大模型时代,我们真的不再需要分词了吗?

文 | 付奶茶
编 | 小轶
分词是NLP的基础任务,将句子、段落分解为字词单位,方便后续的处理的分析。不知道NLPer有没有思考过这个问题:
我们在各项研究工作中想要建模的文本单位究竟是什么?
What are the units of text that we want to model?
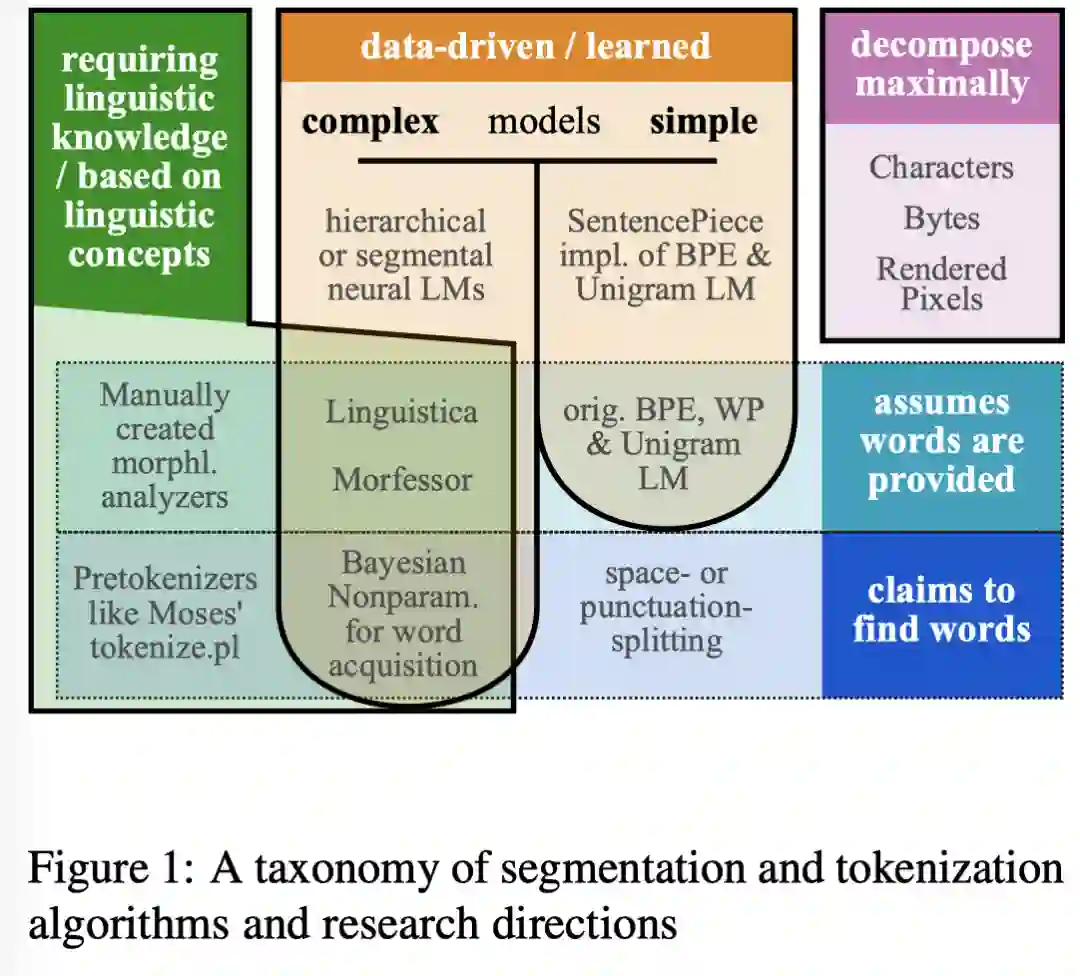
在这篇论文中,作者调查了pre-neural、neural era期的几项工作,通过工作,作者提出了一个结论:
"there is and likely will never be a silver bullet solution for all applications and that thinking seriously about okenization remains important for many applications"
即对于所有的应用,有且可能永远不会有灵丹妙药般的解决方案(angular solution),认真思考研究的计划对于很多应用仍然很重要.下面,我们一起来看下这篇论文:

论文标题:
Between words and characters: A Brief History of Open-Vocabulary Modeling and Tokenization in NLP
论文链接:
https://arxiv.org/abs/2112.10508
在关于什么是token这个问题上一直没有盖棺定论,我们可以看到知乎中大家的讨论:


在这些回答中可以看到大部分同学都持有“按照特定需求切分”“有一定的意义”等想法,并未提炼出标准解决答案.在本篇论文开头作者引用了twitter中的一个回答:

博主的大概意思是,token是人造的概念.在自然语言处理技术的研究中,NLP模型默认被认为文是本被分割成小块,然后输入计算机,最终只是一个整数序列的过程。而在Webster和Kit(1992)[1]提出将这些所谓的“小块”称为连续子字符串-token,token这个概念才正式出现。
1.0时代 token=word的近似
在早期的的认知中,token应该是语义上的切割单位,文本数据传统上被分割为“句子”和“单词”。
这些宏观单位再被分割成微观原子单位,而这些微观单位的定义既要承接语言注释(如词性标记、形态句法注释、句法依赖信息等),也是需承接语言动机,包括缩略词(don't)、复合词(如法语copier-coller)、形态衍生词(如英语或法语antiTrump),以及众多的命名实体类、遵循特定类型语法的其他序列(如数字、url)。
MAF(Morphological Annotation Framework,MAF定义的ISO标准)定义token为“non-empty contiguous sequence of graphemes or phonemes in a document”-文档中字素或音素的非空连续序列,在通常的处理方式是用空格切分。
近年来,基于神经语言模型的方法进一步导致了句子如何被分割成原子单位的进化。
这种进化使得利用Tokenization任务将文本分割为“non-typographically (and indeed non-linguistically) motivated units”,即原来的token变为pre-token,原来的tokenization变为pre-tokenization,常见的工具Moses的tokenizer、Hugging Facede Tokenizers package。
2.0时代 token=subword
在神经网络的时代基于单词级别的模型虽然简单容易理解上手,但是它们无法处理罕见和新奇的单词(在训练中罕见、或者未出现词汇,out- vocabularyOOV)——即可以视为封闭的词汇模型。
在训练时,历史上罕见的单词类型被替换为一个新的单词类型[UNK],任何不属于模型原来封闭词汇表的令牌都替换为[UNK]。这种方法会有很多问题,无法胜任NLG任务等。
除此之外,形态不同意思相近的词在词表中这些词会被当作不同的词处理使得训练冗余。在解决怎么样在有限词汇表下有效地处理无限词汇的问题,研究者们启用更小、更细致的单位来代表存在以上问题的原来的word的单位。
subword tokenization最于常见的词不做处理仍然取word,将稀有单词分割为具有含义的子词单词语(subword)。
例如:unfriendly分解为un-friendly-ly,这些单位都是有意义的单位,un的意思是相反的,friend是一个名词,ly则变成副词。在文本的第六章,作者简要的介绍了几大subwords的常用算法:BPE、WordPiece、UnigramLM。
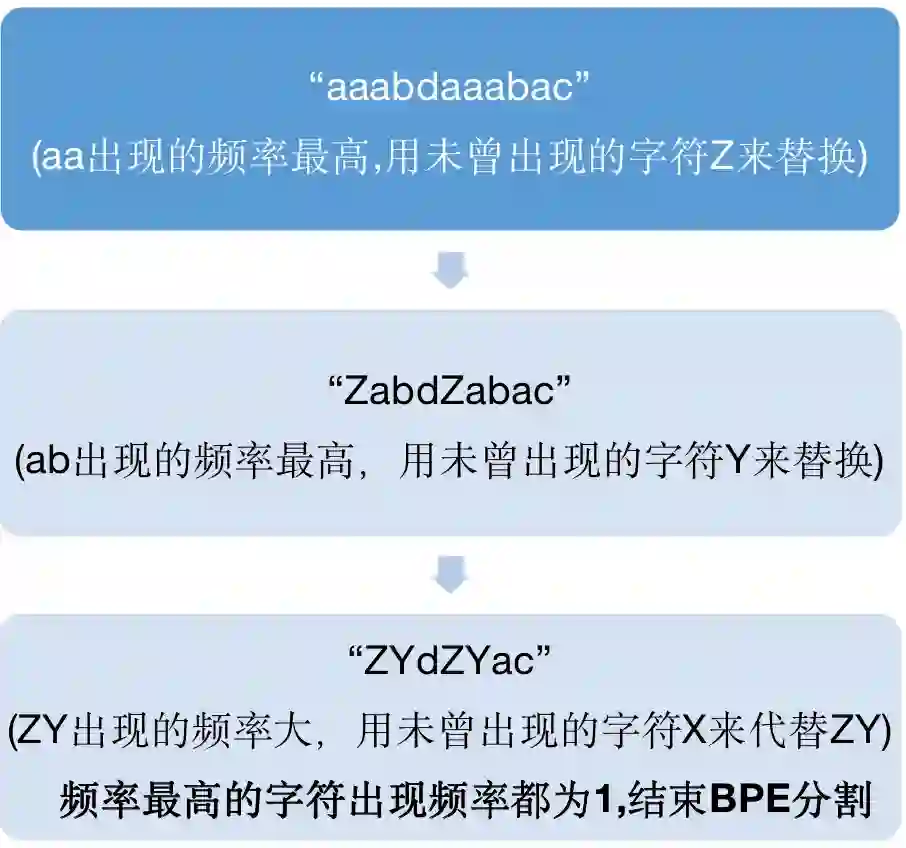
作者论述最为核心的算法即为- Byte Pair Encoding(BPE),算法来源自《Neural Machine Translation of Rare Words with Subword Units》[3]这篇论文,将字节对编码(BPE)(Gage,1994)压缩算法,应用于分词任务,将编码或二元编码是一种简单的数据压缩形式,其中最常见的一对连续字节数据被替换为该数据中不存在的字节。
算法步骤:
(1)准备足够大的训练语料
(2)确定期望的subword词表大小
(3)将单词拆分为字符序列并在末尾添加后缀“ </ w>”,统计单词频率。本阶段的subword的粒度是字符。例如,“ low”的频率为5,那么我们将其改写为“ l o w </ w>”:5
(4)统计每一个连续字节对的出现频率,选择最高频者合并成新的subword
(5)重复第4步直到达到第2步设定的subword词表大小或下一个最高频的字节对出现频率为1
停止符""的意义在于表示subword是词后缀。举例来说:"st"字词不加""可以出现在词首如"st ar",加了""表明改字词位于词尾,如"wide st",二者意义截然不同。每次合并后词表可能出现3种变化:
+1,表明加入合并后的新字词,同时原来在2个子词还保留(2个字词不是完全同时连续出现)
+0,表明加入合并后的新字词,同时原来2个子词中一个保留,一个被消解(一个字词完全随着另一个字词的出现而紧跟着出现)
-1,表明加入合并后的新字词,同时原来2个子词都被消解(2个字词同时连续出现)
通过以上步骤得到了subword的词表,对该词表按照subword长度由大到小排序。编码时,对于每个单词,遍历排好序的子词词表寻找是否有token是当前单词的子字符串,如果有,则该token是表示单词的tokens之一。
从最长的token迭代到最短的token,尝试将每个单词中的子字符串替换为token。最终,将所有子字符串替换为tokens,对仍然没被替换的子字符串情况,则将剩余的子词替换为特殊token,如
实际上,随着合并的次数增加,词表大小通常先增加后减小。BPE允许通过可变长度字符序列的固定大小词汇表来表示一个开放的词汇表,使其成为一种非常适合神经网络模型的分词策略。后期使用时需要一个替换表来重建原始数据。OpenAI GPT-2 与Facebook RoBERTa均采用此方法构建subword vector.该可以有效地平衡词汇表大小和步数(编码句子所需的token数量)。但是基于贪婪和确定的符号替换,不能提供带概率的多个分片结果。
除此之外,作者还介绍了基于概率生成新的subword而不是下一最高频字节对的WordPiece、从词汇表中删除概率最低的项目的UnigramLM、允许已学习的单元跨越这些边界的SentencePiece.在一些研究者们的实验中我们可以看到,例如英、日语中BERT-style模型在NLP任务重Unigram比BPE分割效果更好,而在翻译方面的各项试验中BPE最为可靠.在种种不同角度的论证中,究竟是谁一骑绝尘C位出道,仍旧没有结论性的结果。
卖萌屋相关解读:《NLP Subword三大算法原理:BPE、WordPiece、ULM》
在本章的末尾作者还有一个问题:
How many units do we need?
我们为了获得最佳性能,应该选择多少次merge?在这个问题上研究者们也各持一词,如由于神经机器翻译模型的输出是有频率偏差的,为保持一个更均匀的频率分布是更好的,合并尽可能缩短整个序列的长度而确保95%的subword单位出现至少100次(大概在训练数据),因此在这个问题上,现有的结论仍是表现最好的数字可能取决于任务和领域,并因语言而异。
3.0时代 tokenization-free
作者在本章中提出,如果我们一直依赖于一个预定义word(pretokenization output)概念,在没有这样的定义、或者无法获得、不需要该怎么办,有没有一种方法可以 let our data-driven machine learning approach also learn the tokenization? 因此,在这章中,作者介绍了各种技术来生成不同大小、质量的units。在这里作者做了几大热门选项的分析:
(1) Characters?
研究者们认为word或sub-word级标记序列在噪声存在时将发生显著变化,从而character模型对噪声和非分布数据更有鲁棒性。但是限制采用字符级模型的一个主要因素是,字符序列往往比它们的字级或子字级的对应字符长得多,这使得训练和推理变慢。为了提高训练速度和效率,Libovický、Chung、Cherry等人评估了各种策略和实验,但是它们都没有提供性能和速度的适当权衡。
(2)Character hashes?
在多语言环境中,使用字符级模型会导致非常大的词汇量。不给每个字符自己的embedding,而是用多个哈希函数将所有可能的代码点散列到更小的集合中,以便在代码点之间共享参数,以获得合理的计算效率,并专注于非生成序列标记任务。
(3)Bytes?
避免字符级模型词汇量过大问题的另一种方法是使用UTF-8等标准编码产生的字节序列来表示文本。这可以看作是使用了由标准团体(Unicode联盟)创建的固定的标记化方案,而不是基于语言或统计信息的过程。
具体使用Unicode字节的主要优势是遵循“建模数据中最小有意义单位的原则”时,字节级建模是一种自然选择,ByT5最近的研究表明,字节级模型与字符级模型具有类似的好处(对噪声有更好的鲁棒性,避免词汇量不足等问题),但也有类似的缺点(由于序列较长,训练和推理时间较长)。
(4)Visual featurization: Pixels?
另一种 “tokenization-free” 的建模方式是基于视觉概念,字节级模型的目标是覆盖磁盘上所表示的全部底层“词汇”,而视觉表示的目标是编码人类读者在处理文本时可能使用的字符之间的相似性。
字节级模型依赖于一致的观察序列,这使得它们容易受到变化和噪声的影响,这些可能会在视觉上呈现相似的效果,而使用视觉特征的最初动机是创造反映共享字符组件的嵌入,如汉字或韩语,因此能够更好地概括罕见的或不可见的字符,直接从像素分解进行转换这种模型在机器翻译的各种语言和脚本上都具有竞争力,而且对诱导噪声具有更强的鲁棒性。
总结
作者在结尾引用了一句话:
“It remains to find effective neural architectures for learning the set of entities jointly with the rest of the neural model, and for generalising such methods from the level of character strings to higher levels of representation”
Tokenization,无论是分词的演进过程还是术语的含义本身都随着研究者的深耕有了显著的发展。这篇论文追踪了它们的进化,并展现了多年来研究者们一步步尝试,立足于不同的motivation带来的的重大变化。
我们从论文中的介绍可以看到,尽管tokenization有了重大的进步,但是知道现在还没有完美的方法,所有选项都有缺点和优点,这片希望之乡还很遥远。“仍然需要找到有效的神经架构,以便与神经模型的其余部分一起学习实体集,并将这些方法从字符串级别推广到更高级别的表示”。
萌屋作者:付奶茶
新媒体交叉学科在读Phd,卖萌屋十级粉丝修炼上任小编,目前深耕多模态,希望可以和大家一起认真科研,快乐生活!
作品推荐
 萌屋作者:付奶茶
萌屋作者:付奶茶
后台回复关键词【入群】
加入卖萌屋NLP/IR/Rec与求职讨论群
后台回复关键词【顶会】
获取ACL、CIKM等各大顶会论文集!
![]()
[1] Tokenization as the initial phase in NLP.https://www.researchgate.net/publication/221102283_Tokenization_as_the_initial_phase_in_NLP
[2] https://jishuin.proginn.com/p/763bfbd34ee4
[3] Neural Machine Translation of Rare Words with Subword Units.https://aclanthology.org/P16-1162/
 后台回复关键词【
后台回复关键词【