清华创新架构芯片量产!全球首款可重构超低功耗语音AI芯片
看点:揭秘首款CGRA架构语音AI芯片的性能参数,和它背后的技术密码。


智东西6月27日消息,最近,脱胎于清华大学微电子所Thinker团队的AI芯片创企清微智能迎来新进展:
全球首款可重构超低功耗语音人工智能(AI)芯片TX210已实现规模化量产,于6月中旬正式交付市场,而此时清微智能距成立还不到1年。
这是一款语音SoC芯片,针对手机、可穿戴设备、智能家居等多种应用场景的智能终端产品开发,工作功耗不超过2mW,语音活动检测(VAD)功耗小于100uW,延时不到10ms。
清微智能,拆开来,就是清华、微电子、人工智能,也就代表了这家公司的定位——专注可重构计算芯片,提供以端侧为基础,并向云侧延伸的芯片产品及解决方案。
其核心技术团队来自清华微电子学研究所(以下简称微电子所),其芯片所采用的架构正是中国芯片技术学术领军者——中国半导体行业协会IC设计分会理事长、清华大学微电子所所长魏少军教授所带领研发的可重构计算架构。
今日,智东西来到清微智能的办公室,和创始人兼CEO王博深入交流,看这家出身“名门”、即将满1周岁的AI芯片新秀,如何带着清华大学前沿的创新架构踏入产业的大门,如何快速在逐渐火热的AI芯片市场站稳脚跟。


谋定而后动,脱胎清华微电子系
清微智能成立于2018年7月,其技术脱胎于清华大学微电子学Thinker团队。
如今的芯片产业,放眼望去,数不胜数的国内外半导体企业高管从清华大学电子工程系和微电子所走出。
而微电子所的灵魂人物——现任清华大学微电子研究所所长、中国半导体行业协会IC设计分会理事长魏少军教授,在过去的十几年间一直深耕于一项核心技术——“软件定义芯片”,即可重构计算芯片技术。
意识到可重构计算架构对于芯片算力提升和功耗降低的巨大优势,2006年,魏少军教授牵头成立了清华大学可重构计算研究团队,而这支团队后来成为清微智能的核心。
2015年,AI复兴,对芯片运算能力产生了远高于传统芯片的要求,这个时候,沉寂了9年的可重构计算因其与AI算法契合的特性,开始重新进入“聚光灯下”。
自2016年起,基于可重构计算架构,魏少军教授团队中的清华大学微纳电子系副系主任尹首一副教授带队设计研发了4款Thinker系列的低功耗终端AI芯片,分别是实验性质的验证芯片Thinker I、人脸识别芯片Thinker II、语音识别芯片Thinker S、语音识别芯片Thinker IM。(AI芯片终极难题 被清华大学IC男神解决了!)

这三款芯片的设计方案一问世,就收获了国际学术界的认可。比如Thinker-I首次出现在2017VLSI国际研讨会上时,外界评价它“突破了神经网络计算和访存瓶颈,实现了高能效多模态混合神经网络计算。”
而清微智能CEO王博的本科和硕士均在北京邮电大学计算机通信专业就读,他与清华大学Thinker团队的相识,却来自一段同学缘分。
彼时,王博还在一家云计算方案提供商工作,负责智能硬件产品,他在做一款人脸识别智能门锁时,想要找到合适的芯片,却发现市面上的高通等公司无法满足他们对能耗比等性能的需求。
尹首一副教授的大学同学是王博的高中同学,两人因此结识。
王博得知尹首一副教授在带领Thinker团队做AI芯片,看到其芯片设计方案拥有出色的能耗比,再经过深入了解他们所设计的可重构计算架构的技术,王博对这一架构的扩展性感到认可,觉得这条路线是可行的。
预测到AIoT市场将步入全面爆发期后,2018年7月,王博牵头在北京中关村成立了清微智能公司,将技术产品化,由王博任CEO,尹首一副教授为首席科学家,欧阳鹏博士任CTO和Thinker芯片主架构师。
Thinker团队原本就分为两部分,一部分是尹首一副教授带领一些博士生从事整个架构的设计和优化工作,另一部分是清华以社招形式招进来的专门负责芯片实现的工程师。
清微智能的初始技术团队主要来自Thinker团队中负责实现芯片的工程师们,约一二十人,如今其团队数量已扩展到70多人。团队成员来自清华大学、NVIDIA、Sony等知名高校和企业,在半导体行业具备多年经验。
去年第三季度,清微智能拿到百度战投领投的近亿元天使轮融资,由百度战投、分众传媒、禧筠资本、国隆资本、西子联合控股等联合投资,而新一轮融资计划也将于近期启动。
而清微智能在成立不足一年的时间,就交出了TX210语音芯片百万数量级的量产,图像芯片也将于今年12月量产,这一成就,源自清华大学十多年扎实的技术积累、200多项技术专利。
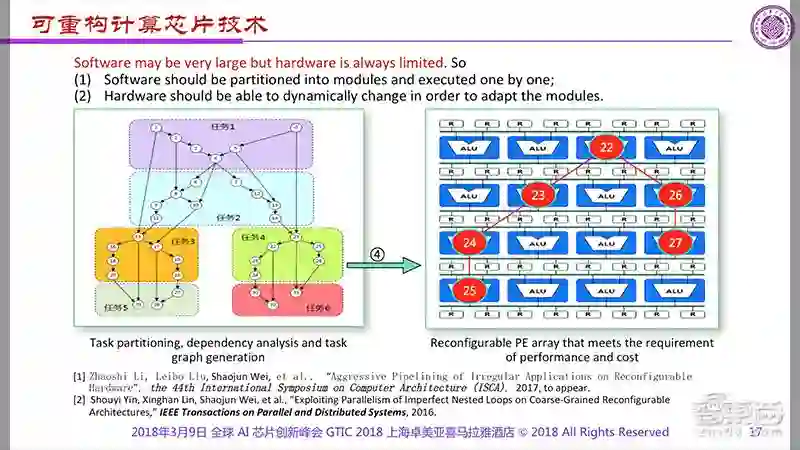
软件定义芯片:可重构计算芯片架构
在今年的全球AI芯片峰会GTIC 2019上,魏少军教授曾展示这样一张PPT。他将芯片分成三部分:第一部分是可更多编程的,如CPU;第二部分是能少量编程的,如GPU;第三部分是不能编程的,如专用芯片。

除了可编程性,这些不同计算架构的主要差别在于能效。专用芯片到GPU之间有1000倍的能效差距,而1000倍是一个很重要的分界线。
魏少军教授表示,如果我们的AI芯片做不到比GPU高1000倍的能效,就不能满足人们在终端侧的需求。
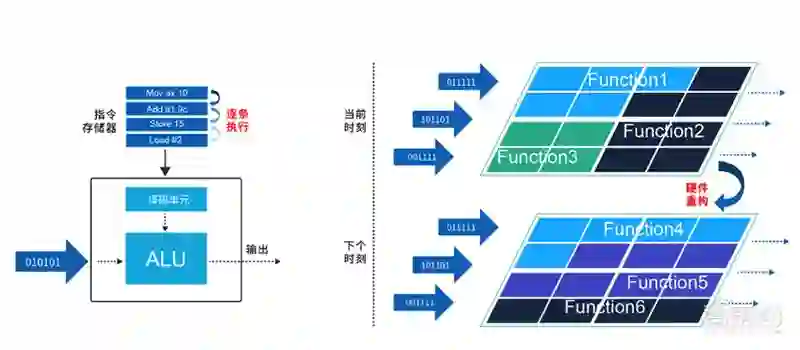
传统的终端AI芯片,主要基于CPU、DSP、GPU、NPU等架构,这些架构本质属于指令驱动的计算模式,属于冯·诺依曼架构。
这些架构在具体计算过程中,面向某一特定领域,往往存在高能效和灵活性不可兼得的问题,比如华为旗舰手机中强大的麒麟芯片,就不适用于安防摄像头、智能家居等场景。
它们需要从指令存储器中加载指令并解析指令,然后指导执行单元进行计算。在数据计算中,这是一种灵活但是低效的时域计算模式。
此外,在AI芯片的研发过程中,也有团队利用单指令流多数据流(SIMD)的方式来提高数据复用,从而减少指令解析,但是SIMD面向的是同构的操作,当指令功能变换时,仍需要重复前面的过程。

为了兼具高能效和可编程性,清华大学Thinker团队致力于研究的是一种无需指令驱动的计算模式,即动态可重构计算架构(CGRA,Coarse grain reconfigurable architecture),也就是上图红色区域。
它是一种非冯·诺依曼架构,简单而言,就是将软件通过不同的管道输送到硬件中来执行功能,使得芯片能够实时地根据软件/产品的需求改变功能,实现更加灵活的芯片设计。
传统的芯片需要让应用来适应架构,而CGRA架构更加灵活,能够根据数据流的特点,让软件来调整芯片的计算能力,在最合理分配和使用算力的同时,成倍节约了数据存储和传输带宽。
王博介绍说,CGRA架构适合AI、视频编解码、语音处理等计算密集型场景,但不适用于以逻辑判断为主的非计算密集型场景。
CGRA基于数据流图,面向的是异构的空域计算,一次配置形成固定的电路结构,从而以接近ASIC效率反复执行,资源利用率和数据复用率高。
同时,相比专用集成电路(ASIC)方式的固定电路结构,它又可以根据应用或者算法进行电路配置,使得硬件重新形成不同的计算电路结构,具有非常强的灵活性。
▲“指令驱动”的时域计算模式 v.s. “数据驱动、动态重构”的空间计算模式
以这个更低能耗和更强灵活性的架构为基础,清微智能CTO欧阳鹏透露,清微智能在具体的芯片设计上,又做了两方面深化。
1、支持混合精度计算
主流神经网络算法具有混合数据精度表示的特点,即不同的神经网络层可用不同数据位宽来表达中间数据或者权重数据的精度。
然而,传统AI架构无法高效支持混合精度计算,通常只能支持单一精度计算,或者只能通过扩展资源方式支持少数几种精度。
相较而言,清微AI芯片产品能支持从1bit-16bit的混合精度计算,同时,不同的神经网络层可以采用不同的精度表示,可以实时切换精度。
这源自CGRA架构的特点,在具体实现过程中,可重构模式动态重组计算资源和带宽,根据精度表示,让计算资源和带宽接近满负荷进行计算,从而将混合精度网络下的计算资源和带宽的利用率逼近极限,高效支持多种混合精度的神经网络。
2、优化非神经网络计算效率
AI算法不止有神经网络中卷积层、全连接层等逻辑,还有非神经网络计算逻辑。
比如在人脸检测和识别中,有NMS(非极大值抑制)以及仿射变换;在语音识别中,有FBANK/MFCC特征提取以及声学解码等。
而与此同时,非神经网络算法也在快速演进。比如最新NMS已经演化到Soft-NMS。
传统AI芯片架构强调了神经网络逻辑的计算效率,却忽视了非神经网络逻辑的计算效率。
针对非神经网络逻辑,一般仍然采用CPU或者DSP进行处理,或者采用ASIC进行固化。
清微AI芯片产品针对神经网络部分和非神经网络部分均进行了计算效率考虑。
针对非神经网络处理逻辑,从算法数据流图进行空间映射,以接近ASIC效率计算。
同时,其产品通过配置形成不同的电路结构来动态处理不同非神经网络计算逻辑,在保证灵活性前提下,计算效率有极大提升。
首款语音AI芯片量产,超强能效比
基于创新的CGRA架构,清微智能第一款实现规模化量产的语音AI芯片TX210拥有业界领先的算力、能耗比、时延、面积和成本。

据介绍,TX210采用台积电40nm ULP工艺,支持WLCSP和QFN两种产品封装。
该芯片支持离线语音唤醒功能,支持5个唤醒词和10个命令词,还支持声纹识别。它支持3-5m的远场语音唤醒和识别,工作频率为50MHz,延迟不到10ms。
继承CGRA架构的特点,TX210芯片可编程、可重构,在结构上有着极强的灵活性,支持多比特DNN神经网络,可以支持1-16bit位宽的神经网络计算,也支持FFT/MEL FILTER等。
由于语音AI芯片的应用场景非常丰富,可以应用至智能手机、可穿戴智能设备、小家电、大家电、玩具及车载等众多场景中,而低能耗又是从终端设备到用户都非常重视的性能。
对此,TX210针对语音交互场景做了更多优化。
比如为了保持在低功耗状态,它采用多级功耗唤醒模式,只有在通过麦克风检测到人声时,它才会被激活,准确监听到“唤醒词”后,TX210才会去唤醒处于休眠状态的主控处理器芯片。
另外,芯片支持一语直达功能,处理器只需要处理唤醒词之后的语音信号内容。
经过多重优化,TX210将工作功耗控制在2mW内,将语音活动检测(Voice Activity Detection,VAD)功耗降至100uW内。

该语音AI芯片的另一个特点是用极小的芯片面积支持丰富的接口和电源管理。
TX210的WLCSP封装面积仅有2.3 x 1.9mm2,适用于手机,蓝牙耳机等对体积要求苛刻的应用场景;同时TX210集成了LDO/ADC/BANDGAP/PGA等模拟器件,支持32K crystal输入,极大降低了用户的使用成本。
除此之外,在降噪方面,TX210也做了进一步优化,单麦基于深度学习进行降噪,双麦则是将传统算法与深度学习相结合,在典型信噪比下,TX210的唤醒识别率达95%,误识别率小于24小时一次。
据介绍,在TX210正式上市前,清微智能已与一些大型的互联网公司、智能手机及家电厂商建立了合作关系。
而这只是清微智能基于CGRA架构芯片的开始,他们的视觉芯片预计将在今年12月量产。
王博告诉智东西,目前他们规划CGRA架构18个月一迭代,下一代架构有望将算力再提高5-10倍。随着Thinker团队持续迭代更新CGRA架构,未来其语音芯片和视觉芯片的算力和能效比都将进一步提升。
在算法方面,清微智能在在算法压缩,量化以及硬件友好化设计方面有长期的积累,并与中科院、清华大学、乔治理工大学等开展了深入合作。
清微智能还研发了一套CGRA软件开发平台,这个平台兼容TensorFlow、Caffe等主流AI框架,可自动完成转换、解析、编译、生成等过程。他们自己的编译平台,允许用户从其它框架无缝迁移清微智能的芯片。

清微智能选择先切入终端AI芯片市场,这与当下的大环境不无关联。
去年,智能终端产品呈井喷式发展,智能音箱在2018年第四季度的出货量增长了95%。日前,工信部电子科技委副主任莫玮曾表示:“中国已成为全球最大的智能终端生产和消费国。”
但业界普遍认为,终端智能的渗透率尚不足1%。这意味着,智能终端市场规模远未达到预期,也意味着终端AI芯片市场的巨大潜力。
基于CGRA架构研发芯片的不止清微智能一家,美国创企Wave Computing采用这一架构的第二代DPU芯片预计将在明年面世,是一款7nm云端AI芯片。
至于清微智能是否有进军云端AI芯片的计划,王博表示,Thinker团队之前曾做出过成功的云端芯片,考虑到公司规模和投入阶段问题,他们想先在端侧验证架构的表现是出色的,等下一阶段有了足够积累,再去做云端芯片。

创新架构是AI芯片发展的关键
目前AI芯片产业化还在起步阶段,从算法到算力,能耗比刚刚能满足用户基础的需求。
由于AI计算需要很大算力,但传统的冯·诺依曼架构在计算密集型任务方面遇到了瓶颈,芯片设计底层架构的创新成为未来持续发展关键,王博认为,这也是很多AI创业公司集中出现的原因,大家都在同一起跑线上。
即便采用同一类架构,如CGRA,设计思路在本质上不会有太多差别,但每个处理元素(PE,Processing Element)中怎么设计、让它实现怎样的功能、处理元素之间怎样连接更高效……这些细节的设计与创新会决定各家芯片的差异。
除了架构创新,工艺、近阈值的技术等方法的进化也很重要,他们能在先进架构的基础上进一步提升芯片的性能。
王博也谈到,做芯片的本质上还是要独立流片以及建立一个完整的生态系统,而不是把各种功能的IP堆在一起就行。做好芯片的前提,是要拥有大量的芯片行业积累。
芯片还需面临越来越多的场景去定义创新,才能将前期费用分摊下去,才能盈利,如果没有几千万的场景去支撑,做芯片的意义就不存在了。
对于终端智能而言,上传云端的稳定性、延时、隐私、部署成本等问题仍亟待解决,即将出现的5G将使得更多设备能够联网互通,使得这些设备对终端智能的要求更加明确和丰富。
结语:终端AI芯片落地新战在即
从清微智能身上,我们看到更加新颖的一种芯片团队组合,他们不仅拥有来自学术大牛带队研发的前沿创新架构,还拥有产业经验丰富的工程师们。两强结合之下,清微智能既拥有高性能+极低功耗的芯片,又能快速推进产品完成变现。
近一两年,一批新玩家涌入终端AI芯片市场,但撇除那些为了实现垂直化整合或优化自身整体方案的AI算法公司、设备供应商等跨界玩家,市场机会逐渐聚拢在少数拥有创新架构的玩家身上。
终端AI芯片的落地之战才刚刚开始,技术路径、覆盖场景、落地速度、生态扩张等因素都有可能将这些玩家拉开差距,市场将检验出谁是能打持久战的企业。
本账号系网易新闻·网易号“各有态度”签约帐号




