技术动态 | 针对复杂问题的知识图谱问答最新进展
本文转载自公众号:PaperWeekly。
作者:付彬、唐呈光、李杨、余海洋、孙健
单位:阿里巴巴达摩院小蜜Conversational AI团队
背景介绍
知识图谱问答(KBQA)利用图谱丰富的语义关联信息,能够深入理解用户问题并给出答案,近年来吸引了学术界和工业界的广泛关注。KBQA 主要任务是将自然语言问题(NLQ)通过不同方法映射到结构化的查询,并在知识图谱中获取答案。
小蜜团队研发的知识图谱问答系统(KBQA)目前已广泛应用于电信运营商、保险、税务等领域,但是在真实的客服场景中,KBQA 在处理复杂问句上仍然面临着挑战。
用户在咨询问题时,倾向于表达非常具体的信息,以便快速的获得答案,比较常见问句类型的有:
1)复杂条件句:“小规模纳税人季度销售额未超过 30 万,但是要开具 5 万元的的专票,需要缴纳附加税费吗?”;
2)并列句:“介绍下移动大流量和畅享套餐”;
3)推理型问句:“你们这最便宜的 5G 套餐是哪个?”等,这给 KBQA 提出了新的挑战:如何有效地利用深度学习模型规模化地处理复杂句问答?
为了应对该问题,我们调研了 KBQA 方向最近几年的关键进展,并着重关注了含有复杂句的数据集及相关的方法。
本文会先介绍 KBQA 主流相关数据集,然后详细介绍两类在相关数据集上的典型方法以及每种方法的代表性模型,最后我们对 Semantic Parsing + NN 的方法进行一个系统性总结,并介绍小蜜团队的 Hierarchical KB-Attention Model。
数据集简介
随着 KBQA 技术的发展,对应的数据集从简单的单跳问答向包含复杂问题转变;问答形式从单轮问答数据集,向面向对话的多轮问答数据集转变(HotpotQA [1] 和 CSQA [2])。表1 列举问答数据集部分属性,同时介绍了相关的三个典型通用知识图谱。
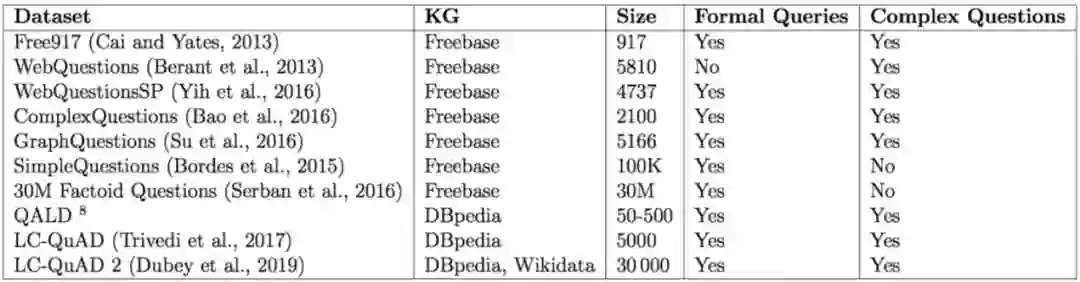
▲ 表一. KBQA评测数据集列表
2.1 WebQuestions及其衍生数据集
WebQuestions [3] 是为了解决真实问题构造的数据集,问题来源于 Google Suggest API,答案使用 Amazon Mechanic Turk 标注生成,是目前使用最广泛的评测数据集,但该数据集有 2 点不足:
① 数据集中只有问答对,没有包含逻辑形式;
② 简单问题占比在 84%,缺乏复杂的多跳和推理型问题;
针对第一类问题,微软基于该数据集构建了 WebquestionsSP [4],为每一个答案标注了 SPARQL 查询语句,并去除了部分有歧义、意图不明或者没有明确答案的问题。
针对第二类问题,为了增加问题的复杂性,ComplexQuestions [5] 在 WebQuestions 基础上,引入包含类型约束、显式或者隐式的时间约束、多实体约束、聚合类约束(最值和求和)等问题,并提供逻辑形式的查询。
2.2 QALD系列(Question Answering over Linked Data)
QALD 是 CLEF 上的一个评测子任务,自 2011 年开始,每年举办一届,每次提供若干训练集和测试集,其中复杂问题占比约 38% [6]。
该数据集不仅包括多个关系和多个实体,如:“Which buildings in art deco style did Shreve, Lamb and Harmon design?”;还包括含有时间、比较级、最高级和推理类的问题,如:“How old was Steve Jobs’s sister when she first met him?”[7]。
2.3 Large-Scale Complex Question Answering Dataset (LcQuAD)
Trivedi [8] 等人在 2017 年公布了一个针对 DBpedia 的复杂问题数据集,该数据集中简单的单跳问题占比 18%,典型的问句形式如:“What are the mascots of the teams participating in the turkish handball super league?”。
该数据集的构建,先利用一部分 SPARQL 模板,一些种子实体和部分关联属性通过 DBpedia 生成具体的 SPARQL,然后再利用定义好的问句模板半自动利用 SPARQL 生成问句,最后通过众包形成最后的标注问题。
Dubey 等人也使用同样的方法,构建了一个数据量更大更多样的数据集 LcQuAD 2.0 [9]。
KBQA核心方法介绍
随着数据集的演变和 KBQA 技术的发展,我们认为 KBQA 当前主要面临两个核心挑战:
1. 复杂问题理解难:如何更恰当地通过知识图谱建模并理解用户复杂问题,并增强方法的可解释性;
2. 模型推理能力弱:如何减少对于人工定义模板的依赖,训练具备推理能力、泛化性强的 KBQA 深度模型;
现在 KBQA 的主流方法主要分为两类:1) Semantic Parser + NN (SP);2) Information Retrieval (IR),因此我们总结了这两类方法中的一些经典论文在 WebQuestions 上的结果,图 1 所示, 从整体趋势来看,结合深度学习的 Semantic Parser 方法效果要略优于 IR 的方法。
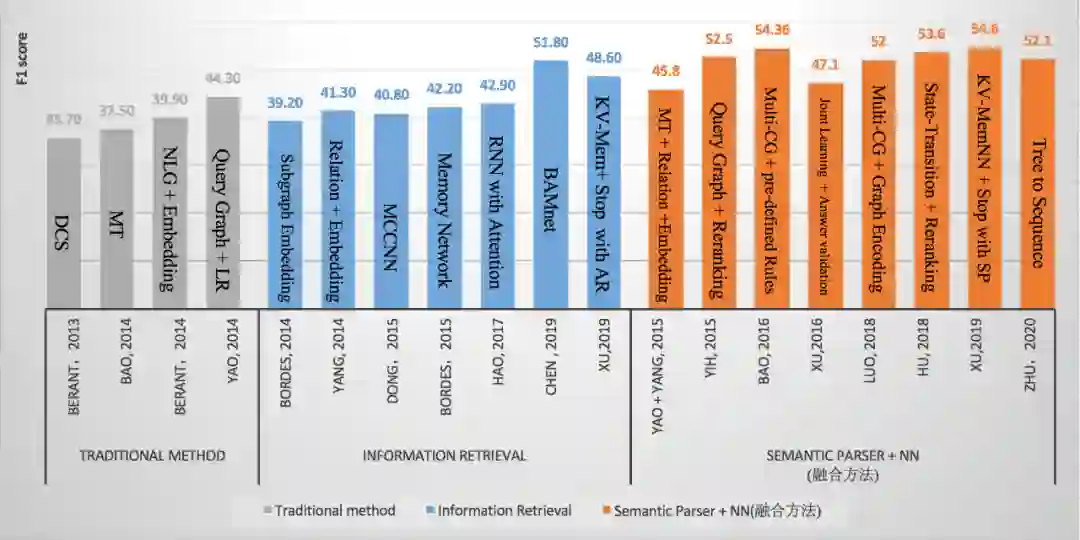
▲ 图1.各方法在WebQuestions上的Benchmark
从上图中我们可以看到,早期研究人员利用传统方法, 通过手工构建模板和规则的方式解析复杂问题,但是此类方法的不足在于需要较专业的语言学知识且可扩展性不强。
随着深度学习在 NLP 领域的应用,研究人员将 QA 问题视为用户 Query 与答案的二分类或者排序问题(IR),利用不同的网络结构(CNN or Attention),并结合 KG 中不同的上下文信息来编码候选答案和 Query 的分布式表示,最后通过计算两者间的匹配度选出最终的答案。
此类方法将语义解析问题转化为大规模可学习的匹配问题,它的优点在于减少了对于人工模板的依赖,而缺点是模型的可解释性不强且整体效果欠佳。
与此同时,研究人员将 NN Based 的方法引入到 Semantic Parser 范式中来增强语义解析能力。早期比较主流的方法是利用查询图(Query Graph)生成过程来模拟语义解析过程,对问句进行解析。
随着 Encoder-Decoder 模型在翻译领域的应用,也有研究人员试图将语义解析问题看做是翻译问题,通过设计不同的树形解码器来得到 Query 的语义表示。
最近,借助 KV Memory Network 中的多个记忆槽来解决 KBQA 中多跳推理问题成为了一个趋势,它的优点在于不依赖于人工模板且可解释性较强,缺点是仍然不能很好地解析序数推理和显隐式时间约束的问题。
同时,我们关注到最近出现了基于神经符号机 [10](Neural Symbolic Machine)的解决方案。接下来,我们将详细介绍这些主流方法。
3.1 Semantic Parser
基于 Semantic Parser 的方法通常将自然语言转化成中间的语义表示(Logical Forms),然后再将其转化为可以在 KG 中执行的描述性语言(如 SPARQL 语言)。
3.1.1 传统方法
传统的 Semantic Parser 方法主要依赖于预先定义的规则模板,或者利用监督模型对用户 Query 和语义形式化表示(如 CCG [11]、λ-DCS [12])的关系进行学习,然后对自然语言进行解析。
这种方法需要大量的手工标注数据,可以在某些限定领域和小规模知识库(如 ATIS [13]、GeoQuery)中达到较好的效果,但是当面临 Freebase 或 DBpedia 这类大规模知识图谱的时候,往往效果欠佳。
3.1.2 查询图方法(Query Graph)
上述传统方法除了适用领域较窄外,大多没有利用知识图谱的信息来进行语义解析。论文 [14] 提出了一种基于 Semantic Parser 的知识图谱问答框架 STAGG (Staged Query Graph Generation)。
该框架首先定义了一个可以直接转化为 Lambda 演算的查询图(Query Graph),然后定义了如何将 Semantic Parser 的过程演变为查询图生成过程(4 种 State+4 种 Action)。
最后通过 LambdaRank 算法对生成的查询图进行排序,选出最佳答案。查询图生成过程一共有三个主要步骤:实体链接、属性识别和约束挂载。
针对 Query:“Who first voiced Meg on Family Guy?”,查询图生成过程如图 2 所示:
1. 实体链接部分采用论文 [15] 的实体链接系统得到候选实体和分数;
2. 属性识别阶段会根据识别的实体对候选的属性进行剪枝,并采用深度卷积模型计算 Query 和属性的相似度;
3. 约束挂载阶段会根据预定义的一些规则和匹配尝试进行最值、实体约束挂载;
4. 最后会根据图本身特征和每一步的分数特征训练一个 LambdaRank 模型,对候选图进行排序。
此方法有效地利用了图谱信息对语义解析空间进行了裁剪,简化了语义匹配的难度,同是结合一些人工定义的处理最高级和聚合类问题的模板,具备较强理解复杂问题的能力,是 WebQuestions 数据集上强有力的 Baseline 方法。
而且该方法提出的 Semantic Parser 到查询图生成转化的思想也被广泛地采纳,应用到了 Semantic Parser+NN 方法中。
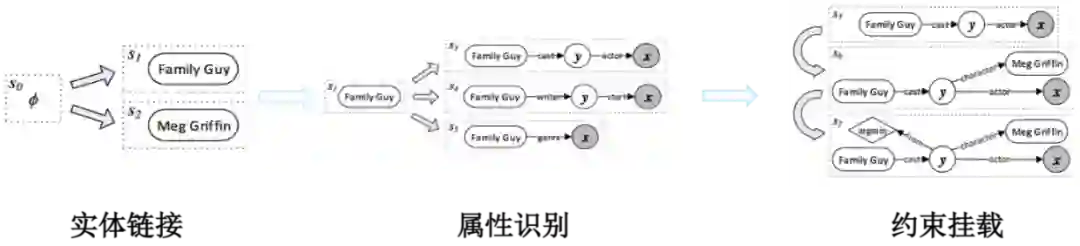
▲ 图2.查询图生成过程图
微软的论文 [5] 在此基础上,扩展了约束类型和算子,新增了类型约束、显式和隐式时间约束,更加系统地提出利用 Multiple Constraint Query Graph(MultiCG)来解决复杂问题的方法。
同时也针对 WebQuestions 数据集复杂问题较少的问题,公开了一个复杂问题数据集 ComplexQuestions。该方法在 WebQuestions 和 ComplexQuestions 数据集上,表现都优于 STAGG 方法。
IBM [16] 沿用 STAGG 的框架,针对属性识别准确率较低的问题,在属性识别阶段,将 Query 和属性名称的字和词 2 个维度进行编码,利用 Hierarchical Residual BiLSTM(HR-BiLSTM,图4所示)计算相似度,提升了属性识别关键模块的准确率,该方法在 SimpleQuestions 数据集上有着优秀的表现,很好地弥补了 Semantic Gap 问题,但是并没有在复杂问题地处理上进行过多地改善。
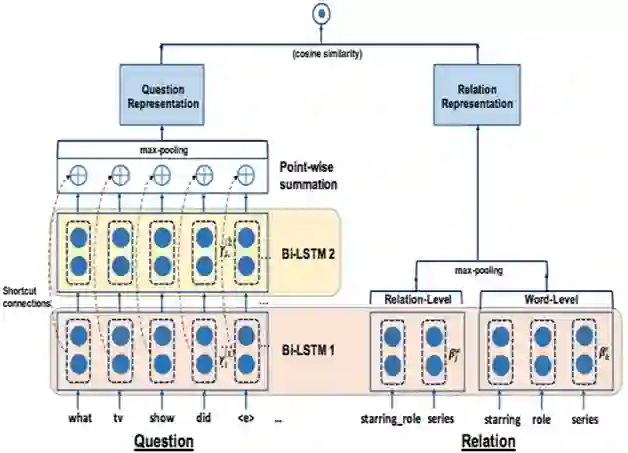
▲ 图3.HR-BiLSTM框架
之前的几种方法虽然取得了不错的效果,但在 Query 与对应的 Query Graph 排序时,没有显式地将 Query Graph 利用神经网络进行泛化性强地语义特征提取,而是利用不同步骤的分数作为特征进行排序。
论文 [17] 提出了一种 Semantic Matching Model(如图5),分别对 Query 和查询图进行编码。
首先对去掉实体的 Query 利用双向 GRU 进行全局编码得到
,然后对 Query 进行依存分析,并利用 GRU 对依存路径进行编码,收集句法和局部语义信息,得到 ,最后两者求和得到 query 编码 。
然后利用查询图中的所有属性名编码和属性 id(将属性名组合)编码,得到图的编码向量
。最后利用 Cosine 距离计算 Query 与查询图的相似度
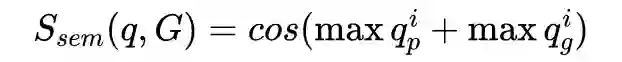
该方法首次将 Query Graph 进行语义编码,计算与 Query 间的相关性程度,并以此作为匹配特征训练模型。该方法在 ComplexQuestions 数据集上的表现优于 MultiCG 的方法,但是依然不能很好地利用神经网络模型处理显隐式时间约束等复杂问题。
▲ 图5.Semantic match model的整体架构
上述方法在对 Query Graph 进行编码的时候,因为最后使用了 Pooling,所以并没有考虑实体和关系的顺序问题,论文 [18] 提出 Tree2Seq 的方法,将 Query Graph 利用 Tree-based LSTM 进行编码,虽然并没有在 WebQuestions 等数据集上取得 SOTA 的效果,但是验证了 Query 结构信息在 QA 任务上的有效性。
3.1.3 编码器-解码器方法(Encoder-Decoder)
随着深度学习的方法和应用,NN-Based 的 KBQA 逐渐成为了一个重要的研究方向 [19],除了 STAGG 等方法中利用 CNN 来提升 Semantic Parser 中属性识别的效果外,基于翻译模型的 Seq2Seq 方法、Attention 机制和 Memory network 也被用来提升 KBQA 的效果。
爱丁堡大学 [20] 提出了利用注意力机制增强的 Encoder-Decoder 模型,将 Semantic Parser 问题转化为 Seq2Seq 问题。
该论文除了使用一个 Seq2Seq 模型来完成 Query 到 Logical Forms 的转化外,还提出了一个 Seq-to-Tree 的模型,利用层次的树形解码器捕捉 Logical Forms 的结构(如图 6 所示)。
该文章主要贡献在于不依赖手工预定义的规则即可在领域数据集上取得 SOTA 方法,但是该方法需要大量的训练语料,因此并不适合通用知识问答数据集。
▲ 图6.Sequence-To-Tree
上述方法利用层次化树形结构优化了 Encoder-Decoder 模型的解码层,而论文 [21] 指出通用的序列编码器利用了词序的特征而忽略了有用的句法信息。
该论文使用 Syntactic Graph 分别表示词序特征(Word Order),依存特征(Dependency)还有句子成分特征(Constituency),并采用 Graph-to-Seq 模型,利用图编码器将 syntactic graph 进行编码。
然后利用 RNN 对每时刻的状态向量和通过 Attention 得到的上下文信息进行解码得到对应的 Logical Forms。尽管该方法验证了额外的句法信息引入有利于提升模型的鲁棒性,但是没有解决对于大量训练语料的依赖问题。
3.1.4 Transition-Based 方法
北大 [22] 提出了 State Transition-based 方法,通过定义 4 种原子操作(图7所示)和可学习的状态迁移模型,将复杂文图转化为 Semantic Query Graph(转化过程如图 8 所示)。
该方法可以利用 BiLSTM 模型识别出多个节点(如多个实体),并用 Multi-Channel Convolutional Neural Network (MCCNN) 抽取节点间的多个关系,克服了查询图生成方法中假设只有一个主要关系和利用人工规则识别约束的缺点,具备更强的鲁棒性。
同时该方法的状态迁移是个可学习的过程,而此前的查询图生成方法中状态迁移过程是预定义的。后续也有论文 [23] 采用 Stack-LSTM [24] 作为状态迁移模型进行语义解析工作。
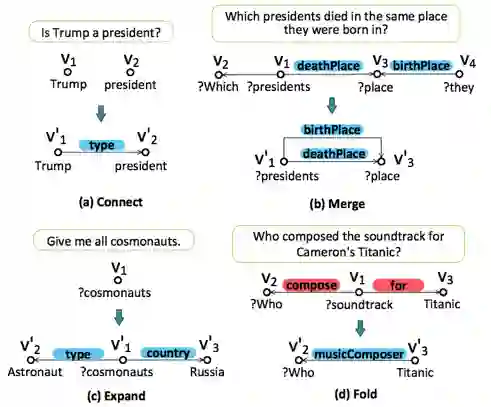
▲ 图7.State转化的4种原子操作
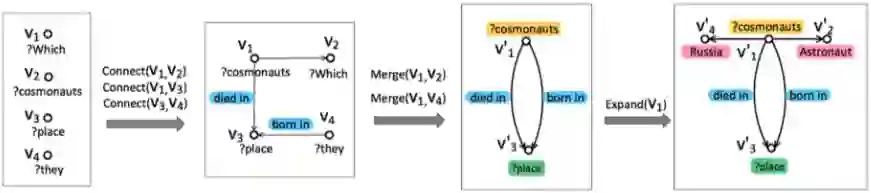
▲ 图8.Query到SQG的转化过程
3.1.5 Memory Network方法
随着机器阅读等技术的普及,近些年基于 Memory Network [25] 的方法也被用来解决复杂问题解析。
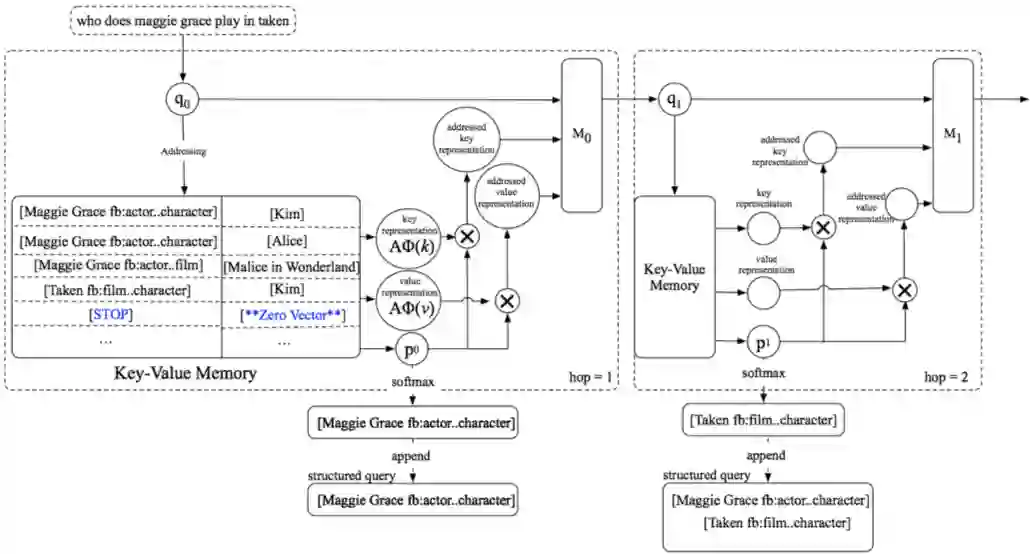
论文 [26] 提出了 Key-Value Memory Network (KV-MemNN),此结构相比扁平的 Memory Network 结构,可以很好地存储具有复杂结构的数据(如 KG),并通过在多个记忆槽内的预测来进行浅层的多跳推理任务,最终生成相关子图路径。
论文 [27] 用 KV-MemNN 来存储图谱中的三元组(SPO)信息,并提出了一个新的 Query Update 机制,实验验证该机制在更新时去掉 Query 中已经定位到的 Key 值,可以让模型能够更好地注意到下一步需要推理的内容。
同时论文在 Key hashing 阶段加入特殊的 STOP 键值,来告诉模型在时刻 t 是否收集了足够的信息回答用户 Query,实验验证了它能避免复杂问题无效的推理过程。
在答案预测阶段,论文实验了基于 Semantic Parser 和 IR 的两种方法,通过消融实验发现,利用 Semantic Parser 进行预测要明显优于 IR 方法,论文猜测因为 Semantic Parser 方法在每一步预测中都会选择最优的 key,比 IR 方法(只用最后一步的表示输出进行排序)利用了更多全局信息。
该方法在不依赖于手工构造模板的情况下,在 WebQuestions 数据集上的效果超过了 SOTA 方法,而且该方法的框架和引入的 Stop、Query Update 机制让整个复杂问题的解析过程具备更好地解释性,我们认为这种利用 KG 进行层次化的解析方法是 KBQA 发展的趋势之一。图 9 为该方法模型结构图。
本章中,我们介绍知识图谱问答中 Semantic Parser 这类方法,分别介绍了4种具体方法:
1)语义解析(Semantic Parser)过程转化为查询图生成问题的各类方法;
2)仅在领域数据集适用的Encoder-Decoder模型化解析方法;
3)基于 Transition-Based 的状态迁移可学习的解析方法;
4)利用 KV-MemNN 进行解释性更强的深度 KBQA 模型。
3.2 Information Retrieval
基于搜索排序(IR)的知识图谱问答首先会确定用户 Query 中的实体提及词(Entity Mention),然后链接到 KG 中的主题实体(Topic Entity),并将与 Topic Entity 相关的子图(Subgraph)提取出来作为候选答案集合,然后分别从 Query 和候选答案中抽取特征。
最后利用排序模型对 Query 和候选答案进行建模并预测。此类方法不需大量人工定义特征或者模板,将复杂语义解析问题转化为大规模可学习问题。
依据特征表示技术不同,IR 方法可以分为基于特征工程的方法和基于表示学习的方法。
3.2.1 基于特征工程的方法
论文 [28] 是该类方法的基础模型,文章首先对问句进行句法分析,并对其依存句法分析结果提取问题词(qword)、问题焦点词(qfocus)、主题词(qtopic)和中心动词(qverb)特征,将其转化为问句特征图(Question Graph,图10)。
然后利用 qtopic 在 KG 内提取 Subgraph,并基于此生成候选答案特征图(图11);最后将问句中的特征与候选特征图中的特征进行组合,将关联度高的特征赋予较高的权重,该权重的学习直接通过分类器来学习。
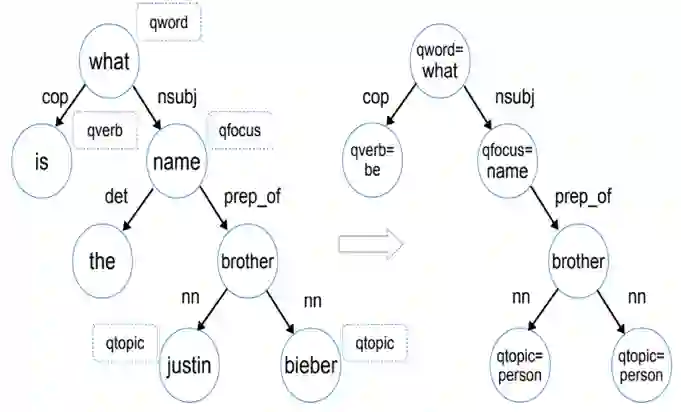
▲ 图10.问句句法分析结果(左)与问句特征图(右)
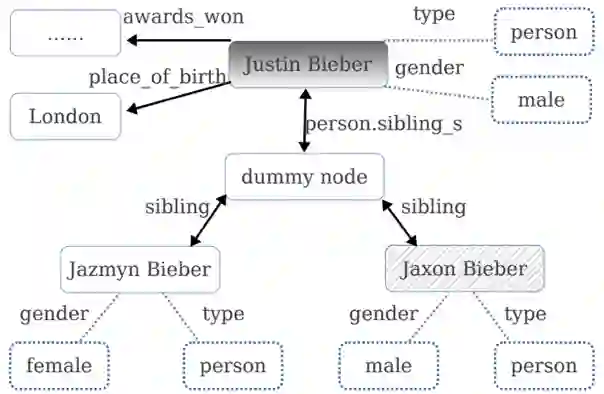
▲ 图11.候选答案特征图
3.2.2 基于表示学习的方法
上述方法有两点不足:第一,需要自行定义并抽取特征,而且问句特征和候选答案特征组合需要进行笛卡尔乘积,特征维度过大;第二,该类方法难以处理复杂问题。为了解决这些问题,学术界利用表示学习方法,将问句和候选答案转换为同一语义空间的向量,将 KBQA 看成是问句与候选答案的表示向量进行匹配计算过程。
1. Embedding-Based方法
论文 [29] 率先将问句以及 KG 中的候选答案实体映射到同一语义空间,其中候选答案实体利用三种向量进行表示:1) 答案实体本身;2) 答案实体与主实体关系路径;3) 与答案实体相关 Subgraph。然后利用 Triplet loss1 对模型进行训练,模型结构如图 12 所示。
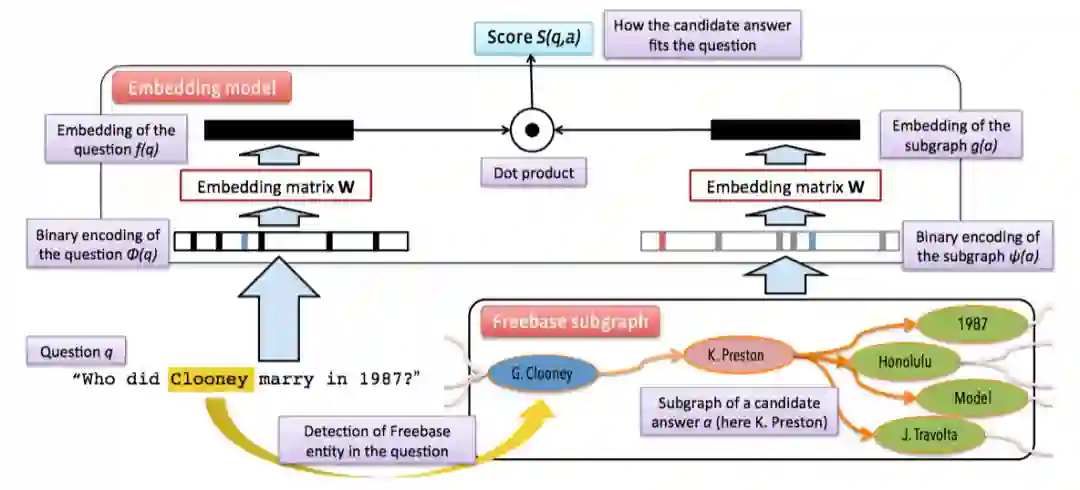
▲ 图12.Subgraph Embedding模型结构图
2. CNN and Attention方法
上述模型针对问句编码采用词袋模型,没有考虑词序对句子的影响,以及不同类型属性的不同特性。论文 [30] 提出 Multi-Column Convolutional Neural Networks (MCCNNs) 如图13所示。
利用CNN分别对问句和答案类型(Answer Type)、答案实体关系路径(Answer Path)和答案实体一跳内的 Subgraph (Answer Context) 进行编码,以获取不同的语义表示。该方法验证了考虑词序信息、问句与答案的关系对 KBQA 效果的提升是有效的。
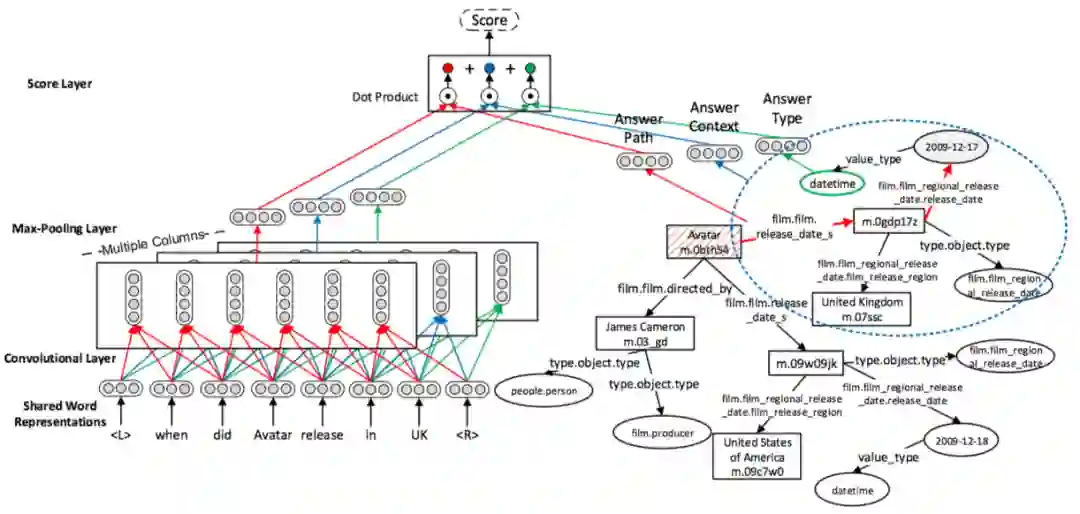
▲图13.MCCNN模型框架图
但是论文 [30] 对于不同答案,将问句都转化成一个固定长度的向量,这种方法不能很好地表达问句的信息。针对该问题论文 [31] 提出了 Cross-Attention based Neural Network(图14 所示)。
将候选答案分成四个维度:答案实体
、答案实体关系路径 、答案类型 和答案上下文(与上述论文相同),然后利用注意力机制动态学习不同答案维度与问句中词的关联程度,让问句对不同答案维度根据注意力机制学习权重,有效地提升问答效果。
论文 [32] 提出了Attentive RNN with Similarity Matrix based CNN(AR-SMCNN,图15所示)模型,利用带有注意力机制的 RNN 来对问句和属性间关系进行建模,并采用 CNN 模型捕捉问句与属性间的字面匹配信息。
该论文验证了字面匹配信息能带来效果上的提升,而实验结果显示,以上两种网络模型对于复杂问题的处理能力依然不足。
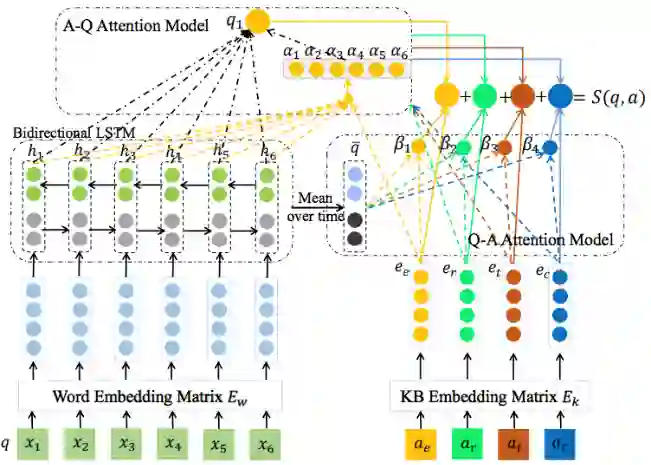
▲ 图14.交叉注意力神经网络
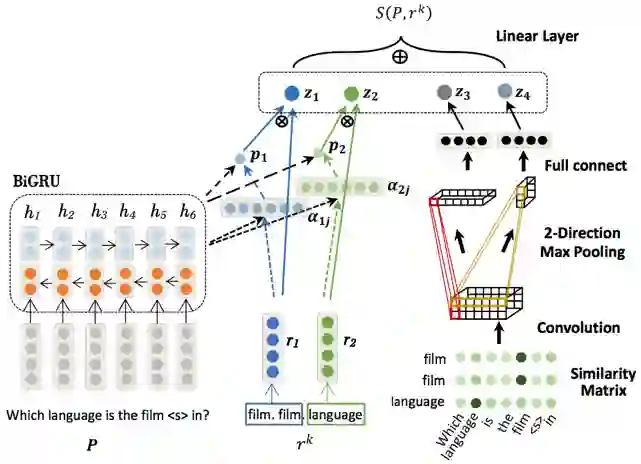
▲ 图15.AR-SMCNN网络框架
3. Memory Network方法
与 Semantic Parser 方法相同,Memory Network (MemNN) 因为其良好的可扩展性以及对于强弱监督 [33] 的适用性,被广泛应用于 KBQA 中。论文 [34] 是将其结合 KG 中三元组信息来解决 KBQA 中简单问题(单跳),同时构建了 SimpleQuestions 数据集。
该论文首先将 KG 中的知识存储到 MemNN 中,然后采样正负例 Query 和正负例的 Answer,两两组合形成多任务,利用 Triplet loss 训练 MemNN。
模型首先通过输入模块(input module)将用户问题、三元组信息转化为分布式表示加入到 Memory 中;然后利用泛化模块(Generalization module)将新的三元组信息(来自 Reverb)加入到 Memory 中。
输出模块(Output module)从 Memory 中选择一些与问题相关性高的三元组信息;回复模块(Response module)返回从输出模块中得到的答案。该论文是 MemNN 在 QA 上的首次尝试,虽然擅长解决简单问题,但是思路为后续的 KBQA 研究工作奠定了基础。
基于上述论文,Jain [35] 提出了一个 L 层的 Factual Memory Network 来模拟多跳推理过程,每层以线性链接,并以上一层输出作为本层输入。
第一层的输入是候选三元组和问句。对问句编码时,为弥补词袋模型无法考虑词序的问题,为每一个词
的不同维度 j 设计一种位置编码(Position Encoding)
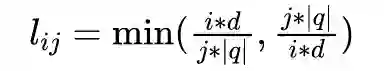
其中 d 是词向量维度。最后使用位置编码更新句向量
。据我们所知,这是首次利用深度模型结合 KG 信息层次化地进行复杂问题的语义解析工作,不仅在 WebQuestions 上验证了这种结构的有效性,也为深度学习模型带来了更好地解释性。
尽管如此,上文提到的方法在编码阶段,将问句和 KG 三元组信息分别进行映射,没有考虑两者间的交互关系。
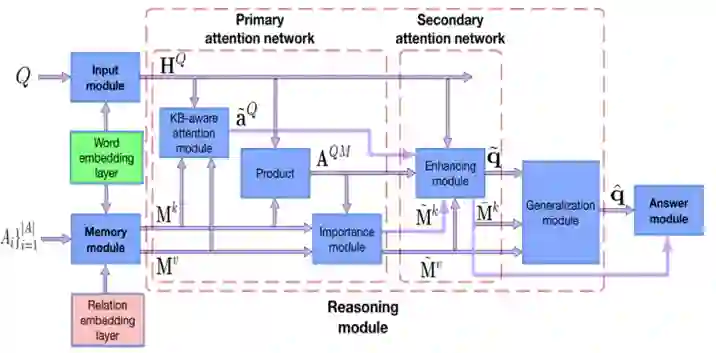
基于此论文 [36] 提出 Bidirectional Attentive Memory Network (BAMnet) 模型, 主要通过 Attention 机制来捕捉 Query 与 KG 信息间的两两相关性,并以此利用相关性增强 Query 的表示,希望能结合到更多的 KG 信息,提升针对复杂问题的处理能力,该方法包含 4 个模块:
1. 输入模块采用 Bi-LSTM 对问句进行编码;
2. 记忆模块(Memory module)针对 KG 信息(答案类型
、答案实体关系路径 、答案上下文 )进行编码存入 Memory network 中;
3. 推理模块分为一个两层的 Bidirectional Attention Network 去编码问句和 KG 中信息间的相互关系和泛化模块(Generalization module)。
模型中 Primary attention network 中的 KB-aware attention module(图17所示)会根据 KG 信息关注问句中的重要部分;Importance module 利用注意力机制计算 KG 中信息与问句的相关程度(比如简单问题对于答案上下文关注度就会降低);
然后在 Enhancing module 中利用 Importance module 计算的相关度权重矩阵,重新更新问句表示和 Memory 中的 Key 值表示,完成第二层 Attention Network;
最后在泛化模块中选取 Memory 中对与问句表示有价值 value,利用 GRU 进行编码,链接到原有问句表示;
4. 回复模块(Answer module)通过计算问句信息和 Enhancing module 中更新过的 KG 信息来得到最后答案。具体见图 16。
该方法与众多 IR 方法一样,在不依赖于人工构建模板的情况下,依靠 Attention 机制和 MemNN,效果比大多数 IR 方法更好,但是并没有引用了 PE 机制的论文 [35] 效果好,我们猜测如果利用 Transformer [37] 的思想,引入词语位置信息,也许可以取得不错的效果。
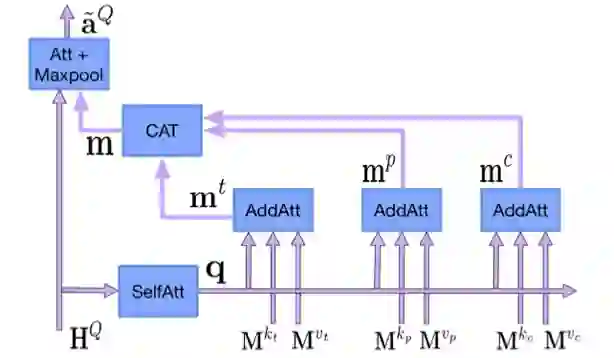
▲ 图17.KB-aware attention module
综上所述,我们可以看出仅仅利用 CNN、Attention 等机制对 Query 与 KG 信息进行简单地端到端模型尽管可以避免大量构造人工模板,但并不能有效解决复杂问题,且部分方法的可解释性不强。
综合 Semantic Parser 方法的实验结果,选用层次化方式建模,并选取有效的网络结构存储复杂的 KG 信息,也许是解决 KBQA 中复杂问题理解和避免人工模板构造的出路之一。
3.3 其他方法
近些年也出现了一些新的方法,不能被简单地归类到上述两类方法中。例如:论文 [38] [39] [40] 尝试使用自动或半自动从 KB 或者 QA 语料中学习模板,并利用模板将问句拆解成Logical Forms 或者理解其意图。
论文 [41] 尝试将一个复杂的问句拆解成几个简单的问句,并从多个简单问句的答案中找出最终的复杂问句答案。
2019年以来,我们也发现有论文尝试利用 Message Passing NN [42] 和 Stepwise Reasoning Network [43] 等方法对于复杂问题进行解析。
最近也有一些研究人员采用神经计算与符号推理相结合的方法进行语义解析。论文 [10] 提出的神经符号机 Neural Symbolic Machine (NSM) 包含 3 个部分,经理(Manager)进行远程监督,利用执行结果对于过程进行指导,提供输入问题和执行的奖赏。
程序员(Neural Programmer)使用 Key-Variable Memory 增强的 Seq2Seq模 型将问句变成程序,符号计算机(Symbolic Computer,如 Lisp Interpreter),利用内置的函数和 Code-Assist(用于将在句法和语法上无效的候选删除)生成一个领域相关的语言,然后执行该语言获得最终的结果。
神经符号计算初步探索了利用神经网络模拟符号推理的过程,使得实现大规模可解释的知识推理与问答成为了可能,我们认为这个方向的发展还有更多探索和尝试的可能。
前沿趋势分析
4.1 更关注复杂问题解析
近些年来,尽管有论文指出 KBQA 中简单问题已经基本被解决 [44],但是在不少论文和我们的实验中显示,实体识别和属性识别一直是影响复杂问题准确率的重要因素。
所以我们认为在对复杂实体链接和具有歧义的易混淆句子上的属性识别工作 [45] 是 KBQA 在工业界落地的一个重要方向。
同时,随着数据集的发展,从 WebQuestions 到 ComplexQuestions、LcQuAD、QALD 等数据集的出现,现在学术界更关注解决包含多跳、聚合、比较或者显隐式时间推理的复杂问题,但是现有方法并没有针对这些具体问题在该类数据集上取得很好地效果。
因此如何能设计更好地网络结构建模复杂问题的逻辑和语义结构、更好地融入 KG 信息解决复杂问题也是需要我们探索的方向。
近来,刘康老师的报告中 [6] 也提到了, 利用神经网络符号计算解决复杂问题,我们也希望看到有研究工作可以利用神经网络对符号计算的模拟,实现解释性强的,可学习地大规模知识问答和知识推理。
4.2 模型鲁棒性增强
深度模型的黑盒不可解释性一直受到研究人员的诟病。论文 [46] 指出在阅读理解任务中,仅在段落中增加一些句子,会使模型效果有大幅下降。我们在 KBQA 实际应用中发现,其对语料的泛化理解以及拒识能力不强,严重影响了 KBQA 模型在工业环境的落地。
但我们没有看到在 KBQA 领域对于模型鲁棒性的研究工作,所以我们认为针对 KBQA 鲁棒性的研究应该其工业应用的重要趋势。论文 [47] 向我们建议了一种生成相反语义句子的方法 [48],感兴趣的读者或许可以尝试一下。
4.3 从单轮问答到多轮交互
真实场景下,用户经常连续询问多个问题,其中部分问题是对话相关,部分问题可以被映射到 KBQA 中。而现在的机器人通常是将问答和对话任务分开解决,我们认为有必要将两种任务统一设计建模,来解决真实场景下的此类问题。
而现在的一些研究在复杂多轮问答(如 CSQA)上的准确率还明显不能落地,期待有更多地工作可以关注这个领域的研究。
小蜜Conversational AI团队的KBQA
小蜜团队持续深耕人机对话方向,打造了一套工业界成型的 KBQA 引擎并落地到真实业务场景中。通过对线上日志的分析,同时参考学术界问题分类的标准,我们总结出小蜜 KBQA 要解决的问题类型:
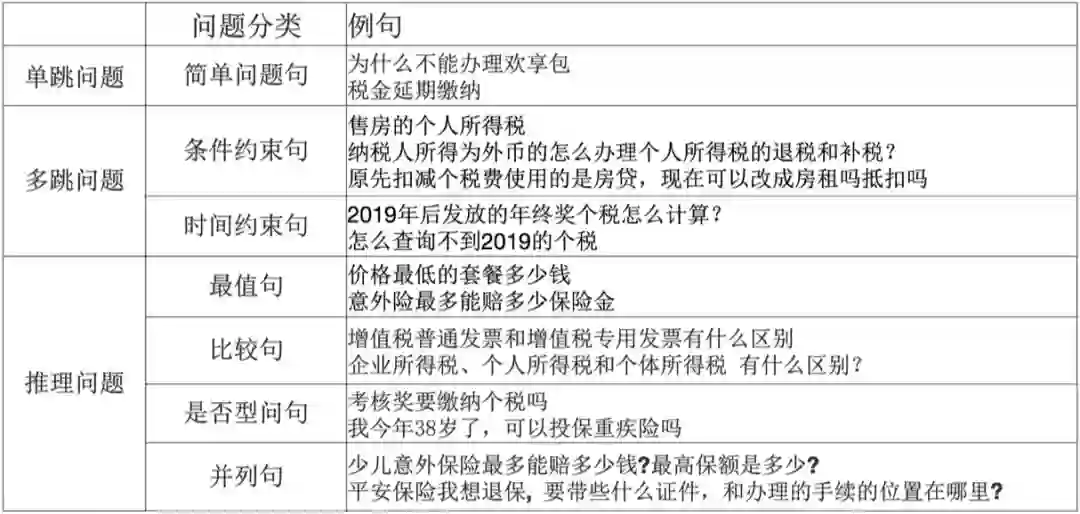
在 KBQA 典型应用领域,例如:电信运营商、税务领域、保险领域,其中包含很多实体以及条件约束,如电信运营商领域,不同流量 (M)、价位 (N) 的各类套餐 (L) 的取消方式都不一样,如果使用 FAQ 方法,会产生 M*N*L 个知识点,造成知识库冗余,而且不能精准地回答用户问题。
我们采用的 KBQA 方案不仅可以精准回答用户问题,还能对 FAQ 知识库进行知识瘦身,减少人工维护成本。
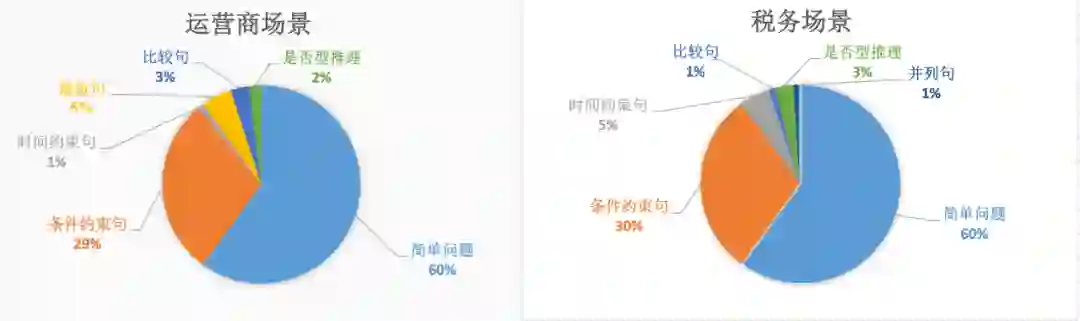
经过分析,在上述几个典型场景中,适合 KBQA 解决的问题占比为 30%~40%,图 18 给出了这些问题不同类型的详细占比。
可以看出,简单问题占比达到 60%,说明大多用户还是希望解决自己的真实问题,而不是考察机器人的能力,但是复杂问题(多跳和推理)也占到了 40%,说明在该类场景的业务也是具备一定复杂程度,如何更精准地回答用户对于这类业务的问题,优化客户人机交互体验,是我们要解决的问题。
我们通过构建面向垂直领域的问答知识图谱,帮助企业挖掘业务知识背后内在的结构化信息,将零散的非结构化知识(石墨)变成有机的结构化知识(钻石),提升领域知识的含金量。
基于领域知识图谱,我们参考学术界方法,研发了基于 MultiCG的Semantic Parser 算法(如图19)对业务中的复杂问句进行解析,并利用Dependency parser模型对约束属性进行消歧,在真实业务场景下,端到端的效果达到 80% 以上,同时也帮助企业的 FAQ 知识库缩容近 10 倍。

▲ 图19.MultiCG with Dependency Parser
在第五部分的前沿趋势分析中,我们指出在真实场景下复杂实体和属性识别是我们亟需解决的问题。在实体识别阶段,因为领域 KG 内实体类别较少,实体消歧工作不是我们关注的重点,但是在用户表述中可能会出现不连续实体或者嵌套实体的问题,如“飞享 18 元 4g 套餐”对应的实体为“飞享套餐”。
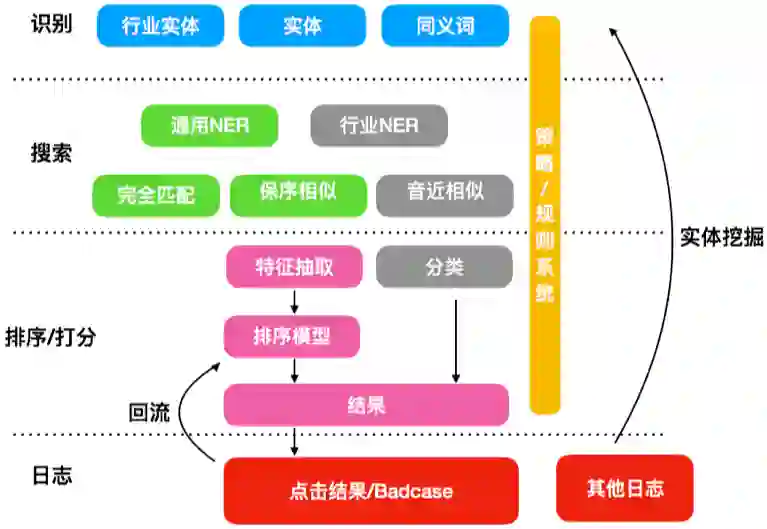
为了更好地识别用户问句中的 mention 并链接到图谱中的实体,减少用户对同义词的配置,我们提出了一个 Search and Rank 框架(如图20),利用匹配和保序相似度等方法对句子中的 mention 和实体进行匹配,再通过排序模型选出最优实体或者进行实体推荐。
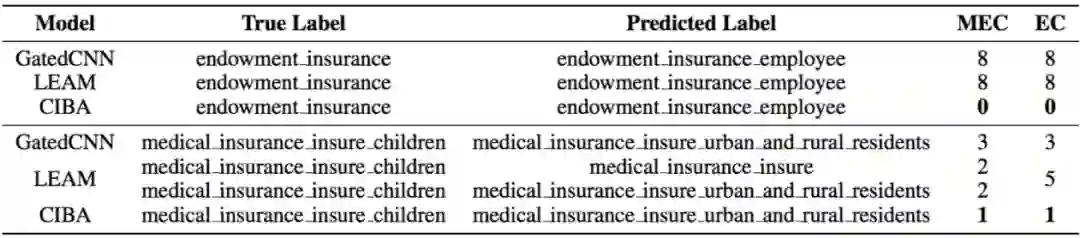
针对属性识别方法,我们提出了一个 Multi-point semantic representation 框架,将每个属性拆解成细粒度的四种因子信息(topic、predicate、object/condition和query type)用以区分易混淆属性,然后利用 Compositional Intent Bi-Attention(CIBA,如图21)将粗粒度的属性信息和细粒度的因子信息与问句表示相结合,增强问句的语义表示。
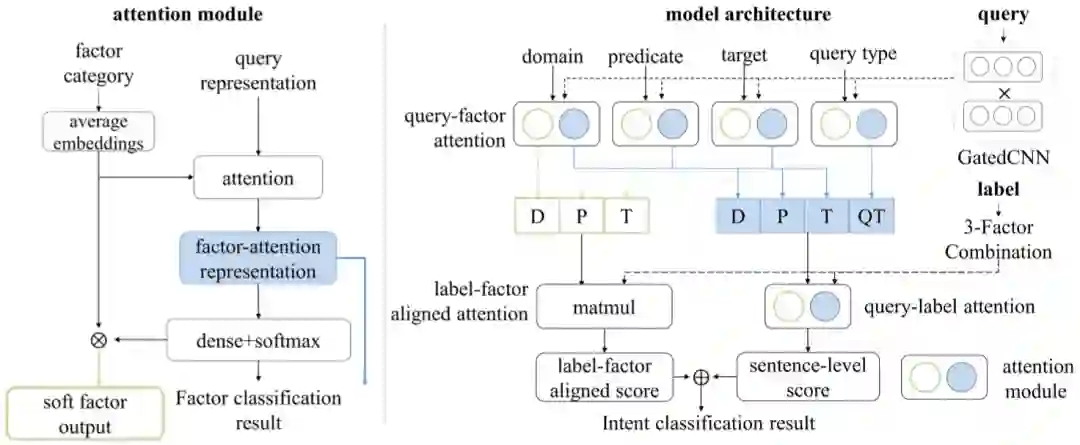
▲ 图21.CIBA模型框架图
实验结果表明(表3和表4),我们提出的方法可以通过属性因子分解减少易混淆属性的错误数量,并在整体分类效果上取得性能提升。相关工作发表在 AAAI 2020 Multi-Point Semantic Representation for Intent Classification 上。
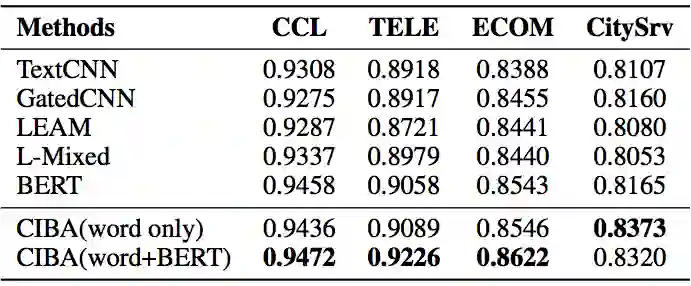
▲ 表3.CIBA模型结果比较
针对模型鲁棒性和表示能力弱,部分约束识别借助人工模板的问题,我们借鉴最近两年 Semantic Parser + NN 方法中 KV-MemNN 的建模思想,我们提出了 Hierarchical KB-Attention Model。
对 Query 与 KB 之间的交互进行了细粒度的建模,以捕捉问句内部核心成分之间的修饰关系,来强化 Query 的层次化语义理解,在效果上超过了 MultiCG 的方法,并且具备更强的复杂问题解析能力和更好的可解释性。
总结
本综述围绕 KBQA 中复杂问题解析的研究进展做了一个详细的介绍,归纳了现有 KBQA 方法面临的两大核心挑战:1) 复杂问题理解难;2) 模型推理能力弱,并针对这两个挑战介绍了 KBQA 主流的两种方法:1) Semantic Parser;2) Information Retrieval。
Semantic Parser 方法中,针对复杂问题理解,我们介绍了利用查询图生成、Encoder-Decoder 和 KV-MemNN 的方法来进行语义解析的方法。
Information Retrieval 方法中我们介绍了利用 Subgraph Embedding、CNN 、Attention 和 Memory Network 机制对 Query 和 KG 不同结构信息进行建模和匹配的方法,此类方法减少了人工模板的依赖,但是可解释性不强,且在现有的数据集结果上效果不佳。
然后我们结合目前 KBQA 的发展,提出了自己对于 KBQA 未来发展趋势的分析。
最后我们对阿里巴巴-达摩院-小蜜 Conversational AI 团队目前在 KBQA 方向上的进展做了一个简明的介绍,输出了我们对于 KBQA 的问题分类、业务场景分析和核心算法概述。希望本篇进展研究可以对读者的研究工作带来一定的启发和帮助。
参考文献
[1] Yang Z, Qi P, Zhang S, et al. Hotpotqa: A dataset for diverse, explainable multi-hop question answering[J]. arXiv preprint arXiv:1809.09600, 2018.
[2] Saha A, Pahuja V, Khapra M M, et al. Complex sequential question answering: Towards learning to converse over linked question answer pairs with a knowledge graph[C]//Thirty-Second AAAI Conference on Artificial Intelligence. 2018.
[3] Berant J, Chou A, Frostig R, et al. Semantic parsing on freebase from question-answer pairs[C]//Proceedings of the 2013 conference on empirical methods in natural language processing. 2013: 1533-1544.
[4] Yih W, Richardson M, Meek C, et al. The value of semantic parse labeling for knowledge base question answering[C]//Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers). 2016: 201-206.
[5] Bao J, Duan N, Yan Z, et al. Constraint-based question answering with knowledge graph[C]//Proceedings of COLING 2016, the 26th International Conference on Computational Linguistics: Technical Papers. 2016: 2503-2514.
[6] 刘康,面向知识图谱的问答系统. AI前沿讲习班第8期PPT
[7] 赵军, 刘康, 何世柱, 陈玉博. 知识图谱[B]. 2018.
[8] Trivedi P, Maheshwari G, Dubey M, et al. Lc-quad: A corpus for complex question answering over knowledge graphs[C]//International Semantic Web Conference. Springer, Cham, 2017: 210-218.
[9] Dubey M, Banerjee D, Abdelkawi A, et al. Lc-quad 2.0: A large dataset for complex question answering over wikidata and dbpedia[C]//International Semantic Web Conference. Springer, Cham, 2019: 69-78.
[10] Liang C, Berant J, Le Q, et al. Neural symbolic machines: Learning semantic parsers on freebase with weak supervision[J]. arXiv preprint arXiv:1611.00020, 2016.
[11] Steedman M. A very short introduction to CCG[J]. Unpublished paper. http://www. coqsci. ed. ac. uk/steedman/paper. html, 1996.
[12] Liang P. Lambda dependency-based compositional semantics[J]. arXiv preprint arXiv:1309.4408, 2013.
[13] Dahl D A, Bates M, Brown M, et al. Expanding the scope of the ATIS task: The ATIS-3 corpus[C]//Proceedings of the workshop on Human Language Technology. Association for Computational Linguistics, 1994: 43-48.
[14] Yih S W, Chang M W, He X, et al. Semantic parsing via staged query graph generation: Question answering with knowledge base[J]. 2015.
[15] Yang Y, Chang M W. S-mart: Novel tree-based structured learning algorithms applied to tweet entity linking[J]. arXiv preprint arXiv:1609.08075, 2016.
[16] Yu M, Yin W, Hasan K S, et al. Improved neural relation detection for knowledge base question answering[J]. arXiv preprint arXiv:1704.06194, 2017.
[17] Luo K, Lin F, Luo X, et al. Knowledge base question answering via encoding of complex query graphs[C]//Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. 2018: 2185-2194.
[18] Zhu S, Cheng X, Su S. Knowledge-based question answering by tree-to-sequence learning[J]. Neurocomputing, 2020, 372: 64-72.
[19] Wu P, Zhang X, Feng Z. A Survey of Question Answering over Knowledge Base[C]//China Conference on Knowledge Graph and Semantic Computing. Springer, Singapore, 2019: 86-97.
[20] Dong L, Lapata M. Language to logical form with neural attention[J]. arXiv preprint arXiv:1601.01280, 2016.
[21] Xu K, Wu L, Wang Z, et al. Exploiting rich syntactic information for semantic parsing with graph-to-sequence model[J]. arXiv preprint arXiv:1808.07624, 2018.
[22] Hu S, Zou L, Zhang X. A state-transition framework to answer complex questions over knowledge base[C]//Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. 2018: 2098-2108.
[23] Cheng J, Reddy S, Saraswat V, et al. Learning structured natural language representations for semantic parsing[J]. arXiv preprint arXiv:1704.08387, 2017.
[24] Dyer C, Ballesteros M, Ling W, et al. Transition-based dependency parsing with stack long short-term memory[J]. arXiv preprint arXiv:1505.08075, 2015.
[25] Weston J, Chopra S, Bordes A. Memory networks[J]. arXiv preprint arXiv:1410.3916, 2014.
[26] Miller A, Fisch A, Dodge J, et al. Key-value memory networks for directly reading documents[J]. arXiv preprint arXiv:1606.03126, 2016.
[27] Xu K, Lai Y, Feng Y, et al. Enhancing Key-Value Memory Neural Networks for Knowledge Based Question Answering[C]//Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). 2019: 2937-2947.
[28] Yao X, Van Durme B. Information extraction over structured data: Question answering with freebase[C]//Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2014: 956-966.
[29] Bordes A, Chopra S, Weston J. Question answering with subgraph embeddings[J]. arXiv preprint arXiv:1406.3676, 2014.
[30] Dong L, Wei F, Zhou M, et al. Question answering over freebase with multi-column convolutional neural networks[C]//Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). 2015: 260-269.
[31] Hao Y, Zhang Y, Liu K, et al. An end-to-end model for question answering over knowledge base with cross-attention combining global knowledge[C]//Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2017: 221-231.
[32] Qu Y, Liu J, Kang L, et al. Question answering over freebase via attentive RNN with similarity matrix based CNN[J]. arXiv preprint arXiv:1804.03317, 2018, 38.
[33] Sukhbaatar S, Szlam A, Weston J, et al. Weakly supervised memory networks[J]. CoRR, abs/1503.08895, 2.
[34] Bordes A, Usunier N, Chopra S, et al. Large-scale simple question answering with memory networks[J]. arXiv preprint arXiv:1506.02075, 2015.
[35] Jain S. Question answering over knowledge base using factual memory networks[C]//Proceedings of the NAACL Student Research Workshop. 2016: 109-115.
[36] Chen Y, Wu L, Zaki M J. Bidirectional attentive memory networks for question answering over knowledge bases[J]. arXiv preprint arXiv:1903.02188, 2019.
[37] Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[C]//Advances in neural information processing systems. 2017: 5998-6008.
[38] Reddy S, T_ckstr_m O, Collins M, et al. Transforming dependency structures to logical forms for semantic parsing[J]. Transactions of the Association for Computational Linguistics, 2016, 4: 127-140.
[39] Abujabal A, Yahya M, Riedewald M, et al. Automated template generation for question answering over knowledge graphs[C]//Proceedings of the 26th international conference on world wide web. 2017: 1191-1200.
[40] Cui W, Xiao Y, Wang H, et al. KBQA: learning question answering over QA corpora and knowledge bases[J]. arXiv preprint arXiv:1903.02419, 2019.
[41] Talmor A, Berant J. The web as a knowledge-base for answering complex questions[J]. arXiv preprint arXiv:1803.06643, 2018.
[42] Vakulenko S, Fernandez Garcia J D, Polleres A, et al. Message Passing for Complex Question Answering over Knowledge Graphs[C]//Proceedings of the 28th ACM International Conference on Information and Knowledge Management. 2019: 1431-1440.
[43] Qiu Y, Wang Y, Jin X, et al. Stepwise Reasoning for Multi-Relation Question Answering over Knowledge Graph with Weak Supervision[C]//Proceedings of the 13th International Conference on Web Search and Data Mining. 2020: 474-482.
[44] Petrochuk M, Zettlemoyer L. Simplequestions nearly solved: A new upperbound and baseline approach[J]. arXiv preprint arXiv:1804.08798, 2018.
[45] Zhang J, Ye Y, Zhang Y, et al. Multi-Point Semantic Representation for Intent Classification[J]. AAAI. 2020.
[46] Jia R, Liang P. Adversarial examples for evaluating reading comprehension systems[J]. arXiv preprint arXiv:1707.07328, 2017.
[47] Chakraborty N, Lukovnikov D, Maheshwari G, et al. Introduction to Neural Network based Approaches for Question Answering over Knowledge Graphs[J]. arXiv preprint arXiv:1907.09361, 2019.
[48] Ribeiro M T, Singh S, Guestrin C. Semantically equivalent adversarial rules for debugging nlp models[C]//Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2018: 856-865.
OpenKG
开放知识图谱(简称 OpenKG)旨在促进中文知识图谱数据的开放与互联,促进知识图谱和语义技术的普及和广泛应用。

点击阅读原文,进入 OpenKG 博客。



