突破!DNA 上的 SQL 查询已经成为现实
几年前,连研究人员都不愿使用DNA来存储数据,觉得这么做太超前了,不具有任何实用价值。今天,你可以使用合适的软件和生化模块来扩展PostgreSQL,并在DNA上运行SQL。
当下全世界的数据浪潮来势凶猛,不仅超出了我们理解数字和衡量单位(比如泽字节)的能力,还超出了我们存储海量数据的能力。
一切都变得数字化,一切都日益在基于算法的应用软件上运行,这些算法拿数据来训练,反过来生成更多的数据,馈送给为更多的下游应用软件和算法……结果可想而知。
简而言之,按照这种步伐,很快就没有足够的数据存储和计算材料以满足需求。这就是为什么人们现在一直在寻找替代的存储介质以存储数据。使用DNA存储数据乍一听很奇怪,实际上大有意义。现在研究人员已取得了重大突破,他们因而能够将DNA存储整合到PostgreSQL这种流行的开源数据库中。
DNA是一种信息编码机制
究其核心,DNA是一个数据存储层。DNA由四种基础部分组成:腺嘌呤、鸟嘌呤、胞嘧啶和胸腺嘧啶(又名AGCT)。DNA由这四个碱基组成三个核苷酸形成的三联体(名为密码子)。密码子是给人体细胞下达蛋白质形成指令的单位。
我们的信息技术基础设施基于以比特(包括两个数字:0和1)来存储信息,而DNA信息存储在四个潜在碱基单位的串中。为了将非遗传信息存储在DNA中,我们必须先将二进制数据从比特转换成DNA数据的四单位(AGCT)结构。
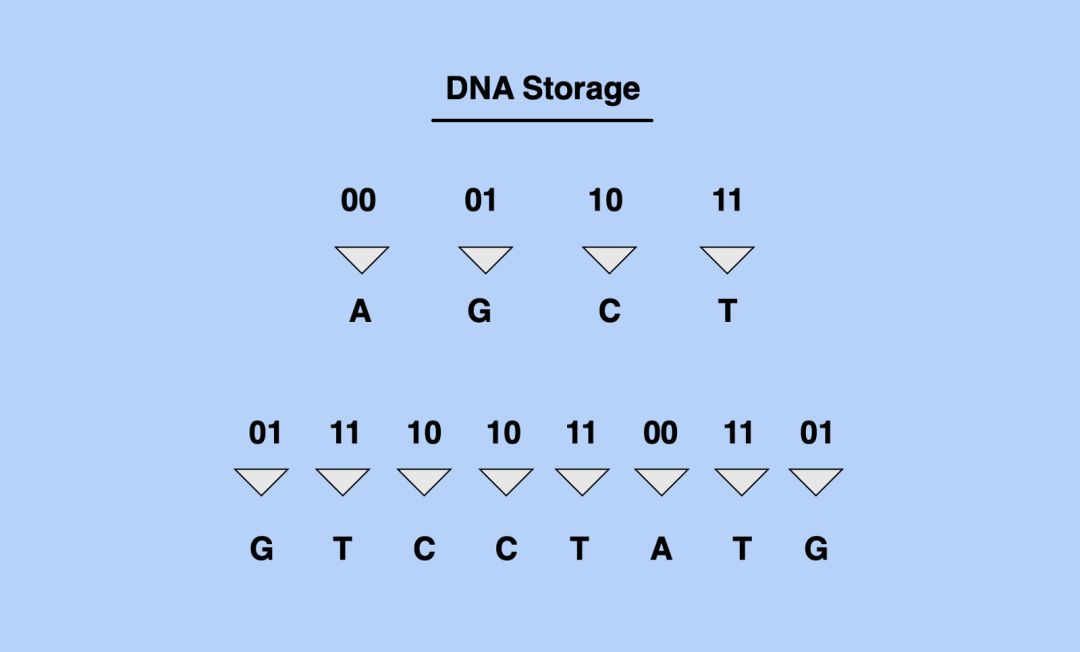
将比特转换成DNA序列(图片来源:Shaan Ray)
理论部分实际上相当简单。与使用硅或磁性介质(其工作原理基于将状态存储为1和0序列的能力)一样,我们可以使用DNA,存储A、G、C和T组成的序列。但是这实际上如何运作?——该如何将数据写入到DNA和从DNA中读取数据?
这可能听起来太过遥远,但分子技术的进步使其变得切实可行,尽管并不称心如意。这一切意味着,确实能够以一种可以在DNA上存储和检索信息的方式来编码信息,分别利用DNA合成和DNA测序。
比如说,微软已展示了世界上第一个自动化的DNA数据存储和检索系统。你可能想知道这个DNA来自哪里,告诉你:这是合成DNA,生成合成DNA的阵列是系统的一部分。
天然存在的DNA呈现有两条核苷酸链的双螺旋这种结构。相比之下,用于数据存储的DNA是单链核苷酸序列,又叫寡核苷酸(oligo),它是使用每次一个核苷酸来组装DNA的化学过程合成的。
法国通信系统工程师学校与研究中心(Eurecom)数据科学系助理教授Appuswamy和伦敦帝国理工学院SCALE实验室负责人Heinis最近发表了DNA存储方面的开创性成果。
使用DNA在现实世界存储数据
Heinis和Appuswamy在创新数据系统研究大会上发表了题为“OligoArchive:在DBMS存储层次结构中使用DNA”的研究论文(http://cidrdb.org/cidr2019/papers/p98-appuswamy-cidr19.pdf)。

虽然他们并非最先使用DNA来存储和检索数据,却最先针对结构化数据这么做,与现成数据库集成起来,而且不仅限于存储,还实现了计算。
DNA作为数据存储层方面要认识到的第一点是,每次执行写入操作时,都必须合成寡核苷酸。这实际上将如何做到?实验室技术人员是否要待命执行此操作,并为用于化学过程的原材料“重新灌满油箱”?
据Appuswamy和Heinis声称,并非如此,微软用自动化的DNA存储和检索系统演示了其在这方面的价值。结果表明,可以在无需人参与的情况下操作这种阵列。就像没人监管数据中心的日常运营一样(维护除外),基于DNA的数据中心将同样如此。
不过,我们离合成DNA阵列替换传统硬盘还远得很。首先,以这种方式存储数据的现代技术速度非常慢。最初,存储1兆字节的数据需要科学家花一周时间。
Appuswamy和Heinis都认为这方面需要做更多的工作。虽然这超出了他们自身研究的范围,所以只好等生化组合过程赶上来,但他们确实让人看到了希望。
首先,他们特别指出存储速度在变得越来越快,目前每秒可以存储数KB。比如说,尽管与SSD相比速度仍然慢得要命,但已是相当大的进步。这个速度对于Appuswamy和Heinis的研究设想的使用场景:归档存储而言实际上可以接受。
数据库引擎使用三层存储层次结构,这种层次结构包括价格/性能特点大不一样的众多设备。性能层存储高性能OLTP和实时分析这类应用访问的数据。
容量层存储对延迟不敏感的批处理分析这类应用访问的数据。归档层用于存储极少访问的数据,比如在安全合规检查或法务审计期间。如今,磁带通常用于这一层。
OligoArchive改变了数据库存储层次结构:它将基于磁带的归档层换成了基于DNA的归档层。合成DNA使用额外的预防措施来加以存储;至于将基于DNA的存储用于普通设备效果有多好还成问题。但数据和数据库进入云端是大势所趋,只要你的数据安全地存储在数据中心,它在最终用户眼里就是黑盒子。
在DNA上运行SQL
Appuswamy和Heinis还特别指出,尽管速度仍很慢,但DNA存储在并行处理方面大有潜力。这是由于DNA存储数量充足、成本低廉——或者更准确地说,希望最终会如此。按目前情况来看,存储1分钟的高质量立体声将花费10万美元。
虽然使用合成DNA用于大规模存储仍然成本过于高昂,但Appuswamy和Heinis表示,他们预计每一次科技突破(包括存储技术)通常会使成本大幅下降。
如果合成寡核苷酸在经济上变得可行,让许多寡核苷酸满足存储需求自在情理之中。这意味着让许多DNA存储单位并行操作这方面巨大潜力。虽然并非每种算法的每个方面都可并行化,但对于果真可并行化的算法而言,可以大幅提升速度。这引出了一个关键点。
就在不久前,DNA还被用于存储非结构化文件,无论是文本、视频或诸如此类的数据。 Appuswamy和Heinis所做的是将DNA存储集成到关系数据库中。他们拿来标准数据库基准测试TPC-H中包含的数据和查询,在PostgreSQL实例上运行TPC-H。不是串行访问,而是随意选择数据。
将结构化数据存储在数据库系统中,后端使用DNA,并通过SQL来查询,这在今天已成为现实。
研究人员为PostgreSQL构建了归档和恢复工具(pg_oligo_dump和pg_oligo_restore),这些工具在DNA上对关系数据执行感知模式的编码和解码,然后他们用这些工具将12KB TPC-H数据库归档到DNA,执行体外计算,然后再恢复该数据库。
这意义重大。这意味着现在DNA存储还可以支持SQL操作,选择性地访问和处理部分数据。请注意:数据并不被提取到数据库以便在那里执行操作。Appuswamy和Heinis找到了一种方法在寡核苷酸中处理SQL连接之类的操作。这超出了生化存储的范畴,还涉及生化计算。
用于编码和解码进出DNA的信息的技术存在着缺陷;然而要做到这一点,研究人员就得处理与这些缺陷有关的一堆问题。在DNA上执行操作需要专门的编码技术,这些技术可以生成适合生化操作的寡核苷酸。读取DNA数据目前很容易出错,而以前的研究依赖数据过度表示:数据以多个副本写入,因此即使原始数据被破坏,还有备份。
相比之下,Appuswamy和Heinis依赖元数据。他们在编写的代码段中添加了一些额外的数据,利用数据库模式感知功能。他们表明,这可以在编码(写入)过程中提高密度,并有助于在解码(读取)过程中识别错误。他们特别指出实际效果比预期的好——一点元数据就大有帮助。
DNA是数据的未来吗?
尽管技术堆栈的某些部分还不成熟,但这是一项重大突破。让已有的数据中心拥有充足的存储资源可以改变游戏规则。但将DNA这种数量充足的材料充当存储和计算的可行介质具有重大影响,远非我们所能想象。
这可能只是朝这个方向迈出的第一步,但每段旅程都从第一步开始。Appuswamy和Heinis并非单枪匹马开展这项工作,他们也不会凭一己之力开展进一步的研究。他们的项目OLIGOARCHIVE一直在取得进展,这归功于与法国蔚蓝海岸大学(UCA)和CNRS的其他研究人员进行合作,因而得以壮大研究团队,并扩大研究范围。
Eurecom、CNRS、ICL、UCA以及DNA合成初创公司Helixworks已获得欧盟资助,以进一步开展DNA存储方面的研究。该系统将旨在支持编码数据,将数据合成为DNA,并通过测序读回数据这整个过程完全实现自动化。它将存储众多不同类型的数据,并实现近数据处理和数据的精确检索。
将数据存储在DNA中方面的进一步研究将得到欧盟的资助。
该项目通过未来和新兴技术(FET)欧盟计划获得资金,该计划投资致力于研究全新未来技术方面新想法的早期阶段项目,在早期阶段很少有研究人员开展项目课题。虽然这似乎是天作之合,但我们很想知道商业机构有没有找过这些研究人员。
Appuswamy和Heinis提到,到目前为止,感兴趣的主要是其他研究人员,不过微软是个例外。倒不是这方面有任何实际成果,而是眼下微软似乎比其他任何公司抱有更大的兴趣。
在这项技术方面获得优势可能意味着主导未来,因为这个领域的突破将带来巨大影响。 Appuswamy和Heinis特别指出,人们的态度表明了这一点:“几年前,人们会觉得这遥不可及。而今天,我们告诉他们我们在做的工作后,他们的态度是‘告诉我们更多’”。
论文全文:












