如何用AI技术治理假新闻泛滥?看ASU大学舒凯等学者这篇《挖掘虚假信息和假新闻:概念、方法和最新进展》研究综述
【导读】互联网的发展是一把双刃剑,一方面让人们可以很便捷地获取和分享信息,另一方面也滋生了假信息泛滥,造成很多严重的后果。如何利用人工智能机器学习数据挖掘技术治理缓解虚假信息的影响?是整个研究界关心的话题。最近,亚利桑那州立大学(Arizona State University)的Kai Shu、Huan Liu和宾夕法尼亚州立大学的Suhang Wang和Dongwon Lee共同撰写关于虚假信息和假新闻检测的概述进展《Mining Disinformation and Fake News: Concepts, Methods, and Recent Advancements》,详述了虚假信息、错误信息、恶意信息的概念的方法体系,值得参阅。

地址:
https://www.zhuanzhi.ai/paper/60a812267d38d28ed4d4e33f288a619e
https://www.arxiv-vanity.com/papers/2001.00623/
摘要
近年来,由于假新闻等虚假信息的爆炸性增长,尤其是在社交媒体上,已经成为一种全球现象。虚假信息和假新闻的广泛传播会造成有害的社会影响。尽管近年来在发现虚假信息和假新闻方面取得了进展,但由于其复杂性、多样性、多模态性和事实核查或注释的成本,它仍然是非常具有挑战性。本章的目的是通过: (1) 介绍社交媒体上信息混乱的类型,并研究它们之间的差异和联系,为理解这些挑战和进步铺平道路; (2) 描述重要的和新兴的任务,以打击虚假信息的表征、检测和归因; (3) 讨论了利用有限的标记数据检测虚假信息的弱监督方法。然后,我们提供了本书章节的概述,这些章节代表了三个相关部分的最新进展: (一) 用户参与信息传播的混乱; (二) 发现和减少虚假信息的技术; (三) 伦理学、区块链、clickbaits等趋势问题。我们希望这本书能成为研究人员、实践者和学生了解问题和挑战的一个方便的入口,为他们的特定需求学习最先进的解决方案,并快速识别他们领域的新研究问题。
概要
社交媒体已经成为一种流行的信息搜索和新闻消费手段。由于通过社交媒体提供和传播在线新闻的门槛低、速度快,大量的虚假信息如假新闻变得泛滥。在美国,那些故意提供虚假信息的新闻文章是出于各种各样的目的而在网上发布的,其目的从经济利益到政治利益不等。我们以假新闻为例。虚假新闻的广泛传播会对个人和社会产生严重的负面影响。首先,假新闻会影响读者对新闻生态系统的信心。例如,在很多情况下,在2016年美国总统大选期间,最受欢迎的假新闻在Facebook上比主流新闻更受欢迎和广泛传播。其次,假新闻故意说服消费者接受有偏见或错误的信仰,以获取政治或经济利益。例如,2013年,美联社(AP)在推特上发布消息称巴拉克·奥巴马(Barack Obama)受伤,导致1300亿美元的股票价值在短短几分钟内蒸发殆尽。美联社称其推特账户遭到黑客攻击。第三,假新闻改变了人们解读和回应真实新闻的方式,阻碍了他们分辨真假的能力。因此,了解虚假新闻的传播方式,开发有效、准确的假新闻检测和干预的数据挖掘技术,缓解虚假新闻传播的负面影响至关重要。
这本书的目的是把研究人员,从业人员和社会媒体供应商聚集在一起,以了解传播,改善检测和减少虚假信息和假新闻在社会媒体。接下来,我们从不同类型的信息无序开始。
1 信息失序 INFORMATION DISORDER
信息失序是近年来备受关注的一个重要问题。社交媒体的开放性和匿名性为用户分享和交流信息提供了便利,但也使其容易受到不法活动的侵害。虽然新闻学研究了虚假信息和虚假信息的传播,但是社交网络平台的开放性,加上自动化的潜力,使得信息的无序迅速传播到大量的人群中,这带来了前所未有的挑战。一般来说,信息无序可以分为三种主要类型: 虚假信息、错误信息和恶意信息[1]。虚假信息是故意散布以误导和/或欺骗的虚假或不准确的信息。错误信息是指一个人没有意识到它是假的或误导的,而分享的虚假内容。恶意信息是指为了造成伤害而共享的真实信息。此外,还有一些其他相关类型的信息混乱[2,3]: 谣言是一个故事在人与人之间传播,其中的真相是未经核实或可疑的。谣言通常出现在模棱两可或具有威胁性的事件中。当谣言被证明是虚假的,它就是一种虚假信息; 都市传奇是一个虚构的故事,包含了与当地流行文化相关的主题。都市传奇的陈述和故事通常是假的。都市传奇通常描述不寻常的、幽默的或可怕的事件; 垃圾邮件是发送给大量收件人的不请自来的信息,包含不相关或不恰当的信息,是不需要的。
虚假或误导性信息的传播往往具有动态性,导致不同类型信息之间的无序交换。一方面,虚假信息会变成错误信息。例如,虚假信息制造者可以在社交媒体平台上故意发布虚假信息。看到这些信息的人可能不知道这些信息是假的,并在他们的社区中使用他们自己的框架来分享这些信息。另一方面,虚假信息也可以转化为虚假信息。例如,一则讽刺新闻可能被有意地断章取义,误导消费者。虚假信息的一个典型例子是假新闻。我们用它作为一个具体的案例研究来说明挖掘虚假信息的问题和挑战。
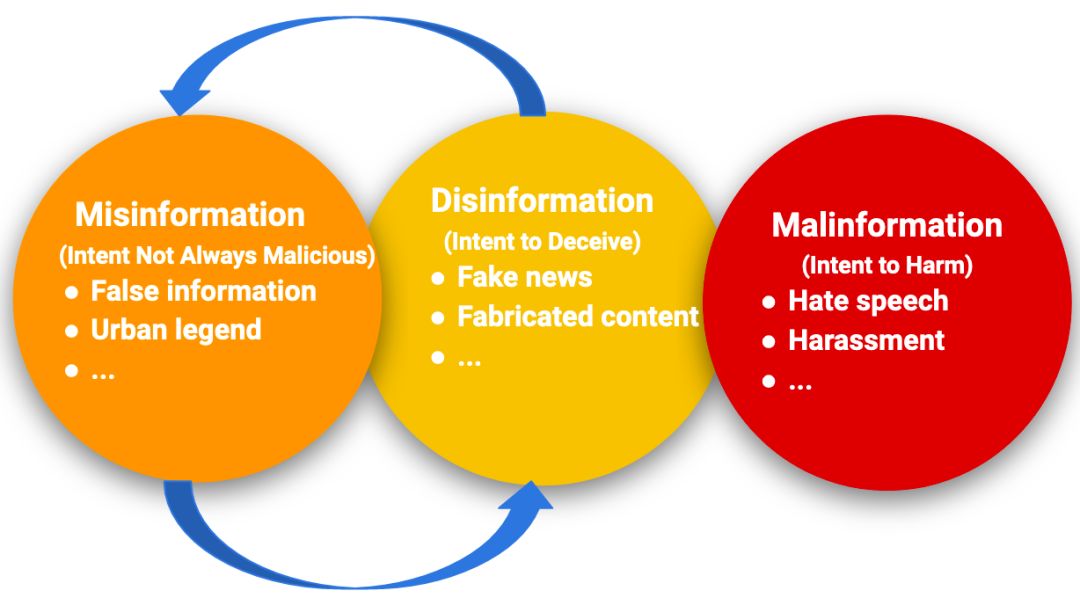
图1: 虚假信息、错误信息和恶意信息之间的关系,以及具有代表性的例子。此外,虚假信息和错误信息可以相互转化。
信息扭曲(Information Disorder)的三个类型:
为了理解和研究信息生态系统的复杂性,我们需要一种共同的语言。目前对“假新闻”等简单化术语的依赖掩盖了重要的区别,它也过分关注“真实”与“虚假”,而信息扭曲则带有许多“误导”的影子。
Misinformation 错误信息(Falseness 虚假)
无意错误,如不准确的文字说明、日期、统计数据或翻译,或讽刺性内容被严肃对待。
Disinformation 虚假信息(Falseness 虚假、Intent to harm 有意伤害)
捏造或故意操纵的内容。故意制造阴谋论或谣言。
Malinformation 恶意信息(Intent to harm 有意伤害)
为个人或公司利益而不是公众利益而故意发布私人信息,如报复性的色情内容。故意改变真实内容的上下文、日期或时间。
1.1 假新闻是虚假信息的一个例子
在这一小节中,我们将展示如何通过社交媒体数据来识别、检测虚假信息(假新闻)并赋予其属性。假新闻通常指的是那些故意且可证实为虚假的、可能误导读者的新闻文章[4,5]。
对于特征描述,目标是了解信息是恶意的,有无害的意图,还是有其他深刻的特征。当人们创造和传播虚假信息时,他们通常有一个特定的目的或意图。例如,在欺骗的背后可能有许多意图,包括: (1) 说服人们支持个人、团体、想法或未来的行动; (2)说服他人反对个人、团体、思想或者未来的行为; (3)对某个人、团体、想法或未来的行动产生情绪反应(恐惧、愤怒或高兴),希望得到支持或反对; (4)教育(例如:,关于疫苗接种威胁);(5) 防止令人尴尬或者犯罪的行为被人相信; (6)夸大某事的严重性(例如,政府官员使用私人邮件); (7)混淆过去的事件和活动(例如:在美国,美国是真的登上了月球,还是只是在地球上的沙漠里?或(8)说明发现虚假信息对社交平台的重要性(如,伊丽莎白·沃伦和马克·扎克伯格争论)。在端到端模型中加入特征嵌入,如索赔和证据之间的因果关系,可以使用[6]来检测意图,如劝诱影响检测[7]。一旦我们确定了一篇欺骗性新闻文章背后的意图,我们就可以进一步了解这一意图的成功程度: 这一意图成功达到其预期目的的可能性有多大。我们可以考虑以社会理论为基础的病毒营销手段来帮助描述。社会心理学指出,社会影响(新闻文章的传播范围)和自我影响(用户已有的知识)是虚假信息传播的有效代理。来自社会和自身的更大影响会扭曲用户的感知和行为,使其相信一篇新闻文章,并无意中参与到其传播中。计算社会网络分析[9]可以用来研究社会影响如何影响个人的行为和/或信念暴露在虚假信息和假新闻。
当考虑整个新闻生态系统而不是个人消费模式时,社会动态就会出现,从而导致虚假信息的扩散。根据社交同质性理论,社交媒体用户倾向于追随志趣相投的朋友,从而获得新闻宣传他们现有的叙述,从而产生回音室效应。为了获得细粒度的分析,我们可以将传播网络按照层次结构进行处理,包括宏观层面的发布、转发和微观层面的回复[10],这表明信息层次传播网络中的结构和时间特征在虚假信息和真实新闻之间存在统计学差异。这可以为纯粹基于意图的视角提供特征描述的补充,例如放大虚假信息的优先级,这些虚假信息在与善意的意图共享后可能很快产生不良影响(例如,最初,幽默)。
检测的目标是在早期或通过可解释的因素有效地识别错误信息。由于假新闻试图在新闻内容中传播虚假信息,因此最直接的检测方法就是对新闻文章中主要内容的真实性进行检测,从而判断新闻的真实性。传统新闻媒体的假新闻检测主要依靠对新闻内容信息的挖掘。新闻内容可以有多种形式,如文本、图像、视频。研究探索了从单一或组合模式中学习特征的不同方法,并建立了机器学习模型来检测假新闻。除了与新闻文章内容直接相关的功能外,还可以从社交媒体平台上新闻消费的用户驱动的社交参与中衍生出额外的社交上下文功能。社会契约代表了新闻随时间的扩散过程,它为推断新闻文章的准确性提供了有用的辅助信息。一般来说,我们想要表现的社会媒体环境主要有三个方面:用户、生成的帖子和网络。首先,假新闻很可能由非人类账户(如社交机器人或电子人)创建和传播。因此,通过基于用户的特征捕获用户的个人信息和行为,可以为假新闻检测[11]提供有用的信息。第二,人们通过社交媒体上的帖子来表达他们对假新闻的情感或观点,比如怀疑的观点和耸人听闻的反应。因此,从帖子中提取基于帖子的特征,通过公众的反应来帮助发现潜在的假新闻是合理的。第三,用户在社交媒体上形成不同类型的兴趣、话题和关系网络。此外,假新闻传播过程往往形成一个回音室循环,突出了提取网络特征检测假新闻的价值。
假新闻通常包含多种形式的信息,包括文本、图像、视频等。因此,利用多模态信息来提高检测性能具有很大的潜力。首先,现有的工作侧重于提取语言特征,如用于二分类的词汇特征、词汇、情感和可读性,或者学习具有神经网络结构的神经语言特征,如卷积神经网络(CNNs)和递归神经网络(RNNs)[12]。其次,视觉线索主要从视觉统计特征、视觉内容特征和神经视觉特征[13]中提取。可视化统计特征表示附加到虚假/真实新闻片段的统计信息。视觉内容特征是描述图像内容的清晰度、连贯性、多样性等因素。神经视觉特征是通过神经网络(如CNNs)来学习的。此外,近年来从图像中提取视觉场景图谱以发现常识[14]的研究进展,极大地提高了从视觉内容中提取结构化场景图的能力。
对于归因attribution,目标是验证所谓的来源或提供者和相关的归因证据。社交媒体中的归属搜索是一个新的问题,因为社交媒体缺乏一个集中的权威或机制来存储和验证社交媒体数据的来源。从网络扩散的角度来看,种源识别就是寻找一组关键节点,使信息传播最大化。确定种源路径可以间接找到起源种源。信息的出处通常是未知的,对于社交媒体上的虚假信息和误传,这仍然是一个公开的问题。信息源路径描述了信息如何从源传播到沿途的其他节点,包括负责通过中介重新传输信息的节点。我们可以利用社会化的特性来追溯[15]的来源。基于度倾向和贴近倾向假设[16],离节点越近的节点,其有较高度中心性的节点越有可能是变送器。在此基础上,通过图优化的方法,估计出在给定的种源节点集合上的顶级发射机。我们计划开发新的算法,可以结合网络结构以外的信息,如节点属性和时间信息,以更好地发现源。
深度学习的成功,尤其是深度生成模型,机器生成的文本可以成为一种新的虚假新闻,它流畅、易读、容易记住,这带来了新的归属来源。例如,通过对抗性训练,提出了SeqGAN[17]、MaliGAN[18]、LeakGAN[19]、MaskGAN[20]等语言生成模型,并提出了基于Transformer[21]的多任务学习无监督模型,如GPT-2[22]、Grover[23]等语言生成模型。一个重要的问题是考虑机器生成的合成文本,并提出解决方案来区分哪些模型用于生成这些文本。可以对不同文本生成算法的数据进行分类,探索决策边界。数据集可以从VAE、SeqGAN、TextGAN、MaliGAN、GPT-2、Grover等代表性语言生成模型中获取。此外,元学习还可以从少量的训练实例中预测新的文本生成源。此外,一些生成模型如:SentiGAN [24], Ctrl [25], PPLM[26],可以生成程式化的文本,对特定的风格进行编码,如:emotional, catchy。在预测模型中,消除伪相关是非常重要的。利用对抗式学习从合成文本中分离出风格因素,并开发具有恢复不同文本生成模型之间可转移特征能力的预测模型。
2 薄弱社会监督力度 THE POWER OF WEAK SOCIAL SUPERVISION
社交媒体让用户可以随时随地与任何人进行联系和互动,这也让研究人员可以用新的视角以前所未有的规模观察人类的行为。用户对新闻文章(包括在社交媒体上发布、评论或推荐新闻)等信息的参与,隐含着用户对新闻的判断,并可能成为虚假信息和假新闻检测的标签来源。
然而,与传统数据明显不同的是,社交媒体数据是大规模的、不完整的、嘈杂的、非结构化的,具有丰富的社会关系。这种新的(但较弱的)数据类型要求结合社会理论和统计数据挖掘技术的新的计算分析方法。由于社交媒体参与的性质,我们将这些信号称为弱社会监督(WSS)。在社会监督较弱的情况下,我们可以学习如何更有效地理解和发现虚假信息和假新闻,具有可解释性,在早期阶段等。一般来说,社交媒体参与主要有三个方面:用户、内容和关系(参见图2)。第二,用户通过发帖/评论来表达自己的观点和情绪。第三,用户通过各种社区在社交媒体上形成不同类型的关系。弱社会监督的目标是利用来自社交媒体的信号,获得对各种下游任务的弱监督。与弱监督类似,我们可以用弱标签和弱约束的形式来利用弱社会监督。
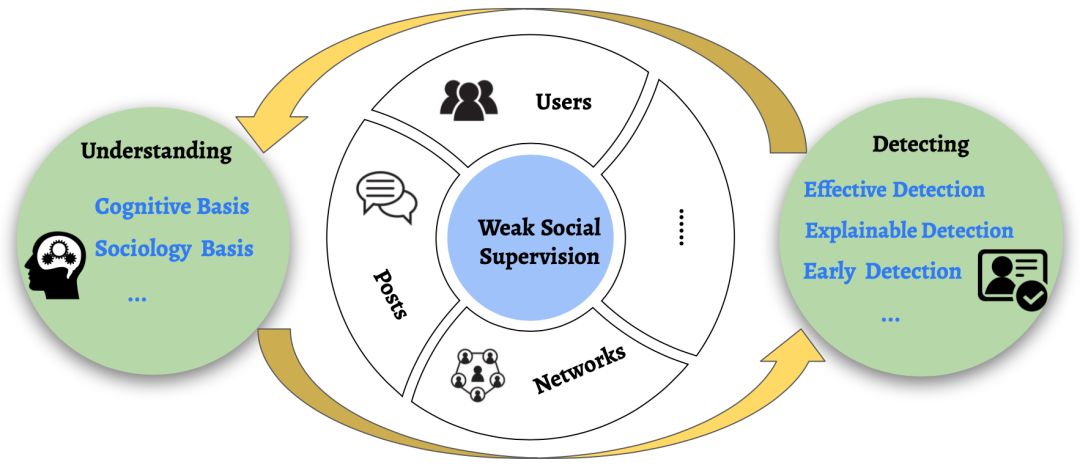
图2: 社会监督下学习理解和发现虚假信息和假新闻的示意图。
2.1 利用WSS理解虚假信息
人类天生就不善于区分错误信息和虚假信息。认知理论解释了这一现象,如朴素实在论和确认偏误。虚假信息主要是利用新闻消费者的个人弱点来攻击消费者。由于这些认知偏见,假新闻等虚假信息往往被视为真实。人类对假新闻的脆弱性一直是跨学科研究的主题,这些研究结果为开发越来越有效的检测算法提供了依据。为了了解虚假信息和假新闻在社交媒体中的影响,我们可以使用技术来描述不同类型WSS的传播特征:1)来源(可信度/可靠性、信任、立场/世界观、意图)[27,28];2)目标社会群体(偏见、人口统计学、立场/世界观)[11];3)内容特征(语言、视觉、语境、情感基调与密度、长度与连贯性)[5,8];4)它们与网络交互的性质(例如,内聚的、分离的)[9]。例如,这些理论的影响可以通过测量用户元数据[11]来量化,从而回答“为什么人们容易受到假新闻的影响?”或者“特定群体的人更容易受到某些类型假新闻的影响吗?”
社会认同理论等社会理论认为,偏好社会接受和肯定对于一个人的身份和自尊是至关重要的,这使得用户在消费和传播新闻信息时更倾向于选择“社会安全”的选项。根据社交同质性理论,社交媒体上的用户往往会关注和加好友的人是志趣相投的人,从而得到新闻宣传他们现有的叙述,产生回音室效应。定量分析是一个有价值的工具,用来验证这些理论是否、如何以及多大程度上可以预测用户对假新闻的反应。在[29]中,作者试图证明新闻分层传播网络中的结构和时间视角会影响假新闻消费,这表明在打击假新闻的斗争中,社会监督薄弱的额外来源是有价值的。为了获得细粒度的分析,传播网络被处理为层次结构,包括宏观级别(以发布、转发的形式)和微观级别(以回复的形式)的传播网络。从结构、时间和语言三个方面分析了虚假新闻与真实新闻在层次传播网络上的差异。
2.2 利用WSS检测虚假信息
发现虚假信息和假新闻提出了独特的挑战,使它变得不容易。首先,数据挑战一直是一个主要的障碍,因为假新闻和虚假信息的内容在主题、风格和媒体平台上相当多样化;假新闻试图用不同的语言风格来歪曲事实,同时嘲讽真实的新闻。因此,获取带注释的假新闻数据是不可扩展的,特定于数据的嵌入方法不足以检测只有少量标记数据的假新闻。其次,虚假信息和假新闻的挑战在不断演变,也就是说,假新闻通常与新出现的、时间紧迫的事件有关,由于缺乏确证的证据或主张,这些事件可能没有得到现有知识库(知识库)的适当验证。为了解决这些独特的挑战,我们可以学习在社会监督薄弱的情况下,在不同的挑战性场景中,如有效的、可解释的和早期的检测策略中,发现虚假信息和假新闻。这些算法的结果为检测假新闻提供了解决方案,也为研究人员和从业者解释预测结果提供了见解。
有效侦测虚假信息

图3: 社会监督下的TriFN学习模型,来自发布者偏差和用户可信度,用于有效地检测虚假信息[30]。
其目的是利用微弱的社会监督作为辅助信息,有效地进行虚假信息的检测。以交互网络为例,对新闻传播过程中的实体及其关系进行建模,以发现虚假信息。交互网络描述了不同实体(如发布者、新闻片段和用户)之间的关系(见图3)。考虑到交互网络,目标是通过建模不同实体之间的交互,将不同类型的实体嵌入到相同的潜在空间中。利用框架trif -relationship for Fake news detection (TriFN)[30],可以利用新闻的合成特征表示来执行虚假信息检测。
在社会学和认知理论的启发下,衍生出弱社会监督规则。例如,社会科学研究表明,以下观察结果有助于我们薄弱的社会监督:人们倾向于与志趣相投的朋友建立关系,而不是与有着相反的偏好和兴趣的用户建立关系。因此,有联系的用户更有可能在新闻中分享相似的潜在兴趣。此外,对于出版关系,可以探讨以下薄弱的社会监督:政治偏见程度高的出版商更容易发布虚假信息。此外,对于传播关系,我们有:低可信度的用户更可能传播虚假信息,而高可信度的用户不太可能传播虚假信息。利用非负矩阵因式分解(NMF)等技术,通过对弱社会监督的编码来学习新闻表征。在真实数据集上的实验表明,TriFN能够达到0.87的检测精度。
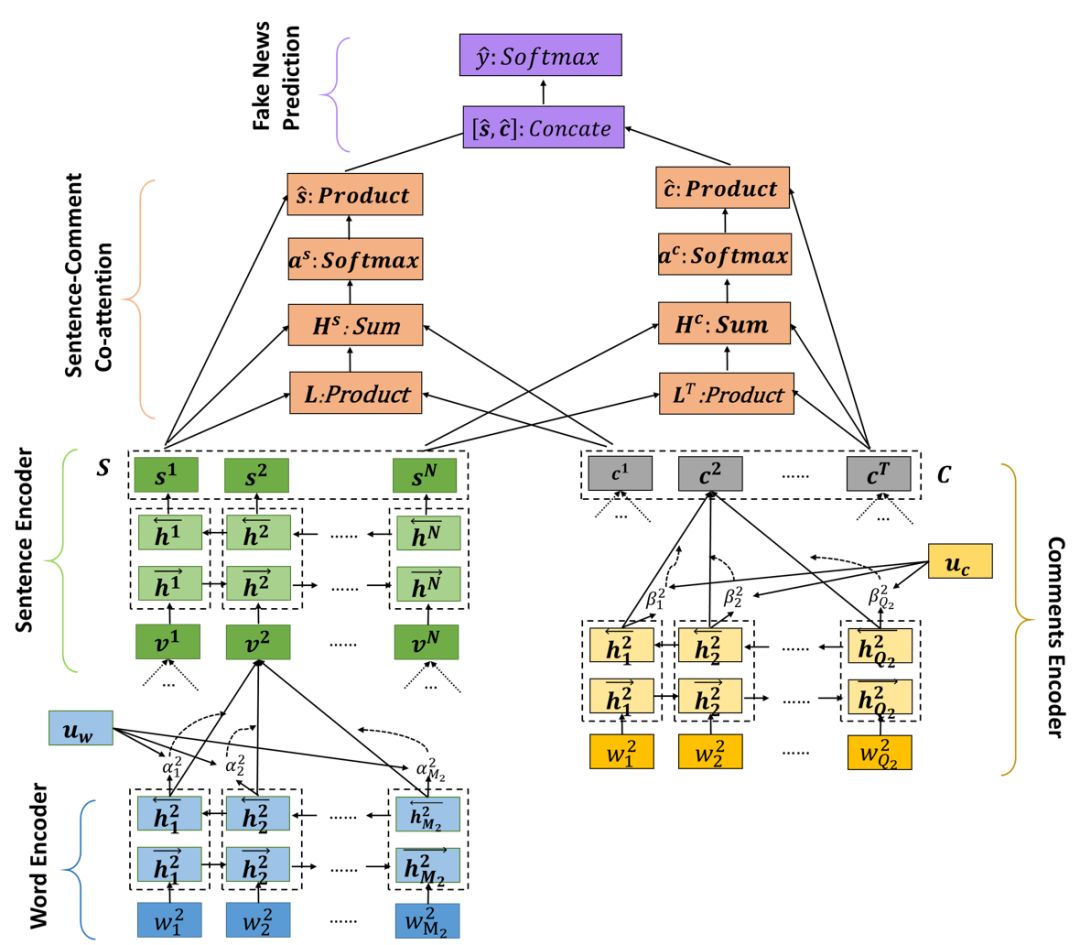
图4: 可解释虚假信息检测[31]的社会监督学习deFEND模型。
用解释来证实虚假信息。以假新闻为例,可解释虚假信息检测的目的是获取top-k可解释的新闻句子和用户评论,用于虚假信息的检测。它有可能改进检测性能和检测结果的可解释性,特别是对于不熟悉机器学习方法的终端用户。可以看出,新闻内容中并不是所有的句子都是假的,事实上,很多句子是真的,只是为了支持错误的索赔句。因此,新闻句子在判断和解释一则新闻是否是假的方面可能不是同等重要的。类似地,用户的评论可能包含一些重要方面的相关信息,这些信息可以解释为什么一条新闻是假的,而它们提供的信息和噪音可能也较少。可以使用以下较弱的社会监督:与原始新闻片段内容相关的用户评论有助于发现假新闻并解释预测结果。在[31]中,它首先使用带有注意力的双向LSTM来学习句子和评论表示,然后利用一个叫做dEFEND的句子-评论-注意神经网络框架(参见图4)来利用新闻内容和用户评论来共同捕获可解释的因素。实验表明,dEFEND在准确性(∼0.9)和F1(∼0.92)。另外,dEFEND可以发现可解释的注释,提高预测结果的可表达性。
虚假信息的早期预警。假新闻等虚假信息往往与新出现的、时间紧迫的事件有关,由于缺乏确凿的证据,现有的知识库或网站可能无法对这些事件进行核实。此外,在早期阶段检测虚假信息需要利用来自用户参与的最小信息预测模型,因为广泛的用户参与表明更多的用户已经受到虚假信息的影响。社交媒体数据是多面性的,表明新闻片段与社交媒体传播者之间存在多种异构关系。首先,用户的帖子和评论有丰富的人群信息,包括观点、立场和情绪,这对发现假新闻很有用。之前的研究表明,传播者之间的矛盾情绪可能预示着虚假新闻的高概率[32,33]。其次,不同的用户有不同的可信度。最近的研究表明,一些不太可信的用户更有可能传播假新闻。这些来自社交媒体的发现很有可能为早期发现假新闻带来更多信号。因此,我们可以同时利用和学习来自社交媒体的多源头的弱社会监督(以弱标签的形式)来推进早期的假新闻检测。
关键思想是,在模型训练阶段,除了有限的干净标签外,还使用社会上下文信息来定义弱规则,以获得弱标记的实例来帮助训练。在预测阶段(如图5所示),对于测试数据中的任何一条新闻,只需要新闻内容,根本不需要社交活动,因此可以在非常早期的阶段发现假新闻。可以使用深度神经网络框架,其中较低层的网络学习新闻文章的共享特征表示,而较高层的网络分别建模从特征表示到每个不同监管源的映射。框架MWSS的目标是,除了干净的标签外,联合开发多个薄弱社会监督的来源。为了提取福利标签,需要考虑以下几个方面,包括情感、偏见和可信度。


图5: MWSS框架,用于从社交媒体数据中进行多重弱监督学习,以便及早发现虚假信息。
3. 发展趋势
假新闻和虚假信息是新兴的研究领域,存在一些重要但尚未在当前研究中得到解决(或彻底解决)的公开问题。我们简要描述有代表性的未来方向如下。
解释方法。近年来,假新闻的计算机检测已经产生了一些有希望的早期结果。然而,该研究有一个关键部分,即这种检测的可解释性。,为什么一条特定的新闻被认为是假的。最近的方法尝试从用户评论[31]和web文档[38]中获得解释因子。其他类型的用户约定(如用户配置文件)也可以建模以增强可解释性。此外,解释为什么人们容易轻信假新闻并传播它是另一个关键的任务。解决这一问题的一种方法是从因果发现的角度,通过推断有向无环图(DAG),进一步估计用户的治疗变量及其传播行为。
神经网络假新闻的生成与检测. 假新闻一直是社交媒体上的一个重要问题,而强大的深度学习模型由于具有生成神经假新闻[23]的能力而被放大。在神经假新闻生成方面,最近的进展允许恶意用户根据有限的信息生成假新闻。生成式对抗网络(GAN)[19]等模型可以从噪声中生成长可读的文本,而GPT-2[22]可以编写具有简单上下文的新闻故事和小说。现有的假新闻生成方法可能无法生成风格增强和事实丰富的文本,这些文本保留了与新闻声明相关的情感/朗朗上口的风格和相关主题。检测这些神经假新闻首先需要了解这些假新闻的特点和检测难度。Dirk Hovy等人提出了一种对抗性设置来检测生成的评论[39]。[23]和[40]提出了神经生成检测器,它可以对生成器的前一个检查点上的分类器进行微调。(1)如何利用神经生成模型生成假新闻?我们能区分人工生成和机器生成的假/真新闻吗?
早期发现虚假信息. 早期发现虚假信息和假新闻是为了防止大量的人受到影响。之前的大部分工作都是学习如何从新闻内容和社会背景中提取特征,建立机器学习模型来检测假新闻,一般都是考虑了二分类的标准场景。最近的研究考虑了这样一种情况:很少甚至没有用户参与被用来预测假新闻。例如,Qian等人提出生成合成用户契约来帮助检测假新闻[41]; Wang等人提出了一个事件不变的神经网络模型,学习可转移的特征来预测新出现的新闻片段是否是假的。在2.2节中,我们还讨论了如何利用不同类型的WSS对假新闻进行早期检测。我们可以使用更复杂的方法来增强这些技术,而这些方法依赖于更少的训练数据,例如,用小样本学习[42]来早期检测假新闻。
基于假信息的交叉主题建模。假新闻的内容在话题、风格和媒体平台[33]上都表现得相当多样化。对于一个真实世界的假新闻检测系统来说,由于标签成本高昂,获取每个领域(如娱乐和政治是两个不同的领域)丰富的标签数据往往是不现实的。因此,假新闻检测通常在单域设置下进行,并且提出了监督[43]或非监督方法[44,45]来处理有限甚至未标记的域。然而,性能在很大程度上是有限的,因为过度拟合小标记样本或没有任何监督信息。此外,在一个领域中学习的模型可能是有偏见的,并且可能在不同的目标领域中表现不好。解决这一问题的一种方法是利用领域自适应技术探索辅助信息,将知识从源领域转移到目标领域。此外,还可以利用诸如对抗性学习等先进的机器学习策略来进一步捕获主题不变的特征表示,从而更好地检测新出现的虚假信息。
参考文献:
[1] Claire Wardle and Hossein Derakhshan. Information disorder: Toward an interdisciplinary framework for research and policy making. Council of Europe Report, 27, 2017.
[2] Liang Wu, Fred Morstatter, Kathleen M Carley, and Huan Liu. Misinformation in social media: Definition, manipulation, and detection. ACM SIGKDD Explorations Newsletter, 21(2):80–90, 2019.
[3] Xinyi Zhou and Reza Zafarani. Fake news: A survey of research, detection methods, and opportunities. arXiv preprint arXiv:1812.00315, 2018.
[4] Edson C Tandoc Jr, Zheng Wei Lim, and Richard Ling. Defining “fake news” a typology of scholarly definitions. Digital journalism, 6(2):137–153, 2018.
便捷查看下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“FND” 就可以获取《挖掘虚假信息和假新闻:概念、方法和最新进展》的论文和PPT专知下载链接索引


相关内容

亚利桑那州立大学(Arizona State University)是全美最大最佳的五所“大学城”之一,创立于1885年,坐落于距州府凤凰城11英里的大学城坦佩。
亚利桑那州立大学学术力量雄厚,教学一流,被誉为全美州立大学中研究密度最高的大学之一,是全球性跨学科教学和研究的重要中心。其商学院和教育学院排名全美前列。此外,天文学也是亚利桑那州立大学名牌系科。


