学习 Lucene 原来可以那么简单!

#扫描上方二维码进入报名#
博客链接:https://my.oschina.net/u/3777556/blog/1647031
作者:Java3y
什么是Lucene??
Lucene 是 apache 软件基金会发布的一个开放源代码的全文检索引擎工具包,由资深全文检索专家 Doug Cutting 所撰写,它是一个全文检索引擎的架构,提供了完整的创建索引和查询索引,以及部分文本分析的引擎。
Lucene的目的是为软件开发人员提供一个简单易用的工具包,以方便在目标系统中实现全文检索的功能,或者是以此为基础建立起完整的全文检索引擎,Lucene在全文检索领域是一个经典的祖先,现在很多检索引擎都是在其基础上创建的,思想是相通的。
Lucene是根据关健字来搜索的文本搜索工具,只能在某个网站内部搜索文本内容,不能跨网站搜索。
既然谈到了网站内部的搜索,那么我们就谈谈我们熟悉的百度、google那些搜索引擎又是基于什么搜索的呢....
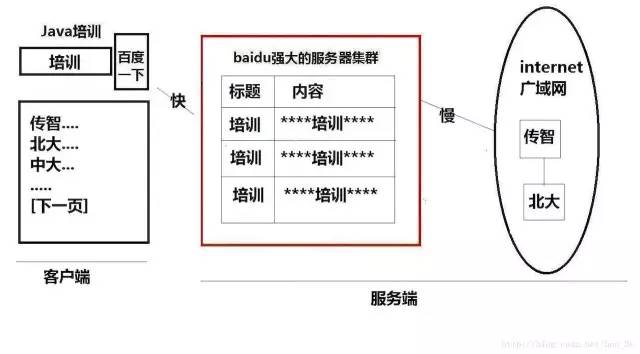
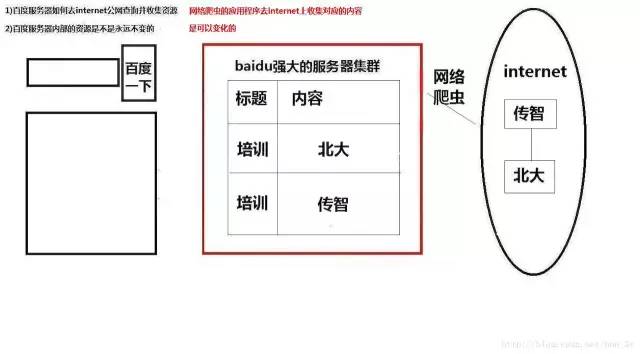
从图上已经看得很清楚,baidu、google等搜索引擎其实是通过网络爬虫的程序来进行搜索的...
为什么我们要用Lucene?
在介绍Lucene的时候,我们已经说了:Lucene又不是搜索引擎,仅仅是在网站内部进行文本的搜索。那我们为什么要学他呢???
我们之前编写纳税服务系统的时候,其实就已经使用过SQL来进行站内的搜索..
既然SQL能做的功能,我们还要学Lucene,为什么呢???
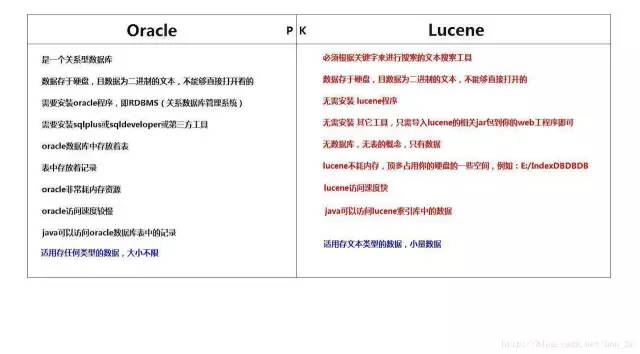
我们来看看我们用SQL来搜索的话,有什么缺点:
(1)SQL只能针对数据库表搜索,不能直接针对硬盘上的文本搜索
(2)SQL没有相关度排名
(3)SQL搜索结果没有关健字高亮显示
(4)SQL需要数据库的支持,数据库本身需要内存开销较大,例如:Oracle
(5)SQL搜索有时较慢,尤其是数据库不在本地时,超慢,例如:Oracle
我们来看看在baidu中搜索Lucene为关键字搜索出的内容是怎么样的:
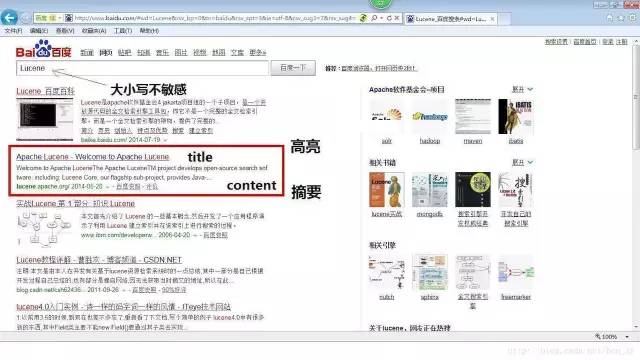
以上所说的,我们如果使用SQL的话,是做不到的。因此我们就学习Lucene来帮我们在站内根据文本关键字来进行搜索数据!
我们如果网站需要根据关键字来进行搜索,可以使用SQL,也可以使用Lucene...那么我们Lucene和SQL是一样的,都是在持久层中编写代码的。。
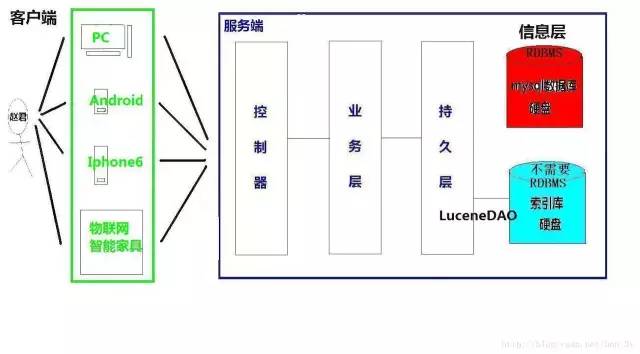
一、快速入门
接下来,我们就讲解怎么使用Lucene了.....在讲解Lucene的API之前,我们首先来讲讲Lucene存放的究竟是什么内容...我们的SQL使用的是数据库中的内存,在硬盘中为DBF文件...那么我们Lucene内部又是什么东西呢??
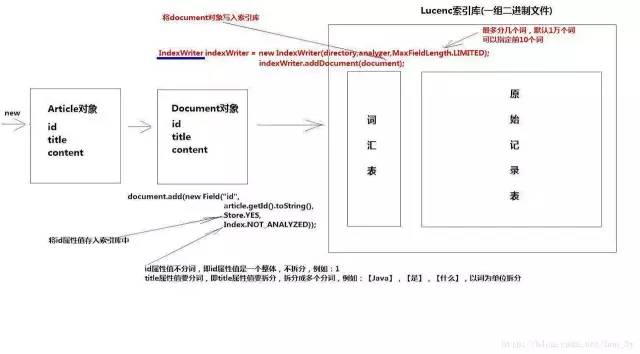
Lucene中存的就是一系列的二进制压缩文件和一些控制文件,它们位于计算机的硬盘上, 这些内容统称为索引库,索引库有二部份组成:
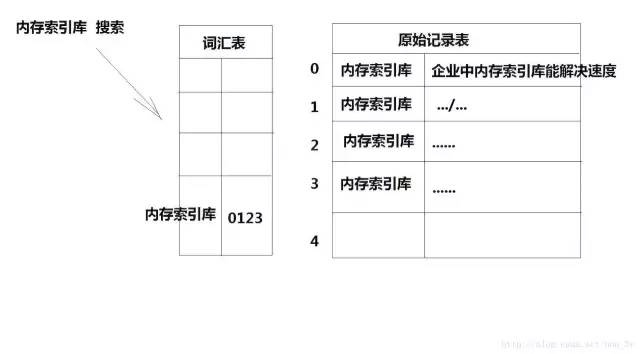
(1)原始记录
存入到索引库中的原始文本,例如:我是钟福成
(2)词汇表
按照一定的拆分策略(即分词器)将原始记录中的每个字符拆开后,存入一个供将来搜索的表
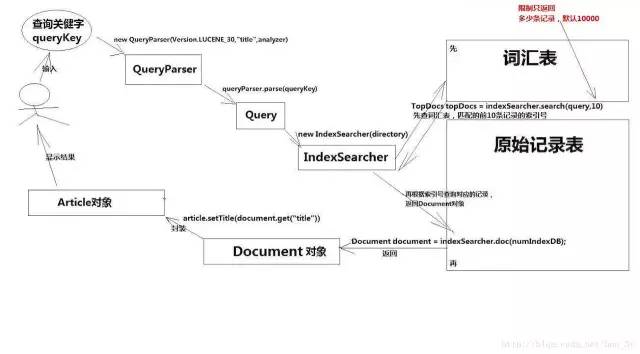
也就是说:Lucene存放数据的地方我们通常称之为索引库,索引库又分为两部分组成:原始记录和词汇表....
1.1原始记录和词汇表
当我们想要把数据存到索引库的时候,我们首先存入的是将数据存到原始记录上面去....
又由于我们给用户使用的时候,用户使用的是关键字来进行查询我们的具体记录。因此,我们需要把我们原始存进的数据进行拆分!将拆分出来的数据存进词汇表中。
词汇表就是类似于我们在学Oracle中的索引表,拆分的时候会给出对应的索引值。
一旦用户根据关键字来进行搜索,那么程序就先去查询词汇表中有没有该关键字,如果有该关键字就定位到原始记录表中,将符合条件的原始记录返回给用户查看。
我们查看以下的图方便理解:
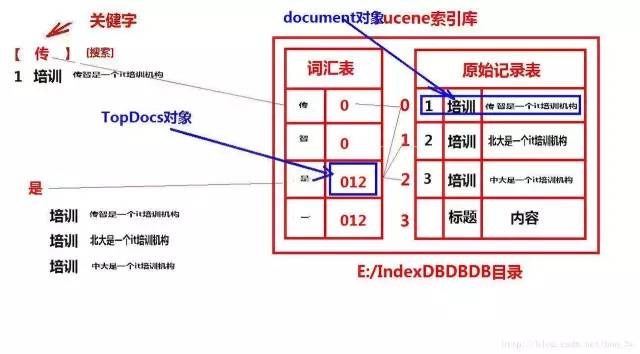
到了这里,有人可能就会疑问:难道原始记录拆分的数据都是一个一个汉字进行拆分的吗??然后在词汇表中不就有很多的关键字了???
其实,我们在存到原始记录表中的时候,可以指定我们使用哪种算法来将数据拆分,存到词汇表中.....我们的图是Lucene的标准分词算法,一个一个汉字进行拆分。我们可以使用别的分词算法,两个两个拆分或者其他的算法。
1.2编写第一个Lucene程序
首先,我们来导入Lucene的必要开发包:
lucene-core-3.0.2.jar【Lucene核心】
lucene-analyzers-3.0.2.jar【分词器】
lucene-highlighter-3.0.2.jar【Lucene会将搜索出来的字,高亮显示,提示用户】
lucene-memory-3.0.2.jar【索引库优化策略】
创建User对象,User对象封装了数据....
/**
* Created by ozc on 2017/7/12.
*/
public class User {
private String id ;
private String userName;
private String sal;
public User() {
}
public User(String id, String userName, String sal) {
this.id = id;
this.userName = userName;
this.sal = sal;
}
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
public String getUserName() {
return userName;
}
public void setUserName(String userName) {
this.userName = userName;
}
public String getSal() {
return sal;
}
public void setSal(String sal) {
this.sal = sal;
}
}
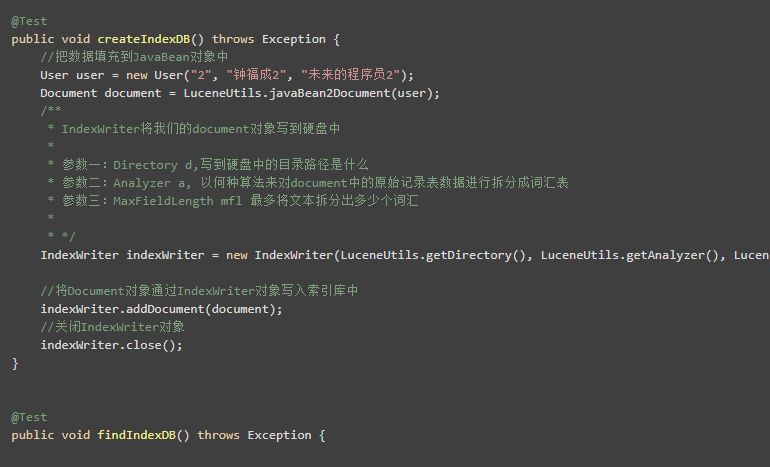
我们想要使用Lucene来查询出站内的数据,首先我们得要有个索引库吧!于是我们先创建索引库,将我们的数据存到索引库中。
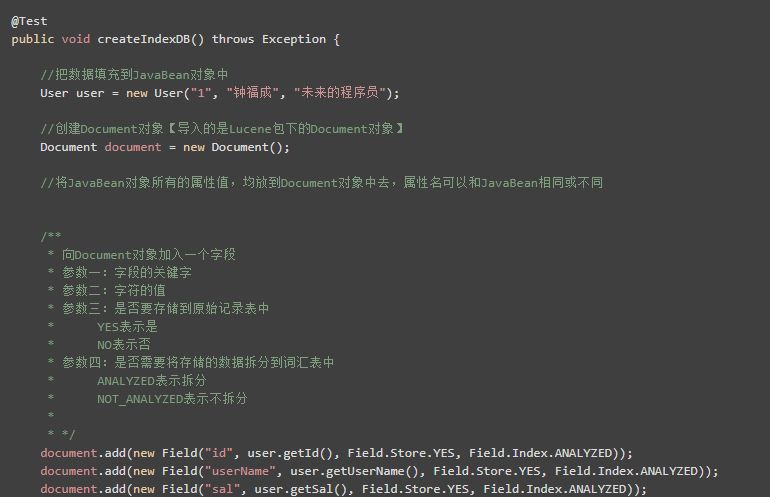
创建索引库的步骤:
1)创建JavaBean对象
2)创建Docment对象
3)将JavaBean对象所有的属性值,均放到Document对象中去,属性名可以和JavaBean相同或不同
4)创建IndexWriter对象
5)将Document对象通过IndexWriter对象写入索引库中
6)关闭IndexWriter对象
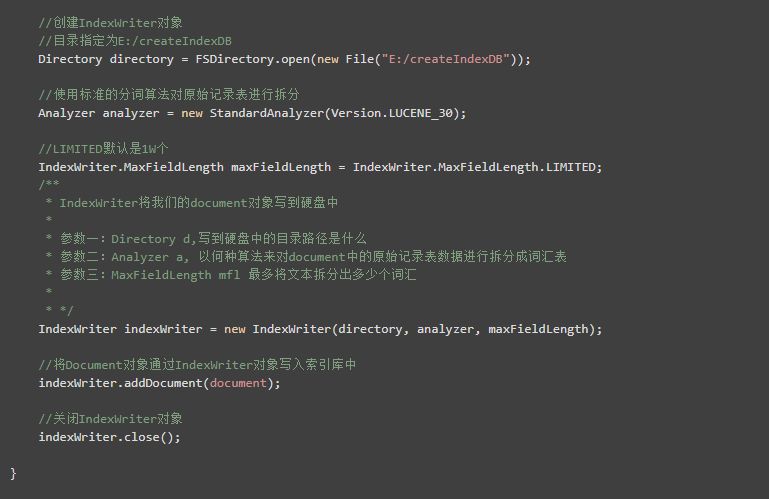
程序执行完,我们就会在硬盘中见到我们的索引库。
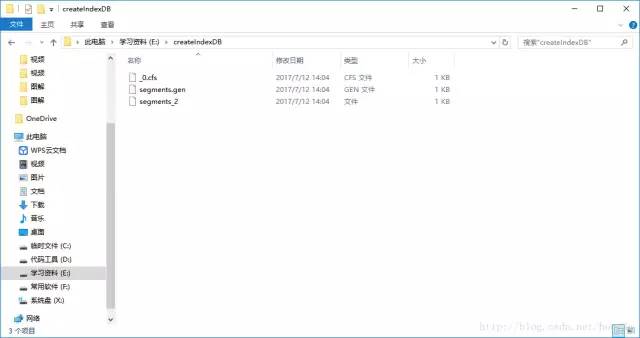
那我们现在是不知道记录是否真真正正存储到索引库中的,因为我们看不见。索引库存放的数据放在cfs文件下,我们也是不能打开cfs文件的。
于是,我们现在用一个关键字,把索引库的数据读取。看看读取数据是否成功。
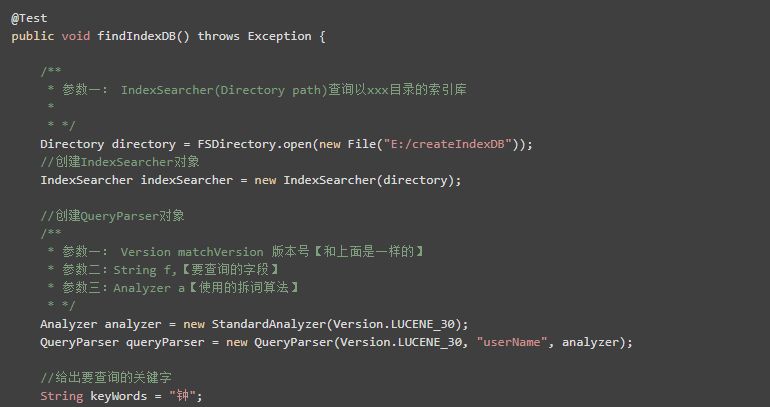
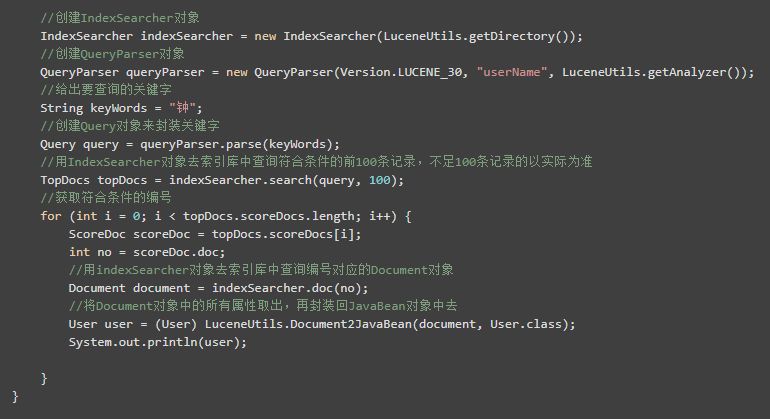
根据关键字查询索引库中的内容:
1)创建IndexSearcher对象
2)创建QueryParser对象
3)创建Query对象来封装关键字
4)用IndexSearcher对象去索引库中查询符合条件的前100条记录,不足100条记录的以实际为准
5)获取符合条件的编号
6)用indexSearcher对象去索引库中查询编号对应的Document对象
7)将Document对象中的所有属性取出,再封装回JavaBean对象中去,并加入到集合中保存,以备将之用
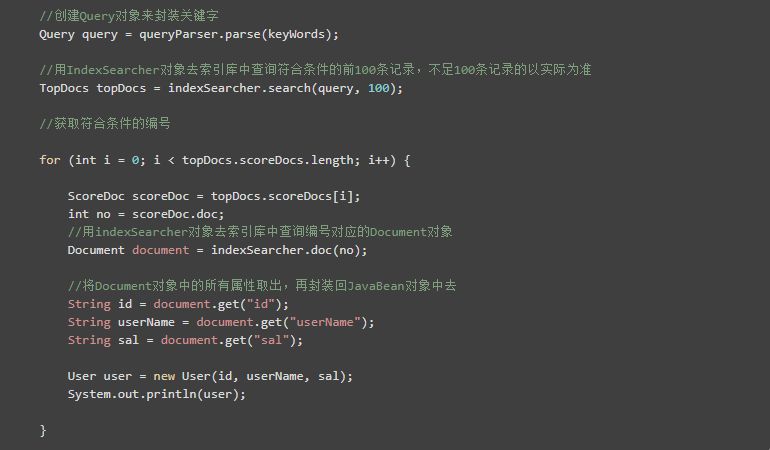
效果:
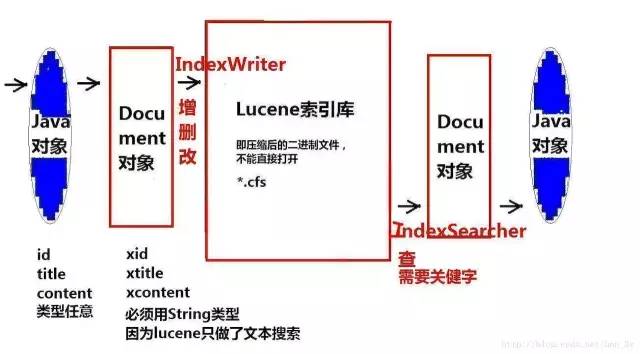
1.3进一步说明Lucene代码
我们的Lucene程序就是大概这么一个思路:将JavaBean对象封装到Document对象中,然后通过IndexWriter把document写入到索引库中。当用户需要查询的时候,就使用IndexSearcher从索引库中读取数据,找到对应的Document对象,从而解析里边的内容,再封装到JavaBean对象中让我们使用。
二、对Lucene代码优化
我们再次看回我们上一篇快速入门写过的代码,我来截取一些有代表性的:
以下代码在把数据填充到索引库,和从索引库查询数据的时候,都出现了。是重复代码!

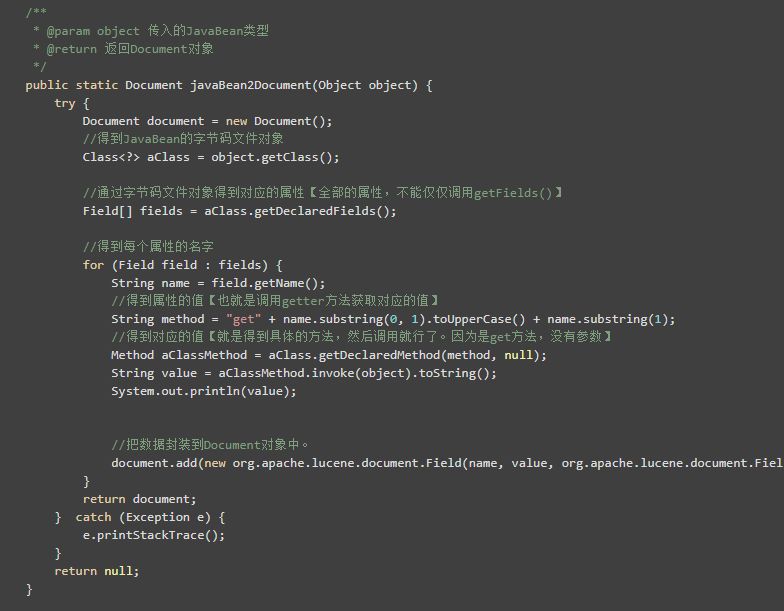
以下的代码其实就是将JavaBean的数据封装到Document对象中,我们是可以通过反射来对其进行封装....如果不封装的话,我们如果有很多JavaBean都要添加到Document对象中,就会出现很多类似的代码。

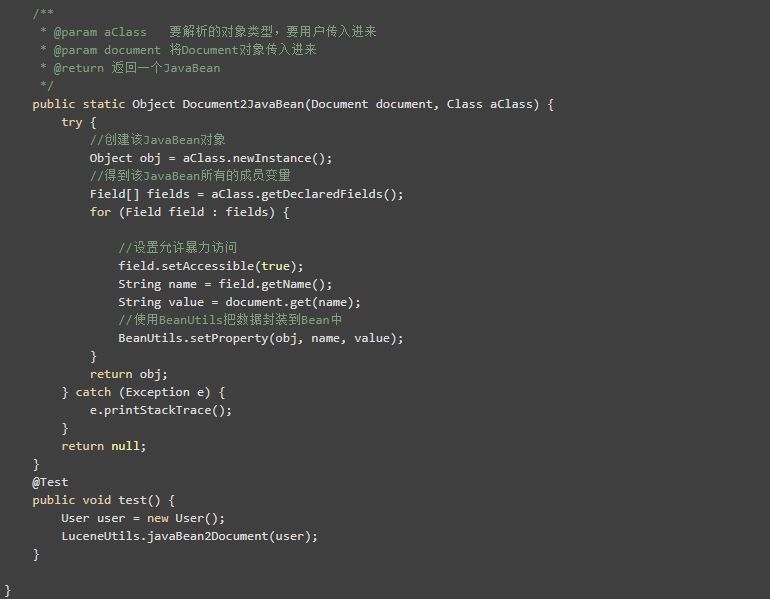
以下代码就是从Document对象中把数据取出来,封装到JavaBean去。如果JavaBean中有很多属性,也是需要我们写很多次类似代码....

2.1编写Lucene工具类
在编写工具类的时候,值得注意的地方:
当我们得到了对象的属性的时候,就可以把属性的get方法封装起来
得到get方法,就可以调用它,得到对应的值
在操作对象的属性时,我们要使用暴力访问
如果有属性,值,对象这三个变量,我们记得使用BeanUtils组件

2.2使用LuceneUtils改造程序
三、索引库优化
我们已经可以创建索引库并且从索引库读取对象的数据了。其实索引库还有地方可以优化的....
3.1合并文件
我们把数据添加到索引库中的时候,每添加一次,都会帮我们自动创建一个cfs文件...
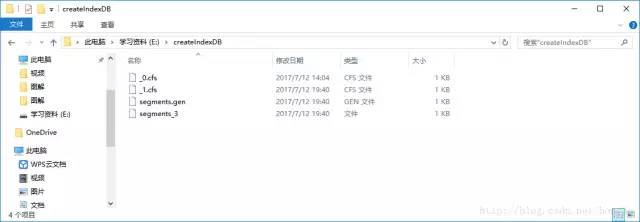
这样其实不好,因为如果数据量一大,我们的硬盘就有非常非常多的cfs文件了.....其实索引库会帮我们自动合并文件的,默认是10个。
如果,我们想要修改默认的值,我们可以通过以下的代码修改:

3.2设置内存索引库
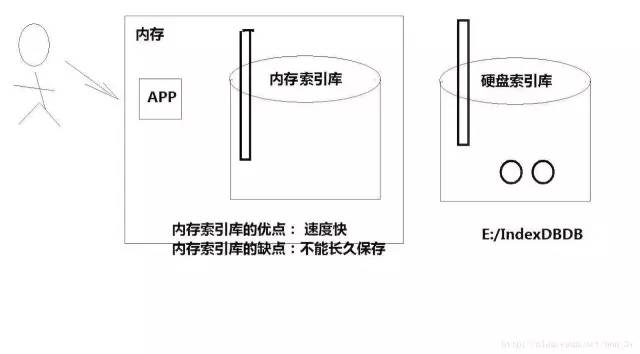
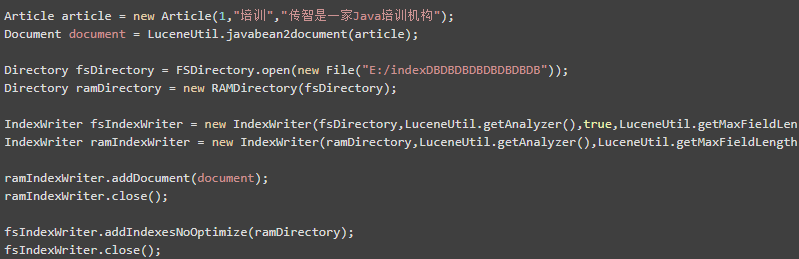
我们的目前的程序是直接与文件进行操作,这样对IO的开销其实是比较大的。而且速度相对较慢....我们可以使用内存索引库来提高我们的读写效率...
对于内存索引库而言,它的速度是很快的,因为我们直接操作内存...但是呢,我们要将内存索引库是要到硬盘索引库中保存起来的。当我们读取数据的时候,先要把硬盘索引库的数据同步到内存索引库中去的。
四、分词器
我们在前面中就已经说过了,在把数据存到索引库的时候,我们会使用某些算法,将原始记录表的数据存到词汇表中.....那么这些算法总和我们可以称之为分词器
分词器: ** 采用一种算法,将中英文本中的字符拆分开来,形成词汇,以待用户输入关健字后搜索**
对于为什么要使用分词器,我们也明确地说过:由于用户不可能把我们的原始记录数据完完整整地记录下来,于是他们在搜索的时候,是通过关键字进行对原始记录表的查询....此时,我们就采用分词器来最大限度地匹配相关的数据
4.1分词器流程
步一:按分词器拆分出词汇
步二:去除停用词和禁用词
步三:如果有英文,把英文字母转为小写,即搜索不分大小写
4.2分词器API
我们在选择分词算法的时候,我们会发现有非常非常多地分词器API,我们可以用以下代码来看看该分词器是怎么将数据分割的:
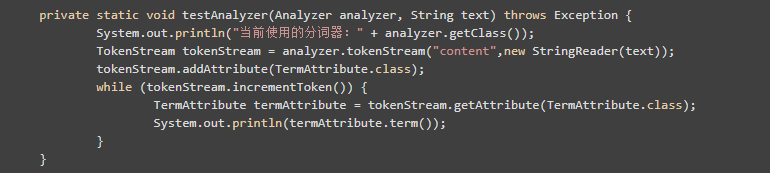
在实验完之后,我们就可以选择恰当的分词算法了....
4.3IKAnalyzer 分词器
这是一个第三方的分词器,我们如果要使用的话需要导入对应的jar包
IKAnalyzer3.2.0Stable.jar
步二:将IKAnalyzer.cfg.xml和stopword.dic和xxx.dic文件复制到MyEclipse的src目录下,再进行配置,在配置时,首行需要一个空行
这个第三方的分词器有什么好呢????他是中文首选的分词器...也就是说:他是按照中文的词语来进行拆分的!
五、对搜索结果进行处理
5.1搜索结果高亮
我们在使用SQL时,搜索出来的数据是没有高亮的...而我们使用Lucene,搜索出来的内容我们可以设置关键字为高亮...这样一来就更加注重用户体验了!
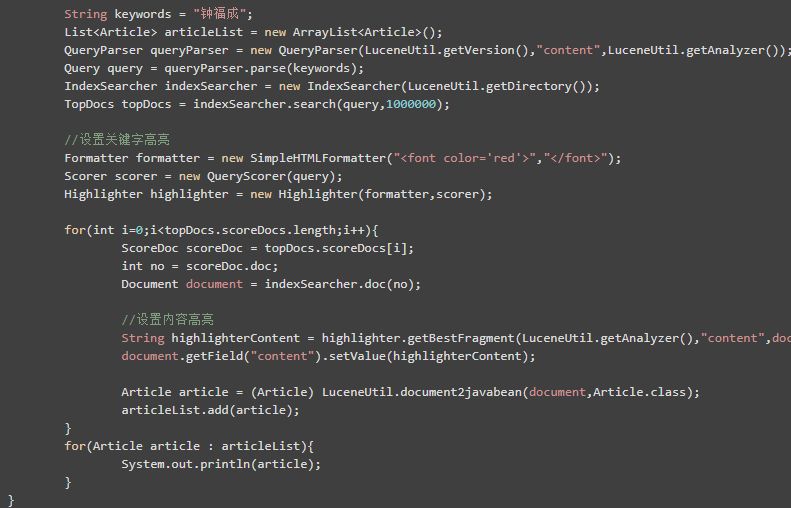
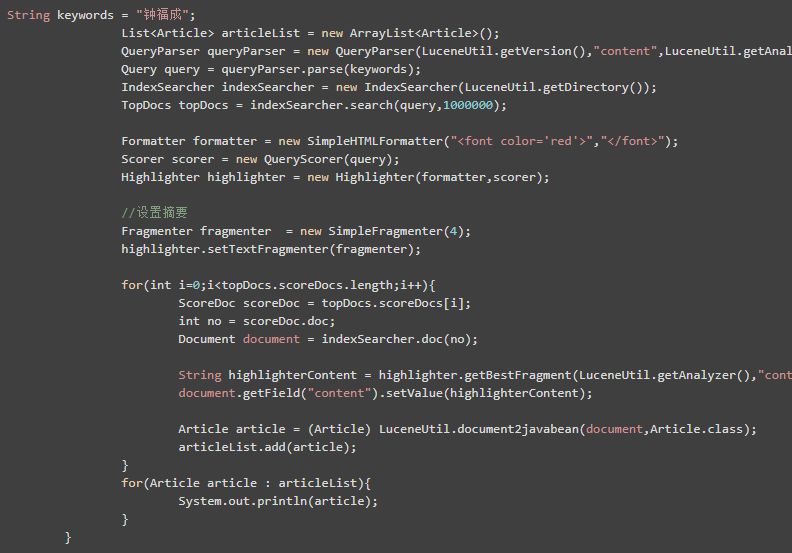
5.2搜索结果摘要
如果我们搜索出来的文章内容太大了,而我们只想显示部分的内容,那么我们可以对其进行摘要...
值得注意的是:搜索结果摘要需要与设置高亮一起使用
5.3搜索结果排序
我们搜索引擎肯定用得也不少,使用不同的搜索引擎来搜索相同的内容。他们首页的排行顺序也会不同...这就是它们内部用了搜索结果排序....
影响网页的排序有非常多种:
head/meta/【keywords关键字】
网页的标签整洁
网页执行速度
采用div+css
等等等等
而在Lucene中我们就可以设置相关度得分来使不同的结果对其进行排序:
IndexWriter indexWriter = new IndexWriter(LuceneUtil.getDirectory(),LuceneUtil.getAnalyzer(),LuceneUtil.getMaxFieldLength());
//为结果设置得分
document.setBoost(20F);
indexWriter.addDocument(document);
indexWriter.close();
当然了,我们也可以按单个字段排序:

也可以按多个字段排序:在多字段排序中,只有第一个字段排序结果相同时,第二个字段排序才有作用 提倡用数值型排序

5.4条件搜索
在我们的例子中,我们使用的是根据一个关键字来对某个字段的内容进行搜索。语法类似于下面:

其实,我们也可以使用关键字来对多个字段进行搜索,也就是多条件搜索。我们实际中常常用到的是多条件搜索,多条件搜索可以使用我们最大限度匹配对应的数据!
QueryParser queryParser = new MultiFieldQueryParser(LuceneUtil.getVersion(),new String[]{"content","title"},LuceneUtil.getAnalyzer());
六、总结
Lucene是全文索引引擎的祖先,后面的Solr、Elasticsearch都是基于Lucene的(后面会有一篇讲Elasticsearch的,敬请期待~)
Lucene中存的就是一系列的二进制压缩文件和一些控制文件,这些内容统称为索引库,索引库又分了两个部分:
原始记录
词汇表
了解索引库的优化方式:1、合并文件 2、设置内存索引库
Lucene的分词器有非常多种,选择自己适合的一种进行分词
查询出来的结果可对其设置高亮、摘要、排序
这篇这是Lucene的冰山一角,一般现在用的可能都是Solr、Elasticsearch的了,但想要更加深入了解Lucene可翻阅其他资料哦~
因排版问题,部分代码无法显示完全,完整代码请可以点击阅读原文或扫码进入查看:








