全面的例子进行实际操作。
注:该方案是为信贷风险专业人士提供的。使用该软件包需要具备信贷风险评分方法的基本知识。
目录
一、为什么要用creditR?
二、开始使用creditR
三、creditR内部的一系列函数
四、creditR包的应用
一、为什么要用creditR
随着对该领域机器学习模型的需求增加,对信贷风险模型的认识正在迅速转变。然而,许多监管者对机器学习技术仍然非常谨慎。可以推测:在这个转换阶段,机器学习算法将与传统方法一起进行。
一旦机器学习算法在挑战领域惯例的同时产生了比传统方法更强大的结果,监管者就可以信任。此外,解释机器学习算法的新方法可能有助于创建一个更透明的过程。
creditR软件包既可以自动使用传统方法,也可以验证传统和机器学习模型。
二、开始使用creditR
为了安装creditR包,你应该安装devtools包。可以通过运行以下代码安装devtools包:
install.packages("devtools", dependencies = TRUE)
可以使用devtools包中的“install_github”功能安装creditr包:
library(devtools)
devtools::install_github("ayhandis/creditR")
library(creditR)
三、creditR内的一系列函数
包下面列出了可用的功能:
ls("package:creditR")
输出:

四、creditR包的一项应用
我们已经熟悉了理论方面的内容。现在我们开始实践吧!
下面分享了creditR的一个示例应用程序,研究如何使用包中提供的功能执行信贷风险评分中的一些常见步骤。
在编写本例时,考虑了实际的做法。
一般应用程序的结构分为两个主题,即建模和模型验证,在注释行中可以看到有关相应代码所做操作的详细信息。
本文中只共享了重要的输出。
这个R脚本旨在使creditR包更容易理解。获得高精度模型不在本研究范围内。
# Attaching the library
library(creditR)
#Model data and data structure
data("germancredit")
str(germancredit)
#Preparing a sample data set
sample_data <- germancredit[,c("duration.in.month","credit.amount","installment.rate.in.percentage.of.disposable.income", "age.in.years","creditability")]
#Converting the ‘Creditability’ (default flag) variable into numeric type
sample_data$creditability <- ifelse(sample_data$creditability == "bad",1,0)
#Calculating the missing ratios
missing_ratio(sample_data)
输出:
#Splitting the data into train and test sets
traintest <- train_test_split(sample_data,123,0.70)
train <- traintest$train
test <- traintest$test
WOE变换是一种结合变量与目标变量的关系将变量转化为分类变量的方法。下面的“WoeRules”对象包含WOE的规则。
在woe.binning.deploy 函数的帮助下,规则得以在数据集上运行。我们需要的变量通过woe.get.clear.data函数分配给“train-woe”对象。
#Applying WOE transformation on the variables
woerules <- woe.binning(df = train,target.var = "creditability",pred.var = train,event.class = 1)
train_woe <- woe.binning.deploy(train, woerules, add.woe.or.dum.var='woe')
#Creating a dataset with the transformed variables and default flag
train_woe <- woe.get.clear.data(train_woe,default_flag = "creditability",prefix = "woe")
#Applying the WOE rules used on the train data to the test data
test_woe <- woe.binning.deploy(test, woerules, add.woe.or.dum.var='woe')
test_woe <- woe.get.clear.data(test_woe,default_flag = "creditability",prefix = "woe")
信息值和单变量基尼系数可以作为变量选择方法。一般来说,IV的阈值为0.30,单变量基尼的阈值为0.10。
#Performing the IV and Gini calculations for the whole data set
IV.calc.data(train_woe,"creditability")
输出:

Gini.univariate.data(train_woe,"creditability")
输出:

#Creating a new dataset by Gini elimination. IV elimination is also possible
eliminated_data <- Gini_elimination(train_woe,"creditability",0.10)
str(eliminated_data)
输出:

现实生活中有太多的变量无法用相关矩阵来管理,因此常使用聚类以确定具有相似特征的变量。由于变量的数量很少,这种特殊的聚类示例没有意义,但通常情况下,该方法在具有大量变量的数据集中非常有用。
#A demonstration of the functions useful in performing Clustering
clustering_data <- variable.clustering(eliminated_data,"creditability", 2)
clustering_data
输出:

# Returns the data for variables that have the maximum gini value in the dataset
selected_data <- variable.clustering.gini(eliminated_data,"creditability", 2)
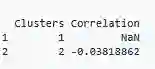
在某些情况下,集群的平均相关性很重要,因为集群的数量可能设置不正确。因此,如果集群具有较高的平均相关性,则应该对其进行详细检查。相关性值(在集群1中的唯一变量)是NaN。
correlation.cluster(eliminated_data,clustering_data,variables = "variable",clusters = "Group")
输出:
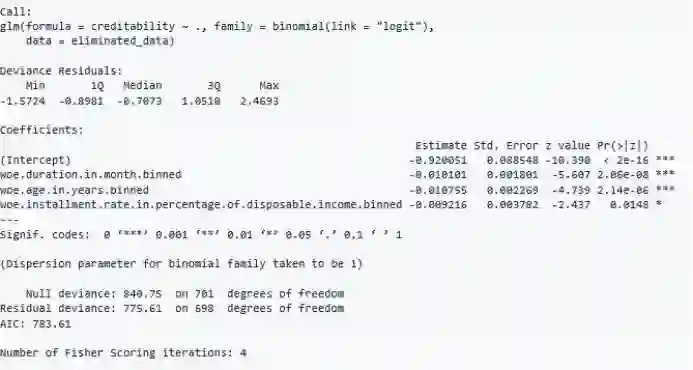
包含在数据集中的变量形成了一个模型。当模型摘要检查变量时,这些变量似乎是有意义的。然后,借助于“woe.glm.feature.importance”函数,变量的权重得以计算。实际上,权重是根据单个单位变化对概率的影响来计算的。
#Creating a logistic regression model of the data
model= glm(formula = creditability ~ ., family = binomial(link = "logit"), data = eliminated_data)
summary(model)
输出:
#Calculating variable weights
woe.glm.feature.importance(eliminated_data,model,"creditability")
输出:

#Generating the PD values for the train and test data
ms_train_data <- cbind(eliminated_data,model$fitted.values)
ms_test_data <- cbind(test_woe[,colnames(eliminated_data)], predict(model,type = "response", newdata = test_woe))
colnames(ms_train_data) <- c("woe.duration.in.month.binned","woe.age.in.years.binned","woe.installment.rate.in.percentage.of.disposable.income.binned","creditability","PD")
colnames(ms_test_data) <- c("woe.duration.in.month.binned","woe.age.in.years.binned","woe.installment.rate.in.percentage.of.disposable.income.binned","creditability","PD")
在现实生活中,机构使用评级尺度而不是连续的PD值。由于一些监管问题或为了适应不断变化的市场/投资组合条件,模型会根据不同的中心趋势进行校准。
包中含有回归和贝叶斯校正方法。利用“calibration object$calibration_formula”代码,可以得到嵌入企业系统中进行校准的数值函数作为输出。
#An example application of the Regression calibration method. The model is calibrated to the test_woe data
regression_calibration <- regression.calibration(model,test_woe,"creditability")
regression_calibration$calibration_data
regression_calibration$calibration_model
regression_calibration$calibration_formula
输出:
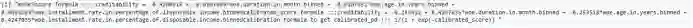
在评定量表上采用贝叶斯校正方法。借助“master.scale”函数,我们可以轻松创建评分量表。然而,在现实生活中,评级尺度只能在多次尝试之后创建。
摘要将添加到输出中。运行R脚本可以看到详细信息。此外,本例的目的仅仅是在本研究范围内引入函数,因此PD值不会单调增加。
#Creating a master scale
master_scale <- master.scale(ms_train_data,"creditability","PD")
master_scale
输出:
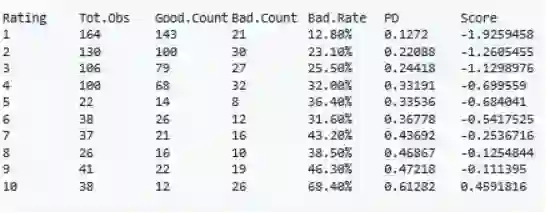
为了应用贝叶斯校正,在数据集中创建了分数变量。然后将评分表校准到5%的中心趋势。
#Calibrating the master scale and the modeling data to the default rate of 5% using the bayesian calibration method
ms_train_data$Score = log(ms_train_data$PD/(1-ms_train_data$PD))
ms_test_data$Score = log(ms_test_data$PD/(1-ms_test_data$PD))
bayesian_method <- bayesian.calibration(data = master_scale,average_score ="Score",total_observations = "Total.Observations",PD = "PD",central_tendency = 0.05,calibration_data = ms_train_data,calibration_data_score ="Score")
#After calibration, the information and data related to the calibration process can be obtained as follows
bayesian_method$Calibration.model
bayesian_method$Calibration.formula
输出:

在实际应用中,对于不熟悉风险管理的员工来说,很难理解概率的概念。因此,需要创建缩放分数。这可以通过使用“scalled.score”函数来实现。
#The Scaled score can be created using the following function
scaled.score(bayesian_method$calibration_data, "calibrated_pd", 3000, 15)
在建模阶段之后,进行模型验证,以验证不同的期望,如模型的准确性和稳定性。在现实生活中,定性验证过程也被应用。
注:模型校准仅用于说明。模型验证测试按如下所示通过原始主尺度进行。
在逻辑回归模型中,应考虑多重共线性问题。虽然使用了不同的阈值,但大于5的vif值表示存在此问题。
#Calculating the Vif values of the variables.
vif.calc(model)
输出:
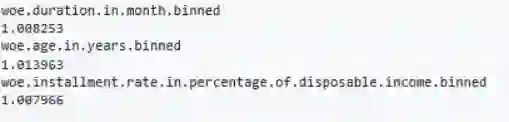
一般来说,基尼系数的可接受下限为0.40。但是,这可能会因模型类型而异。
#Calculating the Gini for the model
Gini(model$fitted.values,ms_train_data$creditability)
输出:
0.3577422
#Performing the 5 Fold cross validation
k.fold.cross.validation.glm(ms_train_data,"creditability",5,1)
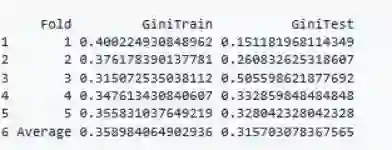
输出:
#The KS test is performed on the distributions of the estimates for good and bad observations
Kolmogorov.Smirnov(ms_train_data,"creditability","PD")
Kolmogorov.Smirnov(ms_test_data,"creditability","PD")
评分卡通常在长期基础上进行修订,因为这一过程会产生重要的运营成本。因此,模型的稳定性会降低修改的必要性。此外,机构希望模型稳定,因为这些模型被用作许多计算的输入,如减值、资本、风险加权资产等。
系统稳定性指标是用来衡量模型和变量稳定性的一种测试。大于0.25的SSI值表明变量稳定性受到损害。
#Variable stabilities are measured
SSI.calc.data(train_woe,test_woe,"creditability")
输出:

由于主量表的主要目的是区分风险,所以HHI测试测量主量表的浓度。超过0.30 HHI值表示浓度高。这可能是由于建模阶段或主比例的创建不正确。
#The HHI test is performed to measure the concentration of the master scale
Herfindahl.Hirschman.Index(master_scale,"Total.Observations")
输出:
0.1463665
在“anchor.point”函数的帮助下,测试默认速率是否与预期水平的平均PD兼容。
#Performing the Anchor point test
Anchor.point(master_scale,"PD","Total.Observations",0.30)
输出:

卡方检验也可用作校准试验。“chisquare.test”函数可用于在指定的置信水平下执行测试。
#The Chi-square test is applied on the master scale
chisquare.test(master_scale,"PD","Bad.Count","Total.Observations",0.90)
输出:

二项检验也可以作为一种校准检验。单尾二项检验通常用于IRB模型,而双尾检验则用于IFRS 9模型。但除IRB外,双尾检验更方便通用。
#The Binomial test is applied on the master scale
master_scale$DR <- master_scale$Bad.Count/master_scale$Total.Observations
Binomial.test(master_scale,"Total.Observations","PD","DR",0.90,"one")
输出:
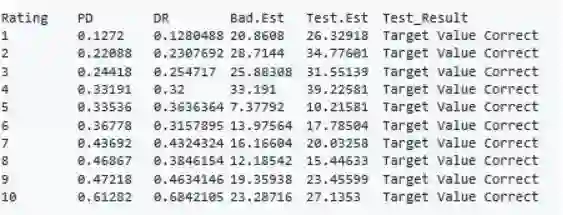
需要管理建模和模型验证,以确保连续性。当R环境被正确管理时,这个可管理的建模和验证环境可以很容易地由机构提供。
机构正在使用开放源代码环境(如具有大数据技术的R或Python)设计更高效的业务流程。从这个角度来看,creditR为建模和验证方法的应用提供了组织上的便利。
最后几点
creditR软件包为用户提供了许多执行传统信用风险评分的方法,以及一些用于测试模型有效性的方法,这些方法也可应用于ML算法。此外,由于该包在传统方法的应用中提供了自动化,因此可以降低这些过程的操作成本。
此外,可以将这些模型与机器学习模型进行比较,以证明ML模型也满足监管要求,满足这些要求是ML模型应用的前提。
修复Bug以及有关作者的信息

Ayhan Dis是一名高级风险顾问。他负责咨询项目,如国际财务报告准则9/IRB模型开发和验证,以及高级分析解决方案,包括欺诈分析、客户分析和风险分析等领域的ML/DL,熟练使用Python、R、Base SAS和SQL。
在他的工作历程中,他使用过各领域如Twitter、天气、信用风险、电时价格、股票价格的数据和客户数据,为银行、能源、保险、金融和制药行业的客户提供解决方案。
作为一个数据科学爱好者,他认为,建立一个人的技术能力并不是数据科学真正的刺激,而是将数据科学与大数据融合在一起,通过人工智能揭示与商业过程相结合的洞察力。
请通过下面共享的电子邮件地址通知作者你在使用包时遇到的错误。
https://github.com/ayhandis
https://www.linkedin.com/in/ayhandis/
disayhan@gmail.com
原文标题:
Hands-On Introduction to creditR: An Amazing R Package to Enhance Credit Risk Scoring and Validation
原文链接:
https://www.analyticsvidhya.com/blog/2019/03/introduction-creditr-r-package-enhance-credit-risk-scoring-validation-r-codes/
译者简介

张睿毅,北京邮电大学大二物联网在读。我是一个爱自由的人。在邮电大学读第一年书我就四处跑去蹭课,折腾整一年惊觉,与其在当下焦虑,不如在前辈中沉淀。于是在大二以来,坚持读书,不敢稍歇。资本主义国家的科学观不断刷新我的认知框架,同时因为出国考试很早出分,也更早地感受到自己才是那个一直被束缚着的人。太多真英雄在社会上各自闪耀着光芒。这才开始,立志终身向遇到的每一个人学习。做一个纯粹的计算机科学里面的小学生。
翻译组招募信息
工作内容:需要一颗细致的心,将选取好的外文文章翻译成流畅的中文。如果你是数据科学/统计学/计算机类的留学生,或在海外从事相关工作,或对自己外语水平有信心的朋友欢迎加入翻译小组。
你能得到:定期的翻译培训提高志愿者的翻译水平,提高对于数据科学前沿的认知,海外的朋友可以和国内技术应用发展保持联系,THU数据派产学研的背景为志愿者带来好的发展机遇。
其他福利:来自于名企的数据科学工作者,北大清华以及海外等名校学生他们都将成为你在翻译小组的伙伴。
点击文末“阅读原文”加入数据派团队~
转载须知
如需转载,请在开篇显著位置注明作者和出处(转自:数据派ID:datapi),并在文章结尾放置数据派醒目二维码。有原创标识文章,请发送【文章名称-待授权公众号名称及ID】至联系邮箱,申请白名单授权并按要求编辑。
发布后请将链接反馈至联系邮箱(见下方)。未经许可的转载以及改编者,我们将依法追究其法律责任。


点击“阅读原文”拥抱组织


