CQRS 没那么难!

#扫描上方二维码报名成都源创会#
有人说:“CQRS很难!”
是吗? 好吧,我也曾这样认为! 但,当我开始使用 CQRS 编写我的第一个软件时,它很快就不攻自破。更为重要的是,我认为从长远来看,以这种方式维护软件更加容易。
我开始思考:为何人们在一开始时认为它是多么困难难和复杂? 我有一个理论:它包含规则! 进入拥有规则的世界总是不舒服的,我们需要适应这些规则。在这篇文章中,我想证明在这种情况下,这些规则是非常易于理解的。
在通往 CQRS 的路上…
从根本上来说,我们可以将 CQRS 视为对软件架构命令查询分离规则的实现。在使用此方法的工作中,我注意到在最简单的 CQS 实现与真正成熟的 CQRS 之间有几个步骤。我想那些步骤可以顺利地引入我之前已经提到的规则。
虽然第一步没有实现我对 CQRS 的定义(但是有时候这么称呼的),但是他们还可以为你的软件引入一些真正的价值。每个步骤都引入一些有趣的想法,可以有助于构建或清理你的代码库/架构。
通常,我们的旅程从这里开始:
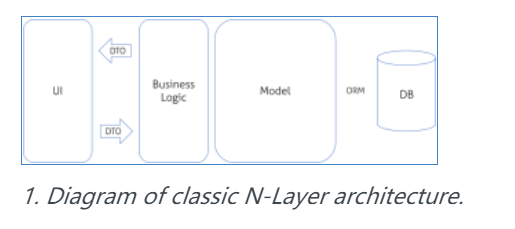
我们可能都知道,这是一个典型的 N-层架构。如果我们想在这添加一些 CQS,我们可以“简单地”将业务逻辑层分离为命令和查询:
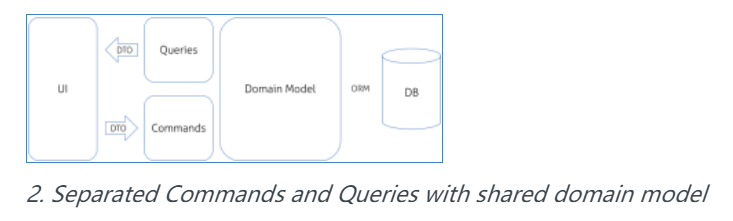
如果你还在使用老式代码库,这可能是最难的一步,就像从意大利面式代码中阅读分离出副作用一样不简单。同时这个步骤可能也是最有好处的一个;它会给你一个副作用执行的位置的概述。
等一下!你正在讨论 CQS,CQRS ,但是你还没有定义到底什么是命令或查询!
没错。我们开始定义它们吧!在这里,我会给你我个人、直观的对命令和查询的定义。它并不全面,而且在实现之前必须加以深化。
命令——首先,触发命令是唯一改变系统状态的方法。命令负责引起所有的对系统的改变。如果没有命令,系统状态保持不变!命令不应该返回任何值。我使用两个类来实现它:Command 和 CommandHandler 。Command 只是一个普通的对象,CommandHandler 将它用于表示某些操作的输入值(参数)。我认为命令是简单地调用领域模型中的特定操作(不一定是每个命令都有的操作)。
查询——同样的,查询是一个读操作。它读取系统的状态,过滤,聚总,以及转换数据,并将其转化为最有用的格式。它可以执行多次,而且不会影响系统的状态。我之前是使用一个有一些 Execute(…) 函数的类来实现它,但是现在我认为分离成 Query 和 QueryHandler/QueryExecutor 可能会更有用。
回到示意图,我需要澄清一些事情;我已经隐秘地做了一个补充修改,模型改为领域模型。由于我认为模型是一组数据容器,而领域模型包括了业务规则中本质复杂性。因为我们对这里的体系架构感兴趣,这个修改不会直接影响我们的进一步考虑。但是值得一提的是,尽管命令负责改变系统的状态,本质复杂性应该放到领域模型。
好的,现在我们可以添加新的命令或者编写新的查询。短时间内,很明显,适用于写的领域模型并不一定适合读。从某种特殊模型中更容易读取数据,这并不是一个重大的发现:
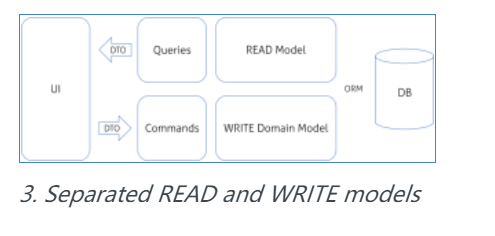
我们可以引入分离模型,由 ORM 映射并构建查询,但是在某些情况下,特别是当 ORM 引入开销时,它将对简化结构有所帮助。
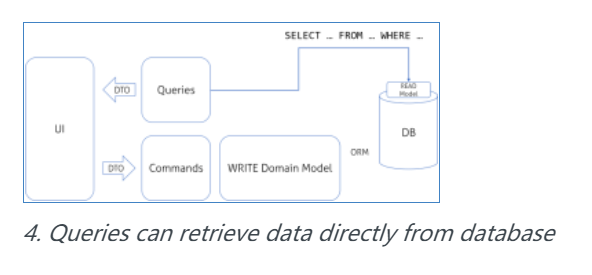
我认为这个特殊的改变应当被好好地考虑!
现在的问题是我们仍然有仅在逻辑层级上分离的读和写模型,因为他们共享公共数据库。这就意味着我们已经分离了读模型,但最有可能是被一些 DB 视图给虚拟化了,物化视图的情况下更好。如果我们的系统没有性能问题,并且我们记住在写模型改变的时候更新查询,那这个方案是可行的。
下一步是引入完全分离的数据模型:
在我看来,这是第一个符合 Greg Young 提出的原始想法的模型,现在我们称它为 CQRS 。但是它仍然有问题!我之后再写。
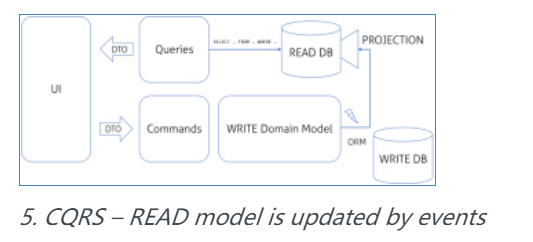
CQRS != 事件溯源
事件溯源是与 CQRS 一起提出的一个概念,通常被标识为 CQRS 的一部分。ES(Event Sourcing)的概念很简单:我们的领域生成的事件表示系统中的每一个更改。如果我们从系统开始记录每一个事件,而且从最初状态开始重现,我们会得到系统的当前状态。它与银行账户的事务相似;我们可以从空账户开始,重现每一个单独的事务,然后(有希望地)得到当前的余款。因此,如果我们已经存储了所有的事件,我们能得到系统的当前状态。
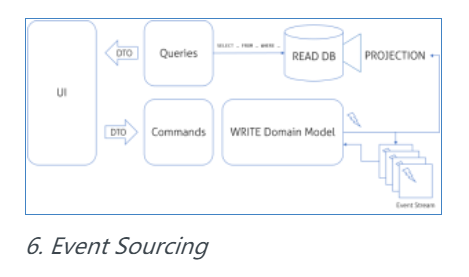
虽然 ES 是存储系统的状态的一种很好的方法,但是 CQRS 并不一定需要它。对于 CQRS ,领域模型实际上如何存储并不重要,而且这只是一个选项。
读模型和写模型
当我们阅读 CQRS 时,分离模型的概念似乎非常清晰和直接,但在实现过程中似乎并不清楚。写模型的责任是什么?我是否应该将所有数据放入我的读取模型中?嗯,这得看情况!
写模型
我喜欢把我的写作模型看作是系统的核心。这是我的领域模型,它做业务决策,它很重要。它做出业务决策的事实在这里是至关重要的,因为它定义了这个模型的主要职责:它代表系统的真实状态,可以用来做出有价值的决策的状态。这种模式是唯一的真理来源。
如果你想了解更多关于设计领域模型的知识,我推荐你阅读领域驱动设计技术哲学。
读模型
在我第一次尝试 CQRS 时,我使用了 WRITE 模型来构建查询……它是 OK 的(或者至少是有效的)。过了一段时间,我们到达了项目中需要花费大量时间进行查询的地方。为什么?因为我们是程序员,优化是我们的第二天性。我们将模型设计为规范化,因此我们的读取端受到连接的影响。我们被迫预先计算一些报告的数据以保持快速。这很有趣,因为实际上我们引入了缓存。在我看来,这是读取模型的最佳定义:它是一个合法的缓存。由于我们必须发布项目,而非功能性的需求没有得到满足,因此,缓存是通过设计来实现的。
标签读取模型可以建议它存储在一个数据库中,仅此而已。实际上读取模型可能非常复杂,你可以使用图形数据库来存储社会连接,使用 RDBMS 来存储财务数据。这是一个多语言持久性很自然的地方。
设计好的读模型是一系列的权衡,例如纯规范化与纯非规范化。如果你的项目很小,并且大多数读取都可以根据写模型有效地进行,那么创建副本将浪费时间和计算能力。但是,如果你的写模型是作为一系列事件存储的,那么使用所有必需的数据而不从头重新播放所有事件将是非常有用的。这个过程叫做快速读取派生,在我看来,它是 CQRS 中最复杂的东西之一,这是我前面提到的一个难点。正如我之前所说,读模型是缓存的一种形式,正如我们所知:
在计算机科学中只有两件困难的事情:缓存失效和命名。 ——Phil Karlton
我说它是一个“合法”的缓存,这个词对我来说也有额外的意义,在我们的系统中,我们有明显的理由更新缓存。我们的域模型产生的事件是更新读模型的自然原因。
最终一致性
如果我们的模型在物理上是分开的,那么同步将需要一些时间,这是很自然的,但是这一次对业务人员来说是非常可怕的。在我的项目中,如果每个部分都正常工作,那么 READ model 不同步的时间通常可以忽略不计。然而,在开发更复杂的系统时,我们肯定需要考虑时间风险。设计良好的 UI 对于处理最终的一致性也很有帮助。
我们必须假设,即使读取模型与写入模型同步更新,用户仍然会根据陈旧的数据做出决策。不幸的是,我们不能确定当数据呈现给用户时它是否仍然新鲜(比如在 web 浏览器中呈现)。
如何将 CQRS 引入到项目中?
我相信 CQRS 如此简单,不需要引入任何框架。你可以从少于100行代码的最简单的实现开始,然后当需要的时候再引入新特性来扩展它。你不需要任何魔法,因为 CQRS 很简单,而且它简化了软件。这是我的实现:

我定义几个接口描述命令和他们的执行环境。为什么我用两个接口来定义一条命令?我这么做是因为我想要保持参数为普通对象,这样就可以不用任何依赖来创建。我的命令 handler 可以从 DI 容器中请求依赖,而且除了在测试中,不需要在任何地方实例化。事实上,ICommand 接口在这的作用相当于标记,来告诉开发者他是否可以将这个类作为命令来使用。

此定义非常类似 IQuery 接口,但它还定义了查询结果的类型。 这不是最优雅的解决方案,但结果是在编译时校验返回的类型。

我的 CommandDispatcher 相当短,它只负责为给定的命令实例化适当的命令助手并执行它。为了避免手动输入命令去注册和实例化,我已经使用了 DI 容器来做这件事,但如果你不想使用任何 DI 容器,你仍然可以自己做。我说过,这个实现将是简单的,我相信是这样。唯一的问题可能是泛型引入的噪音,它可能刚开始的时候会令人沮丧。这个实现在使用上确实是简单的。下面是一个命令和助手的示例:
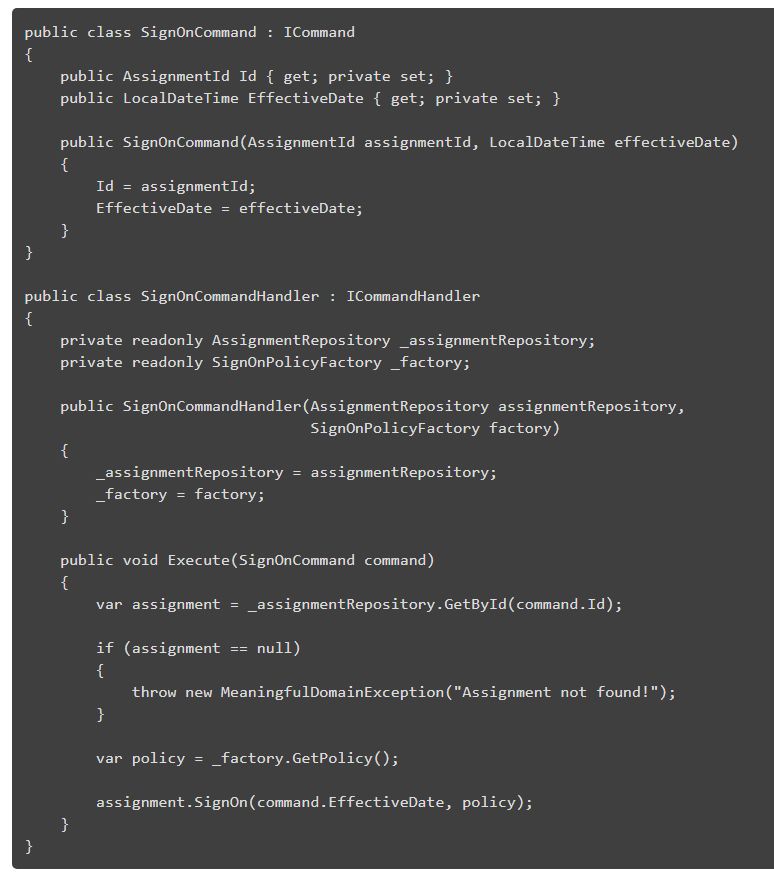
只需要将 SignOnCommand 传给分派器来执行这个命令:

就是这样。QueryDispatcher 看起来很相似,唯一不同是它返回了一些数据,多亏了我之前写的通用代码,Execute 方法返回强类型结果:

就像我说的,这个实现是可以扩展的。例如,我们可以为命令 dispatcher 引入事务,而无需通过创建 decorator 来改变原始实现。
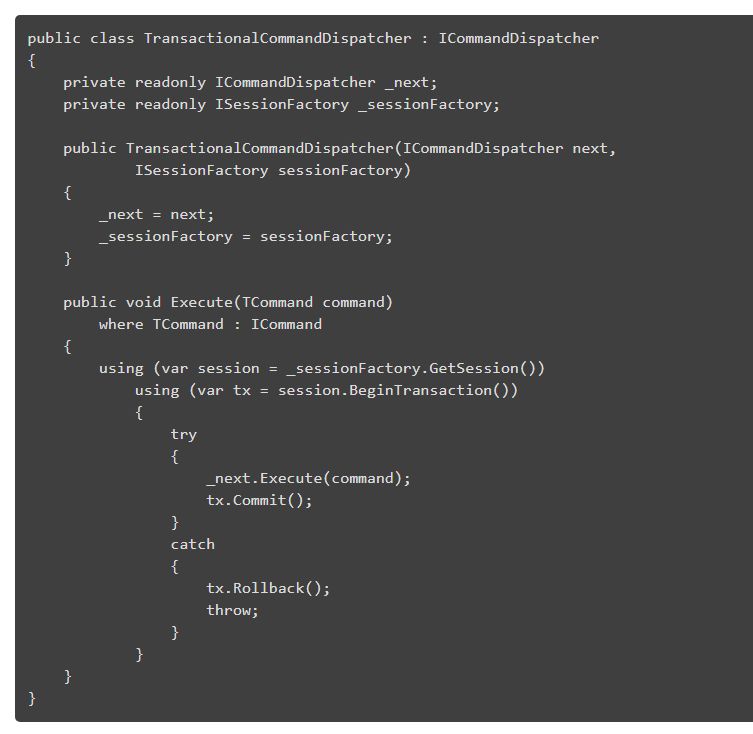
通过使用这个伪方法,我们可以轻松地扩展命令和查询分派器。你可以添加“即发即弃”的命令执行方法和大量日志。
正如你看到的,CQRS 没那么难,基本的思想很清晰,但是你需要遵守一些规则。我确信这篇文章没有涵盖全部的内容,这就是我建议你多读一些的原因。
参考书目
CQRS Documents by Greg Young
Clarified CQRS by Udi Dahan
CQRS by Martin Fowler
CQS by Martin Fowler
“Implementing DDD” by Vaughn Vernon
原文地址:
https://www.future-processing.pl/blog/cqrs-simple-architecture/
参与翻译 : 琪花亿草, kevinlinkai, ZICK_ZEON, Tocy
好书大放送!
最新 Spring Cloud+ Spring Boot 2.0 技术书免费送!
文末留言写书评
留言获赞最多的前6名就能把书抱回家!
活动时间:8月11日-18日
点击参与:




