清华178页深度报告:一文看懂AI数据挖掘

来源:智东西
摘要:数据挖掘(Data Mining)是一门跨学科的计算机科学分支,它用人工智能、机器学习、统计学和数据库的交叉方法,在大规模数据中发现隐含模式,在零售、物流、旅游等行业有着广泛应用场景。
在数据爆炸的时代里,如何利用手中数据资源提高行业效率、提高行业质量,成为了众多企业决策者所关注的问题,数据挖掘也逐渐成为当下的热门研究领域之一,受到了谷歌、亚马逊、阿里、百度等科技巨头的追捧。
来自清华大学人工智能研究院、北京智源人工智能研究院、清华-工程院知识智能联合研究中心联合推出的人工智能数据挖掘报告,详细解读了数据挖掘技术应用领域、研究概念、算法实现、与发展趋势。


数据挖掘与KDD
数据挖掘(Data Mining),是指从大量的数据中自动搜索隐藏于其中的有着特殊关系性的数据和信息,并将其转化为计算机可处理的结构化表示。
目前数据挖掘的主要功能包括概念描述、关联分析、分类、聚类和偏差检测等,用于描述对象内涵、概括对象特征、发现数据规律、检测异常数据等。
一般来说,数据挖掘过程有五个步骤:确定挖掘目的、数据准备、进行数据挖掘、结果分析、知识的同化。
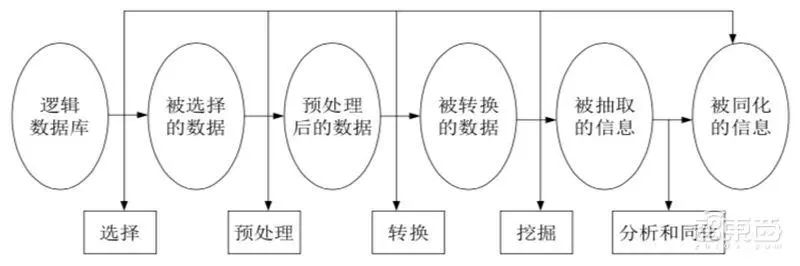
▲数据挖掘过程基本步骤
1、确定挖掘目的
认清数据挖掘的目的是数据挖掘的重要一步。挖掘的最后结果是不可预测的,但要探索的问题应是有预见的。
2、数据准备
数据准备又分为三个阶段:
1)数据的选择:搜索所有与目标对象有关的内部和外部数据信息,并从中选择出适用于数据挖掘应用的数据;
2)数据的预处理:研究数据的质量,为进一步的分析做准备,并确定将要进行的挖掘操作的类型;
3)数据的转换:将数据转换成一个分析模型。这个分析模型是针对挖掘算法建立的。建立一个真正适合挖掘算法的分析模型是数据挖掘成功的关键。
3、进行数据挖掘
对得到的经过转换的数据进行挖掘。
4、结果分析
解释并评估结果,其使用的分析方法一般应视数据挖掘操作而定,通常会用到可视化技术。
5、知识的同化
将分析所得到的知识集成到所要应用的地方去。

▲数据挖掘的分类表
如上图所示,数据挖掘有多种分类方式,可以按照挖掘的数据库类型、挖掘的知识类型、挖掘所用的技术类型进行分类。
同时,数据挖掘也可以按照行业应用来进行分类,比如生物医学、交通、金融等行业都有其独特的数据挖掘方法,不能做到用同一个数据挖掘技术应用到各个行业领域。
数据挖掘是知识发现(KDD)的一个关键步骤。1989年8月,Gregory I. Piatetsky- Shapiro等人在美国底特律的国际人工智能联合会议(IJCAI)上召开了一个专题讨论会(workshop),首次提出了知识发现(Knowledge Discovery in Database,KDD)这一概念。
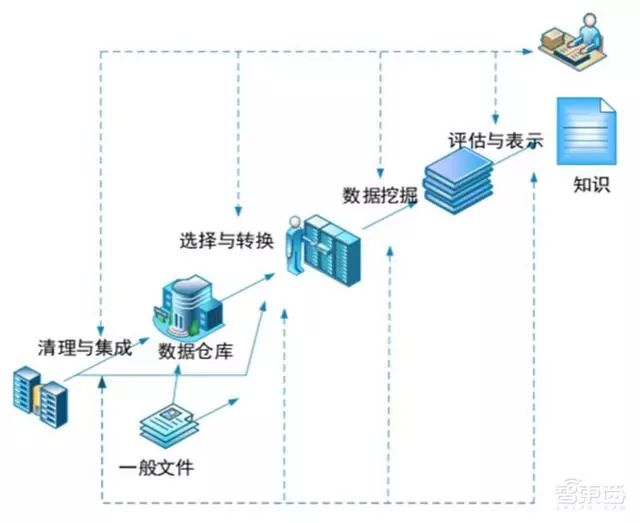
▲数据挖掘是知识发现的过程之一
KDD涉及数据库、机器学习、统计学、模式识别、数据可视化、高性能计算、知识获取、神经网络、信息检索等众多学科和技术的集成,再后来的30年间KDD逐渐形成了一个独立、蓬勃发展的交叉研究领域。
早期比较有影响力的发现算法有:IBM的Rakesh Agrawal的关联算法、UIUC大学韩家炜(Jiawei Han)教授等人的FP Tree算法、澳大利亚的John Ross Quinlan教授的分类算法、密西根州立大学Erick Goodman的遗传算法等等。
目前,数据挖掘已经引起国际、国内工业界的广泛关注,IBM、谷歌、亚马逊、微软、Facebook、阿里巴巴、腾讯、百度等都在数据挖掘研究方面进行了应用与理论研究。
国际知识发现与数据挖掘大会(ACM SIGKDD Conference on Knowledge Discovery and Data Mining,简称SIGKDD)是数据挖掘领域的顶级国际会议,由ACM的数据挖掘及知识发现专委会负责协调筹办,会议内容涵盖数据挖掘的基础理论、算法和实际应用。

数据挖掘源于商业的直接需求
数据挖掘技术从一开始就是面向应用的,源于商业的直接需求。目前数据挖掘在零售、旅游、物流、医学等领域都有所应用,可以大大提高行业效率和行业质量。
举个例子,零售是数据挖掘的主要应用领域之一。这是因为由于条形码技术的发展使得前端收款机系统可以收集大量售货、顾客购买历史记录、货物进出状况、消费与服务记录等数据。
数据挖掘技术有助于识别顾客购买行为,发现顾客购买模式和趋势,改进服务质量,取得更高的顾客保持力和满意程度,减少零售业成本。
同时,同一顾客在不同时期购买的商品数据可以分组为序列,序列模式挖掘可用于分析顾客的消费或忠诚度的变化,据此对价格和商品的花样加以调整和更新,以便留住老客户,吸引新客户。
与此同时,社交网络也是数据挖掘研究中的热门领域,比如新浪微博就是拥有海量数据的资讯平台。
截止到2017年12月,新郎微博已拥有接近4亿活跃用户,内容存量超千亿,“大V”的一举一动和社会热点话题都会引起大量的评论与转发,掀起一股“数据风暴”。
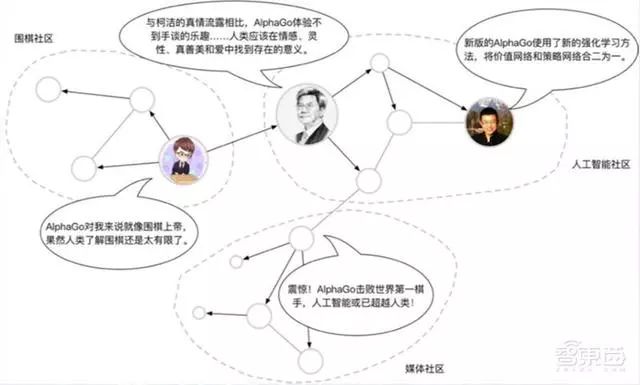
▲柯洁乌镇大战AlphaGo撼负后的微博热议
微博上每个用户的言论、转发内容等都蕴藏着用户个人的兴趣、话题等信息,文字内容本身的智能分析理解也是数据分析领域长久以来孜孜不倦追求的目标。
社会网络中的聚类被称为社区发现,许多精心设计的高效算法可以很好地处理上亿用户的大规模网络。
针对微博用户的海量数据,对其进行数据描述性可以分析群体的年龄、性别比例、职业等;对于平均数、中位数、分位数、方差等统计指标可以帮助我们粗略了解数据分布;回归分析、方差分析等方法则可以解释年龄、职业等因素是否会影响用户对某热门话题的关注程度。
此外,数据挖掘在旅游、物流、医学等领域都有着广泛的应用场景。比如数据挖掘可以对旅游客流的趋向有着准确的预知性,同时对于游客的喜好也有着直接性的掌握;从医学数据中寻找潜在的关系或规律,可以获得对病人进行诊断、治疗的有效知识,增加对疾病预测的准确性等。

人工智能与数据挖掘
数据挖掘从一个新的视角将数据库技术、统计学、机器学习、信息检索技术、数据可视化和模式识别与人工智能等领域有机结合起来,它组合了各个领域的优点,因而能从数据中挖掘到运用其他传统方法不能发现的有用知识。
一般来说,统计特征只能反映数据的极少量信息。简单的统计分析可以帮助我们了解数据,如果希望对大数据进行逐个地、更深层次地探索,总结出规律和模型,则需要更加智能的基于机器学习的数据分析方法。
所谓“机器学习”,是基于数据本身的,自动构建解决问题的规则与方法。数据挖掘中既可以用到非监督学习方法,也可以用到监督学习方法。
1、非监督学习
非监督学习是建立在所有数据的标签,即所属的类别都是未知的情况下使用的分类方法。对于特定的一组数据,不知道这些数据应该分为哪几类,也不知道这些类别本来应该有怎样的特征,只知道每个数据的特征向量。若按它们的相关程度分成很多类,最先想到的想法就是认为特征空间中距离较近的向量之间也较为相关,倘若一个元素只和其中某些元素比较接近,和另一些元素则相距较远。
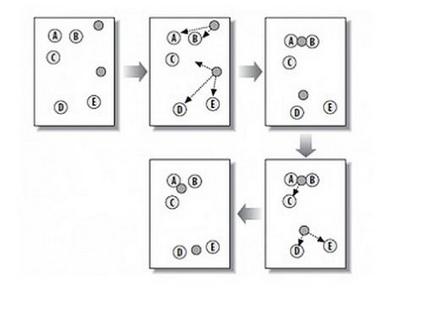
这时候,我们就希望每一个类有一个“中心”,“中心”也是特征向量空间中的向量,是所有那一类的元素在向量空间上的重心,即他的每一维为所有包含在这一类中的元素的那一维的平均值。如果每一类都有这么一个“中心”,那么我们在分类数据时,只需要看他离哪个“中心”的距离最近,就将他分到该类即可,这也就是K-means算法的思路。
K-means算法,在1957年由Stuart Lloyd在贝尔实验室提出,最初用于解决连续的图区域划分问题,1982年正式发表。1965年,E.W.Forgy发明了Lloyd-Forgy or。James MacQueen在1967年将其命名为K-means算法。
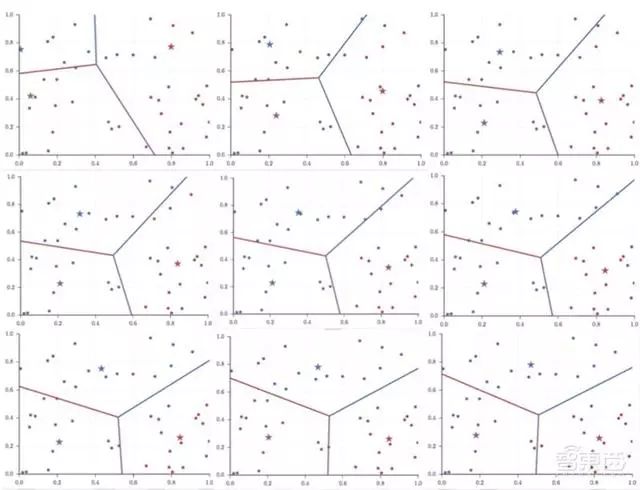
上图是以随机生成的数据点为例,k=3的K-means算法的迭代过程,其中五角星为聚类中心,点的颜色是其类别。在实际应用中,为了获得一个比较好的特征空间,使得“数据之间的相似性与他们在特征空间上的距离有关,距离越近越相似”这句话尽可能成立,我们往往会构建模型来把原数据变换到这么一个特征空间,然后使用K-means算法来进行分类。
2、监督学习
不同于非监督学习,若已知一些数据上的真实分类情况,现在要对新的未知的数据进行分类。这时候利用已知的分类信息,可以得到一些更精确的分类方法,这些就是监督学习方法。
1)决策树模型
所谓决策树,即是一种根据条件来进行判断的逻辑框架。其中,判断的条件,即提出有区分性的问题,以及对于不同的回答下一步的反映,以及最终的决策给出标签。
决策树算法:
1.选取包含所有数据的全集为算法的初始集合A0:
2.对于当前的集合A,计算所有可能的“问题”在训练集上的F(A,D):
3.选择F(A,D)最大的“问题”,对数据进行提问,将当前的集合由“问题”的不同回答,划分为数个子集;
4.对每个子集,重复b、c,直到所有子集内所有元素的类别相同;
5.在实际应用中,数据往往有很多特征,因此,“问题”往往是选取数据的某一特征,而“回答”则是此特征对应的值。
在决策树中,效度函数F(A,D)的选择非常重要。决策树的发展历史,也基本是围绕着F(A,D)的优化而展开。
2)kNN算法
只知道每个数据在特征空间下的特征向量情况下,可以对数据采用无监督分类方法K-means。如果我们拥有了其中一部分数据的标签,我们就可以利用这些标签进行kNN分类。
数据之间的相似性与他们在特征空间上的距离有关。距离越近越相似,越可能拥有相同的标签。
假设我们已经有了很多既知道特征向量也知道具体标签的数据对于新的只知道特征向量却不知道具体标签的数据,我们可以选取离这个特征向量最近的k个已经知道标签的数据,然后选取他们中间最多的元素所属于的那个标签,作为新数据的预测标签。也可以根据他们与新数据的特征向量之间的距离加权(如最近得5分,第二近得4分等),取权重总和最大的标签作为预测标签。
kNN算法不需要构建模型或者训练,和K-means算法一样,往往是和某个构建特征空间的模型一起使用。
此外,还有回归分类、神经网络、朴素贝叶斯分类等等。

巨头们的数据挖掘之路
在当下,数据挖掘也逐渐成为当下的热门研究领域之一,受到了谷歌、亚马逊、微软、百度、阿里、腾讯等科技巨头的追捧。
1、谷歌
谷歌几乎每年都会发表一些让人惊艳的研究工作,包括之前的MapReduce、Word2Vec、BigTable,近期的BERT。数据挖掘是谷歌研究的一个重点领域。
2018年谷歌全球不同研究中心在数据挖掘顶级国际会议KDD上一共发表了7篇文章。
2、亚马逊
亚马逊公司近几年发展势头超级猛,前几年华丽的转身:从一个网上商店公司变为云平台公司再转变到目前的人工智能公司,亚马逊也在数据挖掘领域开始占有一席,尤其是在人才网罗、开源、核心技术研发。
2018年亚马逊在数据挖掘顶级国际会议KDD的Applied Data Science Track(应用数据科学Track)上一共发表了2篇文章,另外还有两个应用科学的邀请报告。
3、微软
微软是老牌论文王国,一直以来都在学术界特别活跃,因此在KDD上每年和微软有关的论文非常多,因此这里只统计了微软作为第一作者的文章。
2018年在数据挖掘顶级国际会议KDD上一共发表了6篇文章,另外还有一个应用科学的邀请报告,这些文章和报告都更多的从大数据的角度在思考如何更有效,更快速的分析。
4、阿里巴巴
阿里巴巴在电子商务方面做了大量的数据挖掘研究。尤其是在表示学习和增强学习做了几个很有意思的工作。
2018年阿里巴巴在数据挖掘顶级国际会议KDD上作为第一作者单位一共发表了8篇文章。
5、腾讯
2018年腾讯在数据挖掘顶级国际会议KDD上作为第一作者单位一共发表了2篇文章。
6、百度
2018年百度在数据挖掘顶级国际会议KDD上作为第一作者单位一共发表了2篇文章。

大数据与数据挖掘
大数据是近年随着互联网、物联网、通信网络以及人类社交网络快速发展的结果,成为一个交叉研究学科,和数据挖掘紧密相连。
大数据的迅速发展也使得数据挖掘对象变得更为复杂,不仅包括人类社会与物理世界的复杂联系,还包括呈现出的高度动态化。这使得很多传统数据挖掘算法不再适用,传统数据挖掘算法必须满足对真实数据和实时数据的处理能力,才能从大量无序数据中获取真正价值。
一方面大数据包含数据挖掘的各个阶段,即数据收集、预处理、特征选择、模式挖掘、表示等;另一方面大数据的基础架构又为数据挖掘提供上层数据处理的硬件设施。
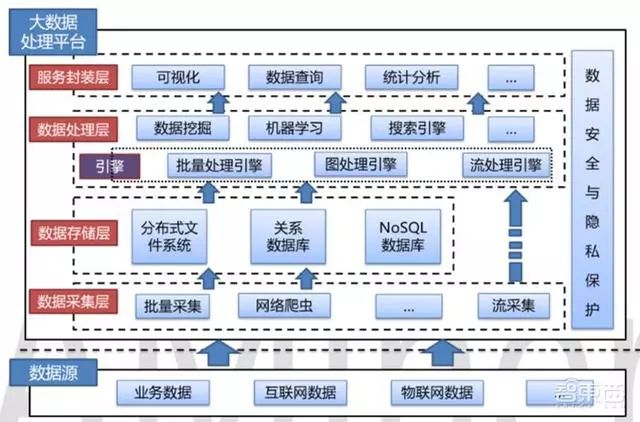
▲大数据处理平台技术架构图
从技术架构角度,大数据处理平台可划分为4个层次:数据采集层、数据存储层、数据处理层和服务封装层。
除此之外,大数据处理平台一般还包括数据安全和隐式保护模块,这一模块贯穿大数据处理平台的各个层次。
智东西认为,随着大数据时代的来临,各行各业所积累的数据呈爆炸式增长,数据挖掘在各个领域的需求将会越来越强烈,与各个专业领域的结合也将会越来越广泛。无论是在科学领域还是工程领域、理论研究还是现实生活中,数据挖掘都将有着极为广阔的发展前景。
未来智能实验室是人工智能学家与科学院相关机构联合成立的人工智能,互联网和脑科学交叉研究机构。
未来智能实验室的主要工作包括:建立AI智能系统智商评测体系,开展世界人工智能智商评测;开展互联网(城市)云脑研究计划,构建互联网(城市)云脑技术和企业图谱,为提升企业,行业与城市的智能水平服务。
如果您对实验室的研究感兴趣,欢迎加入未来智能实验室线上平台。扫描以下二维码或点击本文左下角“阅读原文”