视频 | 机器之心线上分享:用于序列生成的推敲网络
机器之心发布
机器之心编辑部
NIPS 2017 将于当地时间12月4日在美国长滩开幕,在此之前机器之心邀请了多位NIPS 2017 论文作者为读者做技术分享。本文是对中山大学-微软亚洲研究院联合培养博士吴郦军分享视频的回顾与论文解读。
吴郦军博士线上分享视频回顾
论文:Deliberation Networks: Sequence Generation Beyond One-Pass Decoding

论文链接:http://papers.nips.cc/paper/6775-deliberation-networks-sequence-generation-beyond-one-pass-decoding.pdf
摘要:编码器-解码器框架在许多序列生成任务中都实现了非常好的性能,包括机器翻译、自动文本摘要、对话系统和图像描述等。这样的框架在解码和生成序列的过程中只采用一次(one-pass)正向传播过程,因此缺乏推敲(deliberation)的过程:即生成的序列直接作为最终的输出而没有进一步打磨的过程。然而推敲是人们在日常生活中的一种常见行为,正如我们在阅读新闻和写论文/文章/书籍一样。在该研究中,我们将推敲过程加入到了编码器-解码器框架中,并提出了用于序列生成的推敲网络(Deliberation networks)。推敲网络具有两阶段解码器,其中第一阶段解码器用于解码生成原始序列,第二阶段解码器通过推敲的过程打磨和润色原始语句。由于第二阶段推敲解码器具有应该生成什么样的语句这一全局信息,因此它能通过从第一阶段的原始语句中观察未来的单词而产生更好的序列。神经机器翻译和自动文本摘要的实验证明了我们所提出推敲网络的有效性。在 WMT 2014 英语到法语间的翻译任务中,我们的模型实现了 41.5 的 BLEU 分值,即当前最优的 BLEU 分值。
1 引言
基于神经网络的编码器-解码器框架已经在序列生成任务上得到了广泛的应用,其中包括神经机器翻译[1]、文本摘要[19]、图像描述[27]等。在这样的框架中,编码器将长度为 m 的源输入 x 编码成一个向量序列 {h1,h2,· · · , hm}。编码器(通常是一个 RNN)则基于来源的向量表征和之前生成的词来逐个词地生成一个输出序列。注意机制[1,35]则是在生成每个目标词时动态地关注 x 的不同部分,该机制可被整合进编码器-解码器框架中,从而提升长序列的生成质量 [1]。
尽管该框架已经取得了很大的成功,但还存在一个问题:在生成词的时候只能利用生成的词而不是未来的尚未生成的词。也就是说,当解码器生成第 t 个词 y_t 时,只使用了小于 t 的 y,而没有明确考虑大于 t 的 y。相反,真实的人类认知过程会以一种迭代式刷新的方式利用包含过去和未来部分的全局信息。这里给出两个例子:(1) 思考一下当我们在阅读一个句子时在句子中间遇到了一个不认识的词。我们不会在此就停止阅读。相反,我们会继续读完这个句子。然后我们回到这个未知词并试图使用其上下文(包括该词之前和之后的词)来理解它。(2)在书写一份好的文档(或段落、文章)时,我们通常首先会创建一个完整的草稿,然后再根据对整个草稿的全局理解来进行润色。当润色一个特定部分时,我们不会只看这部分之前的内容,而是会考虑这个草稿的全局,从而评估这里的局部元素与全局环境的契合程度。
我们将这个润色过程称为推敲(deliberation)。受人类认知行为的启发,我们提出了推敲网络,该网络通过一个推敲过程可在序列解码过程中同时检查前后的内容,从而可以利用全局信息。具体而言,为了将这样的过程整合进序列生成框架中,我们精心设计了我们的框架——它由一个编码器 E 以及两个解码器 D1 和 D2 构成;其中 D1 是一个第一阶段解码器(first-pass decoder),D2 是一个第二阶段/推敲解码器(second-pass/deliberation decoder)。给定一个源输入 x,E 和 D1 会像标准的编码器-解码器模型一样联合工作,从而生成一个粗略的序列 yˆ 作为草稿和用于生成 yˆ 的对应的表征
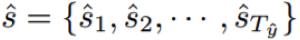
,其中T_yˆ 是 yˆ 的长度。之后,推敲解码器 D2 以 x、yˆ 和 sˆ 为输入,输出经过精细处理后的序列 y。当 D2 生成第 t 个词 y_t 时,还有一个额外的注意模型被用于给每个 yˆ_j 和 sˆ_j 分配一个自适应权重 β_j,其中 j ∈ [T_yˆ];而且 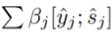
为了验证我们的模型的有效性,我们在两个有代表性的序列生成任务上进行了研究:
(1)神经机器翻译(NMT),即使用神经网络来将源语言的句子翻译到目标语言[1, 33, 32, 34]。标准的 NMT 模型由一个编码器(用于编码源句子)和一个解码器(用于生成目标句子)组成,因为可以使用我们提出的推敲网络加以改善。在 WMT' 14 [29] 英语→法语数据集上基于广泛应用的单层 GRU 模型[1] 上实验结果表明:相比于没有使用推敲的模型,使用推敲可以将 BLEU 分值[17]提升 1.7。我们还在汉语→英语翻译上应用了我们的模型,并且在 4 种不同的测试集上平均实现了 1.26 的 BLEU 提升。此外,在 WMT' 14 英语→法语翻译任务上,通过将推敲应用于深度 LSTM 模型,我们实现了 41.50 的 BLEU 分值,这个成绩是这一任务的全新纪录。
(2)文本摘要,即将长文章归纳为短摘要的任务。这个任务可以使用编码器-解码器框架,因此也可以使用推敲网络来精细处理。在 Gigaword 数据集 [6] 上的实验结果表明推敲网络可以将 ROUGE-1、ROUGE-2 和 ROUGE-L 分别提升 3.45、1.70 和 3.02。
2 框架
在这一节,我们首先会介绍推敲网络的整体架构,然后再介绍各个组分的详细情况,最后还会提出一种用于训练推敲网络的端到端的基于蒙特卡洛的算法。
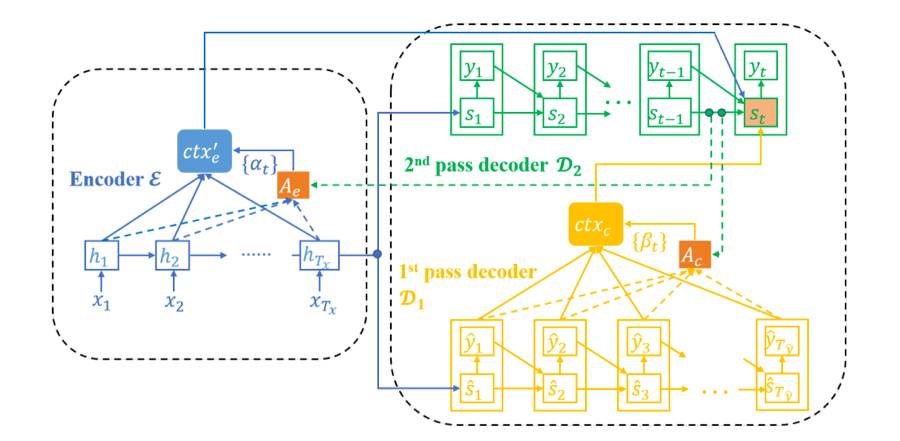
图 1:推敲网络的框架:蓝色、黄色和绿色部分分别表示编码器 E、第一阶段解码器 D1 和第二阶段解码器 D2。为了可读性,这里省略了 E 到 D1 的注意模型。

算法 1:用于训练推敲网络的算法
3 将推敲网络应用于神经机器翻译
我们使用两种不同的网络结构评估了推敲网络:(1)浅模型,基于名为 RNNSearch [1,12] 的有广泛应用的单层 GRU 模型;(2)深度模型,基于类似于 GNMT [31] 的深度 LSTM 模型。这两类模型都是在 Theano [24] 中实现的。

表 1:英语→法语翻译的 BLEU 分值


表 3:汉语→英语翻译的案例研究。注意第二个例子中的“……”表示一个常见句子“(the two sides will discuss how to improve the implementation of thecease-fire agreement)双方将讨论如何改进落实停火协议”。

表 4:推敲网络与不同的深度 NMT 系统(英语→法语)之间的比较
4 将推敲网络应用于文本摘要
我们进一步验证了推敲网络在文本摘要上的有效性,这是编码器-解码器框架得到了成功应用的另一种真实应用 [19]。
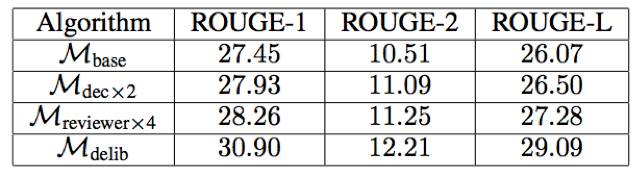
表 5:文本摘要的 ROUGE-{1, 2, L} 分值
5 结论和未来工作
在这项研究中,我们提出了用于序列生成任务的推敲网络,其中会使用一个第一阶段解码器来生成一个原始序列,然后再使用一个第二阶段解码器来润色这个原始序列。实验表明我们的方法在机器翻译和文本摘要任务上可以实现比几种基准方法远远更优的结果,而且我们的方法还在 WMT' 14 英语→法语翻译任务上实现了新的单个模型的当前最佳结果。
未来还有多个可以探索的有潜力的研究方向。首先,我们将研究如何将推敲的思想应用于序列生成之外的任务,比如改善 GAN [5] 生成的图像的质量。其次,我们将研究如何细化/润色不同层级的神经网络,比如 RNN 中的隐藏状态或 CNN 中特征图。第三,我们还很好奇如果解码器有更多阶段(即多次打磨润色生成的序列),生成的序列是否还会更好。第四,我们还将研究如何加速推敲网络的推理以及缩短它们的推理时间。

本文为机器之心发布,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com

