被视为代替Kafka的消息队列:Apache Pulsar设计简介
导读:在传统消息系统中,存在一些问题。一方面,消息的存储和服务一般是紧耦合的,节点的扩容和运维不便,特别是在需要多备份来保证高可用性的场景。另一方面,消息的消费模式被固定,在企业内部需要维护多套系统来保证不同的消息消费场景。另外消息系统中,多租户,多机房互备等企业级的特性和功能也不太丰富。
Apache Pulsar采用了分层的架构,解决了存储计算的耦合,同时提供了很好的扩展性和可维护性。Pulsar也通过订阅层的抽象,提供了统一的消息消费模型。特别是在Pulsar的设计之初,就注重对多租户,多机房互备等方面的需求,提供了众多完备的企业级的特性。
Apache Pulsar从2015年初在Yahoo全球近十个机房内部大规模部署,稳定服务了Yahoo内部邮箱,金融,Flickr,广告,NoSQL等众多的应用场景,一共创建了80多个租户,230多万个topic。 智联招聘在18年用Pulsar替换了线上原有的RabbitMQ,作为内部的消息总线,服务内部的20多个应用,每天会产生6亿多条消息和3TB的数据。在减轻硬件,运维和部署成本的同时,为系统提供了更好的服务质量和扩展性。
Apache Pulsar,是一个使用Apache Bookkeeper提供持久化的pub/sub消息平台,它可以提供如下特性:
跨地域复制
多租户
零数据丢失
零Rebalancing时间
统一的队列和流模型
高可扩展性
高吞吐量
Pulsar Proxy
函数
Apache Pulsar的文档对这些特性都有详细解释,有兴趣可以去看官方文档。
架构
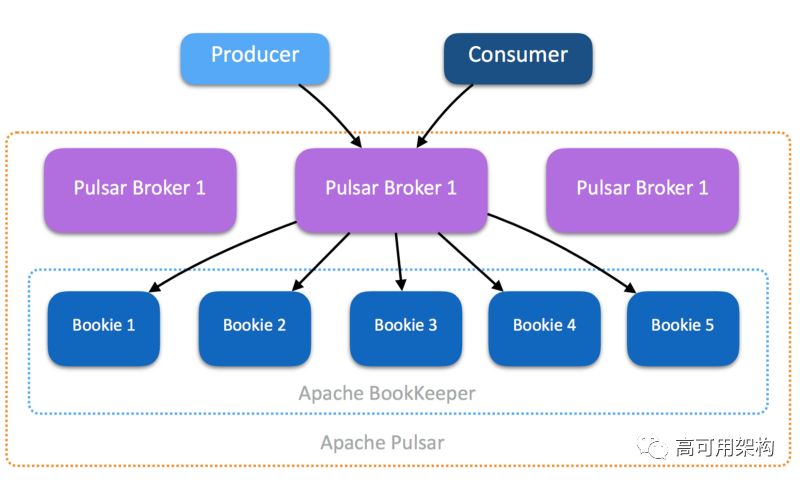
Pulsar使用分层结构,将存储机制与broker隔离开来。此体系结构为Pulsar提供以下好处:
独立扩展broker
独立扩展存储(Bookies)
更容易容器化Zookeeper, Broker and Bookies
ZooKeeper提供集群的配置和状态存储
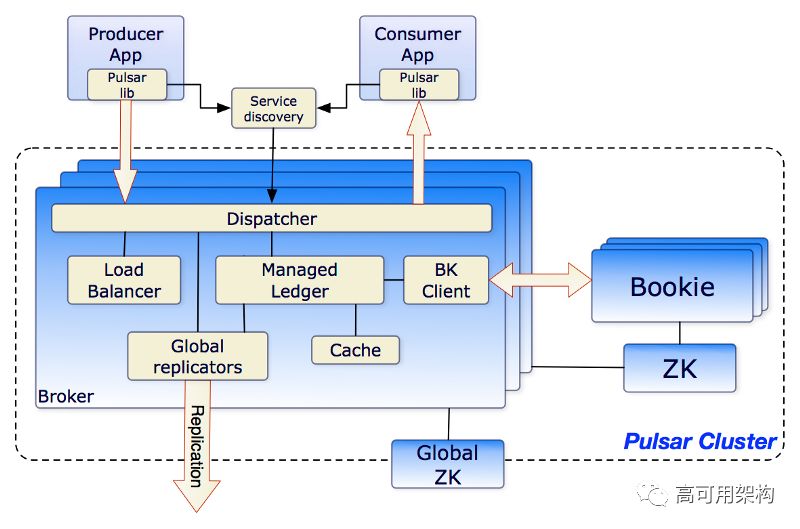
亮点如下:
负载均衡器:Pulsar内置负载均衡器,可在内部将负载分配给所有broker
服务发现:Pulsar具有内置的服务发现功能,可以识别在何处以及如何连接到broker。
全局复制器:可以在为同一个命名空间配置的N个borker之间复制数据。
全局ZK: 全局ZK用于实现跨地域复制
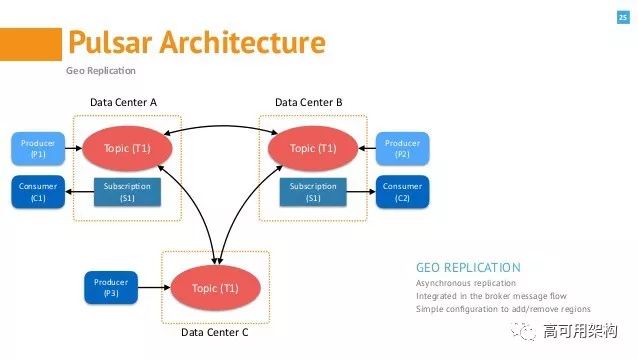
跨地域复制
跨地域复制是Pulsar提供的解决方案。全局集群可以在名称空间级别进行配置,以便在任意数量的集群(n-wayMesh解决方案)中进行复制。从下面的示例中,数据中心C没有消费者,但数据中心A或B中仍会根据订阅模型消费消息。
多租户
多租户特性通过对数据存储的隔离,帮助为企业建立Pulsar集群。这一内置功能将大大降低组织的基础设施建设和运营成本。
零Rebalancing时间
Pulsar的分层架构和代理的无状态性质有助于实现零Rebalancing时间。如果一个新的broker被添加到集群中,它将立即可用;无需在集群中rebalancing数据。
从Bookies的角度来看:当一个新的Bookie添加到集群中时,由于其底层的分布式日志架构(读/写隔离),该节点立刻可以写入数据。基于段复制配置的数据rebalance在后台进行,不会对集群产生任何影响。
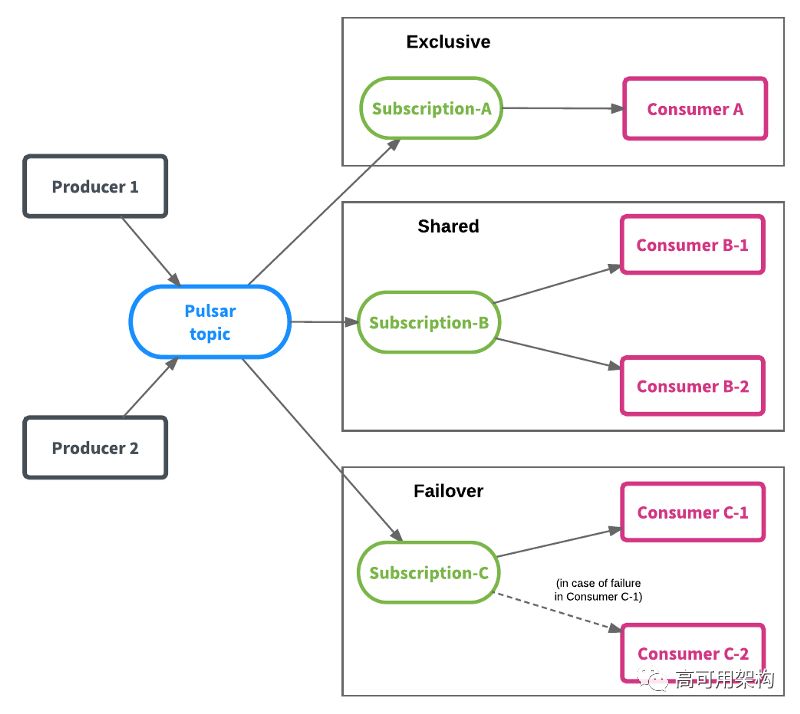
统一的队列和流模型
Pulsar使用同一个模型支持流和队列语义。这个特性可以通过订阅模型实现。消费者使用订阅模型中的任何一个订阅主题:
Exclusive - 支持流语义
Failover - 支持流语义
Shared - 支持队列语义
函数
函数是能够在Pulsar内部或外部存在的本地监听器。从用途本身来看,函数可用于基于内容的路由,这将帮助企业应用程序路由预期的消息。
Proxy
当broker部署在云或Kubernetes中时,需要使用proxy将broker暴露于外部世界。Proxy本身可以提供身份验证和授权。Proxy内置将授权令牌传递给broker以进行命名空间权限验证的功能。
结论
Apache Pulsar使用基于分层体系结构的pub/sub模型,它具有跨地域复制、多租户、零Rebalancing时间等功能。
原文地址:https://medium.com/@pckeyan/apache-pulsar-gentle-introduction-465ca6da0e18
参考阅读:
本文作者Karthikeyan Palanivelu,由方圆翻译。转载本文请注明出处,欢迎更多小伙伴加入翻译及投稿文章的行列,详情请戳公众号菜单「联系我们」。
GIAC全球互联网架构大会深圳站将于2019年6月举行,Apache Pulsar和Apache BookKeeper的PMC成员和Committer翟佳将作为中间件专场的讲师出席2019年GIAC深圳站,并做关于Apache Pulsar的演讲。参加2019年GIAC深圳站,可以了解业界动态,和业界专家近距离接触。


参加 GIAC,盘点2019年最新技术,目前购买7.5折优惠 ,多人购买有更多优惠。识别二维码了解大会更多详情。