如何节省1T图片带宽?解密极致图像压缩!
图像已经发展成人类沟通的视觉语言。无论传统互联网还是移动互联网,图像一直占据着很大部分的流量。如何在保证视觉体验的情况下减少数据流量消耗,一直是图像处理领域研究的热点。也诞生了许多种类的图像格式JPEG、PNG 、GIF、WEBP、HEVC,以及腾讯公司自研的WXAM和SHARPP格式。
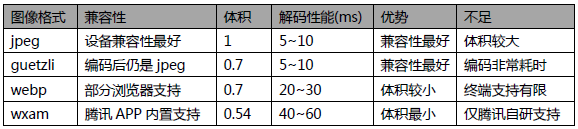
腾讯TEG - 架构平台部图片存储系统TPS 作为超大规模的图片平台,图片数万亿张存储量百P,下载带宽数T,一直需要严重关注图像压缩技术的发展。本文就近几年图像压缩技术的发展、新格式的出炉,和图片存储系统TPS在实际业务上的落地实践做个简单的介绍。以及在不断出现的新格式被逐步应用之后,兼容性最好的传统老格式JPEG依然地位高居不下占据大幅带宽,如何在老格式上也继续挖掘优化点,是本文重点介绍的内容。在开始介绍之前先大概总结下各个格式在兼容性、图像大小以及编解码性能上的优势和劣势。
Webp和HEVC的面世
JPEG、PNG、GIF在互联网畅行了多年后,2010年Google提出了一种新的图片压缩格式 — webp,给图片压缩优化提供了一个新方向。Webp相比JPEG多了一个预测模式,在相同ssim得分下,有损WebP相比可减少25%~34%的大小,有损WebP也支持透明通道,大小通常约为对应PNG的1/3。
借助Webp的开放性和平台兼容性,互联网的推广应用变得很畅顺,这是webp相比JPEG2000和JPEGXR能取得成功的关键原因。Chrome和opera浏览器都支持webp,它们占据了一半的浏览器市场份额,另外Android系统 4.0以上版本也默认支持webp格式。
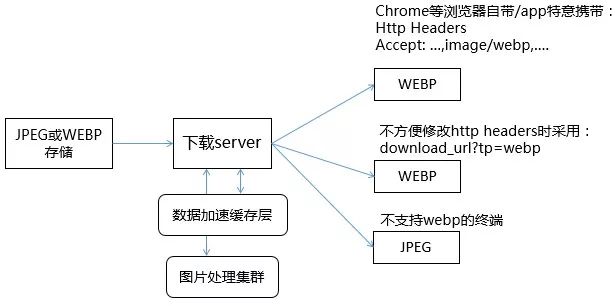
在这个背景下,TEG架构平台部图片存储系统TPS,快速推出了webp解决方案,如下图所示。并在QQ相册、微信朋友圈、微信公众号、QQ看点、腾讯新闻、腾讯视频等公司绝大多数的图片业务开启使用。总共节省了超过500G的带宽,每年成本节省额度大几千万元。
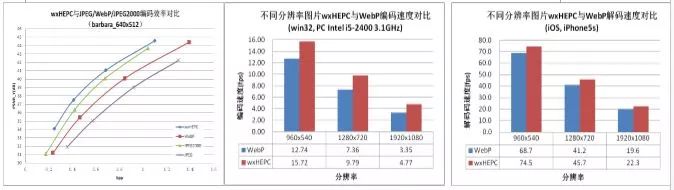
很快,HEVC/H265到来了,它是当前最新一代的视频编码技术,基于该标准压缩出来的图片大小可降到JPEG的46%,动图相对gif甚至可以降低到原来的20%大小,这相比webp又有了极大的提升,这个节省量可以说是相当可观了。但相应的,它的编解码速度相比jpg要差非常多,处理延时大同时设备资源消耗量也非常巨大。于是腾讯微信团队和SNG音视频团队经过大量研究和开发工作,分别推出了自研的性能业界领先的高效图片压缩内核WXAM和SHARP,不牺牲压缩的情况下,编解码速度数倍于知名开源工程x265,甚至超过了webp。
为了进一步提升处理速度,我们甚至对它们的编码在FPGA硬件卡进行实现,进一步降延时降低到了cpu的1/4以内。
虽然WXAM/SHARP并没有外界的浏览器支持,但公司内的各大手机app都推动进行了解码库封装来支持解析,图片存储系统进行适配输出后,又一次优化掉了将近500G的带宽,年化收益大几千万。
JPEG优化之路
WEBP/WXAM/SHARP纷纷落地之后,统计公司业务的图片带宽,JPEG带宽占比仍然超过1/3。原因主要有,各类不兼容这些格式的浏览器、不便进行改造的app、其他不可控的第三方过来的访问。再统计腾讯云的万象优图产品的带宽,外部业务的JPEG甚至超过了90%,终端兼容门槛始终是个很大的障碍。
那在JPEG带宽上我们还能做些什么呢?
通常图像处理服务在编码JPEG图像时会调整图像量化表,以减少图像的大小,即通过降低图片质量值的方式。我们根据不同业务要求设置不同的质量参数,还对特定图片做降级处理,比如二维码为主体的图片,降低更多质量并不影响查看体验。但这些毕竟还是容易肉眼可见的有损调整,于是就有了基于人眼视觉特性来对JPEG做进一步压缩的guetzli,它可以让JPEG图片平均减少30%的大小。压缩效果不比webp差,却没有webp的解码端兼容性问题。
采用传统方法处理图像调整图像质量为85,得到处理后图像大小为48403字节。

Libjpeg编码图像:进行心理视觉编码得到图像大小为32449字节

guetzli编码的图像:采用心理视觉方法编码出的图像,肉眼无法感知其差异,其大小是libjpeg编码图像的67%
基于心理视觉的方法
1.编码原理
年初google发表了关于使用心理视觉来进行图像处理的guetzli论文,在该文中描述了相关优化的主要依据:
人眼锥细胞敏感光谱的重叠,RGB三个通道之间是有联系的,黄色光会降低蓝色光的敏感度,因此黄色区域附近的蓝色可以使用低精度编码
人眼的蓝色空间分辨率低于在红色和绿色,并在高分辨率旁边没有蓝色的受体因此蓝色的高频变化可以使用低精度编码
视觉图像中的精细结构依赖于附近视觉变化的量级,因此可以在有大量视觉噪音的地方使用低精度编码
下图展示了人眼对黄色区域附近的蓝色不敏感(图像引用自guetzli论文)

黄色背景上的hello world!文字不易被观察,将上图分别采用libjpeg和guetzli编码后,将蓝色通道转换为灰度图如下图所示:
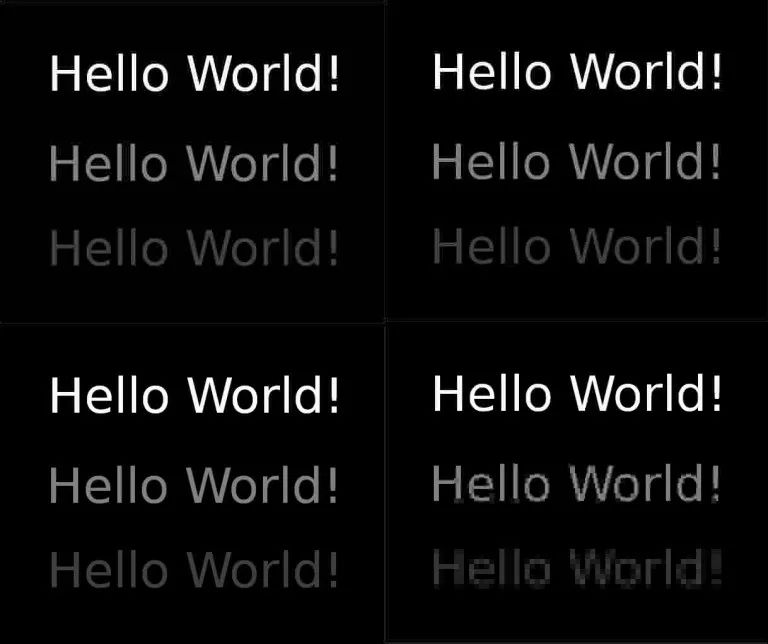
上半部分jpeg编码针对黑色背景和黄色背景,蓝色通道均采用相同的精度保存,而下半部分guetzli编码蓝色在黄色背景下存储时采用低精度的编码。
guetzli编码图像处理过程主要分为以下三个大的迭代过程:
第一次迭代,取得最优的全局量化表
第二次迭代,计算每个块中的哪些系数可供消零(低分辨率部分),且消零后视觉评价体系上图像无差别
第三次迭代,将第二次迭代的消零序列,进行消零尝试,先进行大幅度消零计算其得分和文件大小,然后根据文件大小适当回调消零的系数
因为有了这些消零的部分,使得图像相对于原图在编码时产生更多的连续的0,这样在进行游程编码时能够减少数据量。
原始处理过程:
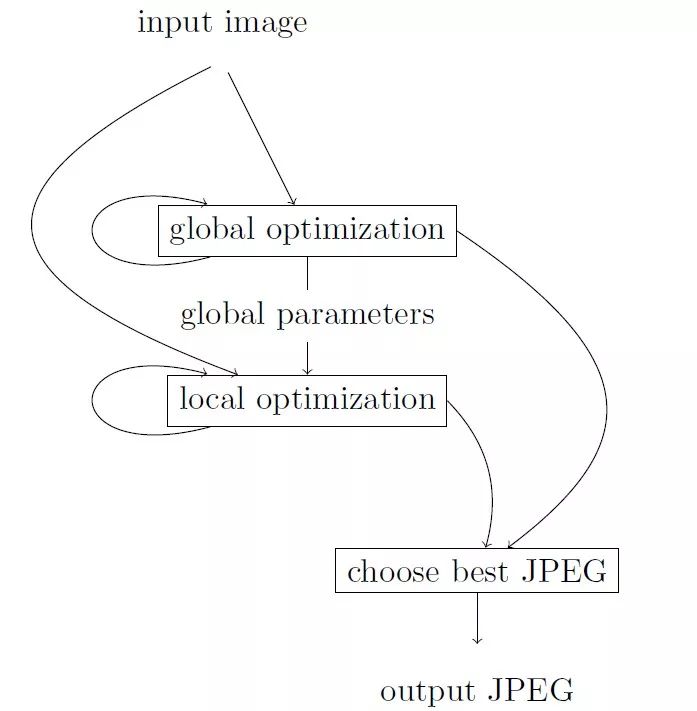
2.性能优化
Guetzli处理过程有非常多次的大小迭代,计算量极大, 加上google官方的版本未进行太多的优化,存在大量重复计算以及流程冗余。Guetzli单图计算消耗,相比jpeg编码高出两个数量级,呈百倍关系。处理延时远远超出在线使用的可承受范围,更关键的是,设备消耗过大。按分辨率500x500的图片来看,平均处理一张延时10秒以上,单图必须被下载1000次节省下带宽成本才能抵消一次的处理设备成本消耗。随着图片分辨率增大,延时上升到分钟级甚至小时级别,非常惊人。
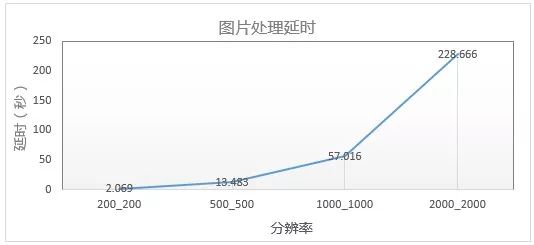
为了能够在现网应用,需要对算法进行移植改造提升其处理速度。图像处理的过程中的很多计算是可以并行的,那么利用GPU来并行化加速处理,很自然的成为了我们的解决思路。和SNG增值产品部开发运维团队组成公司图片业务的Guetzli落地推广的联合项目:实现了算法优化改造,并线下进行了千万级别的图片测试验证,确定了机器选型和资源调度上线。这里的主要优化和效果如下:
Jpeg图像采样方式较多,而官方版本仅支持420与444采样格式,为支持所有的采样,我们在应用中扩展了图像编解码函数,采用libjpeg-turbo进行图像数据解码,完整支持所有jpeg采样,同时ibjpeg-turbo相对于libjpeg在编解码上做了一定的优化,能够提升解码过程的性能。
由于视觉评价体系中大量计算是分别针对图像三个通道进行处理,同时也会将图像按照不同的块进行分割计算以及图像卷积操作,单个块或者通道计算量大,所有块或通道需要重复上百万次计算,计算过程完全相同且块与块之间的计算相对独立不会有相互的影响。那么这些计算过程能够并行,我们扩展了butteraugli视觉评价体系,将这些繁复可并行的计算全部移植到GPU上能大幅减少计算延迟。
在第二次迭代计算可供消零的系数过程中,当消零后的图像误差超过了允许的全局误差之后,后续的可供消零序列将变得不再有意义,我们将计算过程提前终止掉,这样去除了后续大量的无效冗余运算,从计算流程上减少了编码延迟。
算法实现中大量采用双精度进行计算,我们支持将双精度调整为单精度加速计算过程,减少双精度带来的大量性能消耗,不过由于精度上的损失会使得输出结果与官方工具有些差异,但是精度的损失反映到图像上的影响微乎其微。
由于图像大小在一定的范围内波动,图像数据通常在数百KB内波动,图像需要连续的内存、显存空间,那么优化内存、显存使物理内存空间上连续能够提高内存读写速度。利用tcmalloc替换glibc的内存管理,提升主机端内存访问性能。应用内池化显存能够减少设备驱动的调用,提升图像大数据块的分配和释放性能。这样优化后能够减少内存和显存的碎片、由于内存连续也提高了访问性能。
在计算处理过程中有许多冗余函数来生成固定的参数序列,将这些函数合并或预处理展开后减少计算流程上的函数调用冗余。
从主机内存到设备显存的数据拷贝是需要经过PCIE总线,数据拷贝带宽受到GPU物理布局方式以及PCIE总线带宽两方面的影响,那么针对一些较小分辨率的图像,为了平衡传输延迟和计算延迟,我们按图像分辨率将计算拆分,图像大于某一分别率之后计算延迟远远超过传输延迟时,这部分计算转移至GPU上进行,否则在CPU上完成计算。
现网实际应用中,在GPU上提供异构计算服务时同样有一些需要注意的地方,为了避免GPU空闲时驱动程序释放设备导致新应用启动时长过长,我们需要将设备持久化保持在驱动程序中。
为了避免在GPU上部署应用时创建GPU Context的性能开销,应用应该仅在启动时创建GPU Context后续所有计算均在同一Context上使用不同的流来完成。合理的使用流能够有效提升GPU吞吐。
图像处理过程对GPU设备的利用是一个波动的状态,而单个进程通常不能完全有效的利用GPU,为了提升GPU利用率,提升编码集群的吞吐量,需要部署多个应用进程绑定到同一GPU,具体绑定数量需要考虑显存大小与实际应用的GPU利用率。
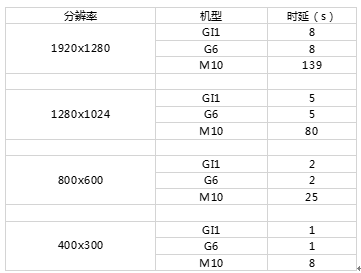
改造后的平均处理延时下降到原来的10%以内,下图GI1和G6代表改造的库跑在GPU设备上的延时,M10表示改造前的官方库的延时。
3.业务落地
经过上述改造后,已经有望上线服务业务了。我们对当前图片平台架构做了部分调整:采用异步压缩,持久化存储,控制CDN缓存时间的方式来贴合业务使用。基本架构如下图所示:
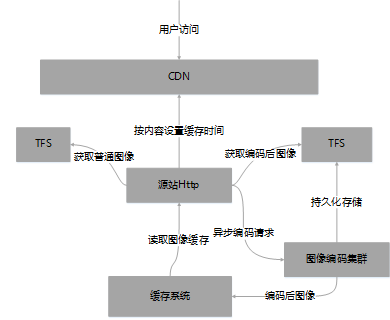
guetzli下载架构
1. 源站需要根据当前图像的格式以及缓存时间灵活的设置CDN缓存时间
2. 编码集群要根据其处理能力和请求时间合理的处理请求
下载流程如下:
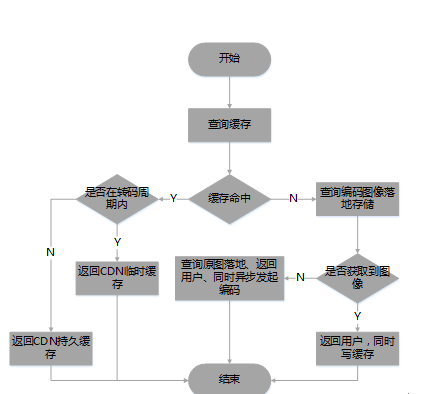
guetzli下载流程
1.当缓存命中后,需要判断缓存图像是否已经编码过,若在编码周期内,则向CDN前端返回临时缓存。否则返回持久缓存
2.若缓存没有命中,则从存储系统中查询落地的编码图像,若落地图像不存在,则将原图返回给CDN设置临时缓存,同时异步发起图像编码。若已存在则直接将图像返回给CDN且持久缓存
4.业务落地现状
针对当前webp/wxam/sharpp无法覆盖的场景,采用心理视觉的图像处理方法,能够在保证图像质量的前提下,大幅减少图像大小,节省用户流量并提升下载体验。上述方案已经在QQ增值业务、腾讯视频、QQ音乐、QQ看点、LOL视频官网中心等业务上进行了应用,腾讯视频、微信公众号、头像等适合落地的图片业务也在测试中。腾讯云的万象优图产品,也可以在控制台一键开启。
这些优化纷纷落地后,总共节省上T的带宽,用户下载延时减少20%以上。未来还会有更多的发展。2017下半年IPhone又新推出了HEIF格式,并对iphone7以上支持硬编解,让IOS对hevc的兼容提供了重大便利,随着ios11的普及,预计未来众多图片业务会朝着heif格式收拢。围绕节省用户和服务器带宽,以及提升用户下载体验的目标,我们会继续前行,让带宽压到最小,让图片越来越清晰。
文章来源:腾讯架构师 (ID:TencentArchitecture)






