
导读:一束光实际选择的路线永远是最快的一条,尽管它看上去比较“远”。对企业来说,现状和目标之间,也存在着一条似远实近的路径,这正是考验企业家的思力和格局之处。
所谓捷径,无非是一种算法

这世界上,很多人都想快速地成功,而成功有捷径吗?
有个成语出自《新唐书·卢藏用传》叫作“终南捷径”,说唐朝人卢藏用中了进士,却没有被授予官职,他干脆跑到京城长安附近的终南山隐居起来。道士司马承祯想退隐天台山,卢藏用建议他隐居终南山。司马承祯看穿了卢藏用:“终南山的确是通向官场的便捷之道啊。”不久,唐中宗果然派人请卢藏用出山做官。
这种通过非暴力不合作来引起朝野注意,最终卖得一个好价钱的逆向行为,可谓是一种捷径。他的名字“藏”和“用”也意味深长。
一脸清高,腹中却含着一团饥火,当然并不高级,不过其背后的道理,却值得探究。
和卢藏用做同样一个梦的还有李白,他则更绝,连科举考试都不屑于参加,野心却又更大,将自己预设为帝王师一类的人物,如同他的偶像谢安那样,先隐居,后掌握大权,建功立业。
这些人不愿意从低级公务员做起,不想一级级往前挪,只想一步登天。对于大众来说,这简直是异想天开。但实际上,“任意门”又是理论上存在的。与大众思维相左的行为,本来就能吸引足够的注意和谈论,于是就有了声望。最高统治者出于征服不合作者的目的也好,或摆出重视人才的姿态也罢,常常也会很配合地来邀请他们共舞一曲—会不会踩到脚则是另外一回事了。

此外,世事一局棋,在帝王们看来,这些山中隐士们或许有“开脑洞”的下法,能帮他们解决困局,而非宦海沉浮中的那些高级官僚所能提供的平庸方案。从这个角度说,一些局外人往往能够一下子看到混乱局面中的关键棋。
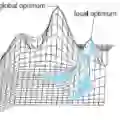
01 困于“局部最优思维”
不少创业者是从其他行业闯入的,因为但凡是局,终有变老变僵的时候,而局中人看不到。
去年,人类棋手中的顶尖高手接连被人工智能AlphaGo碾压式击败。更吊诡地是,遍览人类古今棋局的AlphaGo又被刚出生且“不学无术”的表弟阿尔法元(AlphaGo Zero)给轻松打败了。
最近,AlphaGo的“人肉手臂”、Deepmind资深研究员黄士杰在台湾“中研院”的演讲中谈到他们“喂饲”阿尔法狗和阿尔法元(AlphaGo Zero)的过程,他说:“在推出AlphaGo的改进版 Master之后,Deepmind研究分出两条线,一条是让Master出去比赛,由我来测试;另一条线则是把所有人类知识拿掉,从零开始学习,看AlphaGo Zero可以达到什么程度。”
黄士杰说:“我们在初期预设AlphaGo Zero绝对不可能赢Master。围棋被研究了几千年,一个程序只知道棋盘和规则,一切从零开始,怎么可能会超越几千年的围棋历史?但我们错了……AlphaGo Zero是从乱下开始,找出围棋的下法,它只用了三天,走过了人类研究围棋的千年历程。”
AlphaGo Zero只需要在4个TPU上花3天时间,左右手互搏490万棋局,就找了围棋的规则。而它的前辈AlphaGo需要在48个TPU上,花几个月的时间,学习3 000万个棋局,才打败人类。

论文的第一通讯作者是DeepMind的David Silver博士,也是AlphaGo项目负责人,他表示AlphaGo Zero远比AlphaGo强大,因为它不再被人类认知所局限,而能够发现新知识和新策略。
但美国的两位棋手则在Nature上点评AlphaGo Zero道:“它的开局和收官与专业棋手的下法并无区别,人类几千年的智慧结晶,看起来并非全错,但是中盘看起来则非常诡异。”
在杜克大学人工智能专家陈怡然教授看来,“这或许说明人类的下棋数据将算法导向了局部最优(local optima),而实际更优或者最优的下法与人类的下法存在一些本质的不同,人类实际‘误导’了AlphaGo。”
他说:“AlphaGo Zero降低了训练复杂度,摆脱了对人类标注样本(人类历史棋局)的依赖,让深度学习用于复杂决策更加方便可行。其最有趣之处,是证明了人类经验由于样本空间大小的限制,往往都收敛于局部最优而不自知(或无法发现),而机器学习可以突破这个限制。之前大家隐隐约约觉得应该如此,而现在是铁的量化事实摆在面前。学习人类选手的下法虽然能在训练之初获得较好的棋力,但在训练后期所能达到的棋力却只能与原版的AlphaGo相近,而不学习人类下法的AlphaGo Zero最终却能表现得更好。”
人类的思维导向局部最优,犹如一个人创造性地做了一件事,其他人都会去模仿他的做法,然后便产生一个路径,在同一条路径上比较效率优劣,而对其他路径视而不见。
又如在一间坐满人的剧院中,想往前挪动一排都非常艰难,然而第一排常常坐不满人,似乎有“方便门”供极少数局外人前往。当极少数人发现了这个“方便门”走向第一排,跟随者便开始蜂拥而至,又将这条道堵塞了。
02 梵高和马斯克
像AlphaGo Zero一样,梵高也是从拿起画笔直接乱画开始的,一个从正规美术学院毕业的人成不了梵高,后来那些学习梵高画风的人也成不了梵高。但是,梵高也在与其他画家切磋,感到自己技法局限的他,还去布鲁塞尔美术学院短期进修了基本技法。几年中,梵高成了世界第一流的画家,尽管在他活着的时候,没有人意识到他的价值。

同样,腾讯的大股东是南非的MIH,阿里巴巴的大股东是日本的软银,换句话说,在那个时间点上,没有中国人真正看懂了腾讯和阿里巴巴的价值。
人类的思维总是导向局部最优,这是我们依赖信仰和搜集知识的过程,也是走向封闭的过程。所谓信仰,就是未亲自证实而决定信任的事情,比如课堂上讲授的绝大部分内容。人为什么要学习?是为了更有效率;通过相信自己认为值得信任的那些人的经验,让自己少走弯路,甚至走上捷径。
另一方面,我们的大脑也是依据这等原理进化而来的,我们会把重复的行为记下来,存入脑基核——一个类似蜥蜴大脑的部分,这样,在执行这些行为时就可以基于习惯,让大脑去解决别的困难任务。
比如当你刚学会开车的时候,将车从车库里驶出来需要大量的脑力和注意力,当你成了老司机,就可以一边干别的事,一边把车开上大街。人们在刷牙之前把牙膏挤到牙刷上的举动也常常是不知不觉中完成的。
人们每天通过几十个甚至上百个这样的“行为组块”活着,如果每件事都要关注一下,大脑就会被生活中的各种琐碎占满,结果只能是死机。另外,习惯常常就是某件事物存在的显相,也被称为风格,艺术家们学习的常常是前人的习惯,即风格,甚至因此沾沾自喜。而我们对一个人看法或者说定义,往往也是他习惯的总集。
尽管哲人们认为,教育应该是培养有独立思考能力的人,而实际上我们的教育没有能力培养梵高。教育的本意和大脑养成的习惯回路一样,都是通过重复和记忆,培养“差不多就行”的产品,这也体现了某种效率。
围棋教育同样如此,同样是在前人经验上的改良,但AlphaGo Zero一上来,就直接敲破了历代人累计修建的框架。商学院教不出企业家,但一方面它可以训练经理人,另一方面,它约等于梵高在布鲁塞尔美术学院那一年所受的技法教育,最后是提供一个思维和资源交流的场地。
硅谷传奇、辍学者彼得·蒂尔则对各级辍学生情有独钟。无论是招募合伙人还是选择投资对象,他往往都是辍学者优先。他的好友、博士辍学的马斯克认为,蒂尔和他都是“第一性原理思维”的信奉者,即:一件事尽管现在还不存在,但只要道理上说得通,就应该去用最经济的方式去实现,而不是像大众那种陷入“类比思维”,即在与他人的比较中做到相对更优,比如产品比别人家更好那种。前者先有具体目标,自上而下;后者没有具体清晰目标,自下而上做好细节,认为好的结果自然产生。

“第一性原理思维”对马斯克而言,就是捷径。他作为外行创办成功的公司,挑战了需要百年底蕴的行业经验,这让人匪夷所思。而人们都认为的捷径却越来越拥堵,最终寸步难行,正如底特律汽车业的衰落。
03 私欲的局限
人类大脑中与习惯相关的部分与爬行动物并无二致,是进化中某个阶段的产物,是肉体生存的保障,是为“小我”的生存繁衍服务的。相对而言,特立独行者需要承担巨大的风险,享受冒险的刺激。
“蜥蜴脑”会下意识选择从众,服从社会认同,但人同时也会被另类人和事吸引。那些真正看到某个“捷径”的人,不易被“蜥蜴脑”所制约,与生之欲保持着某种距离。
历史上的山中宰相无论是梁代陶弘景、唐代的李泌、元代的刘秉忠、明代的姚广孝,都是历史的解局人,帝王们对他们言听计从。而作为道士或僧人,他们十分自觉地与权力保持着相当的距离。
马斯克的偶像、科学家尼古拉·特斯拉1943年1月7日在纽约人旅馆3327房间死于心脏衰竭。这个有700项专利的天才因拒绝出售交流电专利而陷入穷困,并在死后留下了一大笔债务。
杜甫在诗中说:“王杨卢骆当时体,轻薄为文哂未休。尔曹身与名俱灭,不废江河万古流。”杜甫和梵高一样,都是死后被发掘出来的大人物。同样,尽管感到失意与窘困,他却也认为流行的那些,终经不起时间的考验。

按照费尔马的最少时间律,一束光穿过空气进入水中,这就是光走过的路径。光线循着一条直线,直到与水接触。水的折射率与空气不同,所以光走的方向产生了改变。
和我们人类设想的两条理论路径不同,一束光实际选择的路线永远是最快的一条,尽管它看上去比较“远”。对企业来说,现状和目标之间,也存在着一条似远实近的路径,这正是考验企业家的思力和格局之处。
人很难同时执行两种“捷径算法”,否则就像某位著名作家曾对不欣赏他的大学生们说:“我写的小说,比他们写的不知道好多少!唯一的缺点就是我还没有死,等我死了之后,你就知道我的价值了。”
作家所言“因为永远失去,让人倍觉珍贵”的逻辑,正应了纳兰性德追悼亡妻的一句词——“当时只道是寻常”。然而,这位作家的反问中包含着焦虑和计算,犹如去设想梵高没有在窘迫失落所导致的错乱中自杀,而是改名换姓偷偷搭上一艘驶往上海的邮轮,然后,活着的梵高就能看到了被画坛大大认可了的“失踪的梵高”。当然,如果梵高真有这么聪明,走了这条捷径,他也就成不了梵高,很可能早就为了一点浮名和收益去迎合世俗审美了。
两种不同的捷径,如鱼和熊掌一般,常常不可得兼,这便是关于选择的问题。这既像被人用刀架在你脖子上,大喝一声“识时务者为俊杰啊”,让你感到选择艰难;同时,它又关系到生活的方方面面,因此十分地日常。
来源:中欧商业评论
延伸阅读《如何系统思考》
点击小程序了解及购买本书
点击文末右下角“写留言”发表你的观点
推荐语:《第五项修炼》实践版。精通应用“第五项修炼”的详尽指南,在复杂、多变、不确定的世界里,系统思考是你生存的必备技能,发现企业持续、敏捷成长的引擎解决复杂问题、睿智决策的利器。

今日推荐
提高沟通效率,降低运营成本
赶紧试试英特尔、谷歌的目标管理利器
▼
「OKR目标管理法」
长按识别下方海报二维码,立即学习

6大模块精华视频
含小社群亲身指导
系统传授OKR实战心法!

登录查看更多
相关内容

AlphaGo Zero是谷歌下属公司Deepmind的新版程序。从空白状态学起,在无任何人类输入的条件下,AlphaGo Zero能够迅速自学围棋,并以100:0的战绩击败“前辈”。
2017年10月19日凌晨,在国际学术期刊《自然》(Nature)上发表的一篇研究论文中,谷歌下属公司Deepmind报告新版程序AlphaGo Zero:从空白状态学起,在无任何人类输入的条件下,它能够迅速自学围棋,并以100:0的战绩击败“前辈”。Deepmind的论文一发表,TPU的销量就可能要大增了。其100:0战绩有“造”真嫌疑。


相关VIP内容
相关资讯
相关论文