新瓶装旧酒:为什么需要知识图谱?什么是知识图谱?——KG的前世今生

点击蓝字,来茶馆喝一杯呀
标题的命名顺序可能让有的读者不太习惯。通常在介绍一个陌生事物的应用前,我们会给出其定义。之所以换个顺序,是为了不让读者一开始就接触比较冰冷生硬的概念刻板描述(后面我尽量用更具体、准确的例子来表达),另一方面也是为了通过现实生活中的例子自然的引入知识图谱的概念。希望通过这种方式加深读者的印象和理解。为了减轻读者理解的负担,我尽可能地避免引入过多的概念和技术细节,将其留到后续的文章进行介绍。
言归正传,本文主要分为三个部分。第一个部分介绍我们为什么需要知识图谱,第二个部分介绍知识图谱的相关概念及其形式化表示。最后,作一个简单的总结,并介绍该专栏后续文章会涉及的内容。
一、看到的不仅仅是字符串
当你看见下面这一串文本你会联想到什么?
Ronaldo Luís Nazário de Lima

估计绝大多数中国人不明白上面的文本代表什么意思。没关系,我们看看它对应的中文:
罗纳尔多·路易斯·纳萨里奥·德·利马
这下大部分人都知道这是一个人的名字了,当然,不出什么意外,还是个外国人。但还是有一部分人不知道这个人具体是谁。下面是关于他的某张图片:

从这张图片我们又得到了额外信息,他是一位足球运动员。对足球不熟悉的可能还是对他没有什么印象。那么再看看下面这张图片:

我再加上当初那洗脑的广告词:“保护嗓子,请用金嗓子喉片。广西金嗓子!”。这下应该许多人都知道他是谁了,毕竟多年前被这洗脑的广告语摧残了很长一段时间。
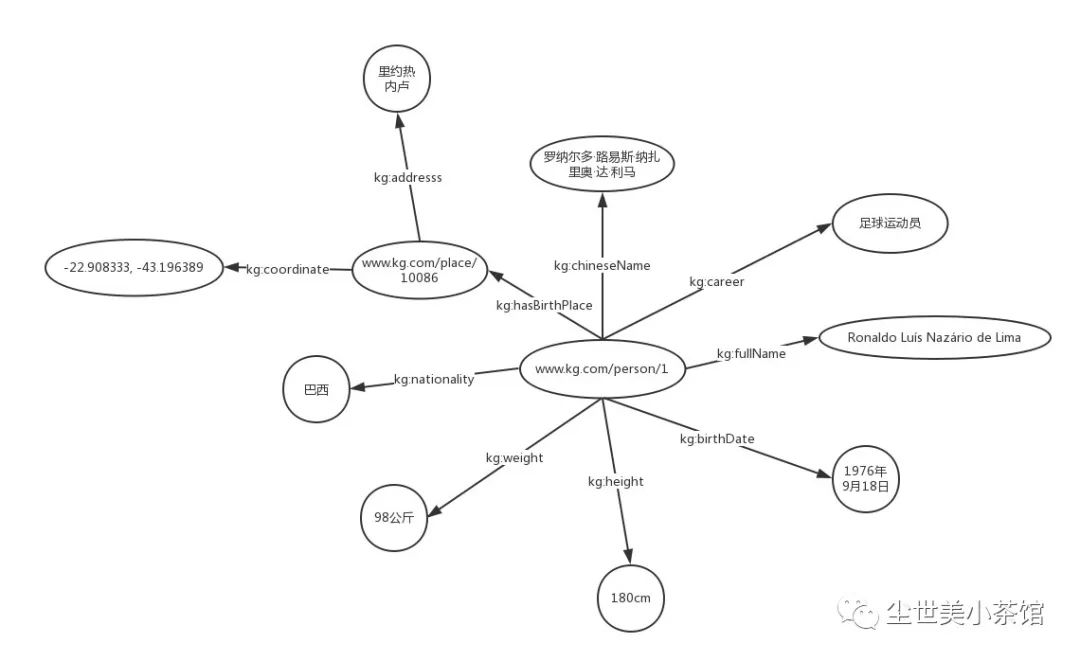
之所以举这样一个例子,是因为,计算机一直面临着这样的困境——无法获取网络文本的语义信息。尽管近些年人工智能得到了长足的发展,在某些任务上取得超越人类的成绩,但离一台机器拥有一个两三岁小孩的智力这样一个目标还有一段距离。这距离的背后很大一部分原因是机器缺少知识。如同上面的例子,机器看到文本的反应和我们看到罗纳尔多葡萄牙语原名的反应别无二致。为了让机器能够理解文本背后的含义,我们需要对可描述的事物(实体)进行建模,填充它的属性,拓展它和其他事物的联系,即,构建机器的先验知识。就以罗纳尔多这个例子说明,当我们围绕这个实体进行相应的扩展,我们就可以得到下面这张知识图。
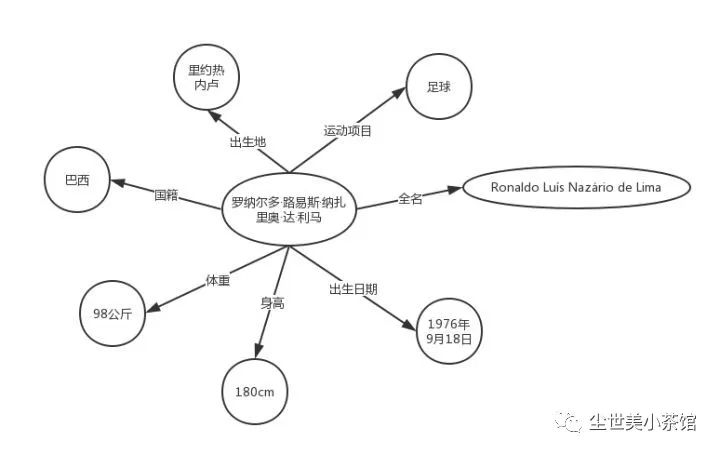
机器拥有了这样的先验知识,当它再次看到Ronaldo Luís Nazário de Lima,它就会“想”:“这是一个名字叫Ronaldo Luís Nazário de Lima的巴西足球运动员。”这和我们人类在看到熟悉的事物,会做一些联想和推理是很类似的。
需要说明的是,上面的知识图并不代表知识图谱的实际组织形式,相反,它还会让读者对知识图谱产生一定的误解。在下一个部分,我会给出这张图所包含内容在知识图谱中更形式化的表示。实际上,我看到许多介绍知识图谱的文章都喜欢给出此种类型的图,却又不给出相应的说明,这可能会让读者一开始就进入理解的误区。
Google为了提升搜索引擎返回的答案质量和用户查询的效率,于2012年5月16日发布了知识图谱(Knowledge Graph)。有知识图谱作为辅助,搜索引擎能够洞察用户查询背后的语义信息,返回更为精准、结构化的信息,更大可能地满足用户的查询需求。Google知识图谱的宣传语“things not strings”给出了知识图谱的精髓,即,不要无意义的字符串,而是获取字符串背后隐含的对象或事物。还是以罗纳尔多为例,我们想知道罗纳尔多的相关信息(很多情况下,用户的搜索意图可能也是模糊的,这里我们输入的查询为“罗纳尔多”),在之前的版本,我们只能得到包含这个字符串的相关网页作为返回结果,然后不得不进入某些网页查找我们感兴趣的信息;现在,除了相关网页,搜索引擎还会返回一个“知识卡片”,包含了查询对象的基本信息和其相关的其他对象(C罗名字简称也为罗纳尔多,搜索引擎只是根据“罗纳尔多”的指代概率返回了“肥罗”这个罗纳尔多的基本资料,但也许你需要C罗的相关信息,那么搜索引擎把C罗这个实体作为备选项列出),如下图红色方框中的内容。如果我们只是想知道罗纳尔多的国籍、年龄、婚姻状况、子女信息,那么我们不用再做多余的操作。在最短的时间内,我们获取了最为简洁,最为准确的信息。
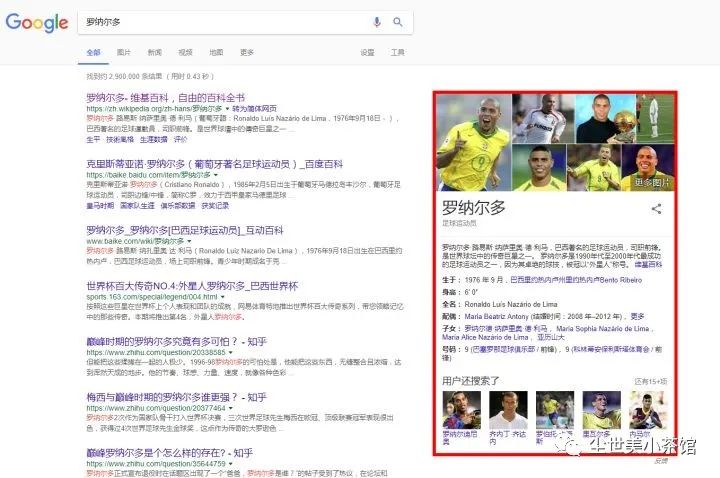
当然,这只是知识图谱在搜索引擎上的一部分应用场景。举这个例子也是为了表明,知识图谱这样一种概念、或者技术,它的诞生是符合计算机科学、互联网发展潮流的。关于知识图谱的更多应用,会在之后的另一篇文章中给出。
二、知识图谱的前世今生
通过上面这个例子,读者应该对知识图谱有了一个初步的印象,其本质是为了表示知识。其实知识图谱的概念并不新,它背后的思想可以追溯到上个世纪五六十年代所提出的一种知识表示形式——语义网络(Semantic Network)。语义网络由相互连接的节点和边组成,节点表示概念或者对象,边表示他们之间的关系(is-a关系,比如:猫是一种哺乳动物;part-of关系,比如:脊椎是哺乳动物的一部分),如下图。在表现形式上,语义网络和知识图谱相似,但语义网络更侧重于描述概念与概念之间的关系,(有点像生物的层次分类体系——界门纲目科属种),而知识图谱则更偏重于描述实体之间的关联。
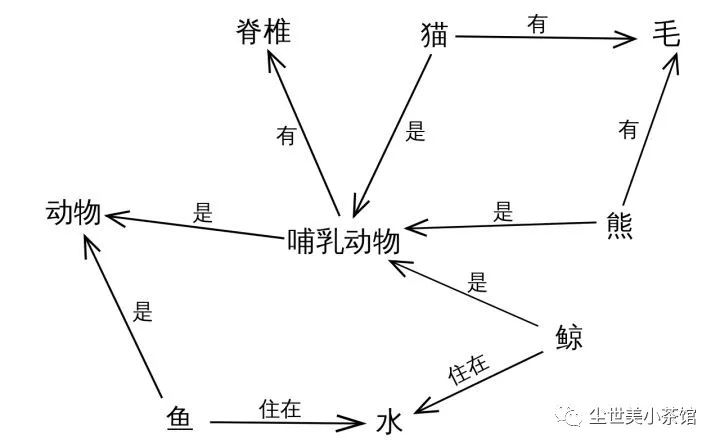
除了语义网络,人工智能的分支——专家系统,万维网之父Tim Berners Lee于1998年提出的语义网(Semantic Web)和在2006年提出的关联数据(Linked Data)都和知识图谱有着千丝万缕的关系,可以说它们是知识图谱前身。
目前,知识图谱并没有一个标准的定义(gold standard definition)。我在这里借用一下“Exploiting Linked Data and Knowledge Graphs in Large Organisations”(公众号“书单”菜单获取介绍和下载链接)这本书对于知识图谱的定义:
A knowledge graph consists of a set of interconnected typed entities and their attributes.
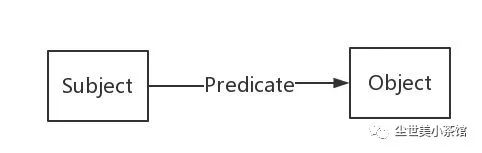
即,知识图谱是由一些相互连接的实体和他们的属性构成的。换句话说,知识图谱是由一条条知识组成,每条知识表示为一个SPO三元组(Subject-Predicate-Object)。
在知识图谱中,我们用RDF形式化地表示这种三元关系。RDF(Resource Description Framework),即资源描述框架,是W3C制定的,用于描述实体/资源的标准数据模型。RDF图中一共有三种类型,International Resource Identifiers(IRIs),blank nodes 和 literals。下面是SPO每个部分的类型约束:
1. Subject可以是IRI或blank node。
2. Predicate是IRI。
3. Object三种类型都可以。
IRI我们可以看做是URI或者URL的泛化和推广,它在整个网络或者图中唯一定义了一个实体/资源,和我们的身份证号类似。
literal是字面量,我们可以把它看做是带有数据类型的纯文本,比如我们在第一个部分中提到的罗纳尔多原名可以表示为"Ronaldo Luís Nazário de Lima"^^xsd:string。
blank node简单来说就是没有IRI和literal的资源,或者说匿名资源。关于其作用,有兴趣的读者可以参考W3C的文档,这里不再赘述。我个人认为blank node的存在有点多余,不仅会给对RDF的理解带来额外的困难,并且在处理的时候也会引入一些问题。通常我更愿意用带有IRI的node来充当blank node,行使其功能,有点类似freebase中CVT(compound value type)的概念。最后的参考资料会给出一篇写blank node缺陷的博客,有兴趣的读者可以看一看。
那么“罗纳尔多的中文名是罗纳尔多·路易斯·纳扎里奥·达·利马”这样一个三元组用RDF形式来表示就是:
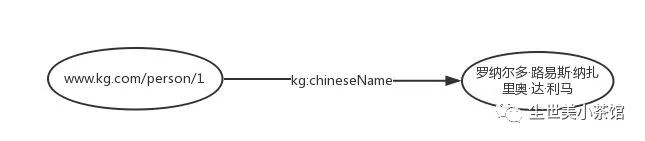
"www.kg.com/person/1"是一个IRI,用来唯一的表示“罗纳尔多”这个实体。"kg:chineseName"也是一个IRI,用来表示“中文名”这样一个属性。"kg:"是RDF文件中所定义的prefix,如下所示。
@prefix kg: <http://www.kg.com/ontology/>
即,kg:chineseName其实就是"http://www.kg.com/ontology/chineseName"的缩写。
将上面的知识图用更正式的形式画出来:
我们其实可以认为知识图谱就包含两种节点类型,资源和字面量。借用数据结构中树的概念,字面量类似叶子节点,出度为0。现在读者应该知道为什么我会说之前那幅图不准确,并会误导大家对知识图谱的理解了吧。"罗纳尔多·路易斯·纳萨里奥·德·利马"作为字面量,是不能有指向外部节点的边的,况且之前的图并不能直观地体现知识图谱中资源/实体(用IRI表示)这样一个极其重要的概念。
三、总结
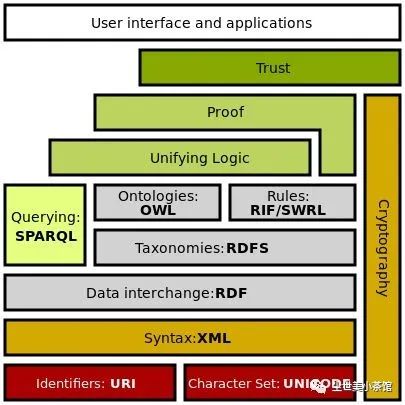
本文通过罗纳尔多这个例子引出了知识图谱的现实需求,继而给出了知识图谱的定义和相关概念,并介绍了知识图谱的RDF形式化表示。作为一篇科普文章,文中省略了许多技术细节。后续我会根据语义网技术栈(Semantic Web Stack,如下图)来介绍知识图谱实现过程中所需要的具体技术。另外,可能会结合实践,介绍如何利用关系型数据库中的数据来构建一个知识图谱,并搭建一个简易的基于知识图谱的问答系统(KBQA)。
1. W3C: RDF 1.1 Concepts and Abstract Syntax
2. Exploiting Linked Data and Knowledge Graphs in Large Organisations
3. Google: Introducing the Knowledge Graph: things, not strings
4. Blog:Problems of the RDF model: Blank Nodes
5. Blog:Compound Value Types in RDF
6. Chen, L., Zhang, H., Chen, Y., & Guo, W. (2012). Blank nodes in rdf. Journal of Software, 7(9).
推荐阅读
征稿启示| 200元稿费+5000DBC(价值20个小时GPU算力)
文本自动摘要任务的“不完全”心得总结番外篇——submodular函数优化
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。

阅读至此了,分享、点赞、在看三选一吧🙏



