杜克大学陈怡然:高效人工智能系统的软硬件协同设计
不久之前,杜克大学电子计算机工程系教授陈怡然发表了主题演讲《高效人工智能系统的软硬件协同设计》,介绍了如何软硬协同设计出高性能的人工智能系统,包括存内计算深度学习加速器、模型方面的优化,分布式训练系统以及一些涉及自动化操作等内容。

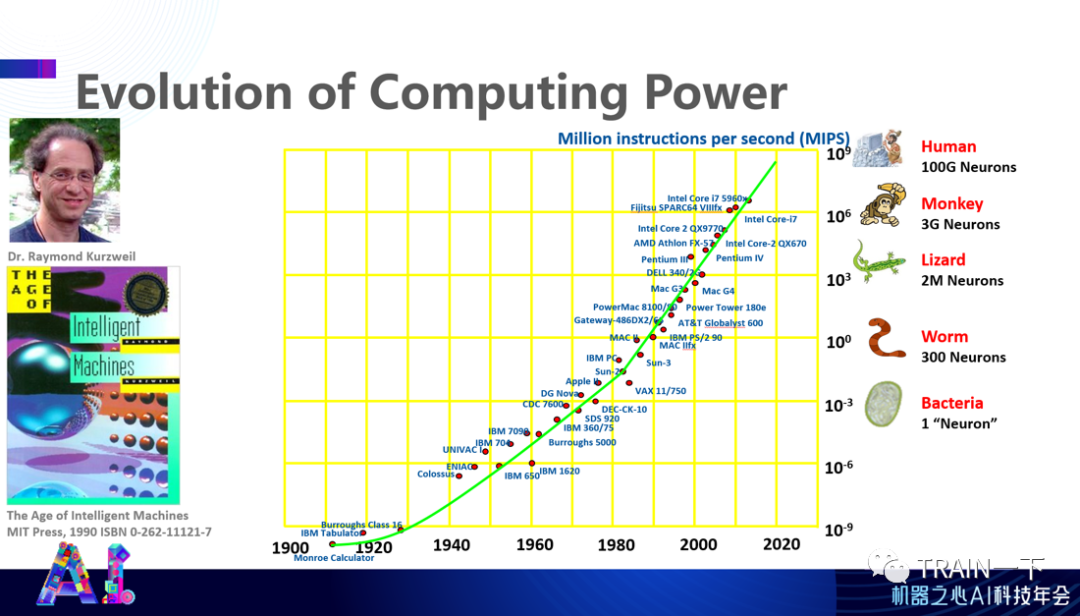

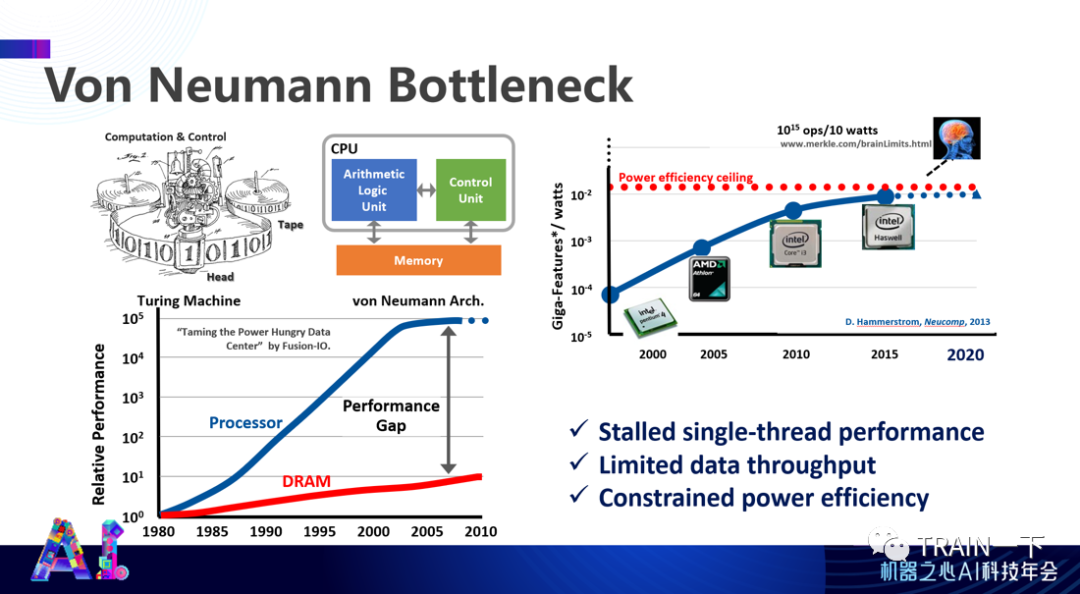
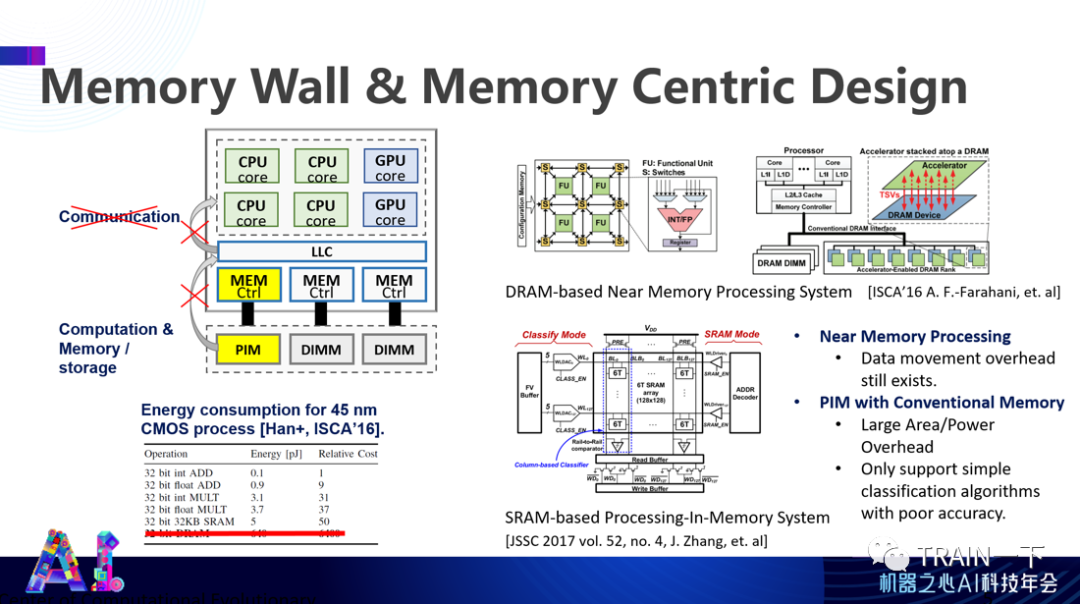
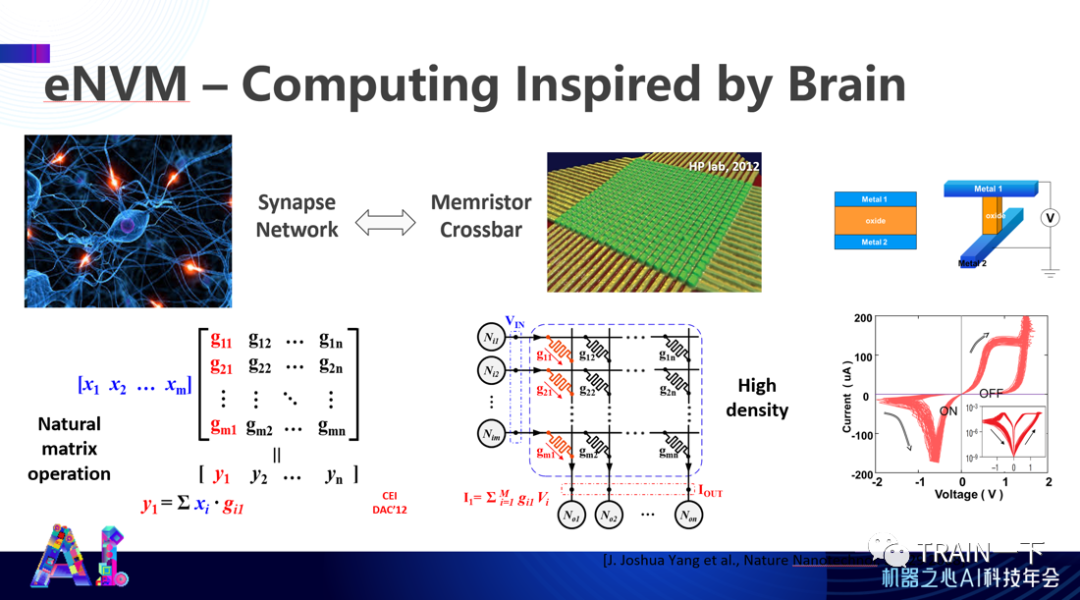

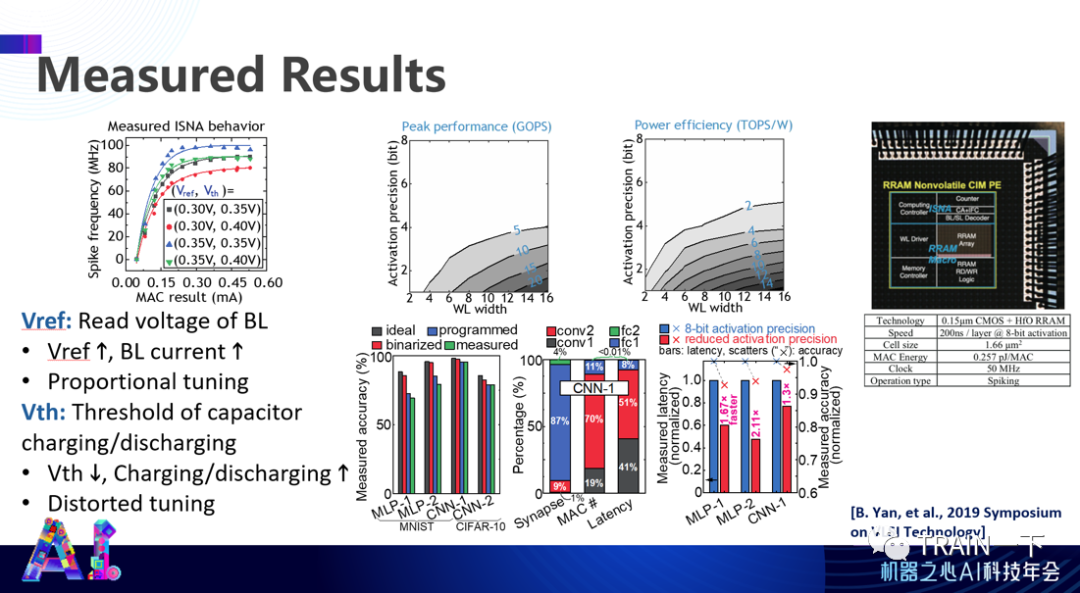
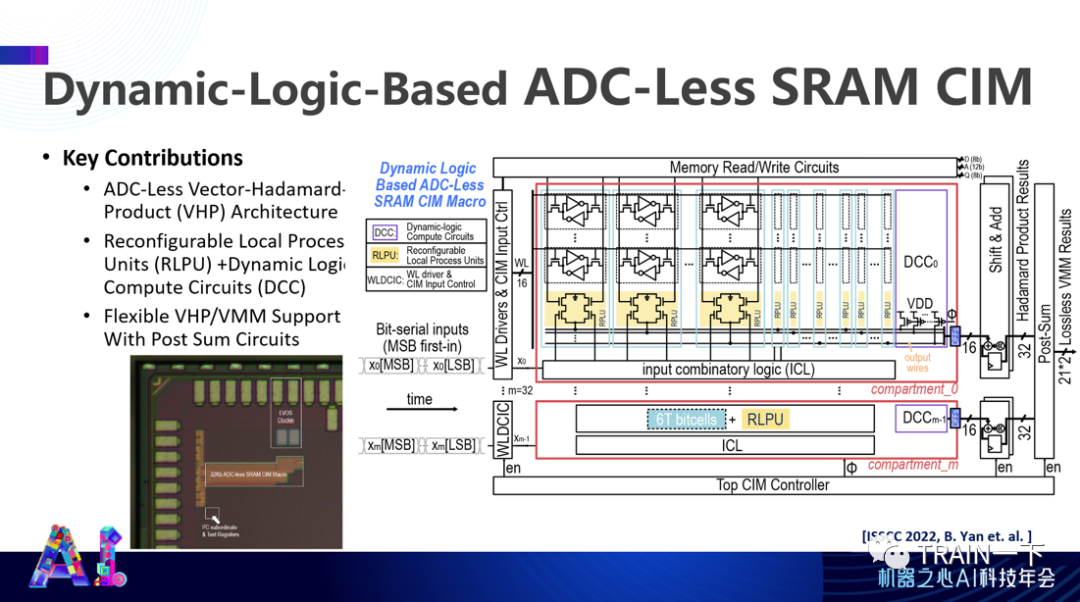
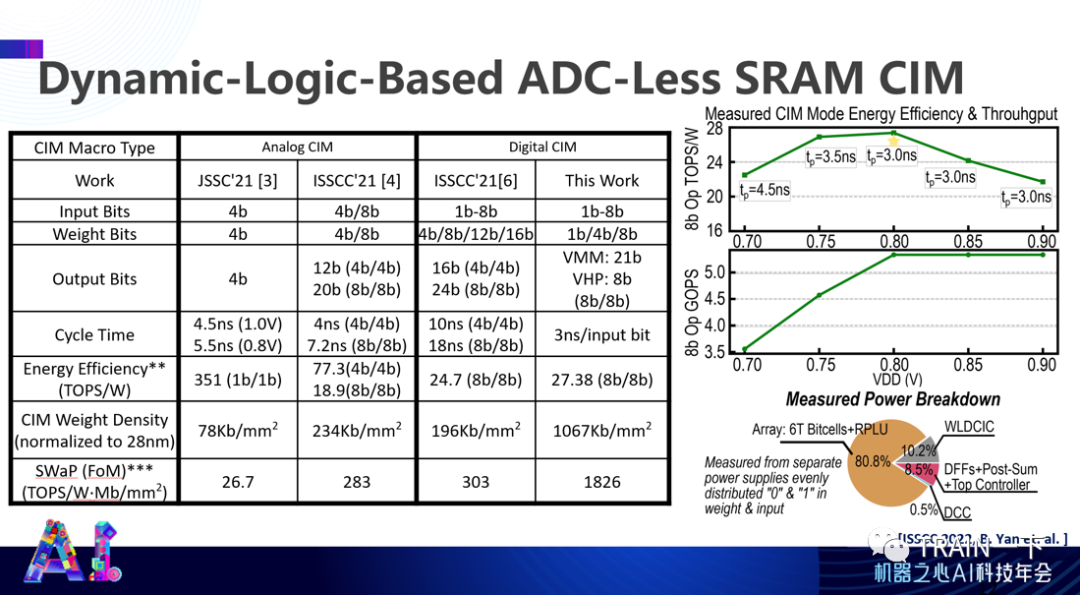
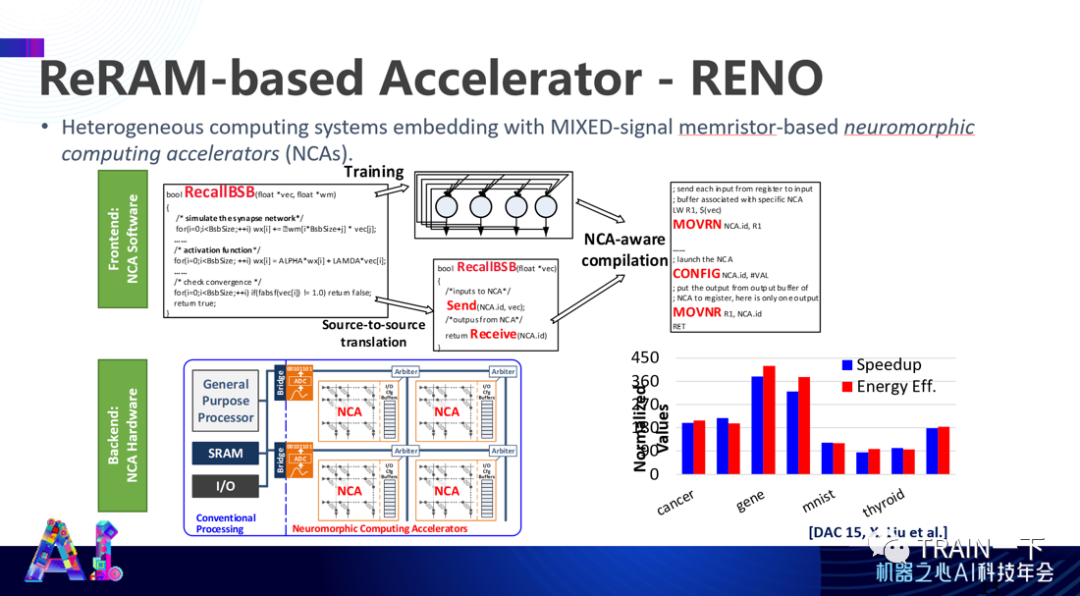
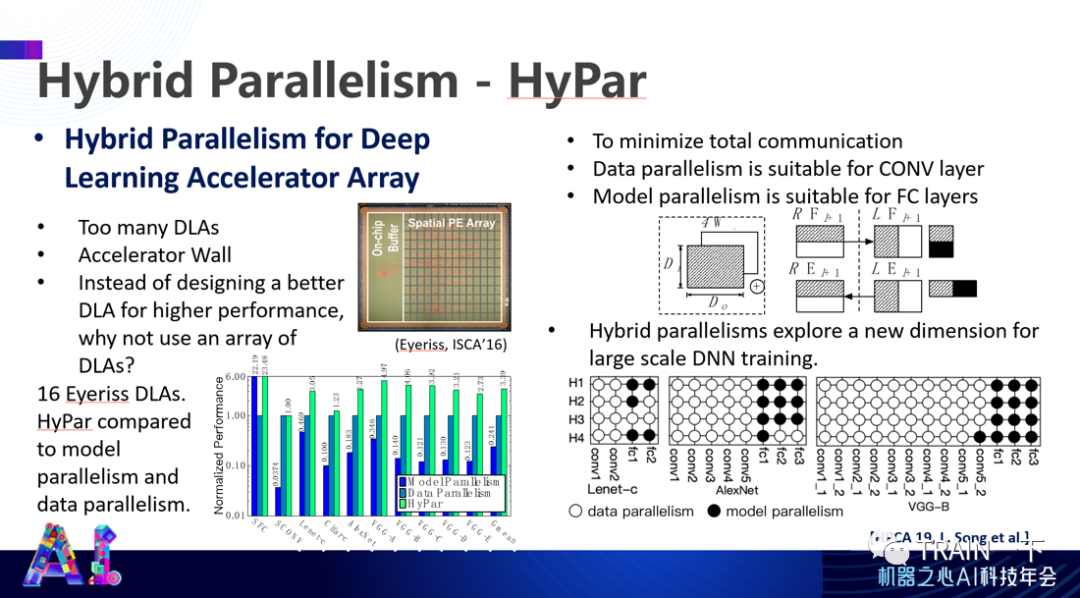
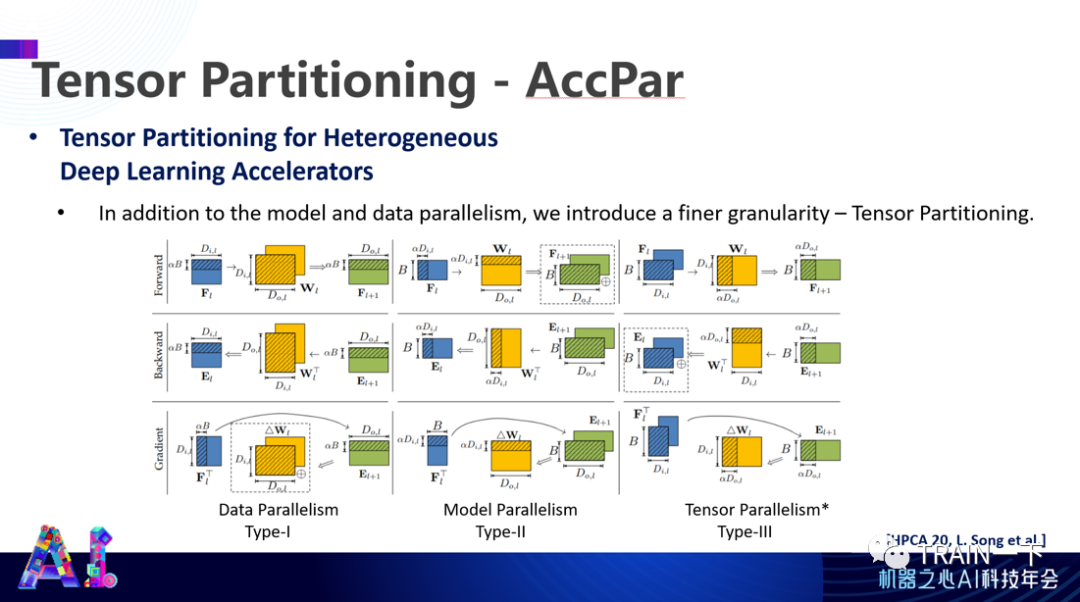
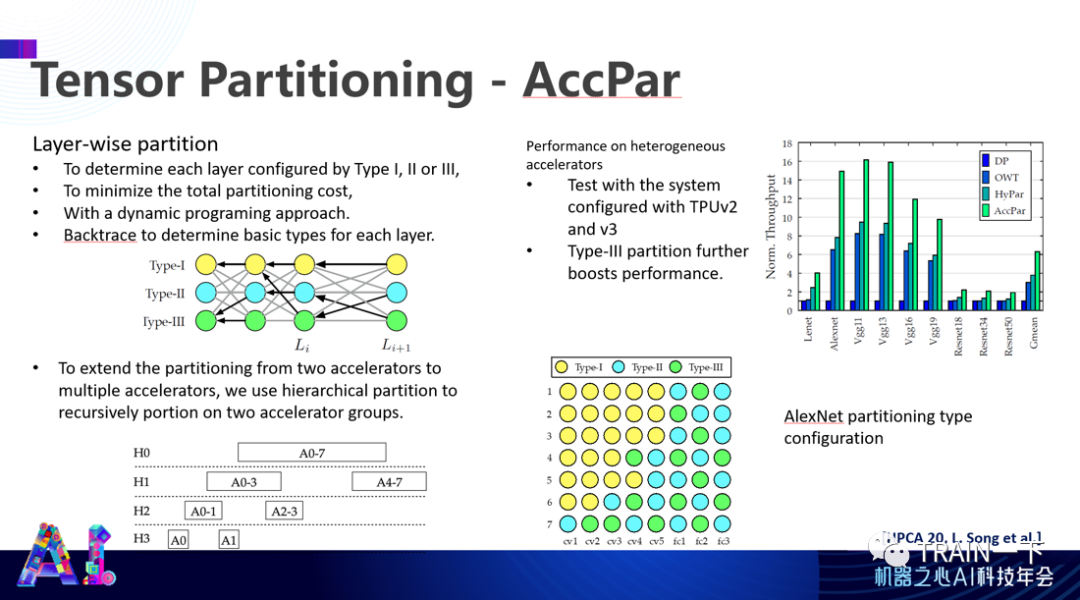
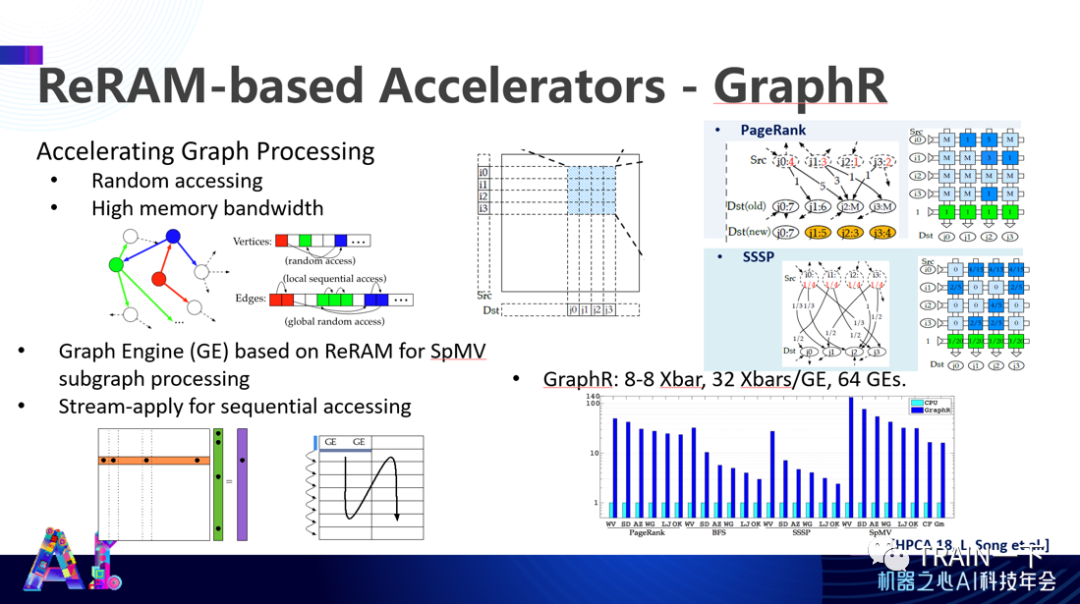




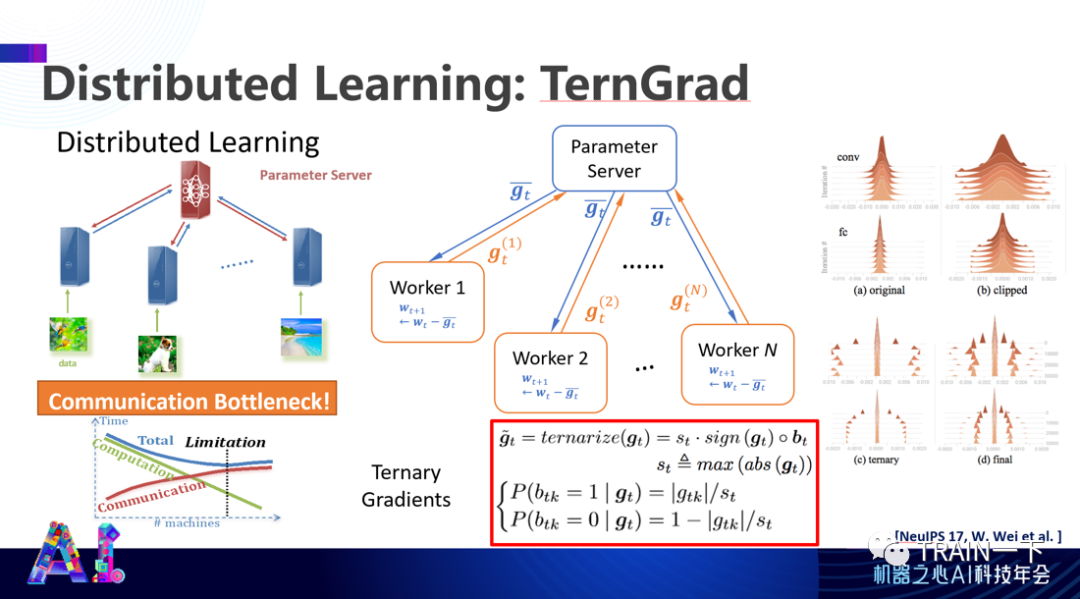
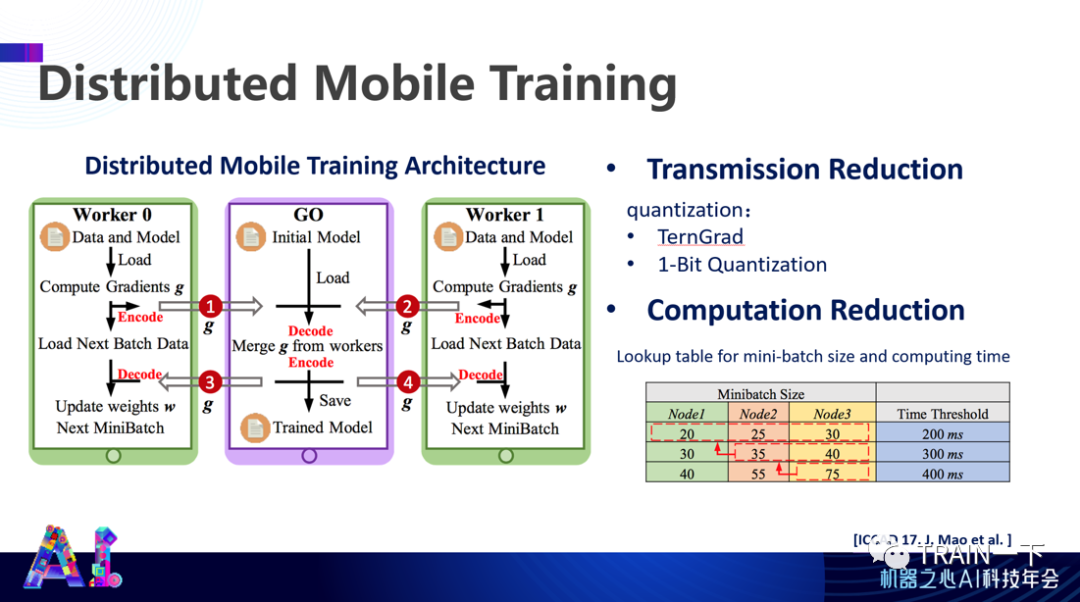

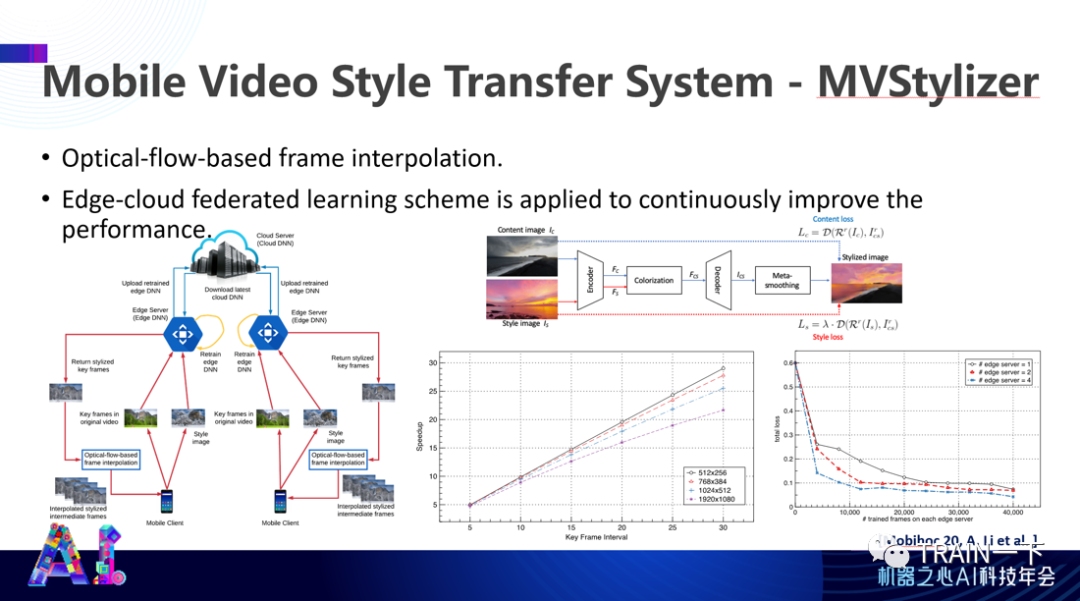
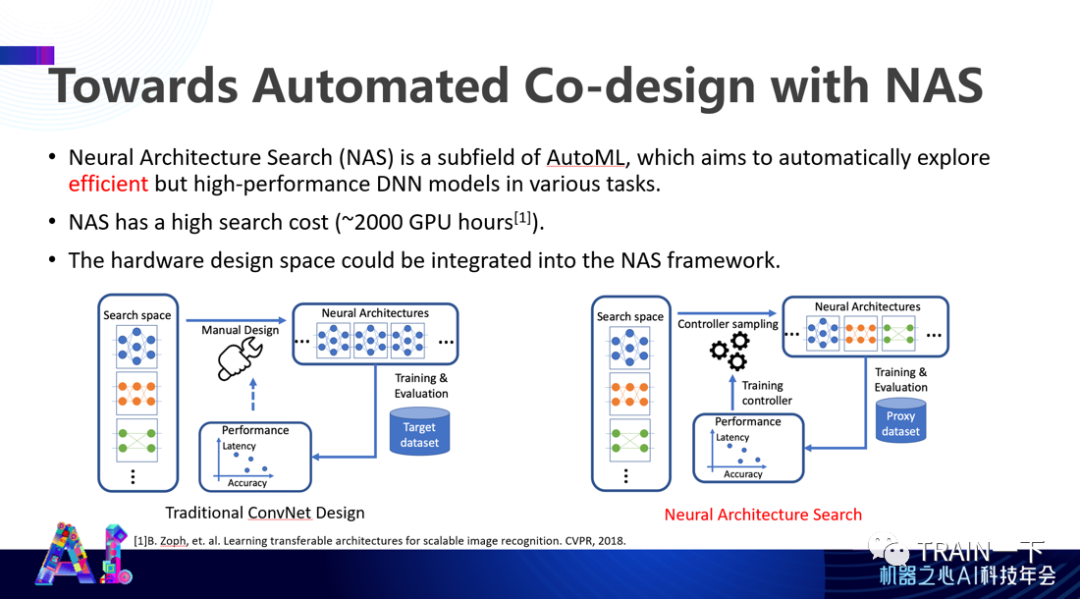
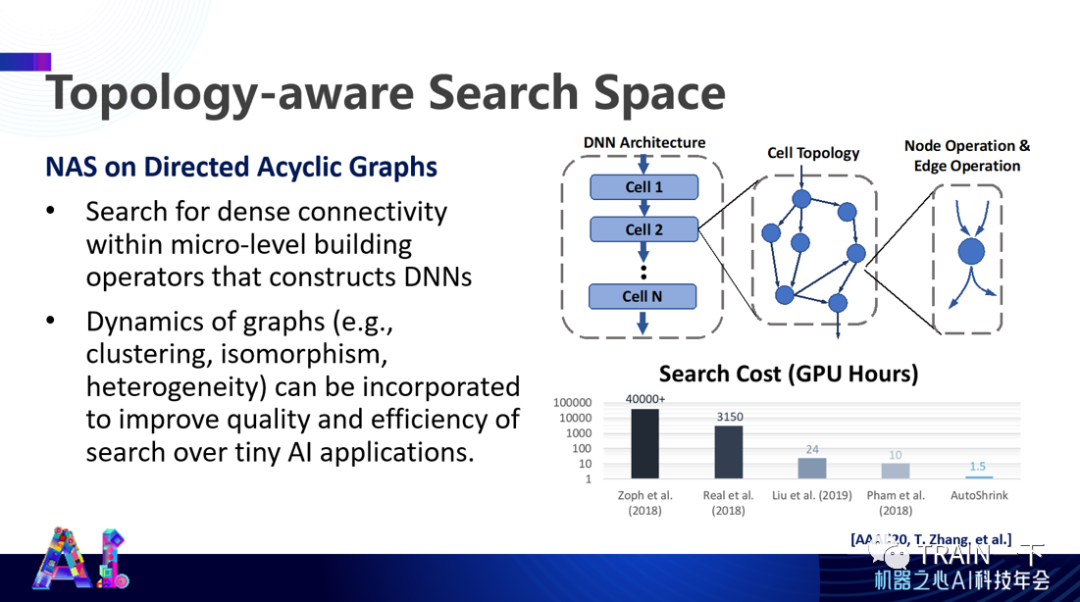
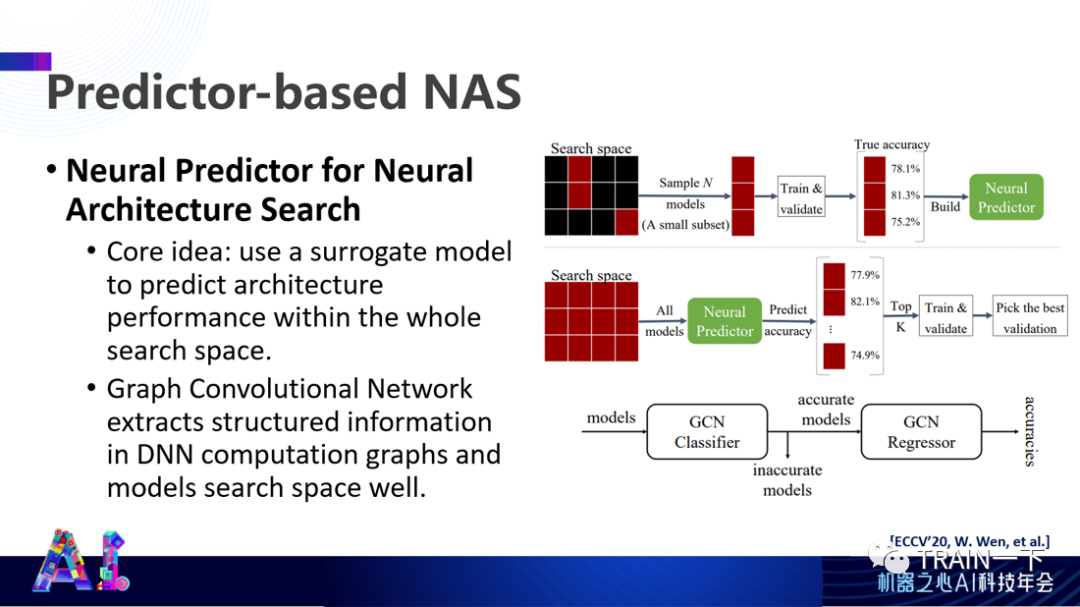
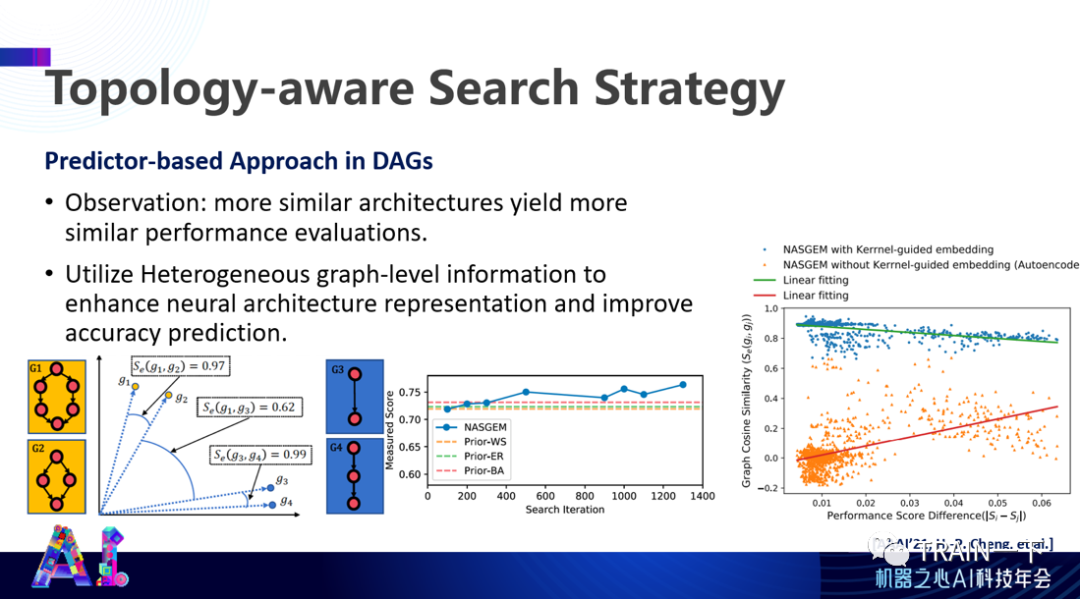
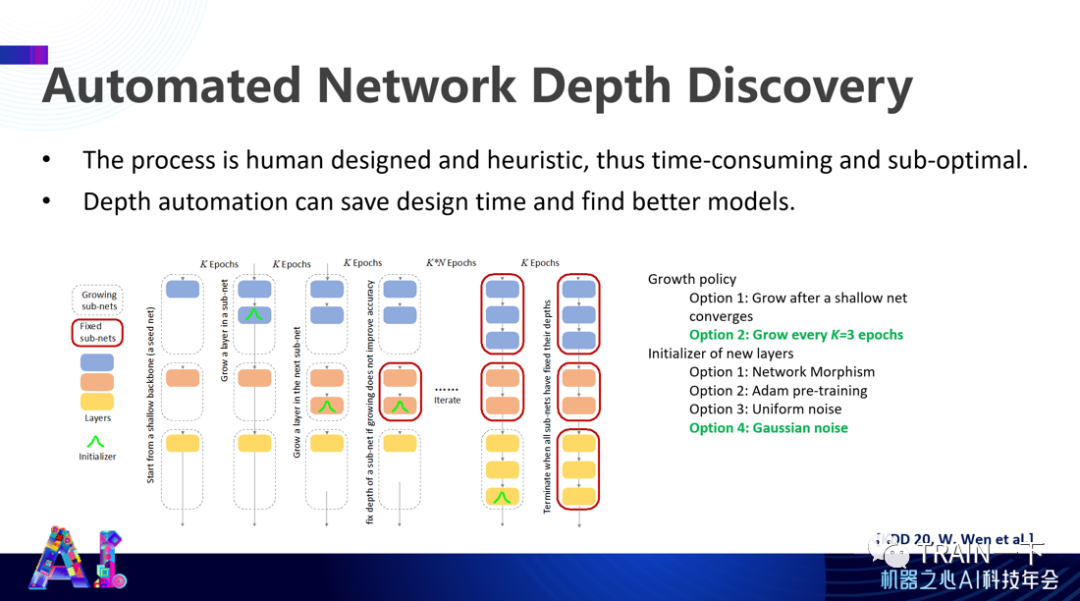

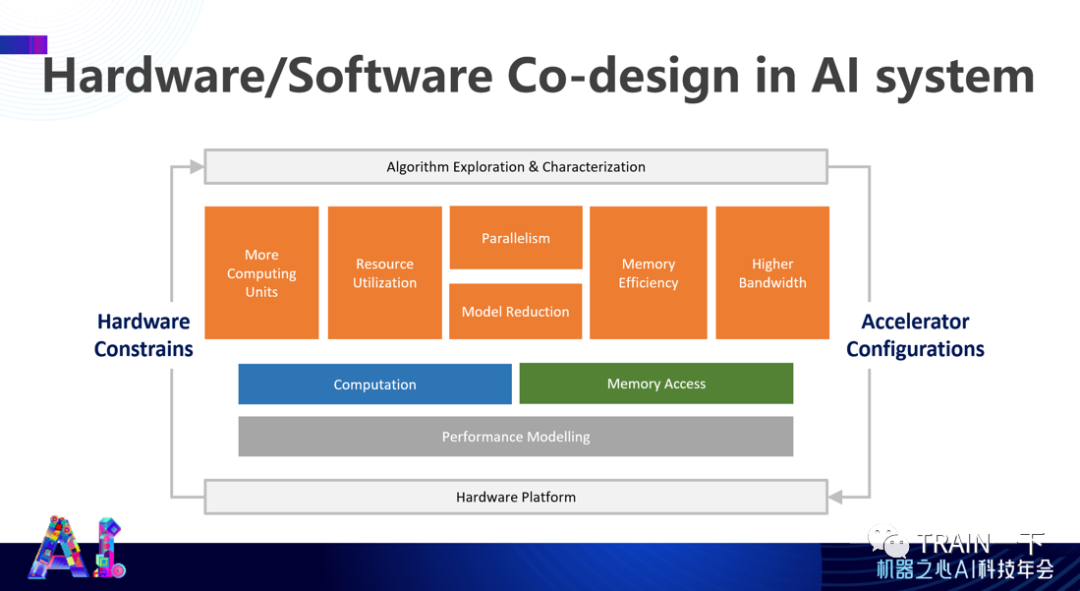
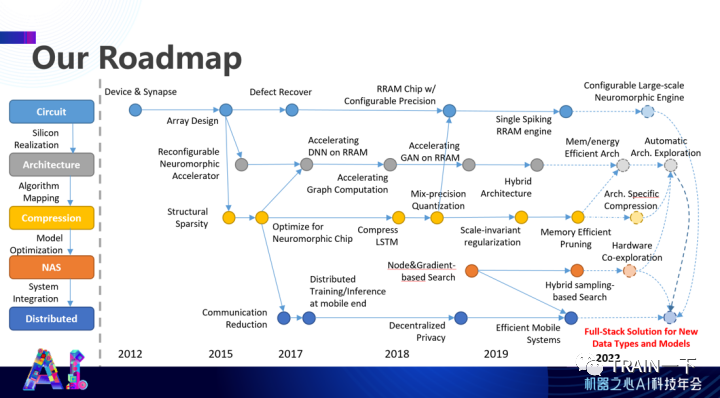
登录查看更多
相关内容

Arxiv
0+阅读 · 2022年6月13日
Arxiv
18+阅读 · 2021年1月28日
Arxiv
13+阅读 · 2018年1月18日


相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2022年6月13日
Arxiv
18+阅读 · 2021年1月28日
Arxiv
13+阅读 · 2018年1月18日