无需建模:谷歌SpecAugment即可获得最先进的语音识别性能
谷歌AI研究人员现在将计算机视觉运用于声波视觉,从而在不使用语言模型的情况下获得最先进的语音识别系统性能。研究人员表示,SpecAugment方法不需要额外数据,在不改动底层语言模型的情况下就可以使用。
谷歌的AI实习生Daniel S. Park和研究科学家William Chan在今天的一篇博文中称:“我们研究的一个意想不到的结果是,甚至在不借助语言模型的情况下,使用SpecAugment训练的模型其性能超过所有之前的方法。虽然我们的网络仍可以从添加语言模型中受益,但我们的结果令人鼓舞,因为它表明可以在不借助语言模型的情况下,训练可用于实际用途的网络。”
SpecAugment的工作原理一部分如下,将视觉分析数据增强应用于语音的视觉表示:声谱图。SpecAugment应用于聆听、关注和拼写(LAS)网络以处理语音识别任务,结果处理LibriSpeech960h(该数据集含有约1000小时长的英语口语)任务时获得2.6%的单词错误率(WER),处理Switchboard 300h(该数据集含有260小时长的英语通话)任务时获得6.8%的单词错误率。
自动语音识别(ASR)系统将语音翻译成文本用于对话式AI,比如Home智能音箱中的谷歌助手或使用Gboard的口述工具处理电子邮件或短信的安卓智能手机。据普华永道2018年的一项调查显示,降低单词错误率是影响对话式AI采用率的一个关键因素。
比如说,近年来语言模型和计算能力方面的进步共同降低了单词错误率,使得语音输入比键盘输入来得更快。
该成果详见于发表在arXiv上的论文《SpecAugment:一种用于语音自动识别的简单数据增强方法》。
持续改进是Alexa等智能助手的制造商经常号称的优点之一,谷歌和亚马逊近几个月发表了详细介绍用来加快技术变革的方法的多篇论文。
亚马逊今天宣布,隔离背景噪声有望使Alexa的语音识别准确率提高15%,而今年晚些时候半监督式训练方法将用于改善Alexa语音识别,预计有望将准确率提高逾20%。
以下为谷歌官方博客对论文的解读,作者AI实习生Daniel S. Park和研究科学家William Chan,经云头条编译供各位参考:
自动语音识别(ASR)是指将音频输入内容转录成文本的过程,从深度神经网络的持续发展中获益匪浅。因此,ASR已经在许多现代设备和产品中无处不在,比如谷歌助手、谷歌Home和YouTube。然而,开发基于深度学习的ASR系统方面仍存在着许多重大挑战。其中的一个挑战是:拥有许多参数的ASR模型往往过拟合训练数据,训练集不够全面广泛时就很难推广到未见过的数据。
在没有足够数量的训练数据这种情况下,可以通过数据增强(data augmentation)方法增加现有数据的有效大小,这有助于大大提高图像分类领域中深度网络的性能。以语音识别为例,数据增强传统上是指以某种方式(比如通过加快或减慢速度),使用来训练的音频波形变形,或者增加背景噪声。这么做的效果是使数据集实际上变庞大,因为单个输入的多个增强版本在训练过程中被馈送到网络中,还通过迫使网络学习相关特征来帮助网络变得稳健。然而,增强音频输入的现有传统方法带来了额外的计算成本,有时还需要额外的数据。
我们在最近的论文《SpecAugment:一种用于语音自动识别的简单数据增强方法》(https://arxiv.org/abs/1904.08779)中,采用了一种新的方法来增强音频数据,将其视作视觉问题而非音频问题。SpecAugment将增强策略直接应用于音频声谱图(即波形的图像表示),而不是像传统做法那样增强输入音频波形。这种方法简单,运用起来计算成本低,而且不需要额外的数据。它在提高ASR网络的性能方面也异常高效,在处理ASR任务LibriSpeech 960h和Switchboard 300h时显示出最先进的性能。
SpecAugment
在传统的ASR中,音频波形在作为网络的训练数据被输入之前通常被编码成视觉表示,比如声谱图。训练数据的增强通常应用于波形音频,之后转换成声谱图,以便每次迭代后,必须生成新的声谱图。在我们的方法中,我们研究的是增强声谱图本身的方法,而不是增强波形数据的方法。由于增强直接应用于网络的输入特征,因此可以在训练过程中在线运行,而不显著影响训练速度。
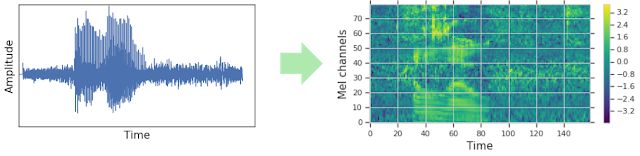
在被馈送到网络之前,波形通常被转换成视觉表示(在我们的例子中是对数梅尔声谱图;详见该文的步骤1到步骤3)
SpecAugment改动声谱图的方法是,在时间方向上使声谱图变形,屏蔽连续频道块,并屏蔽话语块。已经选择这些增强方法来帮助网络稳健,可以防御时间方向上的变形、频率信息的部分丢失以及小段语音输入的部分丢失。下面显示了这种增强策略的示例。
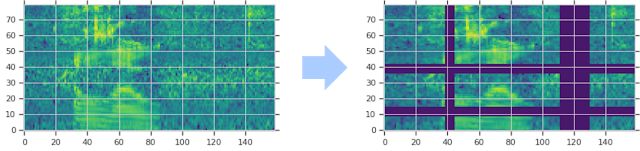
增强对数梅尔声谱图的方法是,在时间方向上变形,屏蔽(多个)连续时步块(垂直屏蔽)和梅尔频道(横向屏蔽)。声谱图的屏蔽部分以紫色显示以示强调
为了测试SpecAugment,我们用LibriSpeech数据集进行了一番实验:我们拿来了三个聆听、关注和拼写(LAS)网络,这是常用于语音识别的端到端网络,并比较了使用增强训练的网络和不使用增强训练的网络之间的测试性能。ASR网络的性能按照网络生成的转录对照目标转录的单词错误率(WER)来加以测量。在这里,所有超参数都保持不变,只有馈入网络的数据被改变。我们发现,SpecAugment可提高网络性能,不用对网络或训练参数进行任何额外的调整。
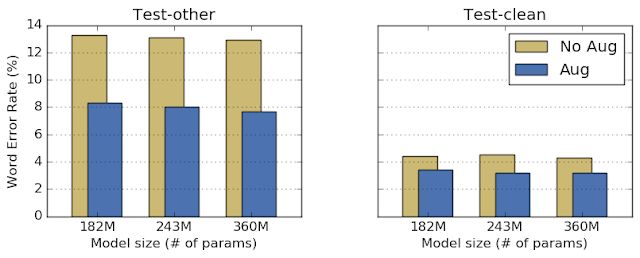
使用增强和不用增强的LibriSpeech测试集上的网络性能。LibriSpeech测试集分成两部分:test-clean和test-other,后者包含噪声较大的音频数据。
更重要的是,SpecAugment通过为网络提供有意破坏的数据来防止网络过拟合。举例来说,下面我们演示了训练集和开发(dev)集的WER如何通过使用增强和不用增强的训练加以改进。我们发现,在不用增强的情况下,网络在训练集上获得了近乎完美的性能,而在干净的开发集和有噪声的开发集上都性能欠佳。另一方面,在使用增强的情况下,网络在训练集上很难获得一样好的性能,但在干净的开发集上实际上有更好的性能,在有噪声的开发集上表现出类似的性能。这表明网络不再过拟合训练数据;提高训练性能将带来更好的测试性能。
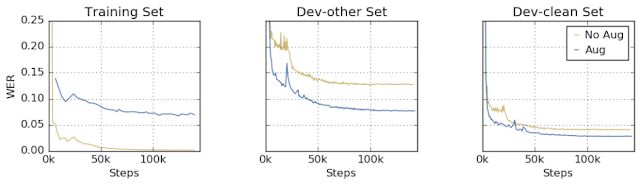
在使用增强和不用增强的情况下,训练集、干净的(dev-clean)开发集和有噪声的(dev-other)开发集的性能。
最先进的结果
我们现在可以专注于提高训练性能,这可以通过使网络变大、从而为网络增添更多容量来实现。再辅以增加训练时间,我们就能够在处理LibriSpeech 960h和Switchboard 300h这两项任务时获得最先进(SOTA)的结果。

LibriSpeech 960h和Switchboard 300h这两项任务的最先进结果的单词错误率(%)。两个任务的测试集都有干净的(clean/Switchboard)子集和有噪声的(other/CallHome)子集。以前的SOTA结果取自Li等人(2019年,https://arxiv.org/pdf/1904.03288.pdf)、Yang等人(2018年,https://arxiv.org/pdf/1810.11352.pdf)和Zeyer等人(2018年,https://arxiv.org/pdf/1805.03294.pdf)。
我们使用的简单增强方法非常高效――我们能够大幅改进端到端LAS网络的性能,远超过传统ASR模型的性能,传统ASR模型历来在较小的学术数据集(比如LibriSpeech或Switchboard)上的表现好得多。
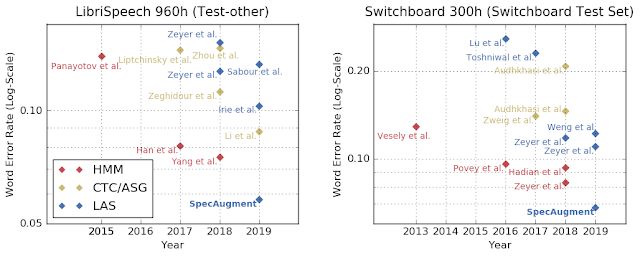
各种类型的网络在处理LibriSpeech和Switchboard任务的性能。随着时间的推移,LAS模型的性能与经典模型(比如HMM)及其他端到端模型(比如CTC / ASG)的性能相当。
语言模型
语言模型(LM)在更庞大的纯文本数据上进行训练,它在通过利用从文本中学习的信息改进ASR网络的性能方面发挥了重要作用。然而,LM通常需要与ASR网络分开来训练,可能在内存中显得很庞大,因而难以装在手机等设备中。我们研究的一个意想不到的结果是,使用SpecAugment训练的模型甚至在不借助语言模型的情况下性能超过所有之前的方法。虽然我们的网络仍可以从添加LM中受益,但我们的结果令人鼓舞,因为它表明可以在不借助LM的情况下训练可用于实际用途的网络。
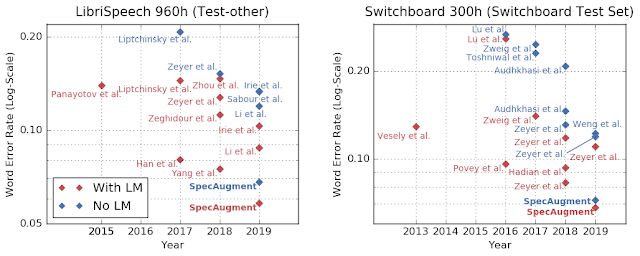
使用和不用LM的LibriSpeech和Switchboard任务的单词错误率。即使在加入语言模型之前,SpecAugment的性能也胜过以前最先进的方法。
过去ASR方面的工作大多专注于寻找更好的网络来加以训练。我们的工作表明,寻找更好的方法来训练网络是大有前景的另一个研究方向。
论文:

完整论文可点击“阅读原文“下载查看~~





