【已开源】华为诺亚方舟实验室提出无需数据网络压缩技术
点击上方“CVer”,选择加"星标"或“置顶”
重磅干货,第一时间送达

本文转载自:华为诺亚方舟实验室
华为诺亚方舟实验室联合北京大学和悉尼大学发布论文《DAFL:Data-Free Learning of Student Networks》,提出了在无数据情况下的网络蒸馏方法(DAFL),比之前的最好算法在MNIST上提升了6个百分点,并且使用resnet18在CIFAR-10和100上分别达到了92%和74%的准确率(无需训练数据),该论文已被ICCV2019接收。
论文地址:https://arxiv.org/pdf/1904.01186
开源地址:https://github.com/huawei-noah/DAFL
研究背景
随着深度学习技术的发展,深度神经网络(CNN)已经被成功的应用于许多实际任务中(例如,图片分类、物体检测、语音识别等)。由于CNN需要巨大的计算资源,为了将它直接应用到手机、摄像头等小型移动设备上,许多神经网络的压缩和加速算法被提出。
虽然现有的神经网络压缩算法在大部分数据集上已经可以取得很好的压缩和加速效果,但是一个很重要的问题被忽略了:绝大多数的神经网络压缩算法都假设训练数据是可以获得的。然而,在现实生活应用中,数据集往往由于隐私、法律或传输限制等原因是不可获得的。例如,用户不想让自己的照片被泄露。因此,现有的方法在这些限制下无法被使用。有很少的工作关注在无数据情况下的网络压缩,然而,这些方法得到的压缩后的网络准确率下降很多,这是因为这些方法没有利用待压缩网络中的信息。为了解决这一问题,我们提出了一个新的无需训练数据的网络压缩方法,具体的,我们把给定的待压缩网络看作一个固定的判别器,接着,我们设计了一系列的损失函数来训练生成网络,使得生成图片可以代替训练数据集进行训练,最后,我们使用生成数据结合蒸馏算法得到压缩后的网络。实验表明,我们的算法在没有训练数据的情况下仍然可以达到和需要数据的压缩算法类似的准确率。
使用GAN生成训练数据
由于训练数据在实际中常常无法得到,在此情况下,神经网络的压缩变得十分困难,因此,本论文提出了利用生成网络生成与训练数据相似的样本,以便于神经网络的压缩。生成对抗网络(GAN)是一种可以生成数据的方法,包含生成网络与判别网络,生成网络希望输出和真实数据类似的图片,判别网络通过判别生成图片和真实图片帮助生成网络训练。然而,传统的GAN需要基于真实数据来训练判别器,这对于我们来说是无法进行的。
许多研究表明,训练好的判别器具有提取图像特征的能力,提取到的特征可以直接用于分类任务,所以,由于待压缩网络使用真实图片进行训练,也同样具有提取特征的能力,从而具有一定的分辨图像真假的能力。于是,我们把待压缩网络作为一个固定的判别器,以此来训练我们的生成网络。
然而,在传统GAN中,传统的判别器的输出是判定图片是否真假,只要让生成网络生成在判别器中分类为真的图片即可训练,但是,我们的待压缩网络为分类网络,其输出是分类结果,所以,我们需要重新设计生成网络的目标。通过观察真实图片在分类网络的响应,我们提出了以下损失函数。
在图像分类任务中,神经网络的训练采用的是交叉熵损失函数,在训练完成后,真实图片在网络中的输出将会是一个one-hot的向量,即分类类别对应的输出为1,其他的输出为0。于是,我们希望生成图片也具有类似的性质,我们的交叉熵损失函数定义为:
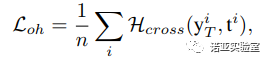
其中
在神经网络的训练中,由卷积核提取的特征也是输入图片的一种重要表示。先前的许多工作表明,卷积核提取的特征包含着图片的许多重要信息,将训练数据输入训练好的深度网络中,卷积核会产生更大的响应(相比于噪声或与此网络无关的数据),基于此,我们提出了特征激活损失函数定义为

目标是让生成图像在待压缩网络中的特征响应值更大,这里我们采用了1范数来优化,原因是1范数相比于2范数会产生更加稀疏的值,而神经网络的响应也常常是稀疏的。
此外,为了让神经网络更好的训练,真实的训练数据对于每个类别的样本数目通常都保持一致,例如MNIST每个类别都含有6000张图片。于是,为了让生成网络产生各个类别样本的概率基本相同,我们引入信息熵,并定义了信息熵损失函数

其中
最后,我们将这三个损失函数组合起来,就可以得到我们生成器总的损失函数:
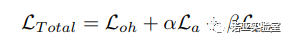
通过优化以上的损失函数,训练得到的生成器可以和真实的样本在待压缩网络具有类似的响应,从而更接近真实样本。
蒸馏算法
除了训练样本的缺失,需要被压缩的神经网络常常是只提供了输入和输出的接口,网络的结构和参数都是未知的。另外,本发明提出的生成网络生成的训练样本是无标注的,基于这两点,我们引入了教师学生网络学习范式,利用蒸馏算法实现利用未标注生成样本对黑盒网络的压缩。
蒸馏算法最早由Hinton提出,待压缩网络(教师网络)为一个具有高准确率但参数很多的神经网络,初始化一个参数较少的学生网络,通过让学生网络的输出和教师网络相同,学生网络的准确率在教师的指导下得到提高。
于是,我们使用交叉熵损失来使得学生网络的输出符合教师网络的输出,具体的损失函数为:


图1 Data-free Learning

实验结果
我们在MNIST、CIFAR、CelebA三个数据集上分别进行了实验。


我们又在CelebA数据集上进行了实验,同样取得了很好的结果。

由于我们的方法由很多损失函数组成,我们通过消融实验来分析每个损失函数项的必要性。表4是消融实验的结果,可以看到,本论文提出的损失函数的每一项都很重要。

最后,我们对教师和学生得到的卷积核做了可视化,可以发现,我们的方法学到的学生网络和教师网络具有非常相似的结构,证明了本论文方法的有效性。

重磅!CVer学术交流群成立啦
扫码添加CVer助手,可申请加入CVer-目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测和模型剪枝&压缩等群。一定要备注:研究方向+地点+学校/公司+昵称(如目标检测+上海+上交+卡卡)

▲长按加群

▲长按关注我们
麻烦给我一个在看!


