新一代端侧声音过滤方案:VoiceFilter-Lite
文 / Quan Wang,Google Research 软件工程师
语音辅助技术依靠精准语音识别来确保对特定用户的响应能力,让用户可以通过语音命令与设备进行交互。但是在多数真实世界案例中,这类技术的输入往往包含重叠语音,为许多语音识别算法带来巨大挑战。我们在 2018 年发布了 VoiceFilter 系统,利用 Google 的 Voice Match 功能,让人们通过注册个人的声音更好地实现与辅助技术的个性化交互。
VoiceFilter 系统
https://arxiv.org/abs/1810.04826Voice Match
https://blog.google/products/assistant/tomato-tomahto-google-home-now-supports-multiple-users/注册个人声音
https://www.blog.google/products/assistant/more-ways-fine-tune-google-assistant-you/
虽然 VoiceFilter 方式非常成功,实现了比传统方式更好的信源失真比 (SDR),但高效的设备端流式传输语音识别还需要解决模型体积、CPU 和内存限制以及电池用量考量和延迟最小化等限制。
在“VoiceFilter-Lite: Streaming Targeted Voice Separation for On-Device Speech Recognition”,我们提出了用于设备端的新版 VoiceFilter,支持利用选定讲话者的注册语音,显著改善重叠语音中的语音识别。重要的是,此模型可与现有设备端语音识别应用轻松集成,让用户在极度嘈杂并且缺少互联网连接的条件下也能使用语音辅助功能。我们的实验表明,一个 2.2MB 的 VoiceFilter-Lite 模型可将重叠语音的词错误率 (Word Error Rate, WER) 降低 25.1%。
VoiceFilter-Lite:Streaming Targeted Voice Separation for On-Device Speech Recognition
https://arxiv.org/abs/2009.04323新版 VoiceFilter
https://arxiv.org/abs/1810.04826
改善设备端语音识别
虽然在将目标讲话者的语音信号与其他重叠信号源分离方面,原始 VoiceFilter 系统非常成功,但其模型大小、计算成本和延迟对于移动设备端的语音识别并不可行。
移动设备端的语音识别
https://arxiv.org/abs/1811.06621
新版 VoiceFilter-Lite 专为设备端应用精心设计。VoiceFilter-Lite 不处理音频波形,而是采用与语音识别模型完全相同的输入特征(堆叠的对数梅尔滤波器组),通过实时滤除不属于目标讲话者的成分以直接增强这些特征。结合网络拓扑的多项优化,运行时所涉及的算子大幅减少。使用 TensorFlow Lite 库对神经网络进行量化后,模型大小仅为 2.2 MB,适合大多数设备端应用。
VoiceFilter-Lite
https://arxiv.org/abs/2009.04323TensorFlow Lite
https://tensorflow.google.cn/lite
为了训练 VoiceFilter-Lite 模型,噪声语音的滤波器组与代表目标讲话者身份的嵌入向量(即 d-vector)一起作为输入馈送至网络。网络预测一个掩码,该掩码与输入逐元素相乘以生成增强的滤波器组。通过定义的损失函数在训练时消化增强后的滤波器组与干净语音的滤波器组之间的误差。
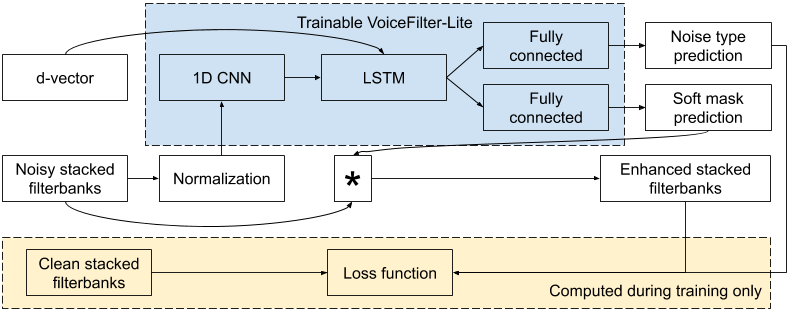
VoiceFilter-Lite 系统的模型架构
VoiceFilter-Lite 是一个即插即用模型,如果讲话者没有注册语音,那么实现该模型的应用就可以轻松绕过。这也意味着语音识别模型和 VoiceFilter-Lite 模型可以分别训练和更新,从而大幅减少部署过程中的工程复杂性。
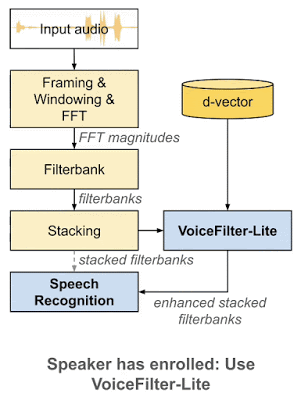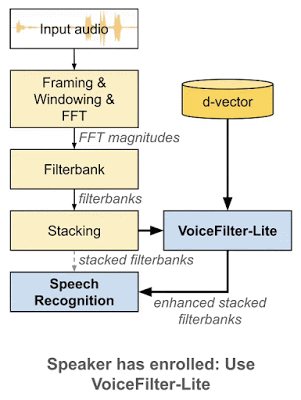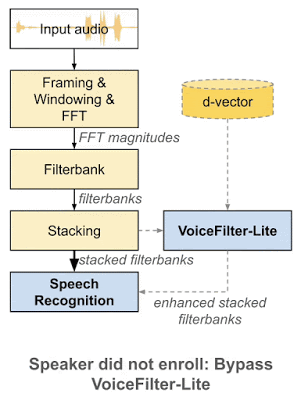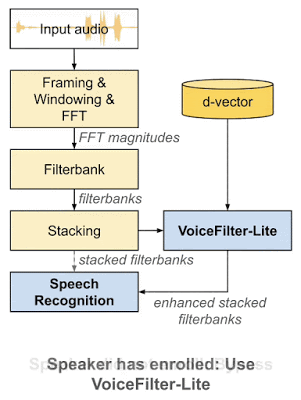
作为即插即用模型,如果讲话者未注册语音,则可以轻松绕过 VoiceFilter-Lite
解决抑制过度问题
使用语音分离模型改善语音识别时,可能会发生两类错误:抑制不足,即模型未能滤除信号中的噪声成分;抑制过度,即模型未能保留有用信号,导致某些词从识别的文本中剔除。由于现代语音识别模型通常使用大量增强数据(如房间仿真和 SpecAugment)训练,因此对抑制不足较为鲁棒,却也导致了严重的抑制过度。
SpecAugment
https://ai.googleblog.com/2019/04/specaugment-new-data-augmentation.html
VoiceFilter-Lite 以两种全新方式解决抑制过度问题。第一,它在训练过程中使用了非对称损失函数,因此模型对抑制过度的耐受性要低于抑制不足。第二,它会在运行时预测噪声的类型,并根据预测结果自适应地调整抑制强度。
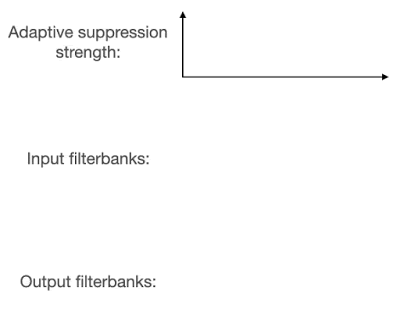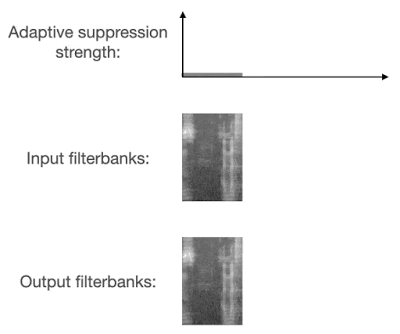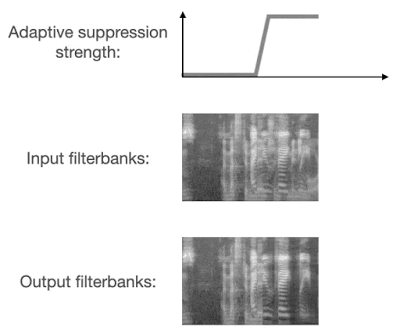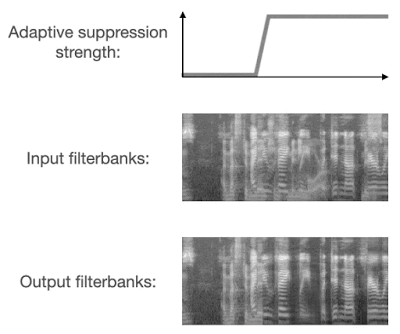
检测到重叠语音时,VoiceFilter-Lite 会自适应地应用更强的抑制强度
在其他场景,如安静环境或各种噪声环境下的单人语音,VoiceFilter-Lite 模型通过这两种方式仍然保持了出色的流式传输语音识别性能,同时明显改善了重叠语音。通过实验,我们观察到在将 2.2MB 的 VoiceFilter-Lite 模型应用于加法重叠语音后,词错误率降低了 25.1%。对于更具挑战性的混响重叠语音,即模拟智能家居扬声器等远场设备,我们也观察到 VoiceFilter-Lite 可使词错误率降低 14.7%。
未来工作
虽然 VoiceFilter-Lite 已在多种设备端语音应用中表现出广阔前景,但我们也在探索其他方向,让 VoiceFilter-Lite 更加实用。首先,目前模型仅使用英语语音进行训练和评估。我们希望采用相同的技术改善更多语言的语音识别。其次,我们想在 VoiceFilter-Lite 的训练过程中直接优化语音识别损失,这有可能超越重叠语音的范围并进一步改善语音识别。
致谢
本文所述研究由 Google 内部多个团队共同完成。贡献者包括 Quan Wang、Ignacio Lopez Moreno、Mert Saglam、Kevin Wilson、Alan Chiao、Renjie Liu、Yanzhang He、Wei Li、Jason Pelecanos、Philip Chao、Sinan Akay、John Han、Stephen Wu、Hannah Muckenhirn、Ye Jia、Zelin Wu、Yiteng Huang、Marily Nika、Jaclyn Konzelmann、Nino Tasca 和 Alexander Gruenstein。
更多 AI 相关阅读:







