最近,阿里安全一线风控发现,在禁售的风险防控库里,有人试图「上新」新品种,借助在社交媒体上走红的「魔法改运」等说辞,引入玄学骗局。这种安全风险如何防范呢?他们给出了答案。
对于阿里安全等风控部门来说,尽量提前发现风险问题,提早布防他们的日常工作。但是,风险对抗不断升级,各类风险词不断变异试图躲避各家平台管控,如果单靠人力防控,只会是杯水车薪。
针对类似具有行业共性的风险治理难题,业界和学界推动以技术创新探索网络风险治理。今年中国中文信息学会语言与知识计算专业委员会主办了「
CCKS 2021 通用百科知识图谱实体类型推断
」比赛,邀请国内 283 支队伍参赛。
12 月 25 日,比赛结果出炉,
阿里安全升级包含封建迷信、软色情、野生动植物保护、血腥暴力等重难点风险治理域在内的 AI 技术,并获得第一名
。
![]()
CCKS 2021 通用百科知识图谱实体类型推断竞赛获奖情况。
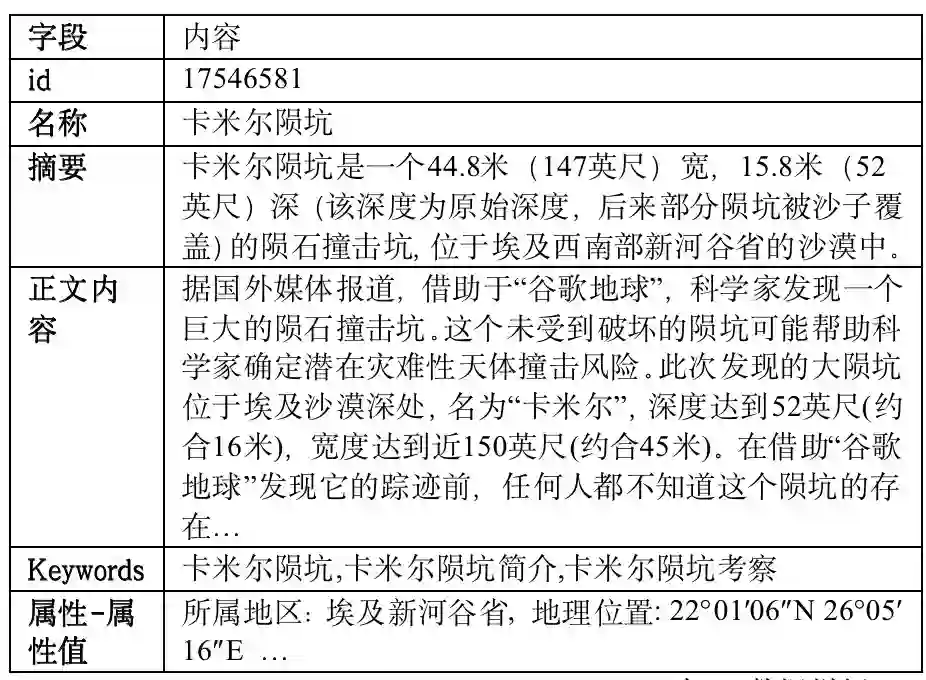
通用百科知识图谱实体类型推断任务围绕通用百科知识图谱构建中的实体类型推断展开,评测从实体百科页面出发,从给定的数据中推断相关实体的类型。数据示例如下:
任务涉及的类型包括组织机构、人物、作品、位置等多个领域,54 种实体类型。实体类型之间具有层级关系。标签体系如下:
![]()
实体类型推断任务指的是指通过上述实体的信息,对实体进行分类,上面示例中的卡米尔陨坑,其对应的标签是『位置_自然景观』。
与目前主流的学术评测不同,本次任务提供的 60 万 训练数据,全部没有标签
。这样的比赛设定更贴近于实际的工程场景,因此对参赛选手解决问题能力有着更高的要求。
此外,实体类型更加丰富,不同领域下包括多个具体的实体类型,整体任务包括几十个实体类型。某些实体可能只属于一个实体类型,某些实体可能属于多个实体类型,因此更加增添了任务的难度。比如「刘德华」既属于「歌手」类型,又属于「演员」类型;「知识图谱概念与技术」就只属于「书籍」类型。
由于训练数据没有标签的特性,如何利用最小的成本给训练数据打上标签,则成为了整个方案最重要的一环。本次评测,阿里安全
采用了多种低成本的方案,对数据进行打标
。
一方面是
弱监督
。通过外部高置信度的数据,训练模型,回标训练集。使用到的外部数据有维基百科、CN-DBpedia。其中,维基百科中的实体都是带有实体标签的,比如通过的标签映射中国男歌手即「人物 > 文艺工作者 > 歌手」, 即可得到外部的歌手数据。
通过此种方法,得到的外部数据共计 30 万条。给定树状结构标签,广度优先 + 剪枝进行递归遍历,获取每个子类别。利用类似的方法,在 CN-DBpedia 中得到数据 70 万条。
另一方面是
基于句法分析标签抽取
。通过分析训练数据,基于统计结果,大部分实体的首句,都包含了实体类型。基于 LTP 依存句法分析和语义角色标注的事件三元组抽取,可抽取出 (海贼王, 是, 漫画)。通过此部分逻辑,可给 Train 打标 20 万条数据。
![]()
实体类型推断任务,本质上是一个文本的多分类任务,因此
在模型的选择上,采用了预训练模型 + finetune 的方式作为基准(baseline)
。
![]()
需要分类的实体,本身包含名称、正文内容、多个属性对和关键词等特征。为了挑选出最佳的特征组合,阿里安全进行多组对照试验,最终得出结论:
输入为「实体名 + 数据源 + 摘要 + 属性名 + 关键词」效果最好
。
阿里安全尝试了多种预训练模型,其中
Roberta-large
效果最好。
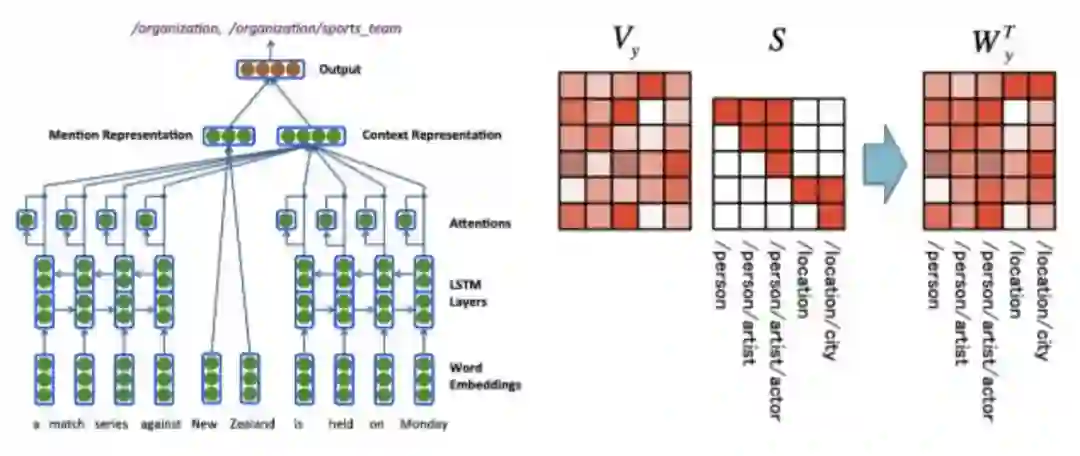
越细粒度的类别,父子标签所占的比重应该是不一样的。例如,如果选择了子标签,那么较粗的粒度肯定要选择父标签,而传统的损失函数在优化时,就是将它们平等对待的。因此,引入了层次分类最常用的几种损失,有效地解决了上述问题,并选用层级损失(Hierarchy loss)作为最终方案。
![]()
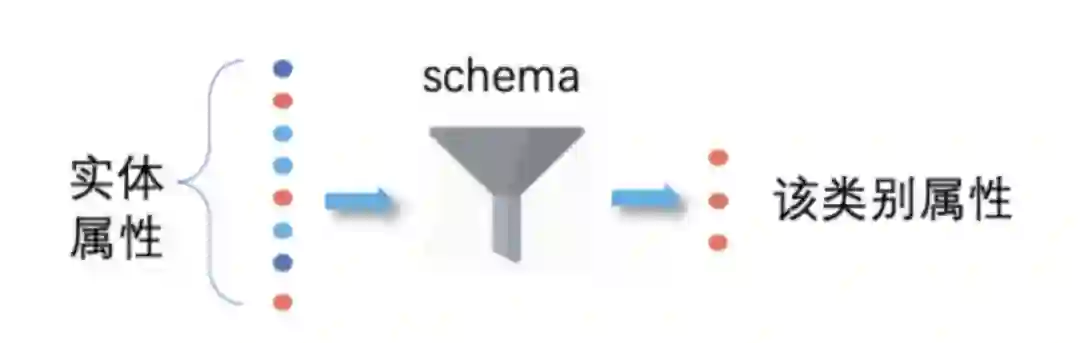
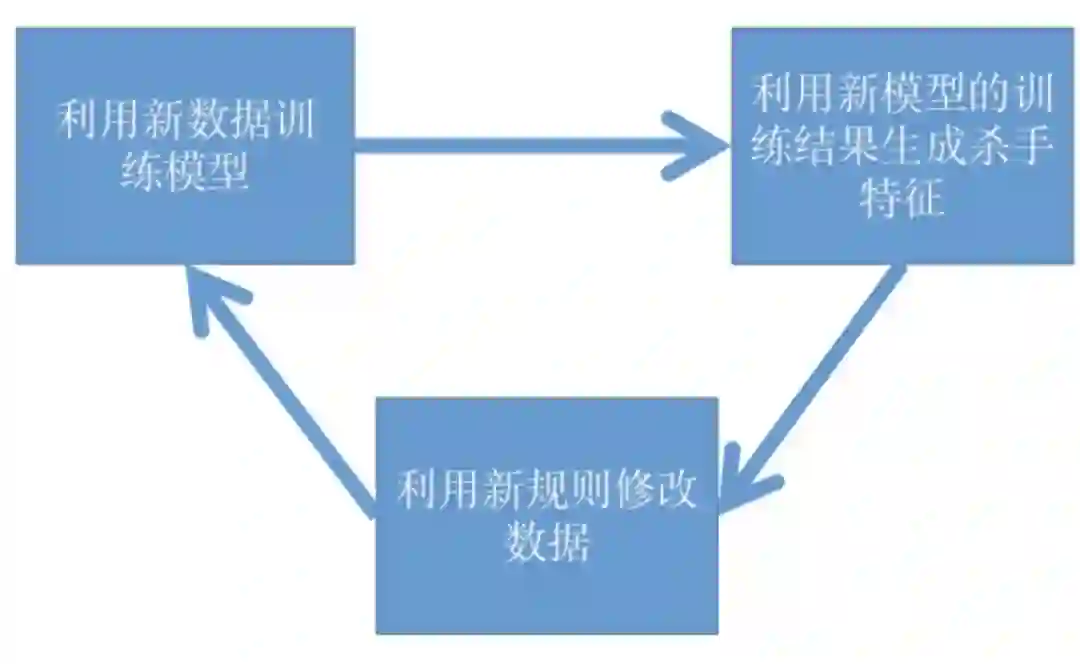
该方案类似于强化学习的思想,模型和数据相互正向优化,直至收敛。以游戏为例,通常会出现游戏类型这样的 schema 字段,反之,若一个实体若出现游戏类型,则大概率是游戏。类似游戏类型这样的 schema 或 keyword,称之为「必杀」特征。这种方式类似漏斗,可以通过必杀属性,进而过滤出具体类别的实体,如下图所示:
![]()
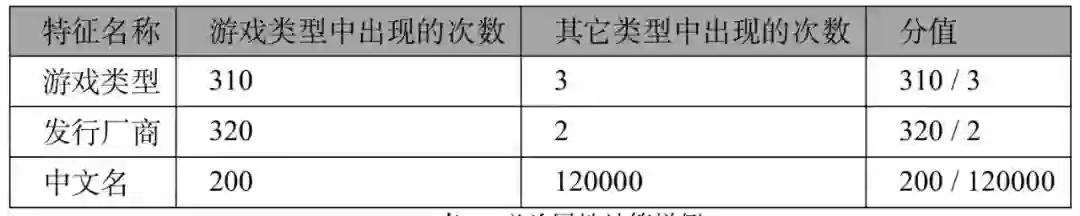
基于第一部分生成的 train,构建了一套自动生成「必杀」特征的逻辑,如下(1)对所有标签为游戏的数据进行统计,生成如下统计结果:
游戏类型 310 次
发行厂商 320 次
中文名 2000 次
以及(2)统计每个特征在其它类型中出现次数;(3)用在本类中出现的次数 / 其它类出现的次数,即为该特征的「必杀」特征。
![]()
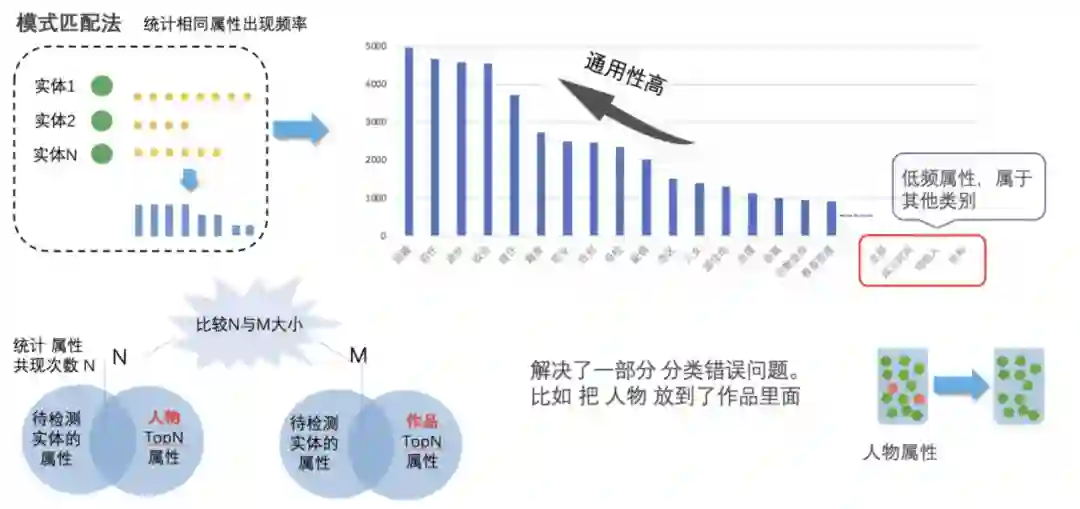
利用分值大于 6 的「必杀」特征,重新打标数据。除了「必杀」属性之外,阿里安全基于「模式匹配法」统计相同属性出现的频率。一方面,可以过滤掉低频属性,另一方面,基于假设:待验证实体的属性与 M 类属性共现的次数远远大于 N 类属性共现次数,可以判断该实体属于 M 类。用这种方法纠正了错误实体分类,如下图所示:
![]()
![]()
各电商平台上每天都会出现各种各样的新产品,
当面对新型商品时,如何判断其是否属于违规的商品类型则成为了一个非常重要的事情
。当出现以一个新的商品种类的时候,实体类型推断模块可以借助商品的描述信息,对此品类的商品进行类型推断,从而自动发现一些新的禁限售商品,从而提升违规商品的防控水位。
因此,
实体类型推断在知识图谱中具有非常重要的价值
,因此该任务也一直是研究的热点。而在实际应用场景中,新实体往往不会有百科那样多的文本特征使用,因此如何利用有限的数据资源,训练出更准确的实体类型推断系统则成为了一个非常有挑战的问题。
随着近期 prompt 方式的飞速发展,小样本甚至零样本的分类方法的效果都得到了大幅度的提高。但是在目前工业界主流的应用场景,还是强依赖于标注数据的高成本运作方式。未来,希望可以出现一套低成本且快速的范式,有效解决目前实体类型推断的难题。
![]()
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com