【泡泡一分钟】同时具有目标识别与定位的语义地图
每天一分钟,带你读遍机器人顶级会议文章
标题:Semantic Mapping with Simultaneous Object Detection and Localization
作者:Zhen Zeng Yunwen Zhou Odest Chadwicke Jenkins Karthik Desingh
来源:2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)
编译:王丹
审核:颜青松,陈世浪
欢迎个人转发朋友圈;其他机构或自媒体如需转载,后台留言申请授权

摘要

本文提出一种基于滤波器的语义地图构建方法,可以同时检测物体和六个自由度的定位。我们的方法称为上下文时间一致性地图(CT-Map),我们根据观测的场景在语义地图上设置物体类别和姿态。然后以条件随机场(CRF)的形式模拟语义地图推断问题。CT-Map是一种CRF,考虑两种形式的关系潜力来解释物体之间的背景关系和物体姿态的时间一致性,以及观察的测量潜力。然后提出粒子滤波算法在CT-Map模型中执行推断。我们在配备了RGB传感器的密西根进度提取机器人上验证了CT-Map方法的有效性。本文的结果表明相对于将观测值视为场景中独立样本的基线方法,基于粒子滤波的CT-Map推断提供了更好的目标检测和姿态估计。

图1.机器人在四次不同方向中对学生休息室进行语义建图。每列显示环境的RGB简照,以及由检测到的和定位到的物体组成的相应语义地图。本文提出了一种时间一致性地图(CT-MAP)的方法,在一系列RGB-D观测的情况下,同时检测目标并定位其6自由度姿态。为了实现这一点,本文将语义建图问题表示为对物体类别和姿态的概率性估计问题。使用条件随机场(CRF)来模拟物体之间的上下文关系和物体姿态的时间一致性。
基于粒子滤波的CT-Map算法流程:

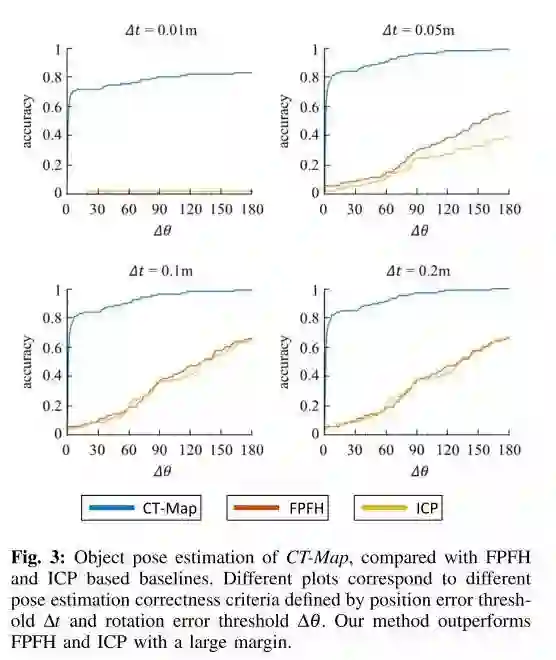
图3.与基于FPTH和ICP的基线比较的CT-Map的目标姿态估计。不同的图对应于由位置误差阈值∆t和旋转误差阈值∆θ定义的不同姿态估计正确性标准。我们的方法比FPTH和ICP有很大的优势。
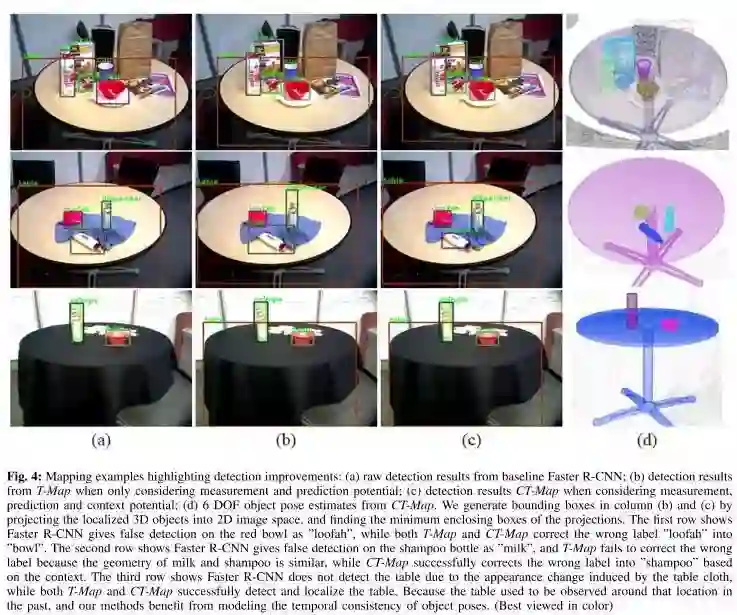
图3.高亮表示检测改进的绘图示例:(a)基线方法Faster R-CNN的原始检测结果;(b)仅考虑测量和预测可能性时T-MAP的检测结果;(c)考虑测量、预测和上下文可能性时的CT-Map检测结果;(d)CT-Map的6自由度目标姿态估计。我们在(b)和(c)列中生成边界框,方法是将本地化的三维对象投影到二维图像空间中,并找到投影的最小边界框。第一行显示 Fater R-CNN在红碗上以“loofah”的形式进行错误检测,而T-MAP和CT MAP都将错误的标签“loofah”更正为“bowel”。第二行显示 Faster R-CNN在洗发水瓶上以“milk”的形式进行错误检测,而T-MAP由于牛奶和洗发水的几何结构相似而未能更正错误的标签,而CT-MAP则根据上下文成功地将错误的标签更正为“shampoo”。第三行显示 Faster R-CNN由于桌布引起的外观变化而无法快速检测到桌子,而T-MAP和CT-MAP都成功地检测和定位了桌子。因为在过去我们经常在这个位置周围观察这个桌子,我们的方法从建模对象姿态的时间一致性中受益。

Abstract
We present a filtering-based method for semantic mapping to simultaneously detect objects and localize their 6 degree-of-freedom pose. For our method, called Contextual Temporal Mapping (or CT-Map), we represent the semantic map as a belief over object classes and poses across an observed scene. Inference for the semantic mapping problem is then mod- eled in the form of a Conditional Random Field (CRF). CT-Map is a CRF that considers two forms of relationship potentials to account for contextual relations between objects and temporal consistency of object poses, as well as a measurement potential on observations. A particle filtering algorithm is then proposed to perform inference in the CT-Map model.We demonstrate the efficacy of the CT-Map method with a Michigan Progress Fetch robot equipped with a RGB-D sensor. Our results demonstrate that the particle filtering based inference of CT-Map provides improved object detection and pose estimation with respect to baseline methods that treat observations as independent samples of a scene.
如果你对本文感兴趣,想要下载完整文章进行阅读,可以关注【泡泡机器人SLAM】公众号(paopaorobot_slam)。
欢迎来到泡泡论坛,这里有大牛为你解答关于SLAM的任何疑惑。
有想问的问题,或者想刷帖回答问题,泡泡论坛欢迎你!
泡泡网站:www.paopaorobot.org
泡泡论坛:http://paopaorobot.org/bbs/


泡泡机器人SLAM的原创内容均由泡泡机器人的成员花费大量心血制作而成,希望大家珍惜我们的劳动成果,转载请务必注明出自【泡泡机器人SLAM】微信公众号,否则侵权必究!同时,我们也欢迎各位转载到自己的朋友圈,让更多的人能进入到SLAM这个领域中,让我们共同为推进中国的SLAM事业而努力!
商业合作及转载请联系liufuqiang_robot@hotmail.com




