统计挖掘那些事(三)-超详尽回归分析指南(理论+动手案例)


浩彬老撕,R语言中文社区特邀作者,好玩的IBM数据工程师,立志做数据科学界的段子手。
个人公众号:探数寻理
往期回顾:

一、理论部分
简单地说,一元线性回归和多元线性回归都属于简单线性回归范畴,最直接的差异在于一元线性回归的自变量只有一个,而多元线性回归的自变量存在多个。
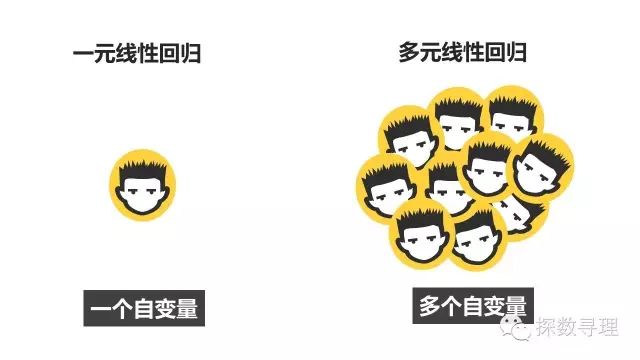
尽管主要的解决思路一致,大家可以把一元线性回归看作多元线性回归的特例,但在解决多元的问题上,咱们还是有比较多的问题需要注意。
回到咱们的回归方程,针对于此问题,我们需要关注的重点有3个:
(1)参数估计;(2)假设检验与评价;(3)变量选择
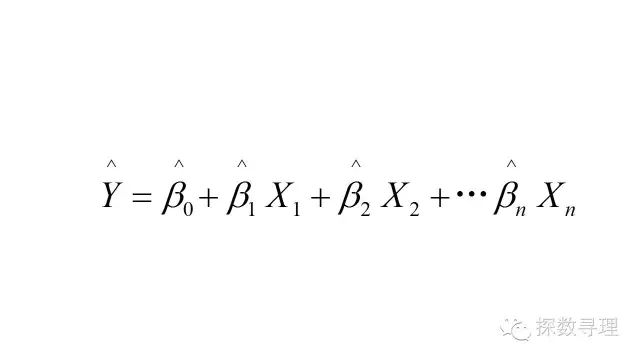
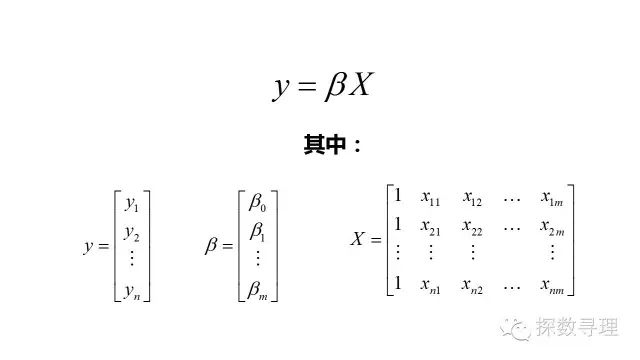
为了便于讨论,我们把上式改写成向量形式:
其中我们的数据集D中一共有n个样本,每个样本均可以由m个属性进行描述:
数据集D表示成矩阵X,第一列置为1,表示回归方程中的常数项
问题1:参数估计
针对于该方程中的未知参数,我们同样可以利用最小二乘法进行估计,损失函数方程有:


问题2:假设检验与评价

(1)F检验
与一元回归分析不一样,我们现在存在多个自变量。为了衡量整体方程的有效性,我们需要研究整体变量X是否有对y产生影响,也即意味着,我们需要验证的命题是:

也即对应的原假设:

为了验证该命题,我们可以借助F检验。
F检验是根据平方和分解式,从回归模型效果的角度进行验证。
平方和分解式有:
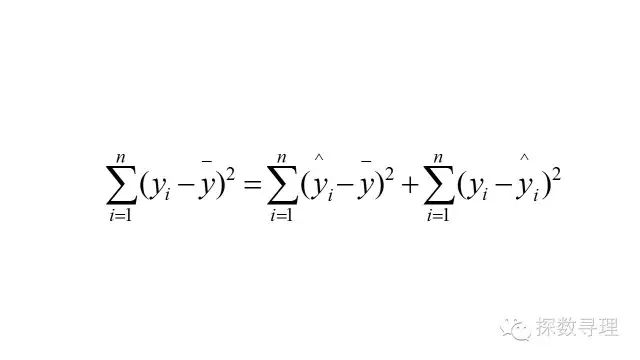
其中各项定义有:


通过以上的平方和分解式,我们成功把因变量的波动情况(SST)成功分解为两部分:(1)能够通过自变量x解释的部分(SSR);(2)不能由自变量x解释的部分(SSE);
因此构造F统计量如下:
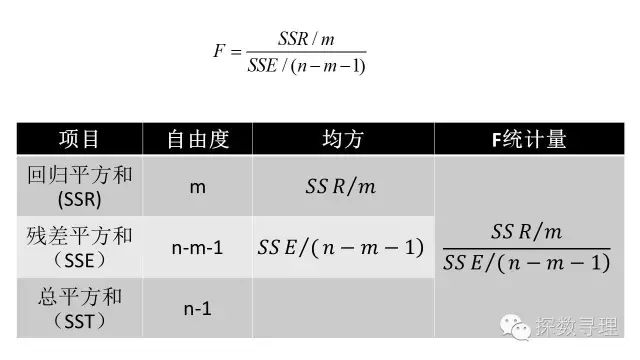
在正态假设的前提下,当原假设成立时,上述的F统计量将服从自由度为(m,n-m-1)的F分布,当F大于临界值时,我们可以拒绝原假设,即认为在显著水平a下,回归方程的整体自变量x与因变量y有显著的线性关系。
(2)t检验
正如在F检验中介绍的,通过原假设,F检验只能说明整体变量X与Y之间有关系,但是并不能说明某个自变量x是否与因变量y有关系,因此我们仍然需要t检验来判断每个自变量的显著性
由一元线性回归的t检验进行推广:假若我们需要检验某个变量xi是否显著(即对应的回归系数bi是否不为0),则可以生成原假设:


(3)偏F检验
事实上,即使是一元回归分析,我们也是可以使用F检验来判断回归方程的显著性,只是在一元回归分析中的t检验与F检验是完全等价的,而在多元回归分析中,则没有那么直接。
但是这是否意味着在多元回归分析中,t检验和F检验则是完全没有关系呢?答案显示是否定的。接下来,我们尝试从另一个视角,从总平方和分解的角度来考察自变量的显著性。
对于平方和分解公式,我们用回归平方和(SSR)反映自变量X对因变量Y的解释能力,那么假如我们要衡量某个特定的自变量x(j)的解释能力可以怎们做?
记对所有自变量得到回归平方和为SSR,剔除掉x(j)后,其他自变量得到回归方程的回归平方和为SSR(-j),显而易见地,变量x(j)对回归方程的贡献为:SSR(j)=SSR-SSR(-j),同样地,我们可以构造偏F统计量

(4)决定系数

让咱们再次回到平方和的分解公式:
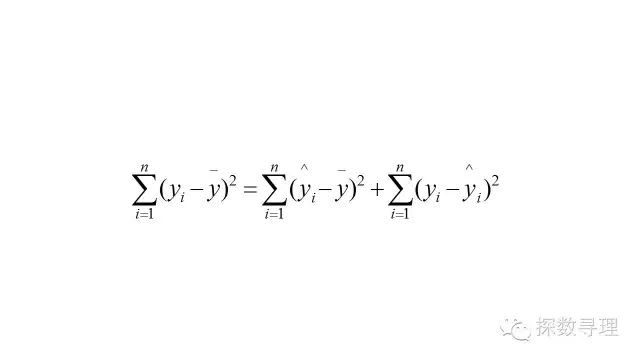
如我们在F检验中所讨论的,在整个分解式中,回归平方和(SSR)反映的是能够通过自变量x解释的部分,因此非常直观地,我们可以认定回归平方和所占的比重越大,则残差平方和越小,就越能证明回归的效果越好。
因此,我们不妨就把回归平方(SSR)和与总平方和(SST)的比值定义为决定系数,一般记作R方。
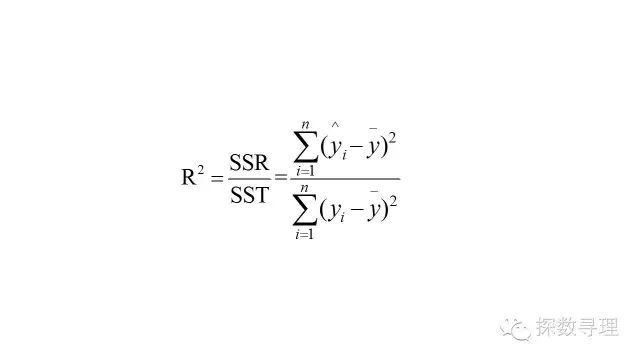
但值得注意的是,R方虽然经常被用作与评估线性回归模型的拟合好坏,但是却也存在着明显的不足:例如自变量越多,R方总是不减(事实上,随着自变量数目的增加,R方一般都是会增加)的,而不管这个自变量本身是否真的有效。

证明:

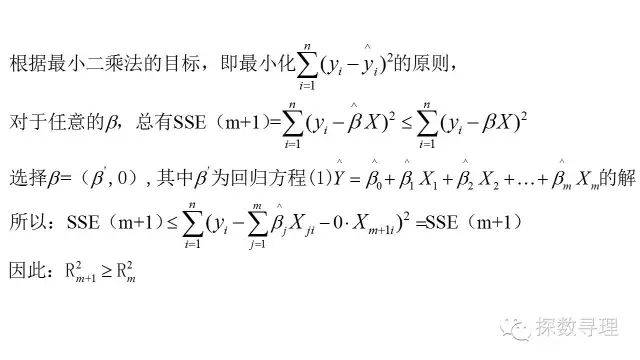
正如上述所证明的,随着自变量个数的增加,决定系数也随之增大,当自变量足够多的情况下,决定系数将表现得足够的“好”。极端情况下,当需要估计参数的数量与样本数量一致时,决定系数将能够达到1.
实际上,这种“好”是通过增加模型复杂度(也意味着牺牲了了残差自由度)所得到的,而随着模型复杂度越高,我们模型过拟合的情况可能就越严重,泛化能力就越差。关于模型过拟合的问题,浩彬老撕会在后面单独写一篇文章详细介绍。
因此为了避免这种无用的假象,我们需要在决定系数公式当中引入惩罚项,对于这个增加惩罚项的决定系数,我们一般称之为调整决定系数:

从公式可以看到,调整的R^2可以是一个负数,它总是小于/等于R方。另外不同于原有的R方,它只有在引入真正有助于分析的变量时,它才会得到增加。
问题(3)变量选择
正如我们所了解到的,并不是所有输入到模型的自变量x都能对因变量y产生显著作用,这就引出了咱们关于多元回归分析的第三个问题,怎么选择变量构建合适的方程。
一个显而易见的方法是,根据所有候选变量所形成的子集,求出所有可能的方程,再根据本文前面所提供的模型选择标准,例如调整r方,选择最优模型。
但该方法一个最大的问题是,对于存在m个变量的场景,我们需要构建(2^m)-1个方程组,显然,当自变量个数m十分大的时候,这是十分困难的。
因此人们为了能够更加简便快速的选择方程,提出了“前进法”,“后退法”以及“逐步回归法”。
实际上,上述的各种方法的核心在于借助于检验标准,控制自变量的进出,而这里的标准,实际上就是咱们在前面介绍的偏F检验。
(1)前进法:
前进法是一个变量由少到多的过程,它根据变量准入标准,每一步引入一个当前最重要的自变量,直至引入所有合乎标准的变量为止。具体做法如下:

(2)后退法
后退法与前进法的思想相反,它是一个变量由多到少的过程,后退法首先利用全部m个自变量建立全模型回归方程,再利用检验标准逐个剔除最不重要的变量,具体做法如下:

(3)逐步回归法
前进法和后退法都存在一个明显的不足,那就是变量的引入后无法再剔除(前进法)/变量被剔除后(无法再被引入),即所谓的“终身制”。
实际上,假定我们的的自变量间完全独立的话,上述前进法和后退法的“终身制”都是没有问题的,但在实际应用当中,我们的自变量往往存在着一定的相关关系,那么这就会带来问题了。
例如在前进法中,某个变量可能一开始是因为通过显著性检验而进入了方程,但在我们引入其他自变量后,这个变量可能就会显得不显著,但是这时候我们却没有办法将它重新剔除出模型了。
为了能够吸收前进法以及后退法的优点,因此提出了逐步回归法。逐步回归法的具体思想,实际上是在前进法的基础上,每当回归方程引入新的自变量后,都对方程中现有的变量重新检验,当发现有自变量不显著的情况下,则会将其重新剔除,具体做法如下:


二、实战部分

实战案例:
样例数据:房产价格分析.xlsx
下载链接:链接: https://pan.baidu.com/s/1gfBKCmB 密码: t95b
该数据集是某地区1998年的房产销售价格信息,包括属性:ID,建造年代,占地面积,室内面积,户外面积,价格

模型流如下所示:
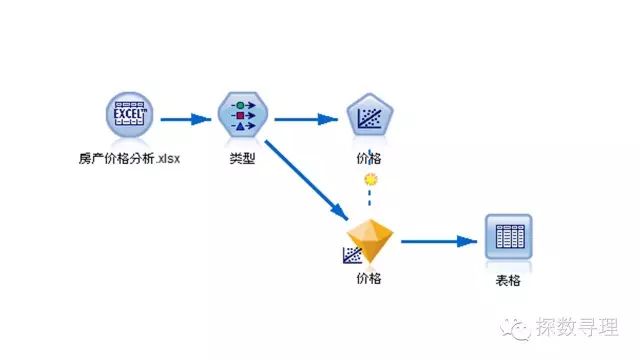
类型节点中:
(1)把ID设为记录表示,表示该属性只作为标识用而不参与建模;
(2)把建造年代,占地面积,室内面积,户外面积四个属性作为输入;
(3)把价格设为目标;
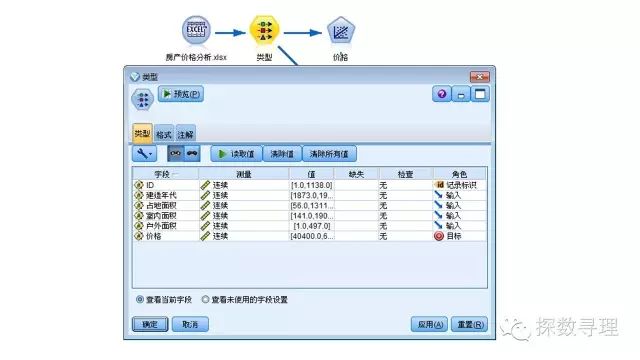
在下方建模选项板中,选中回归节点,并把回归节点添加到流。
在回归节点中,模型选项卡下,一共有四种方法:
(a)进入法:即把所有输入均作为自变量建立全模型;
(b)步进法:即逐步回归法;
(c)后退法
(d)前进法
在此处,我们选择步进法建立回归模型,确认后,运行模型;
运行模型后,点开模型块查看模型结果。
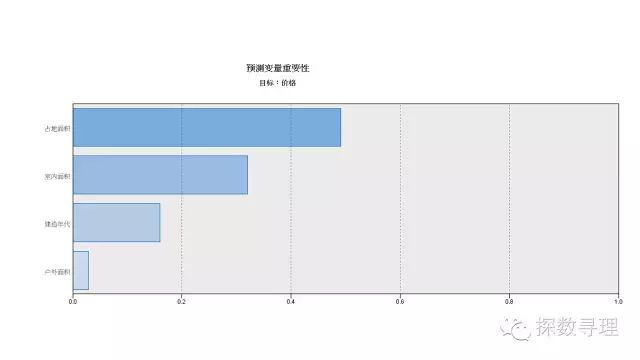
首先看到的是变量重要性,经过分析,模型认为占地面积是最重要的变量,室内面积次之,接下来就是建造年代和户外面积;
在模型块中的高级选项卡下,可以进一步查看模型结果。
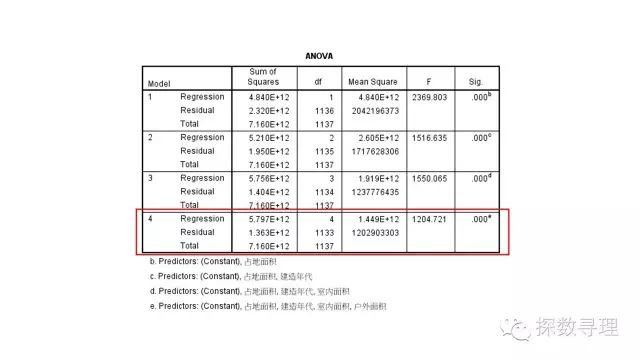
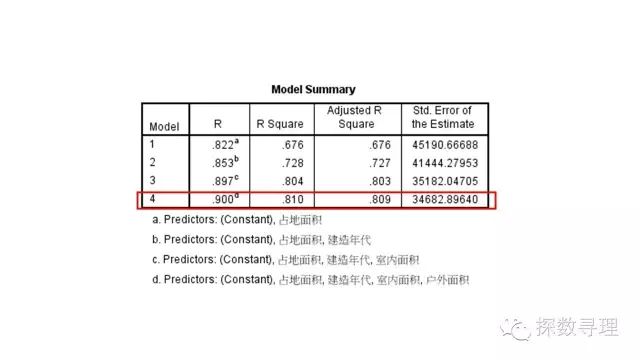
首先查看F检验结果,首先看到一共经历了4步构建出最终模型,按顺序分别引入了占地面积,建筑年代,室内面积,以及户外面积;下方表格对应了每一步所建立回归方程的F检验结果,可以看到最终结果的F统计量为1204.721,对应P值<0.05。
因此,我们认为回归方程整体显著,方程的自变量整体上对因变量销售价格有显著的线性影响
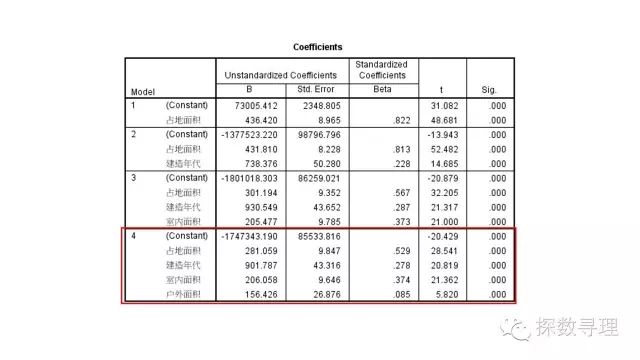
接下来查看系数检验的结果,从表中我们可以写出对应的回归方程式:
价格=-1747343.2+建造年代*901.8+占地面积*281.1+室内面积*206.1+户外面积*156.4
进一步地,我们也可以看到所有系数的t检验结果都是显著的。
最后查看拟合优度检验,可以看到R方值为0.81,调整R方值为0.809,说明我们所选择的自变量还是很能够解释因变量的影响。

事实上,处于篇幅的考虑,回归分析还有很大一部分内容未能涉及(部分证明也从略),关于这部分的内容我们老撕会在后续篇章再作补充。

公众号后台回复关键字即可学习
回复 R R语言快速入门及数据挖掘
回复 Kaggle案例 Kaggle十大案例精讲(连载中)
回复 文本挖掘 手把手教你做文本挖掘
回复 可视化 R语言可视化在商务场景中的应用
回复 大数据 大数据系列免费视频教程
回复 量化投资 张丹教你如何用R语言量化投资
回复 用户画像 京东大数据,揭秘用户画像
回复 数据挖掘 常用数据挖掘算法原理解释与应用
回复 机器学习 人工智能系列之机器学习与实践
回复 爬虫 R语言爬虫实战案例分享