知识疫图背后的故事:如何将新冠疫情搬上地图
要想打造好疫情地图,基础工作是疫情数据的采集与整合。在疫情数据的收集过程中,知识疫图整理了丁香园、WHO、约翰·霍普金斯大学、必应等国内外多个平台的数据源,这些数据对于不同地区疫情有不同力度、不同准确度的描述。多样的数据源,不仅可以使数据更细粒度,而且保证了数据的完整性和准确性。
如图一所示,针对不同数据源的更新特点,知识疫图运用了不同的采集方式,并将采集到的数据集合于一个数据库中,通过整合程序进行监控,整理对齐以便后续前端使用。图二是其中整合程序包含的具体工作,示例了其对数据对照、合并、补充、纠正四个方面的处理。数据整合后的数据库由于数据过大,不利于传输,对此研究人员采用了如图三的数据压缩方式,大大削减了字段不必要的开销。

图一 知识疫图数据采集过程
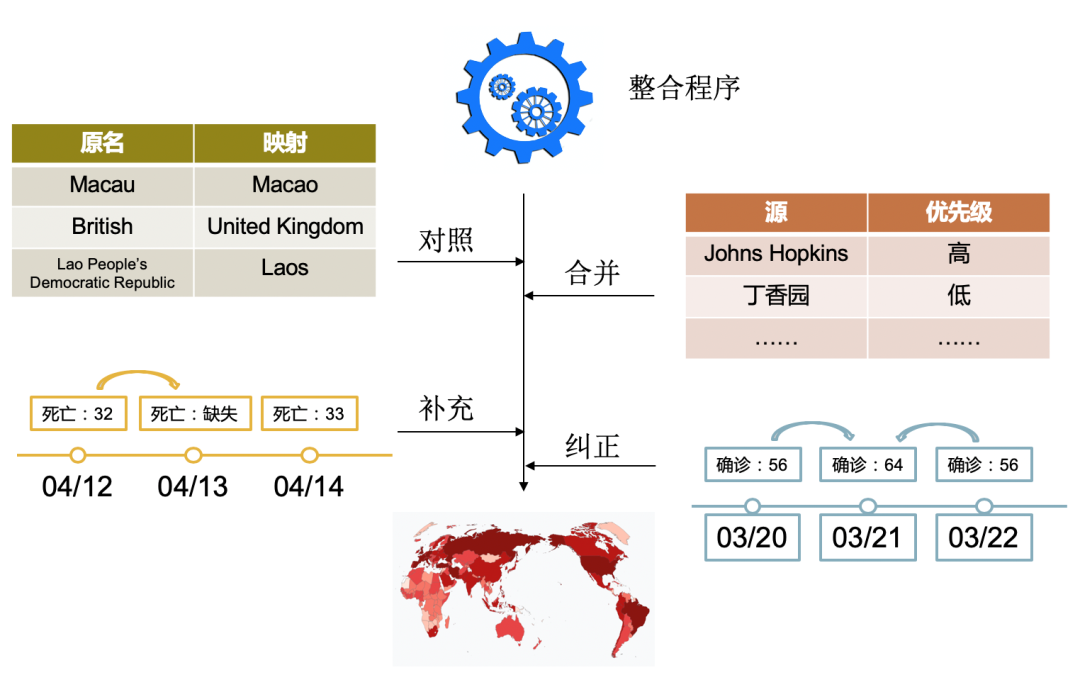
图二 整合程序
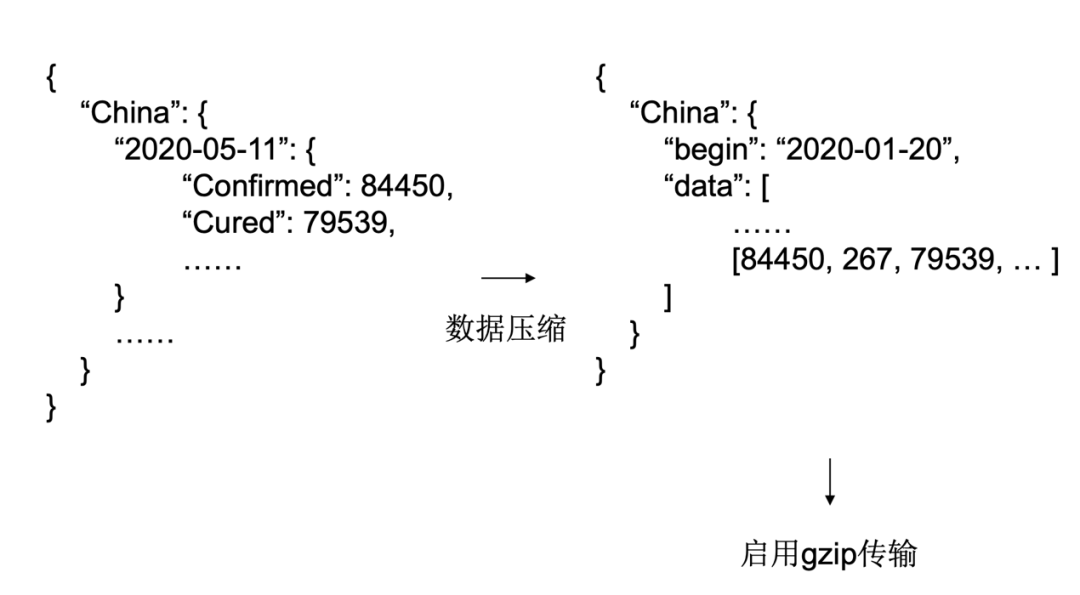
图三 数据压缩方式
地图数据的使用
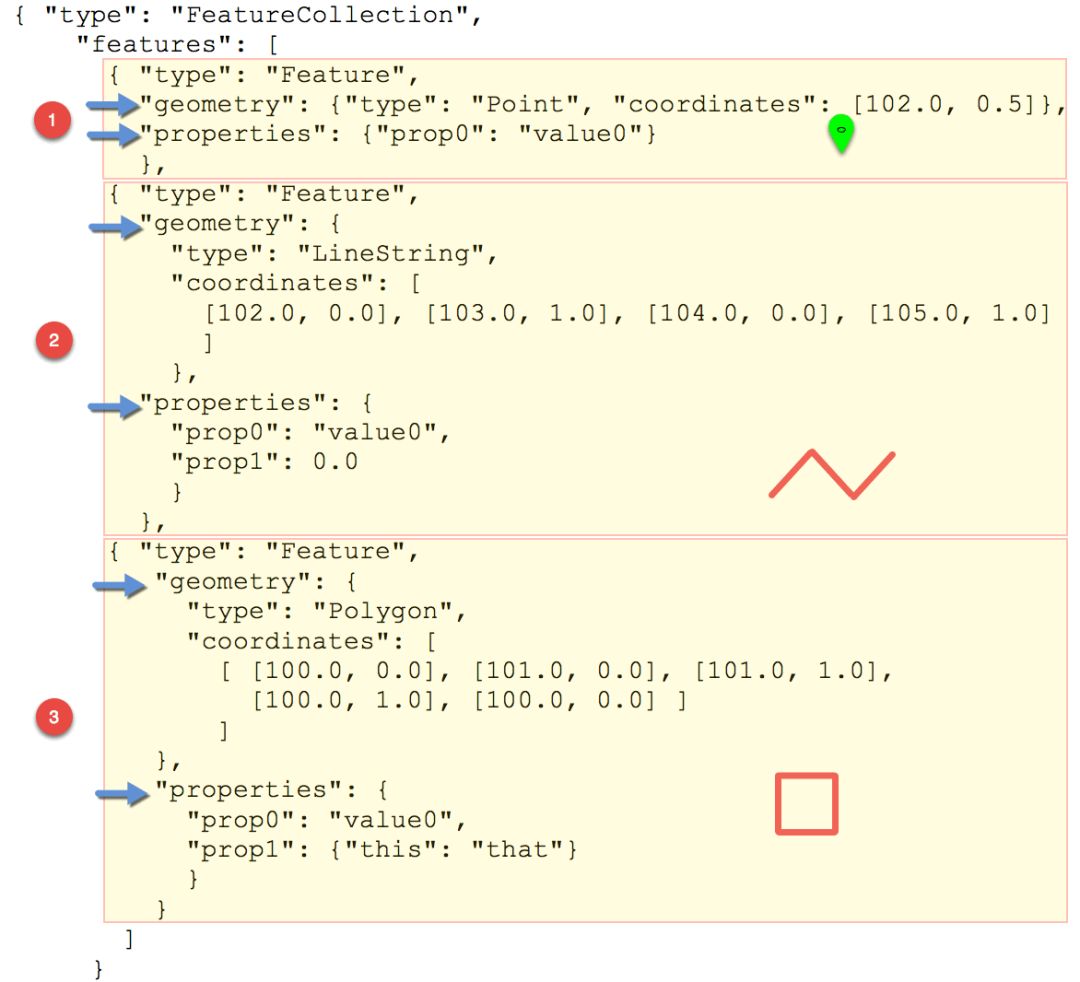
图四 Geojson格式

图五 Toposon格式
在地理数据的来源上,知识疫图国内和国外分别采集了阿里云、Natural Earth两大数据源。在收集到数据之后,进行地区字段的匹配如Beijing–China|Beijing–北京市,繁体简体转换,中英文对照等地区ID重组工作。虽然Natural Earth有数据完整性等优点,但其数据还存在一些细节需要修正(如图六)。中国地区的修正,主要指九段线、南海诸岛、台湾省、藏南地区等边界线和描述的处理。其他世界地区的数据调整包括(1)区域的重新规划比如意大利、法国等国家,需要以国家-大区-省方式重新合并和调整;(2)更粒度的数据处理比如英国苏格兰、北爱尔兰需要细化出像英格兰一样郡级的数据。
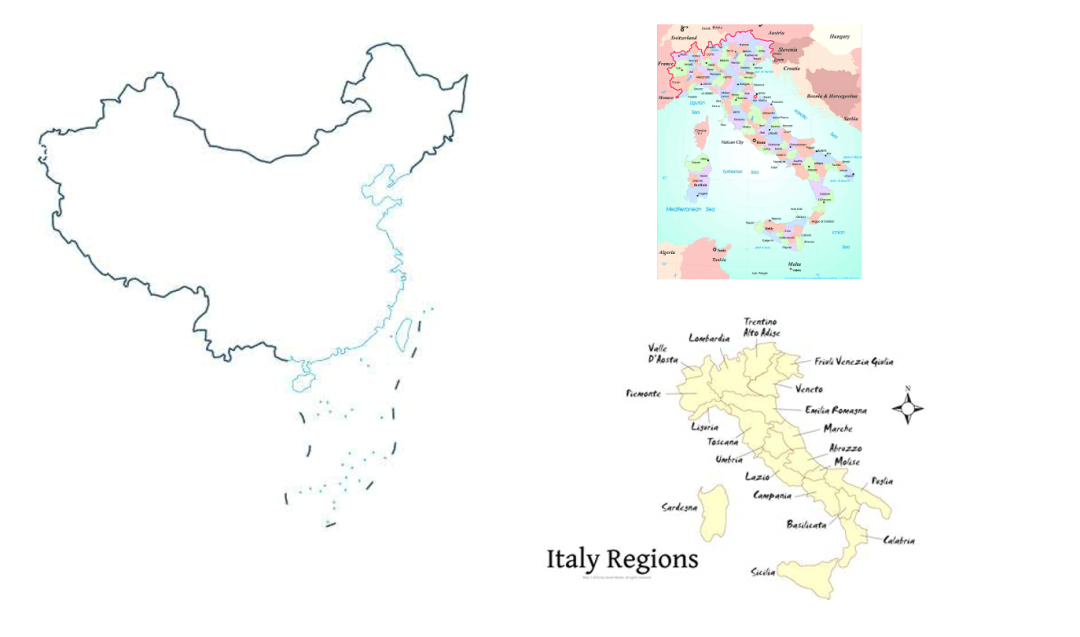
图六 数据修正示例
地图绘制
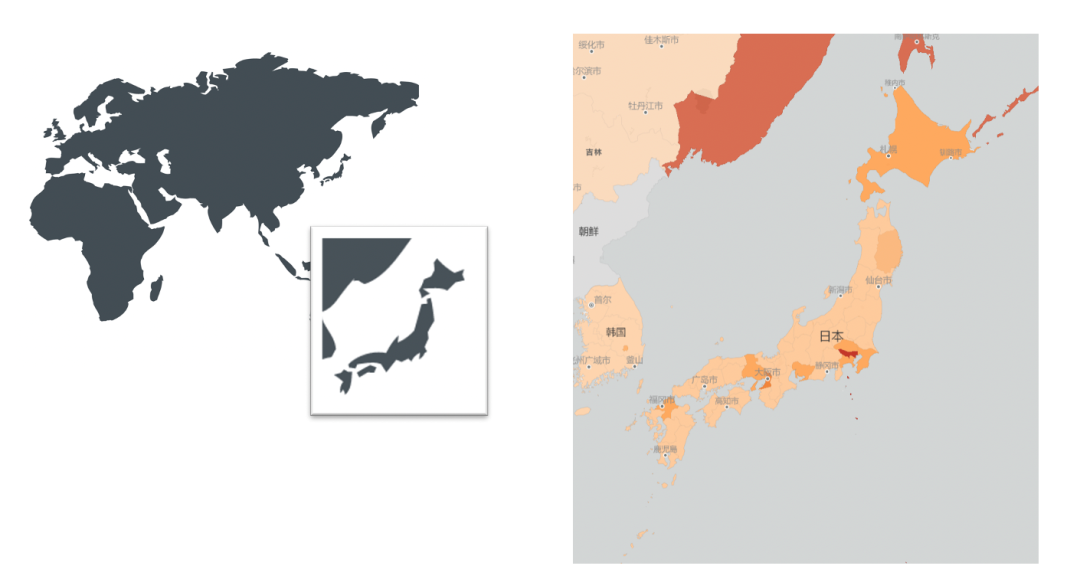
图七 粗粒度vs.细粒度
借助Mapbox Studio进行前端渲染,将完整地图数据转换成区块数据,而区块级数据可以根据放缩大小完成不同程度的边界压缩。比如在图八世界地图的宏观界面时,Mapbox Studio会将细粒度数据压缩为可以满足需求的粗粒度数据,但当放大到某一具体区域时,会转变成此地区细粒度的数据。宏观时采用粗粒度数据,微观时减少细粒度数据的范围,灵活的转变方式可以很好地实现不同层级的数据呈现,并控制传输开销。
图八 Mapbox Studio宏观前端渲染
前端渲染有其内在逻辑和流程,以图九中国地理数据为例,数据源包含了区域等特征。基于数据源地图组件会分为不同的层,每层依据不同的渲染规则负责渲染不同的内容。
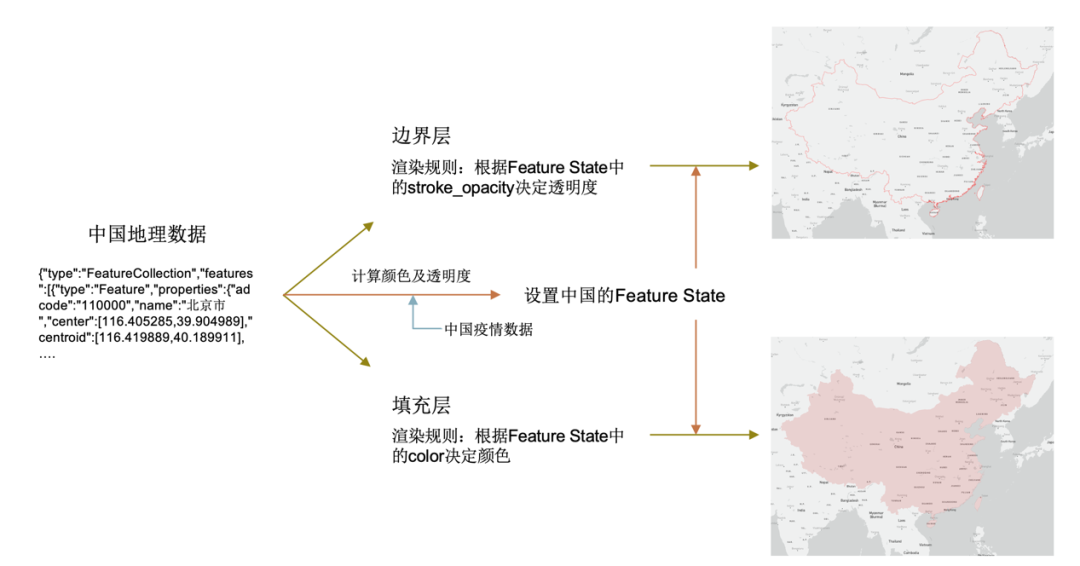
图九 中国地理数据前端渲染
除此之外,知识疫图的疫情地图前端渲染还包括了图十示例的事件,将各类新闻以地图标记的方式放置在疫情地图上,方便用户能够了解全世界在疫情之下各国发生的具体变化。
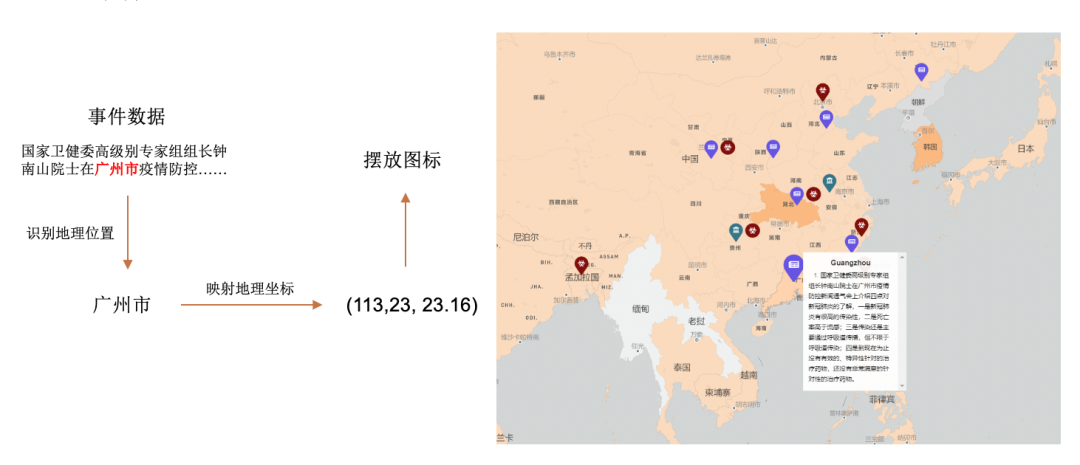
图十 事件渲染
答疑互动

关于数据压缩,Json文件和Gzip压缩的优点和原理?

Gzip可以理解成对于传输的内容做了压缩,现在在网络传输上Gzip算是一种常用的压缩方法,其实就是把这个功能在后端启用起来,算是一个小技巧。Json文件主要是从Geojson到Topojson会有一个比较大的提升,简单地说Topojson减少了重复内容的开销,尤其是像地图边界线这种,经常不同国家会公用同一段边界线,在Geojson里就会需要对这段边界线声明多次,但是Topojson里一次就可以搞定。

在合并同一地区的不同表达时,会有不同语种带来的问题吗?还是说大部分的数据库都是以英语为主的呢?
会有不同语种的问题,主要以英文为主,像视频里提到的法国、意大利之类的地方,专门做了一些行政区的人工处理来解决语言问题。
疫情数据怎么做到多数据源的融合呢,数据源和地理位置的对齐有什么简单的方法么?
对齐方法其实没有特别好的办法。我们这里也是半自动的方法,先做简单的匹配,然后把没匹配到的数据挑出来,看原因是什么比如有的就是语种问题或者是简写之类的问题,然后再把这些特殊情况整合一下写成映射规则放回去再处理。
当天实时的增长数据是怎么处理的?相对昨日的新增有考虑到时区问题么?
时区问题我们的做法是除了当天的情况,其他时间都是以北京时间0点为分界线。当天我们对于昨日的新增是按照过去24小时来做的特殊处理,另外在地名映射上也会考虑到不同地区的重名情况,所以每个地区的id实际上会包含它的上级节点,比如北京的id就是 China|Beijing,这个对于地区匹配也有一定作用。
整理:何文莉
审稿:殷 达








点击阅读原文,下载本次报告PPT!
