如何让人工智能学会用数据说话


上周,微软亚洲研究院知识计算组与我们分享了人工智能是怎么解数学题的,不知道大家是否有所启发呢?接下来让我们一起来看看人工智能是怎么用数据说话的吧。此前,我们在微信上分享了观点|宋睿华:好玩的文本生成,今天我们主要聊的是基于结构化数据的文本生成。
什么是基于结构化数据的文本生成
美联社机器人撰写财经报道,微软机器人自动生成对联,谷歌机器人自动写诗,一时间,机器人自动写作成为学术界和产业界关注和讨论的热门话题【1,2】。
机器人写作又称文本生成。从广义上讲,一些传统的自然语言处理任务,例如机器翻译、文本摘要、对联生成、诗词生成等都属于文本生成的范畴。这些任务的共同点是用户输入非结构化的文本,机器根据任务目标输出相应的文本。
不同于这些任务,本文主要与大家分享的是基于结构化数据的文本生成,即用户输入结构化的数据,机器输出描述和解释结构化数据的文本。(注:为了简便,下文中的文本生成均指基于结构化数据的文本生成。)该任务的特点是基于数据和事实说话。文本生成的典型商业应用包括财经和体育类新闻报道的生成、产品描述的生成、商业数据的分析和解释、物联网(Internet of Things)数据的分析和解释。图1给出了天气预报自动生成的例子。其中,图1a是各种感知器采集到的结构化的天气数据,机器将图1a中的数据作为输入,输出图1b中的天气预报。
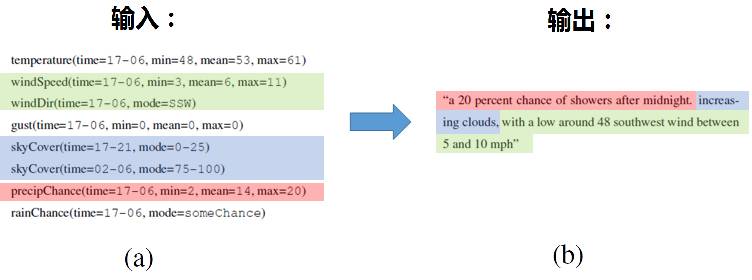
图 1天气预报的自动生成(此例来源于论文【3】)
接下来,本文尝试从商业应用和技术发展两个方面来总结文本生成的领域现状。
文本生成的商业前景
近些年,随着文本生成技术的发展,工业界也诞生了一些专注于文本生成的明星创业公司,例如Narrative Science(前5轮共融资2950万美元),Automated Insights(前3轮共融资1080万美金,并于2015年被美国私募股权基金 Vista Equity Partners以8000万美金的价格收购),Arria NLG(第一轮获得了4027万美金融资)等。这几家明星初创企业的产品也涵盖了文本生成在不同商业领域的应用。
Narrative Science的主要产品是Quill,该产品可以帮助第三方公司分析和解释商业数据。其客户多为金融服务和咨询公司。此外,Narrative Science还特别开发了Quill for Google Analytics,该工具可以实时的将Google Analytics所统计的各种复杂的用户访问数据转化成简单的文字说明,帮助Google Analytics的用户免去阅读各种复杂图表的痛苦,让用户能够快速理解其站点的流量数据,为优化站点提供建议。
Automated Insights的主要产品是WordSmith,该产品已经在美国联合通讯社(The Associated Press)和雅虎得到成功应用,用于撰写财新和体育类报道。让人惊叹的是,美联社在采用Automated Insights的文本生成技术后,每季度可以撰写的财报新闻数量从300篇增加到了4300篇,生产力得到了极大的提高【2】。
Arria NLG则主要与英国国家气象服务局Met Office合作,自动生成天气预报。这是文本生成技术在物联网领域的一个典型应用。如图1所示,各种感知器每天可以采集到大量的结构化数据。但解读这些数据的困难在于:一方面感知器采集的数据量非常大,另一方面数据的解读需要专业知识。基于结构化数据的文本生成技术首先需要从大量的数据中筛选出重要信息,然后生成易于阅读和理解的天气预报文本内容。
文本生成的技术发展
挑战
基于结构化数据的文本生成任务主要包括两个挑战【4】:
第一,说什么(What to say)
第二,怎么说(How to say)
如图1所示,机器首先需要决定说什么,这就意味着机器需要从输入的若干数据记录中选择要描述的记录(图1a中被高亮的数据记录);然后决定怎么说。简单的来说就是机器需对选定的数据记录,用自然语言描述出来(图1b)。
评测
Dimitra Gkatzia等人【5】对文本生成任务的评测方法进行了总结。不一样的是Dimitra Gkatzia等人【5】分析了近10年发表在自然语言处理领域相关会议和期刊(ACL、EMNLP、NAACL等)上关于文本生成的论文,并将相关工作所采用的评测方法归为两大类:内在(Intrinsic)评测和外在(Extrinsic)评测。
内在评测关注系统生成文本的正确性、流畅性和可理解性等。内在评测方法又可分为两类:(1)通过采用自动化的评测方法(如BLEU, NIST和ROUGE等)对比系统生成的文本和人工写作的文本之间的相似度,以此来衡量系统生成文本的质量;(2)通过调查问卷等方式,由人们从正确性、流畅性等角度出发直接对系统生成的文本进行打分,来评价系统生成文本的质量。
外在评测关注于评价系统生成文本的可用性,即评价系统生成的文本对于用户完成特定任务是否有帮助。

Dimitra Gkatzia等人【5】的分析表明,现阶段文本生成的相关工作多采用自动化的内在评测方法——即利用计算机对比系统生成文本和人工写作文本之间的相似度,原因是此类评价方法更加便捷、成本较低。而外在的评测方法成本较高,采用此类评测方法的论文较少,但是此类评测方法能更好的标示出系统的可用性。
方法
早期的文本生成系统多是基于规则的,Reiter等对规则系统进行了归纳总结【4】,认为文本生成系统可以分为三个较为独立的模块:(1)内容规划(Content planning),即选择描述哪些数据记录或数据域;(2)句子规划(Sentence planning),即决定所选择的数据记录或数据域在句子中的顺序;(3)句子实现(Surface realization),即基于句子规划的结果生成实际的文本。可以认为,内容规划主要是解决“说什么”,而句子规划和句子实现主要是解决“怎么说”。
在该框架下,针对不同模块,若干基于统计的模型被提出。Barzilay等提出先将数据记录和句子进行对齐,然后学习模型解决内容选择【6】。Percy Liang等提出了一个概率图模型同时解决内容规划和句子实现【7】。具体来说就是该生成模型首先选择生成哪些数据记录,然后选择生成数据记录中的哪些数据域,最后生成描述数据域的文本。
近几年,随着深度学习方法在自然语言处理领域取得突破,研究人员也尝试将神经网络的方法应用于文本生成。基于神经网络的方法又分为基于神经语言模型(Neural Language Model)的方法和基于神经机器翻译(Neural Machine Translation)的方法。
其中,Wen等提出了Semantic Controlled LSTM(Long Short-term Memory)模型用于对话系统中的文本生成【8】。该模型在标准LSTM的基础上引入了一个控制门读取结构化数据信息,并控制结构化数据信息在语言模型中的输出。该论文获得了2015年EMNLP会议的最佳论文。Kiddon等提出了神经清单模型(Neural Checklist Model),用于解决RNN(Recurrent neural networks)模型对结构化数据中的信息重复生成的问题【9】。Kiddon等将该模型应用于菜谱的生成,即输入菜名以及食材清单,机器输出相应的菜谱。基于结构化数据的文本生成存在数据稀疏的问题,即结构化数据中的许多数据值(实体名、数值等)出现次数非常少,使得模型的学习变的困难。Lebret等将拷贝动作(copy-action)引入神经语言模型,用于解决数据稀疏的问题【10】。Lebret等将该模型应用于维基百科的人物传记生成,即输入人物的信息框(Infobox),机器根据信息框中的人物信息,输出人物的文本描述。

受神经机器翻译模型【11】的启发,Mei等将基于结构化数据的文本生成任务视为一个翻译任务,即输入的源语言是结构化数据,输出的目标语言是文本【3】。很自然的,神经机器翻译模型可以解决怎么说的问题。为了进一步解决说什么的问题,Mei等在神经机器翻译模型的基础上引入了对数据记录的重要性进行建模的机制,即越重要的数据,其先验概率越大,越有可能在文本中被表达出来。
基于神经语言模型的方法和基于神经机器翻译的方法在特定数据集上都取得了较大的进步,其本质仍然是Sequence-to-sequence方法的胜利。
数据
为了推动文本生成技术的发展,研究人员们将相关数据集共享给学术界研究使用。本文对部分数据集进行了收集和整理:
(1)斯坦福大学的Percy Liang教授共享了一份天气预报数据集【7】。这份数据集包括了美国3753个城市(人口大于10000)连续三天的天气预报。
(2)德克萨斯大学奥斯汀分校的Raymond J. Mooney教授共享了机器人足球赛的数据集【12】。这份数据集包括了2036场机器人足球赛的数据统计和评论。
(3)Facebook共享了维基百科人物传记的数据集【10】。这份数据集包括了728,321篇从维基百科获取的人物传记。
(4)剑桥大学的Tsung-Hsien Wen共享了基于服务的人机对话数据集【8】。这份数据集包括了248轮餐馆领域的对话和164轮酒店领域的对话。
总结和展望
综上,基于结构化数据的文本生成技术已经在商业领域获得了初步的成功,深度学习技术的发展和大数据的积累也推动着相关技术的进步。相信该领域会在技术、数据和商业的三重驱动下取得更大的突破。

参考文献
【1】刘挺,机器人来了,记者去哪儿,http://wenting.baijia.baidu.com/article/165162
【2】徐曼,国外机器人新闻写手的发展与思考,http://media.people.com.cn/n1/2016/0105/c401845-28014693.html
【3】Mei, Hongyuan, T. T. I. UChicago, Mohit Bansal, and Matthew R. Walter. 2016. What to talk about and how? Selective Generation using LSTMs with Coarse-to-Fine Alignment. In Proceedings of NAACL-HLT.
【4】Reiter, Ehud. 2007. An architecture for data-to-text systems. In Proceedings of ENLG.
【5】Gkatzia, Dimitra, and Saad Mahamood. 2015. A Snapshot of NLG Evaluation Practices 2005-2014. In Proceedings of ENLG.
【6】Barzilay, Regina, and Mirella Lapata. 2005. Collective content selection for concept-to-text generation. In Proceedings of EMNLP.
【7】Liang, Percy, Michael I. Jordan, and Dan Klein. 2009. Learning semantic correspondences with less supervision. In Proceedings of ACL.
【8】Wen, Tsung-Hsien, Milica Gasic, Nikola Mrksic, Pei-Hao Su, David Vandyke, and Steve Young. 2015. Semantically conditioned LSTM-based natural language generation for spoken dialogue systems. In Proceedings of EMNLP.
【9】Kiddon, Chloé, Luke Zettlemoyer, and Yejin Choi. 2016. Globally coherent text generation with neural checklist models. In Proceedings of EMNLP.
【10】Lebret, Rémi, David Grangier, and Michael Auli. 2016. Neural text generation from structured data with application to the biography domain. In Proceedings of EMNLP.
【11】Bahdanau, Dzmitry, KyungHyun Cho, Yoshua Bengio, and Roee Aharoni. 2014. Neural Machine Translation by Jointly Learning to Align and Translate. In Proceedings of NIPS.
【12】Chen, David L., and Raymond J. Mooney. 2008. Learning to sportscast: a test of grounded language acquisition. In Proceedings of ICML.

刘璟博士,微软亚洲研究院副研究员。他的研究兴趣包括信息抽取、文本生成和社会计算。至今为止,他在这些领域的顶级会议上发表了10余篇论文,如ACL、SIGIR、WSDM、EMNLP、CIKM等,并已获得两项国际专利。刘璟博士还曾任ACL、EMNLP、NAACL、EACL等国际会议和TOIS、TWEB等国际期刊的评审委员。
知识计算组致力于通过知识发现、数据挖掘与计算来理解和服务这个世界。研究组聚集了包括数据挖掘与计算、机器学习、自然语言处理、信息检索和社会计算等领域的多学科研究员,主要从事如下研究方向:实体链接、搜索和知识挖掘与计算,基于结构化数据的文本生成,服务于真实世界的语义计算框架应用,基于大规模行为数据的用户理解。十年来,该组成员的研究成果对微软的重要产品产生了影响,包括必应搜索、微软学术搜索、微软认知服务等。
知识计算组现招聘实习生,工作内容涉及机器学习和自然语言处理等领域,工程和研究均可,根据个人兴趣和能力确定工作内容。要求编程能力较强;有一定的沟通能力,有责任心;对机器学习、自然语言处理、人工智能有热情和兴趣;高质量的完成工作;半年以上实习期。
感兴趣的同学可以下载并填写申请表(申请表链接: http://www.msra.cn/zh-cn/jobs/interns/intern_application_form_2014.xls 点击阅读原文即可查看)并将其与完整的中英文简历(PDF/Word/Txt/Html形式)一同发送至:cyl@microsoft.com
你也许还想看:
感谢你关注“微软研究院AI头条”,我们期待你的留言和投稿,共建交流平台。来稿请寄:msraai@microsoft.com。




