独家 | 从 MICCAI2017 收录论文一窥人工智能医疗的最近进展
AI 科技评论按:AI研习社公开课系列持续进行中。此次我们请到香港中文大学博士陈浩为大家介绍“人工智能在临床医学影像计算与分析中的应用”这一研究热点,主要从方法、思路、如何结合问题解决的角度介绍了医疗影像领域重要会议MICCAI 2017的部分收录论文。
分享嘉宾陈浩是视见医疗的创始人兼首席科学家,在香港中文大学取得博士学位并获得香港政府博士奖学金,本科毕业于北京航空航天大学并获得金质奖章。研究兴趣包括医学影像计算,机器学习(深度学习), 计算机视觉等。博士期间发表数十篇顶级会议和期刊论文,包括CVPR、MICCAI、AAAI、MIA、IEEE-TMI、NeuroImage等 。担任包括NIPS、MICCAI、IEEE-TMI、NeuroImage等国际会议和期刊审稿人。三维全卷积神经网络相关论文获得2016 MIAR最佳论文奖。2014年以来带领团队在数十项国际性医学影像分析和识别挑战赛中获得冠军。

陈浩博士在学校中研究的就是医学图像计算方向,这次也就给大家分享MICCAI 2017中他自己感兴趣的几篇论文。
MICCAI介绍
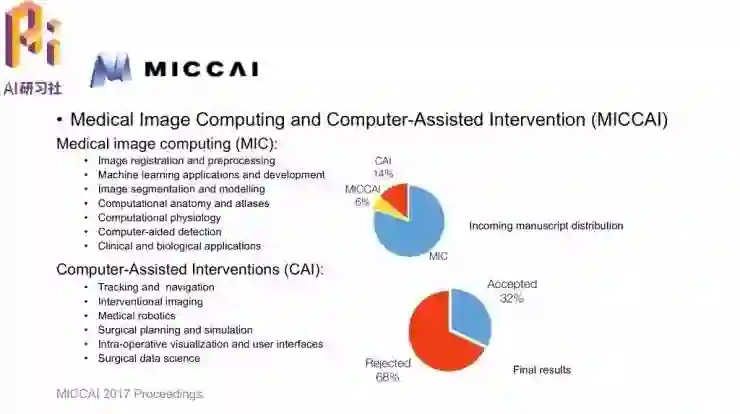
陈浩博士首先介绍了MICCAI会议的情况。MICCAI的全称是Medical Image Computing and Computer-Assisted Intervention,是计算机影像处理计算(MIC)以及计算机辅助介入(CAI)两个领域的综合性会议。MIC中包含的课题包括配准、机器学习、图像分割、传统CAD(计算机辅助检测)以及临床和生物学应用。CAI集中在在介入部分,包括追踪和导航、介入式影像、医用机器人等等。
今年MICCAI中,投MIC方向的论文居多,其余有14%的CAI和6%的MICCAI。总的论文录取率为32%。从录取率来看,MICCAI是医学领域的会议中论文录取比较严格的。(录取率与CVPR、ICCV相当)

MICCAI 2017中,共接收了分属15个组的255篇论文;图中标红的组是录取量相对比较大的组,包括配准、脑相关研究、MRI&张肌/纤维处理、光学成像、运动和心脏图像分析,还有一个较大的部分是特征提取和分类;论文数量最多的分组是医学影像计算中的机器学习。
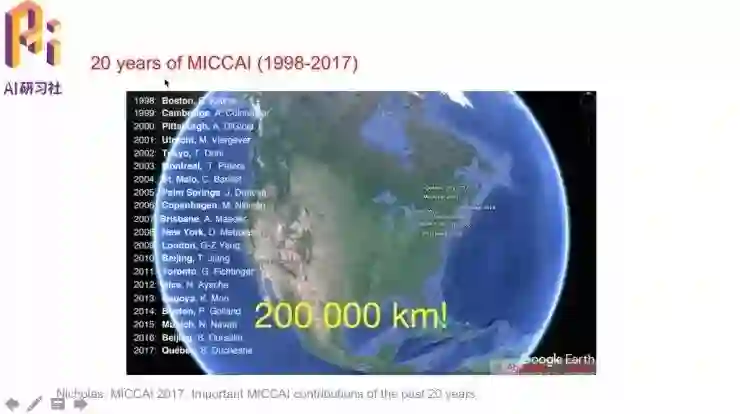
MICCAI 会议从创立到2017年刚好是20周年,在世界多地轮流举办。今年MICCAI的举办地点是加拿大魁北克。

MICCAI 最初是在1998年由三个小会议CVRMed、VBC、MrCAS组成的。2004年时MICCAI Society正式成立。

回顾MICCAI过去20年中被引量最高的文章,有7篇文章是分割和检测,2015年的U-Net大家也都很熟悉了。

还有9篇文章是做registration,也都比较早了,包括共信息熵、demon算法等著名方法。

有4篇文章是CAI的方向,覆盖到AR/VR、机器人、规划和可视化。
MICCAI 2017 收录论文选读
下面陈浩就开始介绍本届MICCAI上他个人比较感兴趣的论文。

第一篇关于整张图像的多实例分类学习。这项研究的背景是,各种医学图像中诊断病症存在时,如果出现一个正例,就可以认为图像的判定结果是“有疾病、阳性”;但“无疾病”的判定结果需要图像中所有的区块都没有出现正例才行。那这就是多实例学习的范畴。
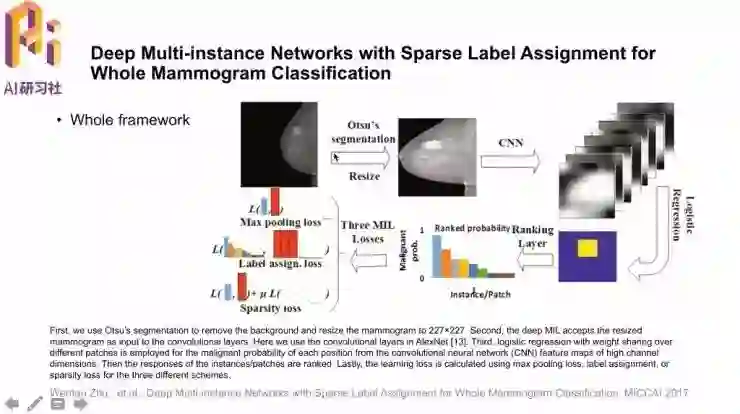
论文名称是「Deep Multi-instance Networks with Sparse Label Assignment for Whole Mammogram Classification」。模型的总体框架是,首先对输入图像进行分割、缩放得到感兴趣的区域,通过CNN提取很多区块后,用线性回归分类器得到可能性排序,最后根据机器学习模型得到影像的判定结果输出。
论文中比较了模型训练中三种不同的损失,最大池化损失、标签设定损失和这篇文章中提出的稀疏性损失。设计这些损失函数的原因如下。

最大池化(Max-pooling)损失是把不同区块的可能性进行排序,选取其中最大的,损失表达式就是交叉熵的负对数似然。它的缺点是,只选择了所有区块中的一个。

对于有多个区块是阳性的情况,就很自然地可以想到标签设定(Label-assignment)损失,选取出k个正例、其余为负例,然后通过损失函数训练网络。损失函数里同样包含了权重的惩罚项。这种损失逻辑上似乎更合理,但具体计算时如何为不同的图像选取适合的k值是一个问题。

稀疏性(Sparsity)损失中就规避了这样的显式的k值选取,提出了很好的求解方法。通过选取超参数μ,配合rn的L1范数,让不同区块的预测结果分别趋向于1或0,实现了稀疏性。
方法的比较结果如图中下方表格,其中也包含了先用ImageNet做预训练再迁移到医学图像的模型。可以看到,在AlexNet加上三种不同损失的结果中,稀疏性损失的模型不仅取得了与预训练CNN+随机森林相当的准确率,AUC更是得到了巨大提升。这样就在这个数据集上得到了很好的表现,而且具有不错的鲁棒性。

论文中作者也展示了模型对不同样本图像的响应值。第一排图像中红框标出的是病灶部位的ground truth,下方是feature map中对应位置的评分。可以看到稀疏性损失模型的预测结果最好。

第二篇是关于图像分割的深度主动学习。医学影像分割的ground truth是非常昂贵的,需要有多年临床经验的专家标注数据;一般计算机视觉问题中通过普通人众包标注建立大规模标注数据集训练模型的方法是行不通的。所以,在数据集中只选取有代表性的数据进行标注就可以降低费用。
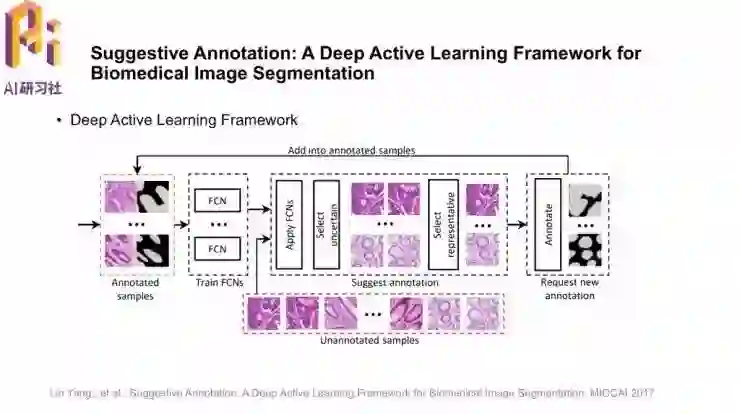
这篇「Suggestive Annotation: A Deep Active Learning Framework for Biomedical Image Segmentation」中的亮点就是采用了主动学习的框架,选取不确定的、有代表性的样本进行标注并训练模型;一直重复这个过程可以更好地指导模型学习,这就是模型中的建议标注suggestive annotation。
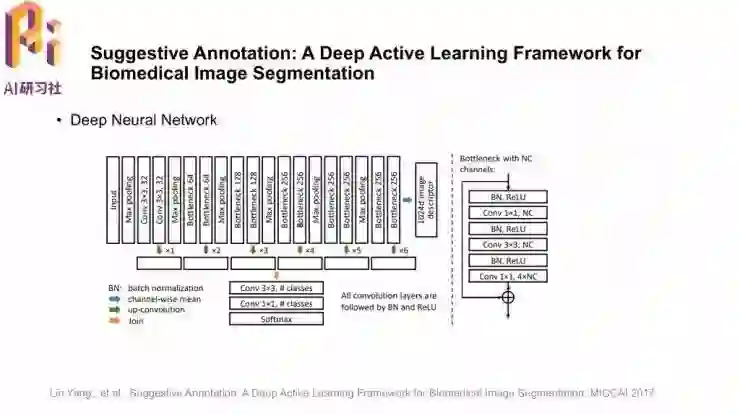
模型结构沿用了陈浩博士团队发表在CVPR2016的DCNN,并且加入了残差连接。模型还抽取了1024维的特征向量作为图像的外观描述,用来在不同图像之间做对比、找到有代表性的样本。

刚才提到要找不确定性和有代表性,“有代表性”实际评估的指标就是图像的相似度。上图中,a图是原始样本,b图是FCNN输出的分割后feature map,c图是图像中不同特征预测结果的不确定性,d图中就显示出不确定性和预测的准确率是有关系的,越高的不确定性就对应越低的准确率。下面的一排图像就是根据1024维的特征向量找到的相似图像。
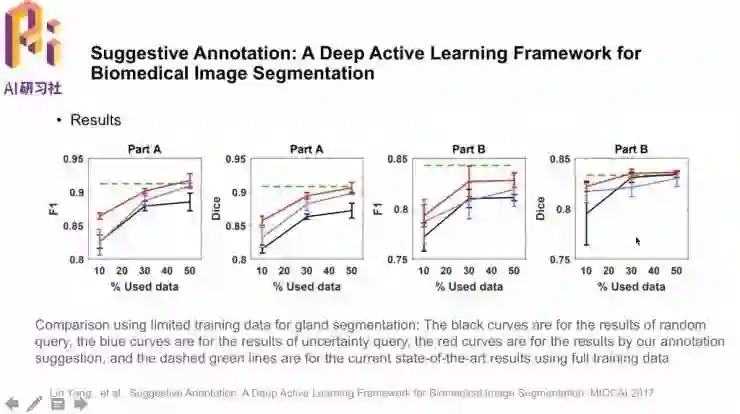
模型的实验结果如图,几张图中F1分数表示检测到腺体的准确率,Dice指分割的准确率。Part A、B是当时比赛时的两个数据集。
图中黑线指不计算不确定性和相似性,随机抽取样本训练的基准组;蓝线是仅用不确定性抽取样本;红线是不确定性+有代表性的样本抽取方法;绿色虚线是用所有数据训练模型之后的结果。可以看到红线收敛得最快,而且只用50%的训练数据就可以接近甚至超过绿线。这就说明了主动选取样本、引导模型训练的方法在节省成本和收敛速度方面的有效性。

第三篇是利用无标注数据的图像分割对抗性学习,对抗性学习也是近期的热门范式。
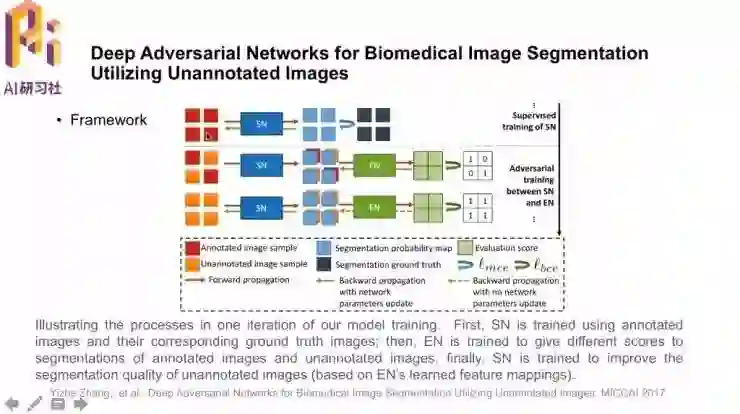
模型框架如图,对于有标注的数据,首先采用传统的有监督学习方式学习分割网络SN。然后加入无标注数据,当无标注和有标注数据同时存在时,通过反向传播和更新参数训练评估网络EN;在仅有无标注数据时,也做反向传播,但更新的是分割网络SN的参数。过程中,分割网络SN和评估网络EN对抗式地学习,而且也利用到了无标注的数据。

损失函数如图,这是一个基本的对抗学习损失函数,带有多类别的交叉熵和二分类的交叉熵。训练过程中分别训练EN和SN。蓝框中圈出的部分是等价的。
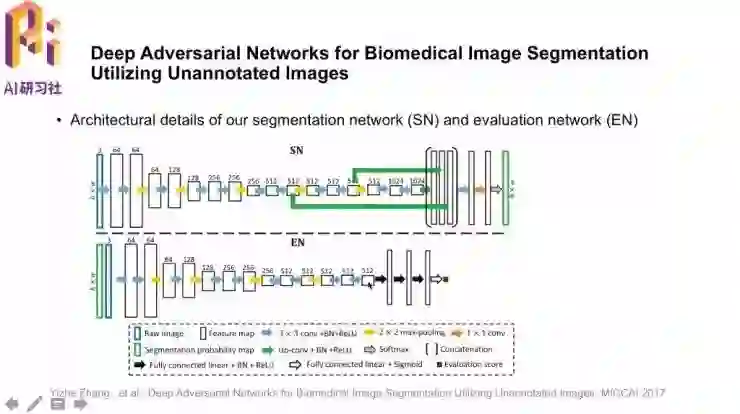
两个网络的具体结构如图。评估网络EN是一个传统的CNN网络;值得注意的是,它的输入不仅有原图像,也有分割结果的probability map,这是为了更好地利用输入信息;最后输出“是否是标注图像”的评估分值。

实验结果方面,图像分割需要分割到实例级别,可以看到这篇论文中提出的DAN达到了很好的结果,检测准确率F1、分割准确率Dice、形状相似性Hausdorff距离(越小越好)都有不错的表现。

第四篇文章也是用GAN做的图像合成。
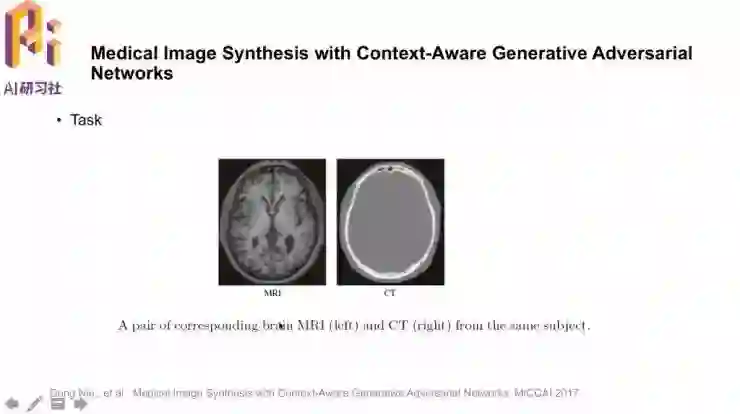
「Medical Image Synthesis with Context-Aware Generative Adversial Networks」。研究的任务就是用MRI图像生成对应的CT图像,这样做的是可行的,因为图像中有一些信息是共享的;要这样做的原因是,用MRI图像合成CT图像,就可以避免做CT时的辐射。
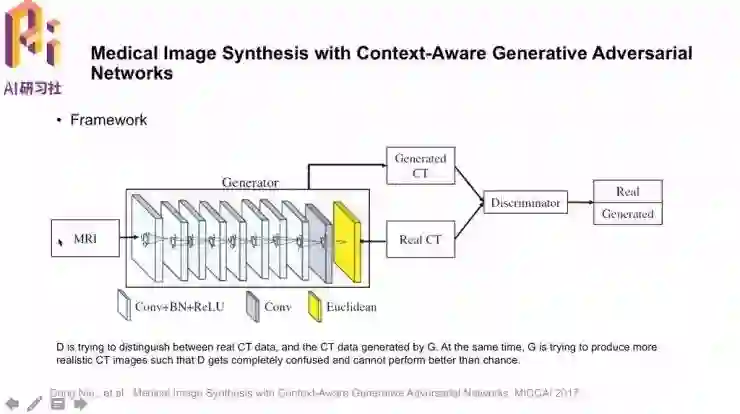
网络结构如图,与前面不同的是,生成器这时的输出就是生成的CT图像。和一般的GAN一样,鉴别器要尝试区分生成的CT图像和真实的CT图像,引导生成器生成越来越真实的CT图像。

G的损失中,除了对抗鉴别器的一项,当然也要包含“与ground truth接近”的一项;作者还加了一项Image gradient difference loss减小梯度的变化范围。
作者还提出了一个重要思想auto-context model(图中ACM),用一系列分类器利用上下文信息,把原始图像和第一个分类器的分类结果联合作为第二个分类器的输入,这样就有一个精细调整的过程。
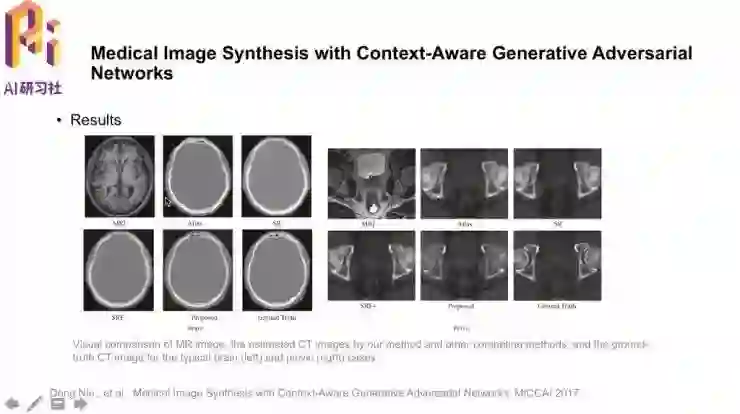
可以直观看到,模型的结果还是不错的。
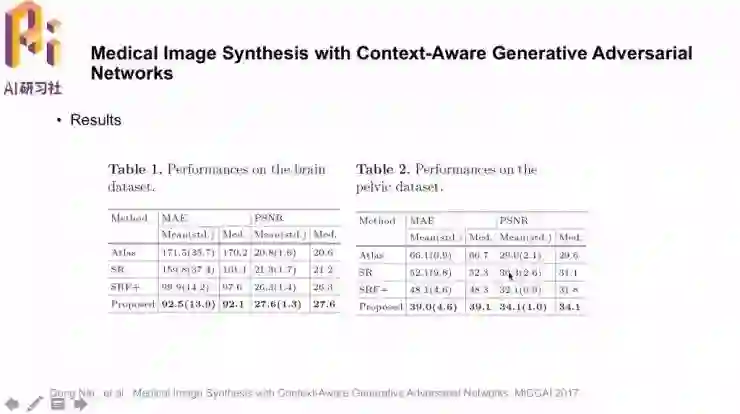
客观数据方面,平均错误值MAE(越低越好)和信噪比PSNR(越高越好)都取得了不错的结果

下一篇是体积数据的分割。

其中用到的DenseNet结构也是今年提出的新网络结构,比之前的ResNet有更密集的连接。这种网络结构的好处在于,1,每一层都能直接接收到指导信息,也就是隐式的“深度监督”;2,特征有很高的复用程度;3,能够降低feature map对应参数的数目。
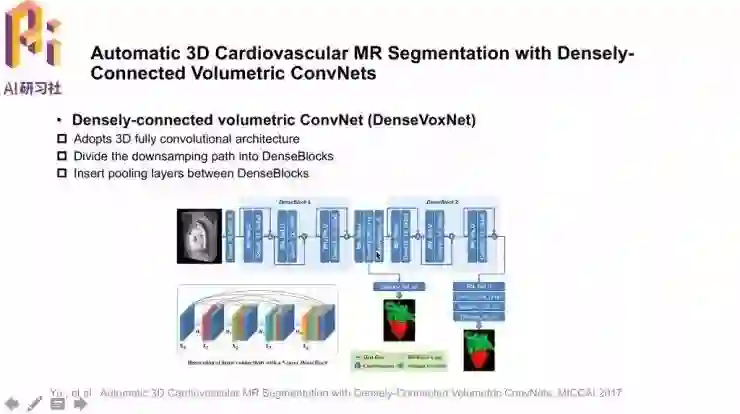
这篇论文「Automatic 3D Cardiovascular MR Segmentation with Densely-Connected Volumetric ConvNets」也就来自陈浩博士团队,任务目标是全心脏的三维体积分割,采用了三维全卷积神经网络,并且把下采样的路径分成了不同的DenseBlock块,在不同的DenseBlock中增加池化层增大感受野。
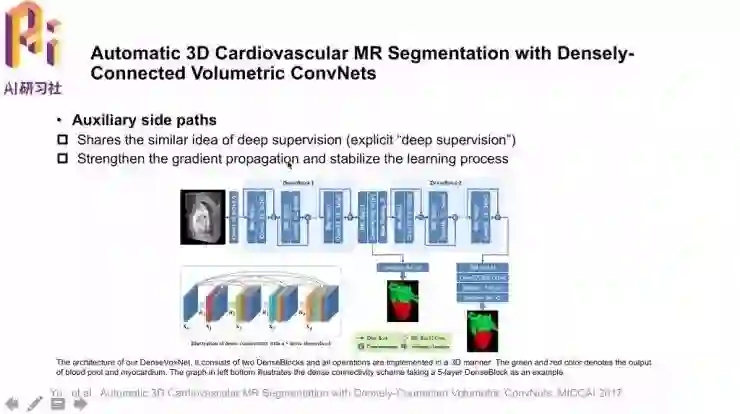
模型中还带有辅助侧路径,是一种显式的梯度传播增强方法。

结果方面,分割上取得了不错的结果

不同的网络间比较,DenseVoxNet用更少的参数数量(也带来了更快的训练速度)取得了更好的数据。

前面的论文中都是基于单模态的数据,这篇「Deep Correlation Learning for Survival Prediction from Multi-modality Data」就是多模态的深度相关学习。
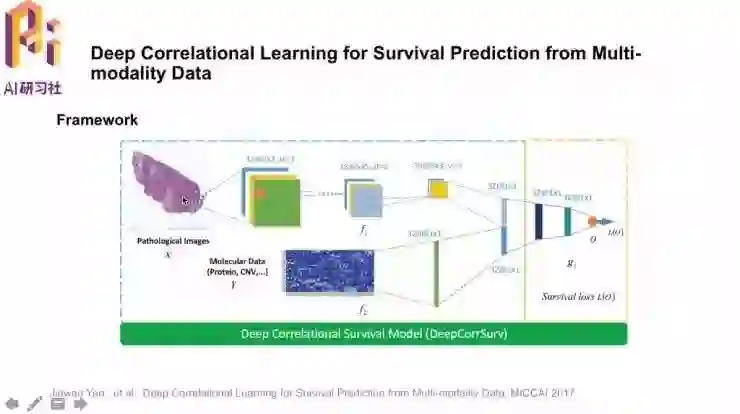
网络中有病理图像的数据输入,也有蛋白质、基因等多模态数据,特征联合之后形成输出。

但其实在常见的网络结构之后也有新的做法,第一个是用关联耦合系数提高数据的关联性,更多利用共有的信息;不过这不一定会对最终目标带来提高。然后针对论文中具体研究的生存时间问题,又设计了一个损失函数做精细调节。这样就用无监督方法挖掘相关信息,再用有监督学习改进。
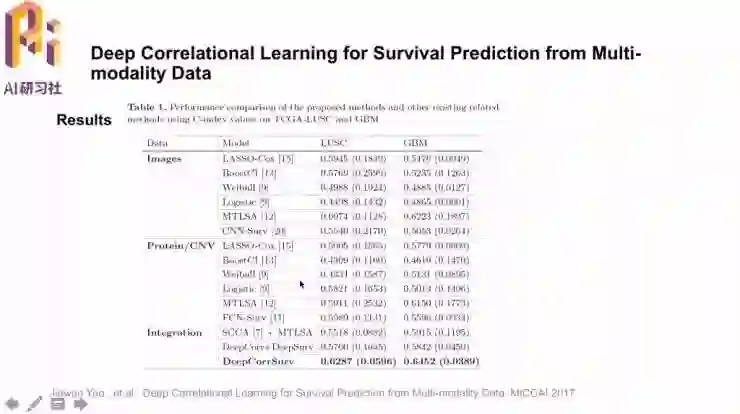
从结果中可以看到单独依靠图像数据和单独依靠蛋白质/CNV数据的预测方法,结果都不太高。结合起来之后,可以达到最高的结果。

还有一个方向是,人体器官的形状是比较固定的,那么就带有固定形状的先验知识进行深度学习。

这个方向里要介绍的两篇论文中的第一篇用到PCA,经过主成分分析后,数据点都可以由主成分的线性组合得到。这里的U就存储了基本形状的表征。
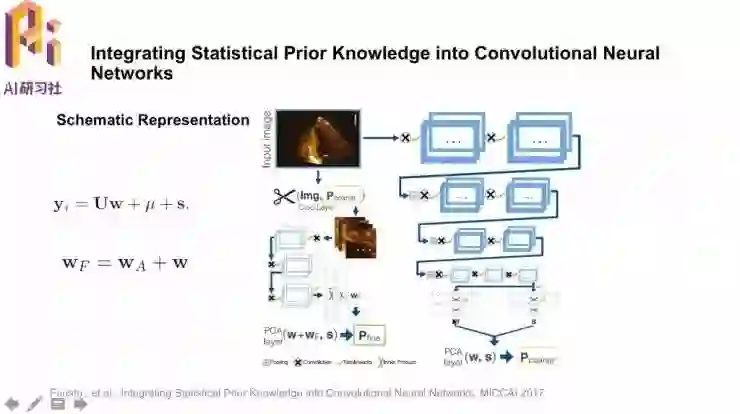
这篇论文中就利用了这一点,模型最后的PCA层中计算权重w和位移s,以Uw+μ+s作为任一数据点的表征。最后再降低yi的预测和ground truth之间的损失,从而得到大致的形状,剪切出更精细的形状进行堆积,得到更精细的结构。
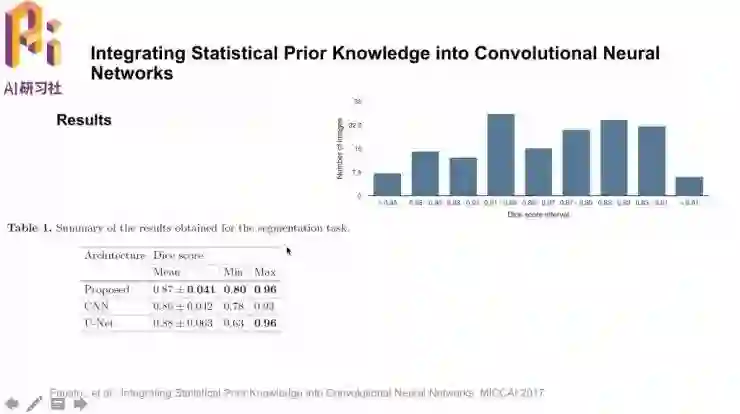
结果方面,首先做了图像分割任务,与CNN、U-Net取得了相当的均值,而最大值和最小值都是领先的;右侧的分布图中也可以看到结果比较鲁棒。另一个测试是点的定位任务,误差距离也更小。
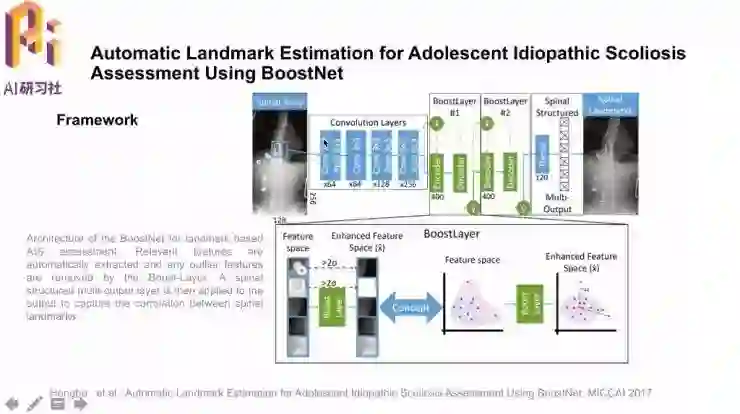
另一篇论文也是研究点的定位,在影像中找关键点。文章中研究的具体问题是脊柱侧弯的关键点检测。

输入X光图像,经过卷积层后,BoostLayer的作用是去除大于两倍标准差σ的偏离值,再经过带有脊椎形状约束的Spinal Structured层之后,就可以输出关键点的定位结果。
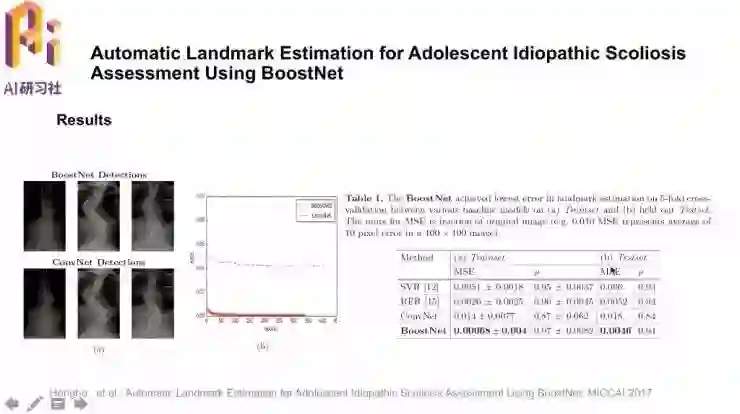
结果方面,论文所提的方法很好地抓取到了脊柱的形状,包括侧弯/病变的情况;传统CNN对有病变的情况就处理得差一些。量化结果方面也取得了很低的错误率。

陈浩博士还分享了一个好消息,他们团队的论文「3D deeply supervised network for automated segmentation of volumetric medical images」就拿下了MIA-MICCAI 2017的最佳论文奖,其中也用到了深度监督的思想,在不同的任务(肝脏或者心脏分割)中取得了不错的效果。
结语

论文分享后,陈浩博士根据自己的研究经验总结道:
首先数据是非常重要的,毕竟获取数据的代价是非常高的;
有一些结合问题的好的先验知识和有深度的想法也对研究有所帮助;
这次在MICCAI,陈浩博士也观察到,深度学习不仅在计算机视觉领域火热,在医学图像计算中也很火,不过想要从实验室走到临床的话,解释性仍然是一大问题;
深度学习对计算能力的要求也非常高;
病理全切片有巨大的数据量,如何利用计算平台、算法对其进行分析也是一个重要课题;
图像的语意分割问题上虽然取得了很大进步,但是否已经可以认为解决了这个问题了、临床上是否需要这样的分割还需要思考;
以及,在算法以及数据集的制约下,模型的泛化性往往还是较差的,这也是应用到实际医疗诊断中还需要解决的问题。

陈浩博士分享了几张在魁北克参加MICCAI时的照片
也欢迎大家参加在西班牙召开的MICCAI 2018和在香港召开的MICCAI 2019和IPMI(Information Processing in Medical Image)2019。

最后陈浩博士简单介绍了一下他们的实验室,在王平安教授带领下,现在有二三十位PhD共同在做医学影像分析和机器学习方面的研究。陈浩博士本人也是在今年年初创立了视见医疗科技,获得了几轮融资后也在招聘全职和实习生,欢迎发简历给他们,共同在人工智能医疗领域中做一些有意思的、能对世界产生影响的事情。
本文由 AI 科技评论整理,观看完整视频请进入课程回放页面 http://www.mooc.ai/open/course/230。更多学术消息、人工智能相关新闻报道、更多专家学者公开课,请继续关注 AI 科技评论。
————— 给爱学习的你的福利 —————
AI慕课学院《机器学习算法与实战基础入门班》,
日本名古屋大学博士陈安宁老师亲授,
帮助对机器学习感兴趣的同学快速入门机器学习,
零开始讲解机器学习知识,算法理论+案例实训,
层层递进,直通机器学习的本质及其应用!
详细了解点击文末阅读原文

————————————————————