【学界】要合作,不要对抗!无需预训练超越经典算法,上交大提出合作训练式生成模型CoT
作者:卢思迪 上海交通大学
来源:新智元
【导读】上海交通大学APEX实验室研究团队提出合作训练(Cooperative Training),通过交替训练生成器(G)和调和器(M),无需任何预训练即可稳定地降低当前分布与目标分布的JS散度,且在生成性能和预测性能上都超越了以往的算法。对于离散序列建模任务来说,该算法无需改动模型的网络结构,同时计算代价较理想,是一种普适的高效算法。本文是论文第一作者卢思迪带来的解读。
论文地址:https://arxiv.org/pdf/1804.03782.pdf
GitHub:https://github.com/desire2020/Cooperative-Training
生成式模型是无监督学习这一领域的一个重要话题。对于连续数据(如图片)的建模,自2014年生成式对抗网络(Generative Adversarial Network, GAN)发表以来,研究已取得了不少进展。然而,对于离散数据,特别是离散序列的建模与生成,针对这个问题的研究仍没有产生足够令人满意的突破。
对于这一类数据建模问题,经典算法如极大似然估计(Maximum Likelihood Estimation, MLE)很难称得上是理想的算法。在数据有限的情况下,它和生成式任务并不能完美地相适应。如下图,MLE等价于优化单侧KL散度KL(P||G):
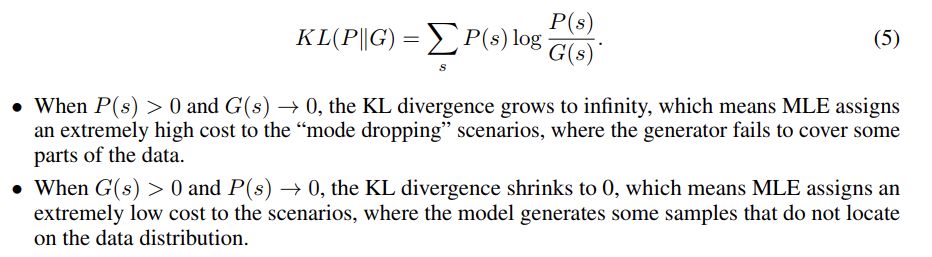
由于KL散度不对称,对于预测中的失误,MLE这一目标函数能够给出比较好的惩罚进而给予纠正;但是对于潜在的生成失误,MLE并不能很好地起到作用。
针对这一问题,研究者们提出了序列生成式网络(Sequence Generative Adversarial Network, SeqGAN)。SeqGAN是这一领域针对MLE问题的早期尝试之一,其使用强化学习来优化GAN的目标函数,即:
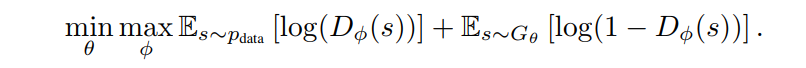
相比于经典算法,SeqGAN在样本生成的质量上有了一些改进。然而由于对抗网络固有的不稳定性,SeqGAN常常在预测式任务中表现不佳。此外,受限于策略梯度法这一基于策略的强化学习(Policy-based Reinforcement Learning)的能力,SeqGAN并不能单独使用,需要使用MLE进行预训练。

针对这个问题,上海交通大学APEX实验室研究团队提出合作训练(Cooperative Training),通过交替训练生成器(G)和调和器(M),无需任何预训练即可稳定地降低当前分布与目标分布的JS散度,且在生成性能和预测性能上都超越了以往的算法。对于离散序列建模任务来说,该算法无需改动模型的网络结构,同时计算代价较理想,是一种普适的高效算法。
在图片生成等任务里,GAN之所以能奏效,是因为其本质上优化的是当前分布与目标分布的Jensen-Shannon散度(JSD),即:
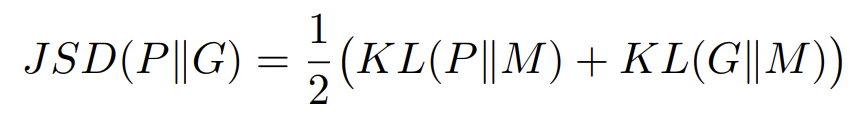
其中M=0.5P + 0.5G,是当前已习得分布G与目标分布P的一个均衡混合分布。从定义可以看出,JSD对于P和G是对称的。也就是说,对于模型在生成式任务和判别式任务中的错误,这个衡量标准都可以均衡地反馈出来。如果能够直接最小化JSD或者它的一个无偏差(unbiased)近似,那么对于目标分布的拟合就是比较准确的。遗憾的是,直接对JSD本身进行优化是不可能的。原因是,我们只有对于自己当前分布的建模G,但是无法直接拿到目标分布P,进而构造准确的M是不可能的。但是,受到GAN的启发,我们可以训练一个模型去近似混合分布M,并且以它为支点来优化一个JSD的好的近似。
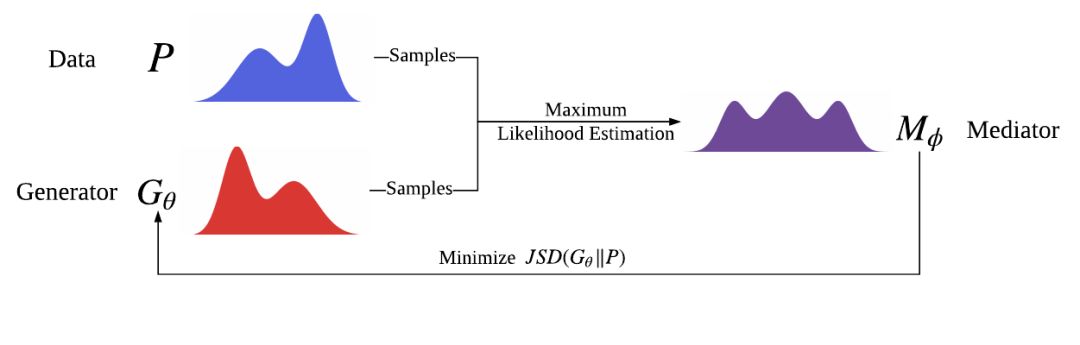
基于这一想法,研究者们提出了合作训练(Cooperative Training, CoT)。如图所示,在合作训练的框架内,有两个架构相同的模块,称为生成器(Generator, G)和调和器(Mediator, M)。
每一次迭代,从G中采出一些样本,再从训练数据中随机选出等量的样本,把两者混合,用来训练M。由于这种情况下,我们只关心M对于给定样本的似然度估计,因此在训练M时,我们使用MLE就不会产生一般意义下的各种问题。在M得到训练后,对于来自G的一组样本s,用M给出的估计值M(s)来代替真实值M*(s),从而得到一个JSD的近似估计。在训练G时,最小化这个近似估计,即可达到对于目标分布的趋近。
通过一些推导,我们可以给出这个算法中两个模块各自的目标函数:
调和器(Mediator):
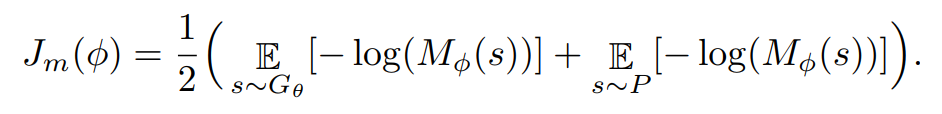
生成器(Generator):
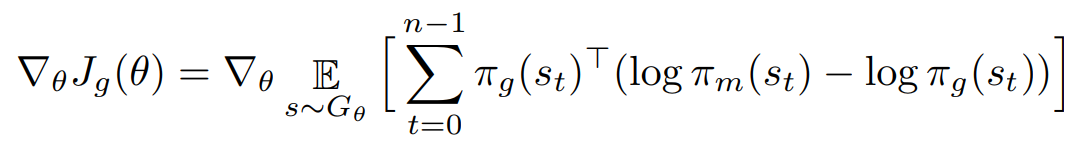
其中π代表两个模块在给定前缀下对于下一步所有决策的概率估计。为了不使这篇介绍过于无趣,详细的推导请参见原文。完整算法流程如下:

可以看出,这个算法的计算复杂度与MLE一致,两者仅差一个常数倍数。
对于CoT来说,最终的优化问题可以写成:
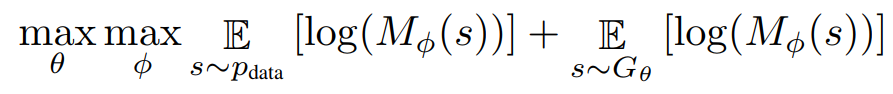
这是一个合作式目标(而非GAN中的非合作博弈目标)。通过推导我们可以知道,这个优化目标的一半和JSD的相反数趋势一致,两者的差值就是目标分布的熵!
对于合成数据上的验证性实验,研究者使用了由SeqGAN提出,并在TexyGen(一个基准评测系统)中得以完善的数据,即合成数据图灵测试(Synthetic Turing Test)。结果如表所示,公平起见,这一测试中所有的模型未使用任何正则化,且生成器架构完全相同。
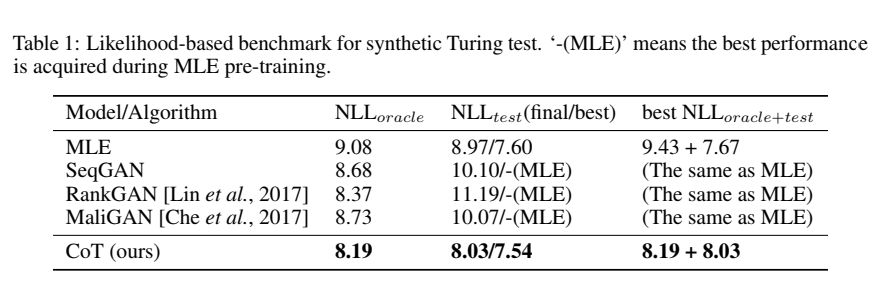
注意到,即使是在反映预测式任务性能的NLL test(这本身是MLE的优化目标)这一指标上,CoT也超越了MLE,不仅仅是在收敛性能上优于MLE,即使训练途中所探索到的最好局部最优(7.54)也好于MLE。而在生成质量的测试指标NLL oracle方面,从零开始训练,无需任何MLE预热的CoT达到了使用简单生成器架构模型中最优水平。如果综合考察生成质量和预测准确性,之前的模型在两个指标之和的意义下相比MLE并没有产生改进。而CoT不但有明显改进,而且在两个任务下的性能水平基本一致(均为8.1左右)。反观MLE,则很不均衡(生成损失:9.43预测损失:7.67)。这更说明一个无偏的优化目标对于数据建模的有效性之重要。
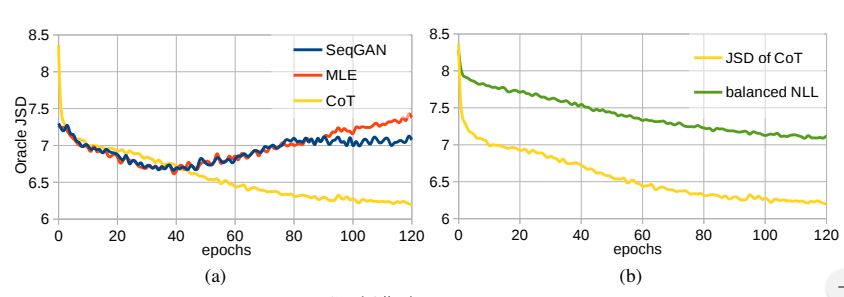
我们注意到相比较G,由于M的训练目标形式上更接近有监督学习,再加上在推荐设定中它的容量比G更大,它很容易过拟合,进而影响模型的表现。因此,在使用一些简单的正则化技术,如Dropout之后,模型的表现更加令人满意。在合成数据上,我们可以通过算出真正的JSD来说明这一点。如图,使用了正则化后,我们可以发现我们的算法达到了对于真正的JSD的持续、一致、较为稳定的优化。而且,由调和器提供的对JSD的趋势估计也非常准确。
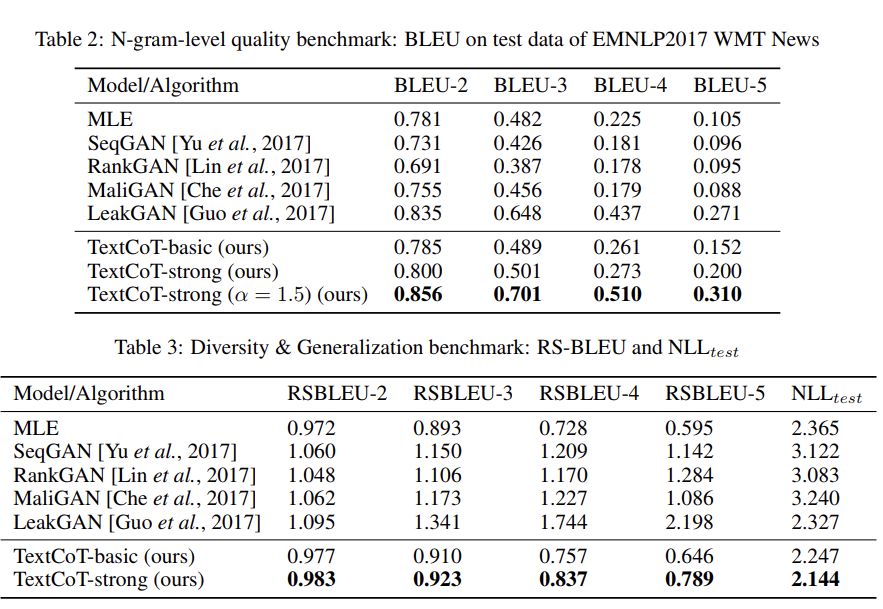
除此之外,作为一个通用的离散序列建模算法,我们也进行了一些文本上的实验。为了控制变量,我们使用这一领域前人工作大都评测过的一个较长文本数据集EMNLP 2017 WMT News Section。如表所示,在使用相同(或接近)的架构和细节设定的前提下,我们的算法达到了最佳水平。
我们注意到这个算法还可以用于提高其自身的效果。具体来说,对于M我们也可以使用CoT来代替MLE对其进行训练。由于CoT具有提高模型在预测任务中泛化性能的能力,这样做可以使得模型更加稳定。然而,受限于篇幅和时间,我们没有给出实践上的验证,但这一想法本身非常有趣。
我们提出新的生成式模型训练算法合作训练(Cooperative Training),用于优化当前已习得分布和目标分布的JS散度。该算法无需预训练,计算速度和MLE同等理想,且在所有离散序列建模任务(包括生成式和预测式)里面超越了以往的算法。我们希望能进一步地对这一算法展开研究,并将其延拓至其他类型数据如图片上,为生成式模型建立一个新的范式。我们也期待研究者能够就CoT与GAN之间更深层次的联系展开研究,并产生一些有趣的结论。
☞【学界】OpenPV:中科院研究人员建立开源的平行视觉研究平台
☞【征稿通知】IEEE IV 2018“智能车辆中的平行视觉”研讨会
☞【学界】ParallelEye:面向交通视觉研究构建的大规模虚拟图像集
☞【CFP】Virtual Images for Visual Artificial Intelligence
☞【最详尽的GAN介绍】王飞跃等:生成式对抗网络 GAN 的研究进展与展望
☞【智能自动化学科前沿讲习班第1期】王飞跃教授:生成式对抗网络GAN的研究进展与展望
☞【智能自动化学科前沿讲习班第1期】王坤峰副研究员:GAN与平行视觉
☞【重磅】平行将成为一种常态:从SimGAN获得CVPR 2017最佳论文奖说起
☞【征稿】神经计算专刊Virtual Images for Visual Artificial Intelligence
☞【学界】IJCAI 2018 | 海康威视Oral论文:分层式共现网络,实现更好的动作识别和检测
☞【业界】rFpro推出自动驾驶模拟平台,能以每秒120帧的速度运行高清质量图形
☞【业界】NVIDIA推出DRIVE Constellation仿真系统,在虚拟现实环境中测试自动驾驶汽车安全行驶
☞【学界】CVPR 2018:用狗的数据训练AI,华盛顿大学研发模拟狗行为的AI系统



