ACL2020表格预训练工作速览

作者:哈工大SCIR 潘名扬、窦隆绪
1. 简介
近年来预训练语言模型(BERT、ERNIE、GPT-3)迅速发展,促进了NLP领域各种任务上的进步,例如阅读理解、命名实体识别等任务。但是目前的这些预训练模型基本上都是在通用文本上进行训练的,在需要一些需要对结构化数据进行编码的任务上(如Text-to-SQL、Table-to-Text),需要同时对结构化的表格数据进行编码,如果直接采用现有的BERT等模型,就面临着编码文本与预训练文本形式不一致的问题。
本文将详细介绍两个表格预训练模型:TaBert和TaPas。他们分别是FAIR&CMU和Google在ACL2020上提出的,通过对结构化的表格数据和与之相关的自然语言句子进行的预训练,增强‘文本’与‘表格’两种多模态数据的对齐。在相关的表格语义解析任务上取得了显著的实验效果。
2. 下游任务介绍与分析:Text-to-SQL
在这里,我们给出Text-to-SQL任务一个相对正式的定义:在给定关系型数据库(或表)的前提下,由用户的提问生成相应的SQL查询语句。下图是一个具体的实例,问题为:有哪些系的教员平均工资高于总体平均值,请返回这些系的名字以及他们的平均工资值。可以看到该问题对应的SQL语句是很复杂的,并且有嵌套关系。

图1 Spider数据集的样例
面向表格的语义解析(如Text-to-SQL)不同于一般的问答任务,不仅需要编码通用文本(如:“哪个国家的GDP最高”),还需要编码结构化的数据(如:有关各国经济情况的若干表格)。其中一个关键的挑战是,如何理解数据库表格中的结构信息(如:数据库名称、数据类型、列名以及数据库中存储的值等),以及自然语言表达和数据库结构的关系(如:GDP可能指的是表中的“国民生产总值”一列)。
因此,有关这一任务的语义解析尝试学习自然语言描述和数据库的(半)结构化信息的联合表示。但是,在应用预训练模型时存在一些问题:1)数据库中的信息存在很强的结构关系,而预训练模型是用于编码自由形式的文本;2)数据库中可能包含大量的行和列,使用简单的语言模型对其进行编码是很困难的;3)语义解析是和特定领域相关的,解析器的结构和底层数据库的结构高度耦合。
3. TaBert(FAIR&CMU)
Pengcheng Yin等人提出了TaBert模型,它是一个用于联合理解自然语言描述和(半)结构化表格数据的与训练方法。TaBert在BERT之上进行构建,能够将表格结构线性化以适配基于Transformer的BERT模型。
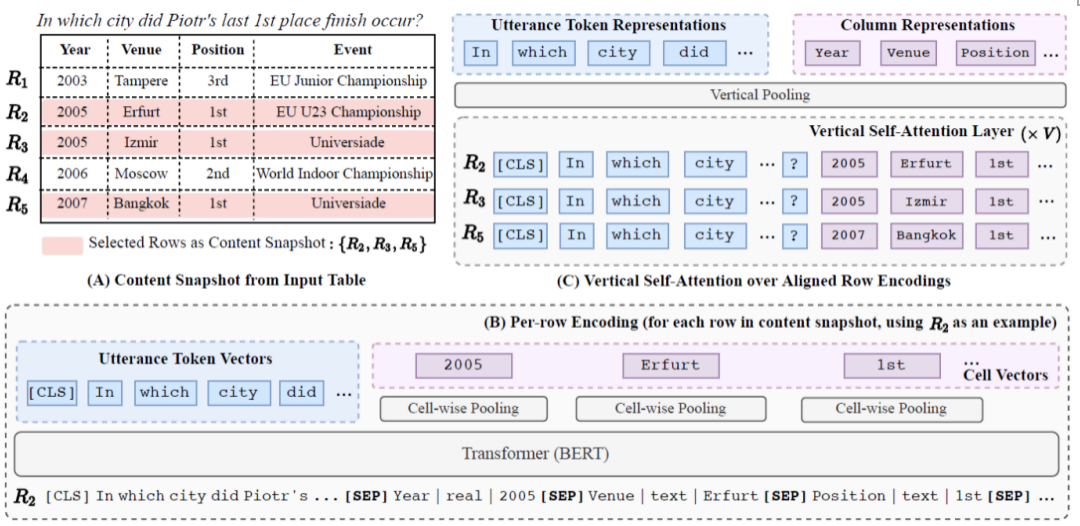
3.1 自然语言描述和表格结构的表示
图2给出了TaBert的原理概览,给定自然语言描述u和表格T,模型首先从表中选取与描述最相关的几行作为数据库内容的快照,之后对其中的每一行进行线性化,并将线性化的表格和自然语言描述输入到Transformer中,输出编码后的单词向量和列值向量。随后编码后的每一所有行被送入垂直自注意力编码层(Vertical Self-Attention),一个列值(一个单词)通过计算同一列的值(同一单词)的垂直排列向量的自注意力得到。最终经过池化层得到单词和列的表示。
3.1.1 数据库内容的快照
由于表格可能包含大量的行,但是只有少数的几行与输入描述相关,对所有的行进行编码是没必要的同时也是难以计算的。因此TaBert使用只包含几行预描述最相关的“内容快照”,它提供了一个有效的方法,能够从列值计算出列的表示。
TaBert使用一个简单的策略来得到一个K行的内容快照。如果K>1,对表中的每一行与输入描述计算n-gram覆盖率,选取前K行作为快照。如果K=1,为了尽可能多的获得表中的信息,TaBert构建了一个合成行,每一列都是从对应列选取n-gram覆盖率最高的一个值,作为合成行这一列的值。这样做的动机是,与描述相关的值可能存在于多行中。
3.1.2 行的线性化
TaBert对内容快照中的每一行进行线性化,作为Transformer的输入。每一个值表示成三部分:列名、类型和单元值,中间使用“|”分割。如上图的B,R2行的2005就可以表示为:

对于一行来说,其线性化即为将所有的值进行连接,中间使用”[SEP]“进行分割。之后在前面链接自然语言描述,作为Transformer的输入序列。
3.1.3 垂直自注意力机制(Vertical Self-Attention)
TaBert中Transformer输出了每一行的编码结果,但是每一行是单独计算的,因此是相互独立的。为了使信息在不同行的表示中流动,TaBert给出了垂直自注意力,可以在不同行的相互对齐的向量中进行计算。
如图2(C)所示,TaBert有V个垂直堆叠的自注意力层。为了生成垂直注意力的对齐输入,首先对每个单元值计算固定长度的初始向量(对Transformer的输出向量进行平均池化)。接下来将自然语言描述的向量序列与初始化后的单元值向量进行连接。
垂直注意力与Transformer拥有相同的参数,但是是对垂直对齐的元素(自然语言描述中的同一个单词,同一列中的单元值)进行操作。这种垂直注意力机制能够聚合不同行中的信息,允许模型捕获单元值的跨行依赖关系。
3.1.4 自然语言描述和列的表示
每一列的表示:在最后一个垂直层中,将对齐的单元值向量进行平均池化,得到该列的表示。描述中每一个单词的表示也采用类似的方式进行计算。
3.2 预训练过程
3.2.1 训练数据
TaBert使用了从英文维基百科和WDC WebTable语料库中收集的表格和与其相邻的文本作为训练数据。预处理后的语料包含26.6M个表和自然语言句子。
3.2.2 无监督学习目标
TaBert使用不同的目标来学习上下文和结构化表的表示。对于自然语言上下文,使用遮蔽语言模型(MLM)目标,在句子中遮蔽15%的token。
对于列的表示,TaBert设计了两个学习目标
遮蔽列预测(Masked Column Prediction,MCP)目标使模型能够恢复被遮蔽的列名和数据类型。具体来说就是从输入表中随机选取20%的列,在每一行的线性化过程中遮蔽掉它们的名称和数据类型。给定一列的表示,训练模型使用多标签分类目标来预测其名称和类型。直观来说,MCP使模型能够从上下文中恢复列的信息。
单元值恢复(Cell Value Recovery,CVR)目标能够确保单元值信息能够在增加垂直注意力层之后能够得以保留。具体而言,在MCP目标中,列ci被遮蔽之后(单元值未被遮蔽),CVR通过这一列某一单元值的向量表示s<i, j>来恢复这一单元值的原始值。由于一个单元值可能包含多个token,TaBert使用了基于范围(span)的预测目标,即使用位置向量e_k和单元的表示s<i, j>作为一个两层网络的输入,来预测一个单元值的token。
3.3 应用示例:基于表格的语义解析
3.3.1 有监督的语义解析
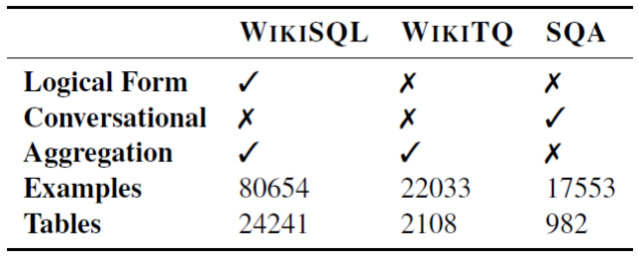
基准数据集:Spider是一个Text-to-SQL数据集,包含10181条数据和超过200个数据库。每一条数据包括:一条描述、一个数据库(包含一个或多个表)、和一条标注的SQL语句。SQL语句通常需要连接多个表进行查询,比如:SELECT COUNT(*) FROM Country JOIN Lang ON Country.Code = Lang.CountryCode WHERE Name = 'Aruba' 。
语义解析器:TranX是一个开源的通用语义解析器,根据用户定义的语法,将自然语言描述翻译成中间表示,中间表示可以转换为特定领域的查询语言(如SQL)。作者使用TaBert作为编码部分,并且使用IRNet中的SemQL(可以理解为SQL的简化版本)作为底层的语法表示。
3.3.2 弱监督的语义解析
弱监督语义解析是指从其执行结果中推断出正确查询的强化学习任务。与有监督的语义解析相比,弱监督语义解析更具有挑战性。因为解析器无法直接获取正确的查询,必须在执行结果的奖励信号的指导下,在指数级的空间中进行搜索。
基准数据集:WikiTableQuestions是一个弱监督语义解析数据集,包含来自维基百科的22033条句子和2108个半结构化的网络表格。与Spider数据集相比,WikiTableQuestions并不涉及夺标的连接,但是需要对表中的一系列条目进行组合、多步推理。
语义解析器:MAPO是一个弱监督的语义解析模型,它将查询的搜索偏向于模型已经发现的高回报的查询,提高了增强算法的效率。MAPO使用一种专门针对单个表回答组合问题的特定于领域的查询语言。作者使用TaBert替换了其中的LSTM编码器部分。
3.4 实验
作者基于BERT_large和BERT_base训练了两个不同的版本:TaBert_large和TaBert_base。并且对比了不同内容快照大小的情况(K=1和K=3),同时与只使用BERT的情况进行对比(可以看作是没有进行与训练的K=1的情况)。
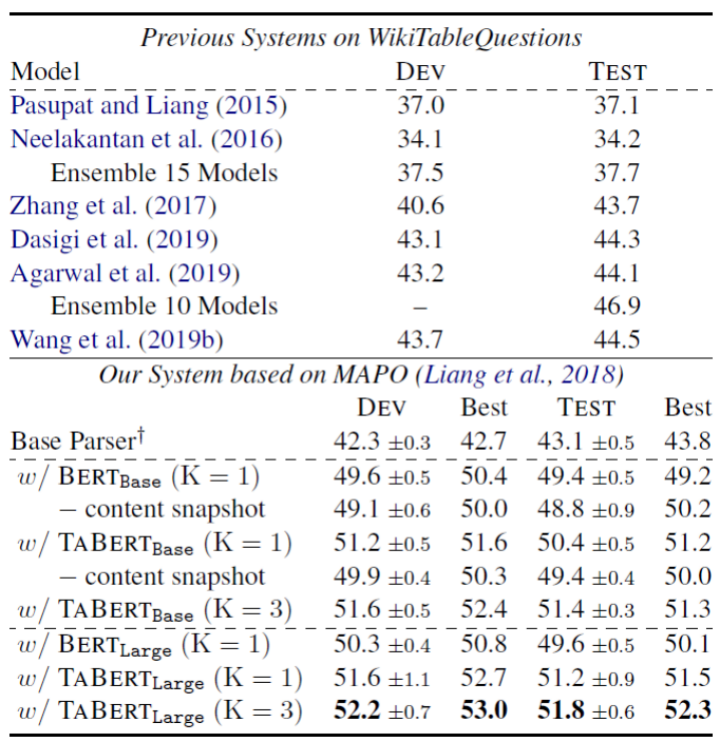
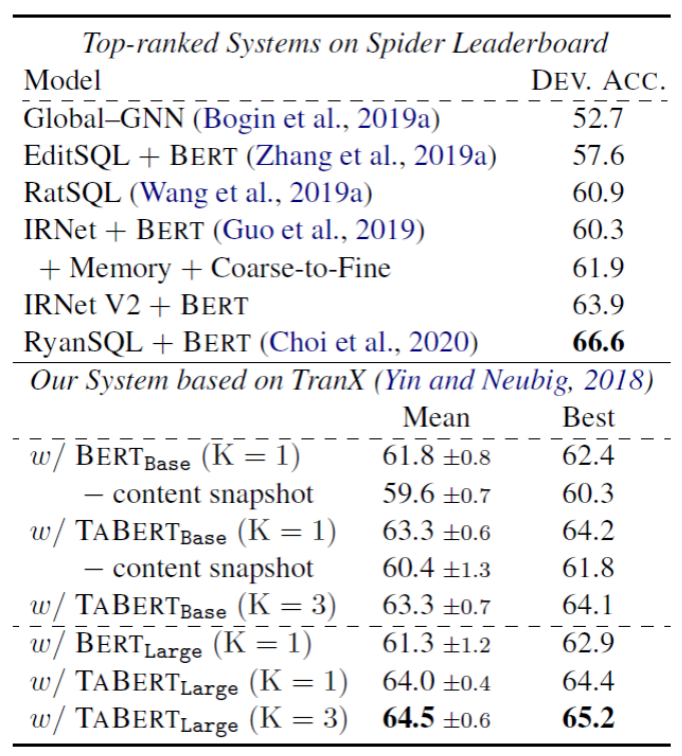
表1和表2展示了在WikiTableQuestion和Spider数据集上的端到端评价结果。可以看到,与现有的语义解析系统相比,使用TaBert作为问句和表格编码器的解析器更具有竞争力。
在WikiTableSQL数据集上,使用K=3的TaBert_large模型使MAPO得到增强,完全匹配准确率达到了52.3%,超过了之前最好的模型(46.9%)。
表1 WikiTableQuestion上的执行准确率
在Spider数据集上,解析器基于TranX构建,并使用和IRNet模型类似的SemQL语法,而TaBert具有更简单的解码器。有趣的是,可以观察到,只使用Bert_base的性能(61.8)与使用Bert增强的IRNet模型(61.9)性能相当。这说明了TaBert的基本解析器是一个有效的baseline。使用TaBert_large(K=3)/进行编码时,模型的准确率达到了65.2,比使用基本模型提升了2.8%,虽然排行榜上其他的系统拥有更复杂的模型,但是TaBert在开发集上的结果已经接近最佳提交(RyanSQL+Bert)的结果。这说明使用TaBert作为表示层可以得到更好的效果。
表2 Spider开发集上的精确匹配准确率
3.4.1 内容快照(content snapshot)的影响
TaBert使用内容快照来从数据库表格中获取与自然语言描述最相关的信息。因此作者实验了内容快照对数据库结构表示的影响(结果已包含在表1和表2中)。在不包含内容快照的设置下,列被表示为“列名 | 类型”而不包含单元值。可以看出,内容快照对于Bert和TaBert都是有效的,说明对列值进行编码有助于模型推断出描述中的实体和对应列之间的对齐。
此外,比较只用一个合成行的TaBert(K=1)和使用输入表中的多行的TaBert(K=3),后者的性能要更好一些。这表明,编码更多与输入句子相关的表的内容更有助于回答涉及多行信息推理的问题。
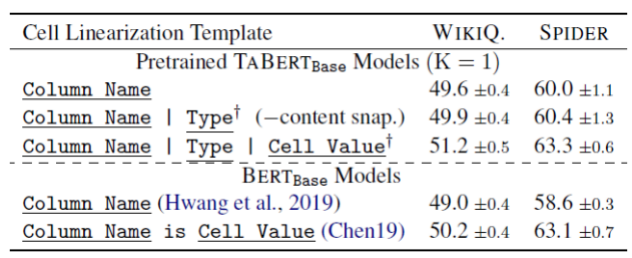
3.4.2 行线性化的影响
TaBert对表格进行线性化作为Transformer的输入,表3(上半部分)给出了不同线性化方法的效果,作者发现,添加类型信息和内容快照可以提高模型性能,因为他们提供了更多列的信息。
同时作者比较了现有的其他线性化方法(表3下半部分):Hwang等人使用Bert对连接的列名进行编码以学习列的表示,但是不编码单元值产生的性能较差。Chen等人提出了一种“自然”的线性化方法,来判断一个自然语言描述是否包含了表中列出的信息。
表3 不同线性化方式的性能
3.4.3 预训练目标的影响
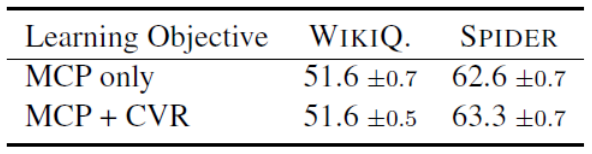
TaBert使用了两个预训练目标:遮蔽列预测(MCP)和单元值恢复(CVR)。表4给出了不同的预训练目标下TaBert的性能。可以看出,使用CVR来辅助MCP得到了略微的提升,这表明CVR可以使列的表示在附加单元值的情况下更具有代表性。
表4 TaBert_base(K=3) 在不同与训练目标下的性能
3.5 小结与未来工作
TaBert是一个用于联合理解文本和表格数据的与训练编码器。实验结果显示,使用TaBert作为特征表示在两个数据集上取得了较好的结果。这也为未来的工作开辟了道路。
首先作者计划在其他涉及对文本和表格联合推理的相关任务上添加TaBert。其次,探索其他的表线性化策略,提升与训练语料库的质量,提出新的无监督目标。最后,将TaBert扩展到跨语言的设置下(使用外语的描述和英语的结构数据),并且使用更高级的语义相似性度量来创建内容快照。
4. TaPas(Google)
Jonathan Herzig等人提出的TaPas,是一种不需要生成逻辑表达式,直接通过表格回答问题的方法。TaPas从弱监督中得到训练,并通过选择表格单元格和选择性地应用相应的聚合运算符来预测结果。TaPas扩展了BERT的结构,使用从Wikipedia爬取的表格和文本片段进行预训练,并且是TaPas端到端的模型。
4.1 TaPas模型
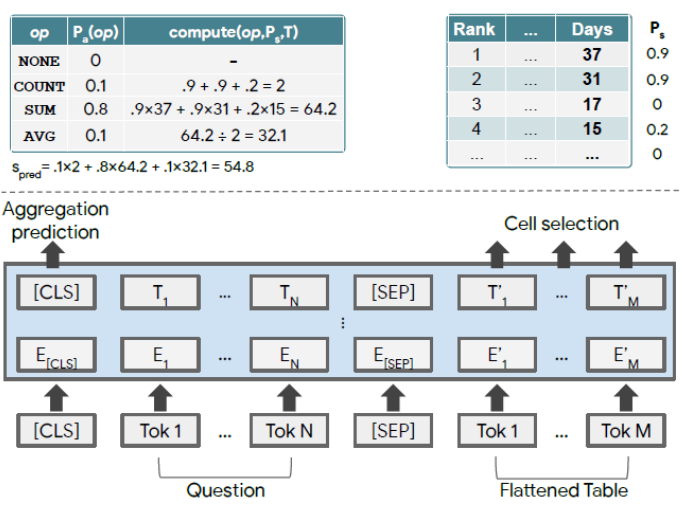
TaPas的结构(如图3)基于BERT编码器,并添加了额外的位置embedding用于编码表的结构。该模型首先将表格平铺成单词序列,并将单词分割成wordpiece(token),并将其连接到问题token之后。此外模型还添加了两个分类层,用于选择单元格和对单元格进行操作的聚合操作符。
4.1.1 附加的Embedding
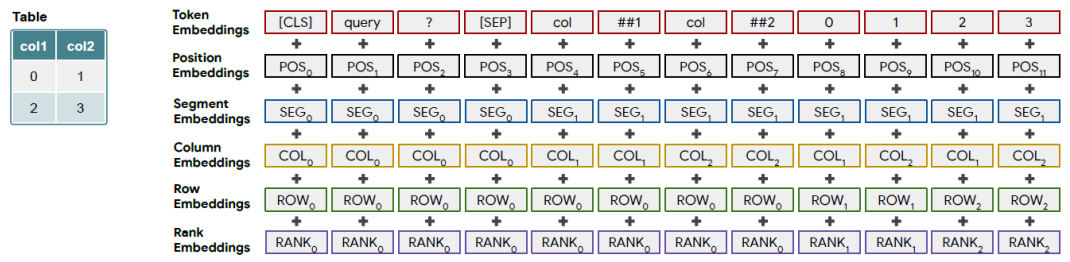
在被送入模型之前,token embedding需要与位置embedding进行结合,模型试用了一下位置embedding:
位置ID:token在序列中的索引(与BERT相同)
片段ID:有两个值:0表示描述,1表示表头和单元值
列、行ID:列、行的索引值。0表示自然语言描述
序数ID:如果一列的值可以被转换为浮点数或日期,就将它们进行排序,基于它们的叙述给定对应的embedding(0表示无法比较,1表示最小,以此类推)
历史答案:在多轮对话的设置中,当前问题可能指示了之前问题或者其答案,于是添加了一个特殊标记:如果该token为前一问题的答案则为1,否则为0。
4.1.2 单元格选取
分类层选取表中单元值的一个子集。由于还可能存在聚合操作,这些单元值可以是最终答案,也可以是用于计算最终答案的输入。每个单元值被建模为伯努利分布,首先计算每个token的logit值,随后计算单元内所有token的logit的平均值作为当前单元的logit值。然后选取所有概率大于0.5的单元格。
此外作者发现,在单一列中选取单元值可以起到一定作用。模型添加了一个分类变量来选取正确的列,通过计算一列中所有单元值的平均值embedding,经过一个线性层得到该列的logit值。此外还添加了一个单独的列,表示不选取任何单元格。
4.1.3 聚合操作预测
语义解析任务通常需要对表格进行推理,如求和、计算平均值等。为了在不生成逻辑形式的情况下处理这些情况,TaPas需要对预测的单元值给定一个聚合操作符。操作符由一个线性层选择,在第一个token的最后一层应用softmax得到选取每一中操作符的概率。
4.2 预训练
作者从维基百科中提取了620万条表格和文本数据,包括330万个infobox和290万个WikiTable。并且只考虑少于500个单元格的表。类似于TaBert,TaPas也采用了MLM(masked language model)作为预训练目标。同时还尝试添加了另一个训练目标:判断表格是否符合文本描述,但是发现对于我们的任务并没有提升。
为了提升训练效率,TaPas将序列的长度控制在一定范围以内。为了适应这一点作者在进行预训练时,从描述中随机选取8~16个单词的文本片段。对于表,首先添加每个列和单元格的第一个单词,然后逐渐添加单词知道达到最大序列长度。为每个表生成10个这样的序列。

4.3 Fine-tuning
4.3.1 单元值选取 (无聚合操作)
-
选择列的平均交叉熵损失:
-
列中单元格选择的平均交叉熵损失:
-
对于不适用聚合操作的情况,定义聚合操作为None(赋值给 ),集合操作loss为:
4.3.2 数值型答案(带聚合操作)

4.3.3 有歧义的答案
4.4 实验
4.4.1 数据集
4.4.2 实验配置
4.4.3 实验结果
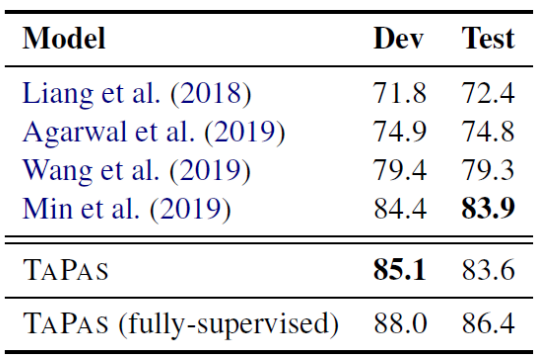
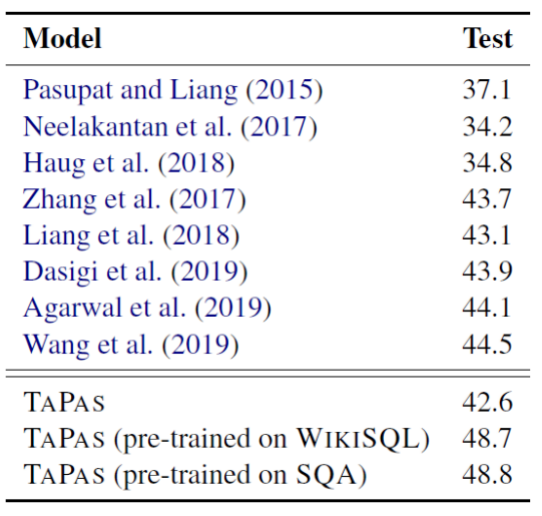
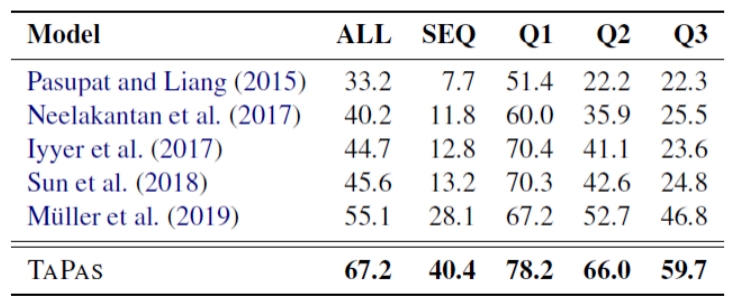
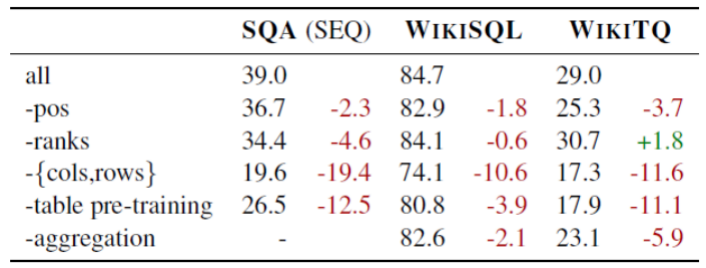
4.4.4 WikiTQ上的定性分析
-
12%左右的数据存在多个答案(“Name at least two labels that released the group’s albums.”)、标签错误或信息缺失 -
10%的数据需要进行复杂的时间比较,而且也复发通过SQL语句等形式进行解析(“what country had the most cities founded in the 1830’s ?”) -
16%的标准答案中的文本类型的值未出现在表格中,需要对其执行字符串操作。 -
10%的表格过大,超过了512的序列长度限制 -
13%的数据没有选择任何单元格,需要对这种行为进行惩罚 -
2%的情况,答案是两个数值之间的差,是模型所处理不了的(“how long did anne churchill/spencer live?”))
4.4.5 预训练分析
表11 Mask LM的准确率
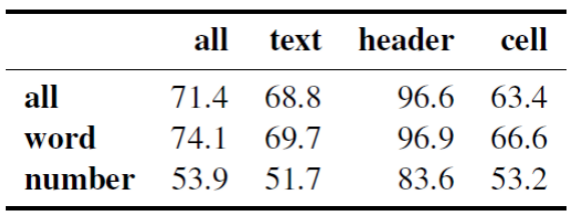
4.4.6 局限性
4.5 小结
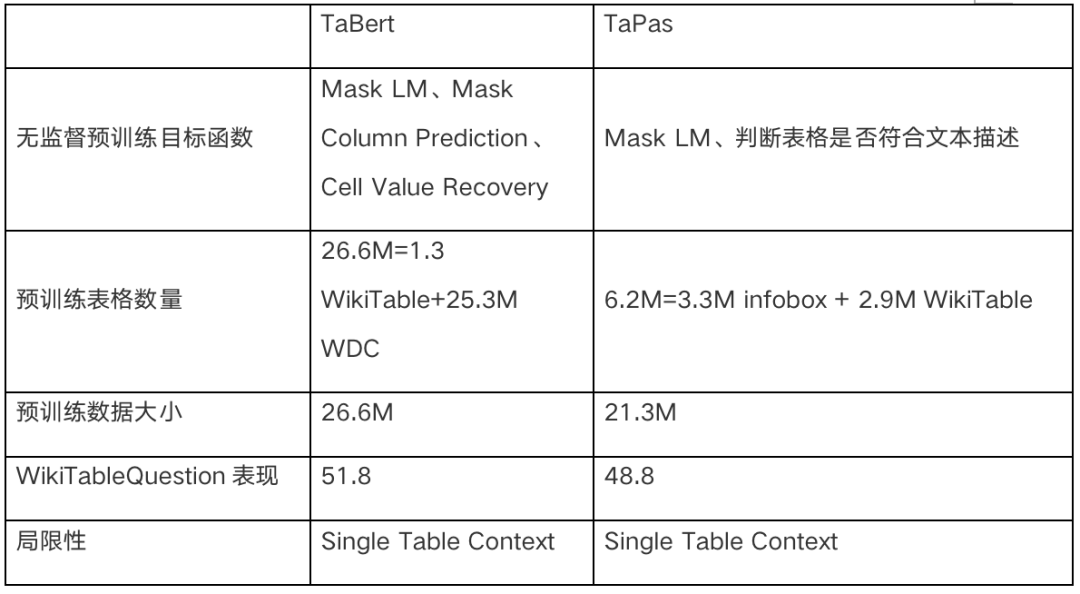
5. 模型对比与未来工作
参考资料
TABERT: Pretraining for Joint Understanding of Textual and Tabular Data.
[2]TAPAS: Weakly Supervised Table Parsing via Pre-training.
[3]Spider: A Large-Scale Human-Labeled Dataset for Complex and Cross-Domain Semantic Parsing and Text-to-SQL Task.
由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方"AINLP",进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心

推荐阅读
征稿启示| 200元稿费+5000DBC(价值20个小时GPU算力)
完结撒花!李宏毅老师深度学习与人类语言处理课程视频及课件(附下载)
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
文本自动摘要任务的“不完全”心得总结番外篇——submodular函数优化
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。

阅读至此了,分享、点赞、在看三选一吧🙏


