想了解风头正劲的联邦学习?这篇包含400多个参考文献的综述论文满足你
选自arXiv
作者:Peter Kairouz 等
机器之心编译
参与:魔王、杜伟
联邦学习(Federated Learning,FL)指多个客户端在一个中央服务器下协作式地训练模型的机器学习设置,该设置同时保证训练数据去中心化。 联邦学习使用局部数据收集和最小化的原则,能够降低使用传统中心化机器学习和数据科学方法带来的一些系统性隐私风险和成本。 近期社区对联邦学习的研究出现爆发式增长,这篇论文探讨了联邦学习的近期进展,并展示了该领域所面临的开放性问题和挑战。 本论文作者来自澳大利亚国立大学、CMU、康奈尔大学、谷歌、香港科技大学等机构。


联邦学习是多个实体(客户端)协作解决机器学习问题的机器学习设置,它在一个中央服务器或服务提供商的协调下进行。 每个客户端的原始数据存储在本地,无法交换或迁移,联邦学习利用局部更新(用于立即聚合 (immediate aggregation))来实现学习目标。
问题识别:模型工程师找出要使用联邦学习解决的问题;
客户端设置:如有需要,将客户端(如在手机上运行的 app)设置为在本地存储必要的训练数据(尽管时间和数量都存在限制)。在很多案例中,app 已经存储了数据(如文本短信 app 必须存储文本信息,照片管理 app 存储照片)。但是,在另一些案例中,还需要保留额外的数据或元数据,如用户交互数据,以为监督学习任务提供标签;
模拟原型开发(可选):模型工程师可能为模型架构开发原型,并用代理数据集(proxy dataset)在联邦学习模拟环境中测试学习超参数;
联邦模型训练:启动多个联邦训练任务来训练模型的不同变体,或者使用不同的优化超参数;
(联邦)模型评估:在任务经过充分训练后(通常需要数天),分析模型并选择优秀的候选模型。分析可能包括在数据中心的标准数据集上计算得到的度量,或者模型在留出客户端上评估本地客户端数据的联邦评估结果;
部署:最后,在选择好模型之后,就要进入标准的模型部署流程了,该流程包括手动质量保证、实时 A/B 测试(在一些模型上使用新模型,在另一些模型上使用之前的模型,然后对比其性能)以及分阶段部署(staged rollout,这样可以在发现较差行为时及时回退,以免影响过多用户)。模型的特定安装流程由应用的所有者设置,通常独立于模型训练过程。也就是说,对使用联邦学习或传统数据中心方法训练得到的模型,都可以同样地使用该步骤。
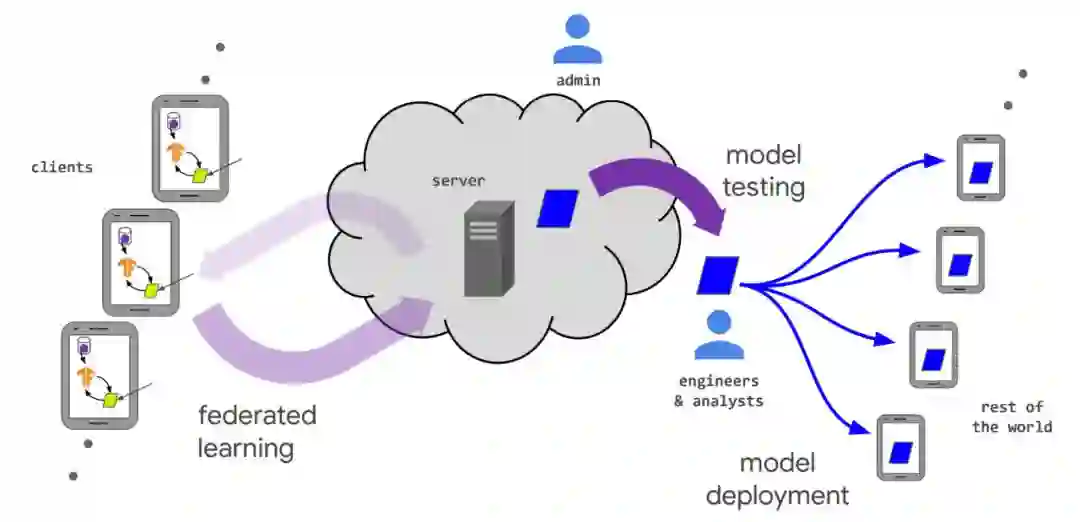
客户端选择:服务器从一组满足要求的客户端中进行采样。例如,服务器需要确认手机是否接通电源、在无限带宽 wi-fi 连接状态还是空闲状态,以避免影响设备用户;
广播(broadcast):选中的客户端从服务器下载当前模型权重和训练程序(如 TensorFlow graph [6]);
客户端计算:每个选中的设备通过执行训练程序在本地计算模型更新,例如在本地数据上运行 SGD(就像在联邦平均算法中那样);
聚合(aggregation):服务器收集全部设备更新。为了提高效率,一旦足够多的设备报告结果,则落后者会被丢弃。这一步也是其他技术的集成点,这些技术可能包括:能够增强隐私性的安全聚合、为提高通信效率对更新聚合执行有损压缩以及差分隐私所需的噪声添加和更新裁剪(update clipping);
模型更新:基于参与当前轮次的所有客户端计算得到聚合更新,服务器基于此在本地更新共享模型。

如上表 1 所示,联邦学习设置涉及大量问题。与具备明确设置和目标的领域相比,准确描述特定联邦学习设置的细节非常重要,尤其是当提出方法做出的假设不适用于所有设置时(如参与所有轮的有状态客户端);
当然,任何模拟的细节都应得到展示,以便研究可复现。但是,说明模拟要捕捉现实世界的哪些方面也很重要,这样才能使在模拟问题上成功的方法也能成功用于现实世界目标,并取得进展;
隐私和通信效率通常是联邦学习中的首要考虑因素,即使实验是使用公开数据在单个机器上运行的模拟实验。联邦学习在这方面更胜其他机器学习类型,因为对于提出的任何方法,明确计算发生地和通信内容都是十分重要的。










