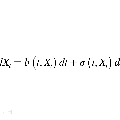为了帮助各位学术青年更好地学习前沿研究成果和技术,AI科技评论联合Paper 研习社(paper.yanxishe.com),推出【今日 Paper】栏目, 每天都为你精选关于人工智能的前沿学术论文供你学习参考。以下是今日的精选内容——
Reinforcement Learning via Fenchel-Rockafellar Duality
Scalable Gradients for Stochastic Differential Equations
Streaming automatic speech recognition with the transformer model
The importance of phase in complex compressive sensing
Do As I Do: Transferring Human Motion and Appearance between Monocular Videos with Spatial and Temporal Constraints
Generating Object Stamps
RoboFly: An insect-sized robot with simplified fabrication that is capable of flight, ground, and water surface locomotion
FrequentNet : A New Deep Learning Baseline for Image Classification
Convolutional Networks with Dense Connectivity
Implementing version control with Git as a learning objective in statistics courses
通过Fenchel-Rockafellar对偶进行强化学习
论文名称:Reinforcement Learning via Fenchel-Rockafellar Duality
论文链接:
https://paper.yanxishe.com/review/8517
推荐理由:作者回顾凸对偶性的基本概念,重点是非常普遍且极为有用的Fenchel-Rockafellar对偶性。
作者总结了如何将这种对偶性应用于各种强化学习(RL)设置,包括策略评估或优化,在线或离线学习以及打折或未打折的奖励。 这些推导产生了许多有趣的结果,包括使用行为不可知的离线数据执行策略评估和基于策略的策略梯度的能力,以及通过最大似然优化来学习策略的方法。 尽管许多结果以前都以各种形式出现过,但是作者对这些结果提供了统一的处理方法和观点,作者希望它们能够使研究人员更好地使用和应用凸对偶工具,从而在RL中取得更大的进步。
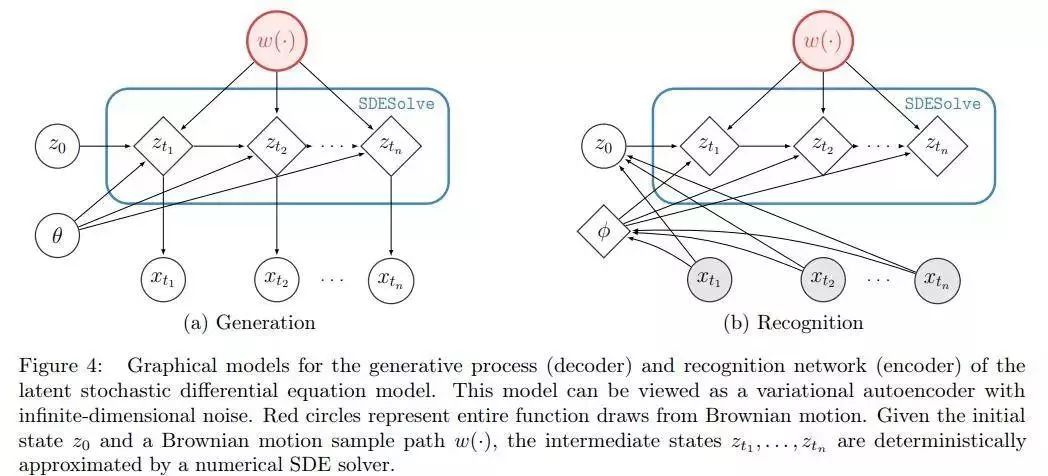
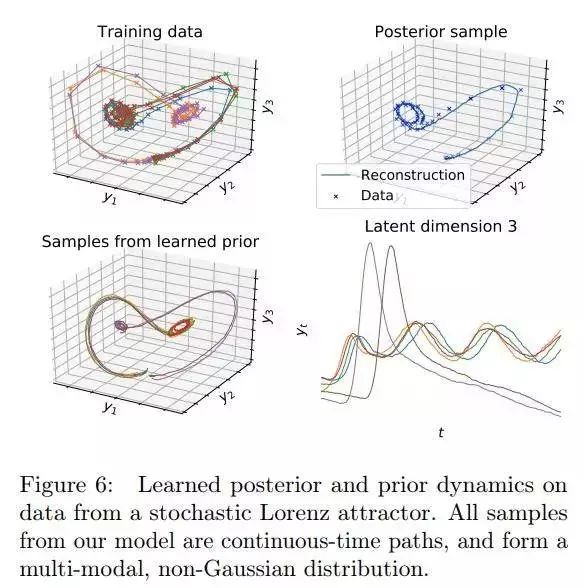
论文名称:Scalable Gradients for Stochastic Differential Equations
作者:Li Xuechen /Wong Ting-Kam Leonard /Chen Ricky T. Q. /Duvenaud David
论文链接:
https://paper.yanxishe.com/review/8518
推荐理由:伴随灵敏度方法可缩放地计算常微分方程解的梯度。 作者将这种方法推广到随机微分方程,从而利用高阶自适应求解器实现梯度的时效性和恒定内存计算。 具体来说,作者推导了一个随机微分方程,其解为梯度,一种用于记忆噪声的内存有效算法以及数值解收敛的条件。 此外,作者将其方法与基于梯度的随机变分推断相结合,以解决潜在的随机微分方程。 作者使用这种方法来拟合由神经网络定义的随机动力学,从而在50维运动捕获数据集上实现竞争性能。
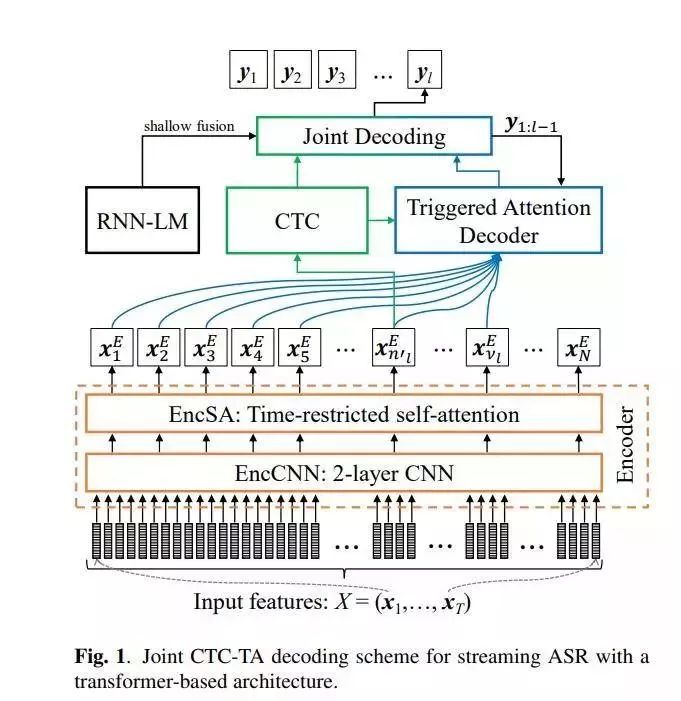
论文名称:Streaming automatic speech recognition with the transformer model
作者:Moritz Niko /Hori Takaaki /Roux Jonathan Le
论文链接:
https://paper.yanxishe.com/review/8514
推荐理由:基于编码器-解码器的序列到序列模型已经证明了端到端自动语音识别(ASR)的最新结果。最近,与基于递归神经网络(RNN)的系统体系结构相比,使用自我注意力对时间上下文信息进行建模的转换器体系结构已显示出显着更低的字错误率(WER)。尽管获得了成功,但实际使用仅限于脱机ASR任务,因为编码器/解码器体系结构通常需要整个语音发音作为输入。
在这项工作中,作者提出了一种基于变压器的端到端ASR系统,用于流式传输ASR,在该系统中,每个口语单词后必须立即生成输出。为此,我们对编码器应用了有时间限制的自注意力,并为编码器-解码器注意机制触发了注意。对于LibriSpeech的“干净”和“其他”测试数据,作者提出的流媒体转换器体系结构实现了2.7%和7.0%的WER,据所知,这是针对此任务发布的最佳流媒体端到端ASR结果。
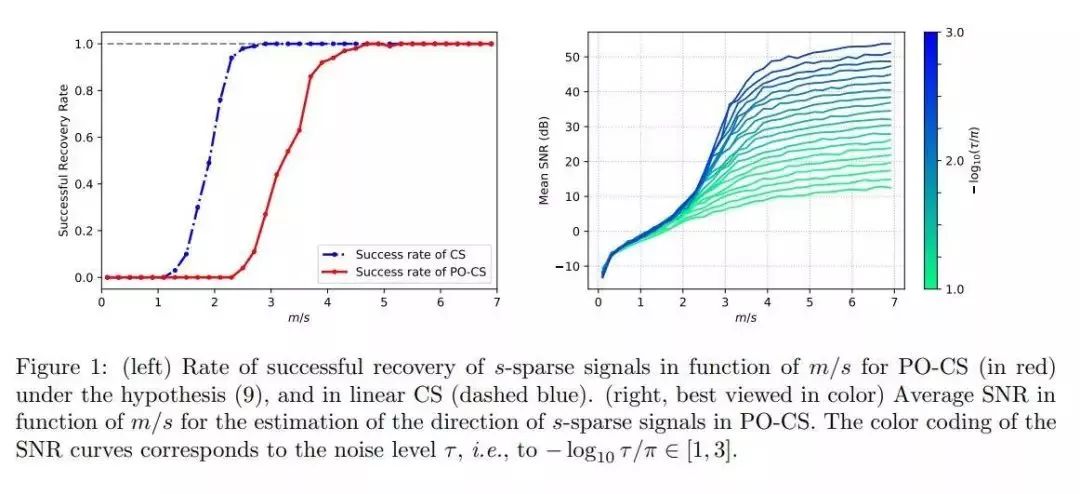
论文名称:The importance of phase in complex compressive sensing
作者:Jacques Laurent /Feuillen Thomas
论文链接:
https://paper.yanxishe.com/review/8513
推荐理由:作者考虑从复杂随机测量的相位(即在仅相位压缩感测(PO-CS)场景中)估计实际的低复杂度信号(例如稀疏矢量或低秩矩阵)的问题。
作者表明,如果感测矩阵是一个复杂的高斯随机矩阵,并且与信号空间的复杂度级别相比测量次数较大,则可以以高概率且高达全局未知信号幅度,来完美地恢复此类信号。 。此外,如果每个测量值都乘以未知符号,则仍可以恢复。作者的方法是通过将(非线性)PO-CS方案重铸为根据信号归一化约束和相位一致性约束(施加任何信号估计以匹配测量域中的观测相位)构建的线性压缩感测模型而进行的。实际上,可以从压缩感测文献的任何实例最优算法(例如,基本追踪去噪)中获得稳定且鲁棒的信号方向估计。通过证明与该等效线性模型关联的矩阵,可以在上述条件下以测量次数高概率满足受限等轴测特性,从而确保这一点。作者最终通过实验观察到,稳健的信号方向恢复大约是压缩感测中信号恢复所需的测量次数的两倍。
像我一样做:在具有时空限制的单眼视频之间转移人类的运动和外观
论文名称:Do As I Do: Transferring Human Motion and Appearance between Monocular Videos with Spatial and Temporal Constraints
作者:Gomes Thiago L. /Martins Renato /Ferreira João /Nascimento Erickson R.
论文链接:
https://paper.yanxishe.com/review/8515
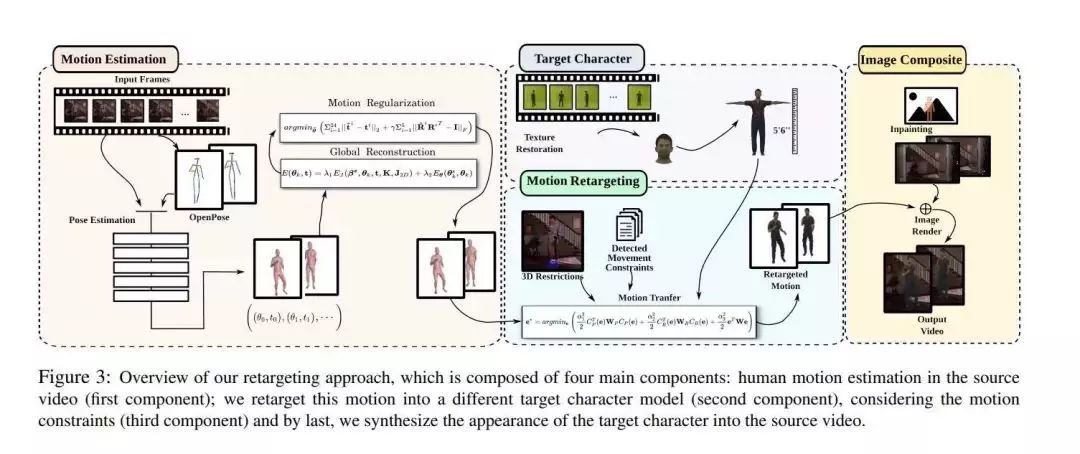
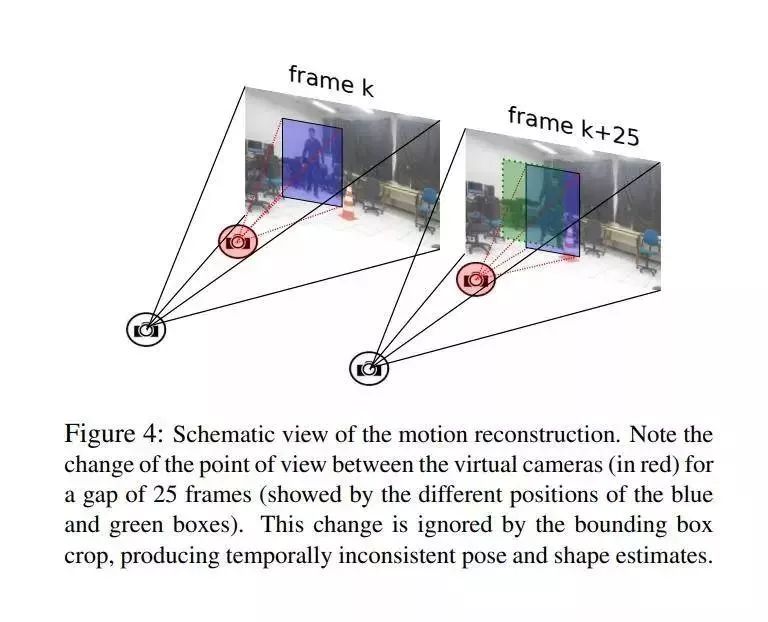
从真实演员的图像创建合理的虚拟演员仍然是计算机视觉和计算机图形学的主要挑战之一。无标记的人类运动估计和来自野外图像的形状建模使这一挑战脱颖而出。尽管最近在视图合成和图像到图像的翻译方面取得了进步,但是当前可用的配方仅限于仅转移样式,并且不考虑角色的运动和形状,而角色的运动和形状天生就混杂在一起以产生合理的人类形式。
在本文中,作者提出了一种统一的公式,用于从涉及所有这些方面的单眼视频中转移外观并重新定向人类运动。作者的方法由四个主要部分组成,并在最初录制他们的不同上下文中合成了新的人们视频。与最近的外观转移方法不同,作者考虑了身体形状,外观和运动约束。评估是使用包含严酷条件的可公开获得的真实视频通过几次实验进行的。其方法能够以超越最新技术的方式传递人类动作和外观,同时保留必须保持的动作的特定特征(例如,脚触摸地板,手触摸特定对象)并保持最佳状态视觉质量和外观指标,例如结构相似度(SSIM)和学习的感知图像补丁相似度(LPIPS)。
由于篇幅有限,剩余五篇的论文推荐精选请扫描下方二维码继续阅读——
生成对象图章
论文名称:Generating Object Stamps
RoboFly:昆虫大小的机器人,具有简化的制造工艺,能够飞行,地面和水面移动
论文名称:RoboFly: An insect-sized robot with simplified fabrication that is capable of flight, ground, and water surface locomotion
FrequentNet:用于图像分类的新的深度学习基准
论文名称:FrequentNet : A New Deep Learning Baseline for Image Classification
具有密集连接性的卷积网络
论文名称:Convolutional Networks with Dense Connectivity
在统计课程中以Git为学习目标实施版本控制
论文名称:Implementing version control with Git as a learning objective in statistics courses