手把手丨输验证码输到崩溃?教你15分钟黑掉全球最流行的验证码插件

大数据文摘作品
编译:Katrine Ren、朝夕、钱天培
验证码这种东西真的是反人类。虽然它在保证账号安全、反作弊以及反广告有着至关重要的作用,但对于普通用户来说,输验证码很多时候实在是让人抓狂。
文摘菌18岁的时候帮朋友刷QQ空间留言就天天和验证码作斗争,前几天传一个视频又创下了连续7次输错验证码的记录。不过好在文摘菌最近发现,用机器学习破解简单验证码已经是妥妥的小事了。
今天,文摘菌就带来了一个15分钟黑掉世界上最受欢迎的验证码插件的小教程。欢迎开启新年第一黑。
先给大家介绍一下今天我们要黑的验证码插件。在Wordpress官网的插件注册页面(https://wordpress.org/plugins/)搜索“captcha”,返回的第一条结果“Really Simple CAPTCHA”就是今天我们要开刀的插件了。
由于这个插件是开源的,我们可以用它的源代码任意生成我们训练需要的验证码图片了。为了让这件事更有一点挑战性,我们不如给自己设定一个问题解决的时间限制——就15分钟吧!
插播:我绝对没有任何批评“Really Simple CAPTCHA”这个插件或它的作者的意思。这个插件的作者本人也承认这个插件已难以保证安全性了,并建议大家使用别的方法。本文只是在单纯地阐述一个有趣而快捷的技能挑战。然而,如果你正好是这个插件的100万多个用户里的一个,可能你是时候换个别的工具了。
热身准备
为了制定一个作战计划,让我们先来看看“Really Simple CAPTCHA”这个插件能够生成的是什么类型的图片吧。

好吧,看来这是个由4个字母组成的验证图片。让我们核实一下它的PHP源代码:
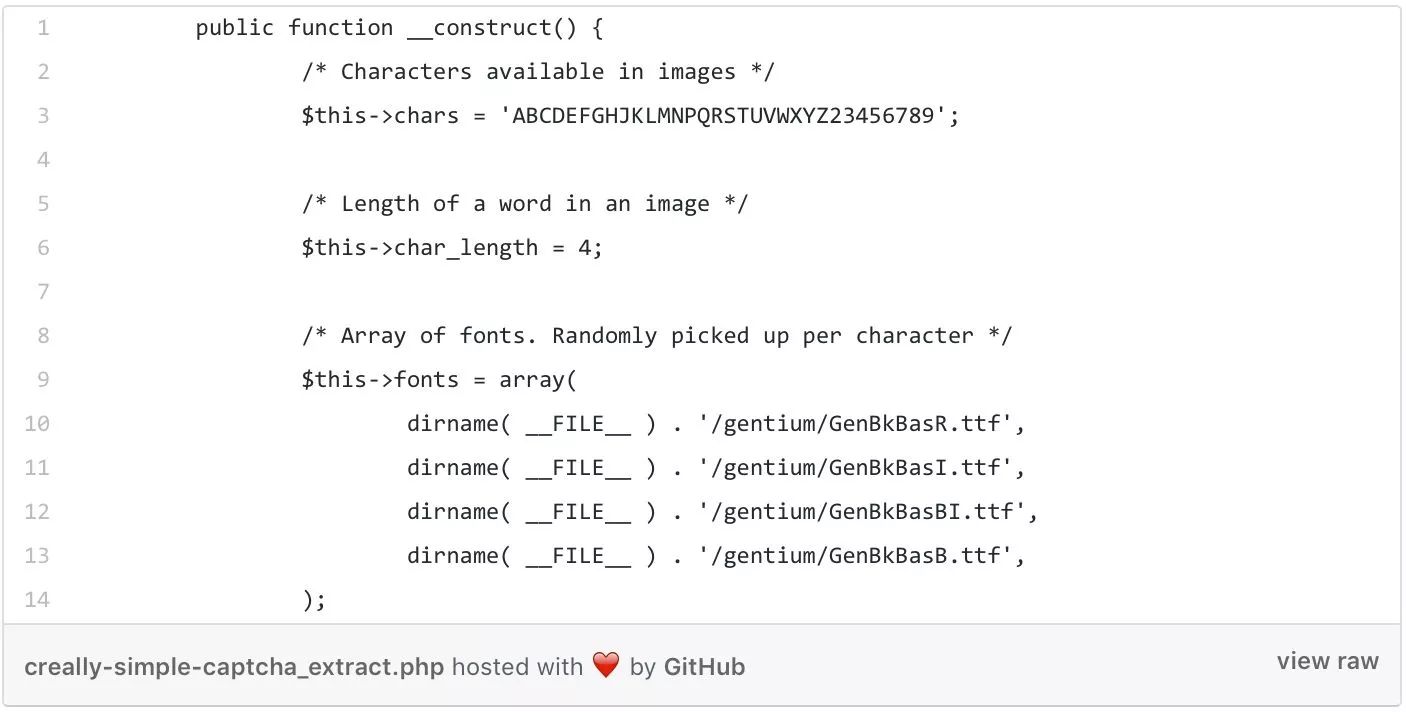
没错,它用了任意混合4种不同的字体的方式来生成了4个字符的验证码。我们可以看到,这个系统为了避免用户混淆字母和数字,在代码中设定了从来不使用O和I这两个字母。所以算下来我们需要识别的字母和数字共有32个。
目前用时:2分钟。
工具一览
工欲善其事,必先利其器。要解决我们的问题,我们需要用到以下工具:
Python 3
Python有很多机器学习和计算机视觉库可以调用。
OpenCV
OpenCV是一个目前流行的用于计算机视觉和图像处理的框架,我们需要用到它去处理CAPTCHA验证码图像。这个框架拥有Python API,因此我们可以直接使用Python调用它。
Keras
Keras是一个用Python编写的深度学习框架,它使用极少的代码就可以简单地实现对深度神经网络的定义、训练和应用。
TensorFlow
TensorFlow是谷歌的机器学习库。虽然我们将会在Keras中编码,但Keras自己实际上并不会执行神经网络的逻辑,而是背地里把所有的脏活累活都丢给谷歌的TensorFlow机器学习库去处理。
好了,说完工具,让我们回到挑战本身吧。
创建数据集
为了训练机器学习系统,我们首先需要训练数据。而为了破解CAPTCHA系统,我们需要的训练数据应该长这样:

由于我们已经有了WordPress插件的源代码了,因此我们只需要对其源代码小作改动,就可以得到10,000张验证码图片及其相对应的答案。
在花费了数分钟来捣腾代码并增加了一个简单的“for”循环之后,我得到了一个装满了训练数据的文件夹,里面有10,000个PNG格式的文件,文件名就是与之匹配的正确答案:

这是全文唯一一个我不会给你们示范代码的部分。我们在做的事情是出于学习和教育目的,并非真的要你们在现实中去黑掉WordPress的网站。不过,我将会给你们我在最后生成的那10,000张图片,以便你们可以复制我的结果。
目前用时:5分钟
简化问题
现在已经有了可用的训练数据,我们可以直接用这些数据去训练一个神经网络:
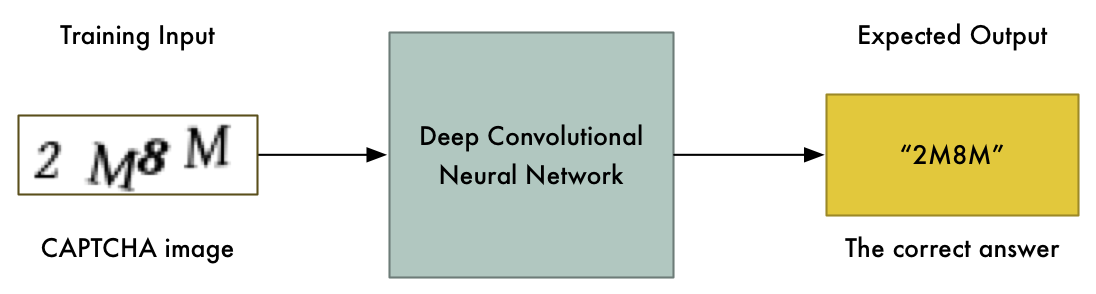
在训练数据足够多的情况下,这个方法应该是可行的,但我们还能把问题进一步简化。在仅有15分钟的情况下,问题越简单,我们所需要的训练数据和计算能力也就越少。
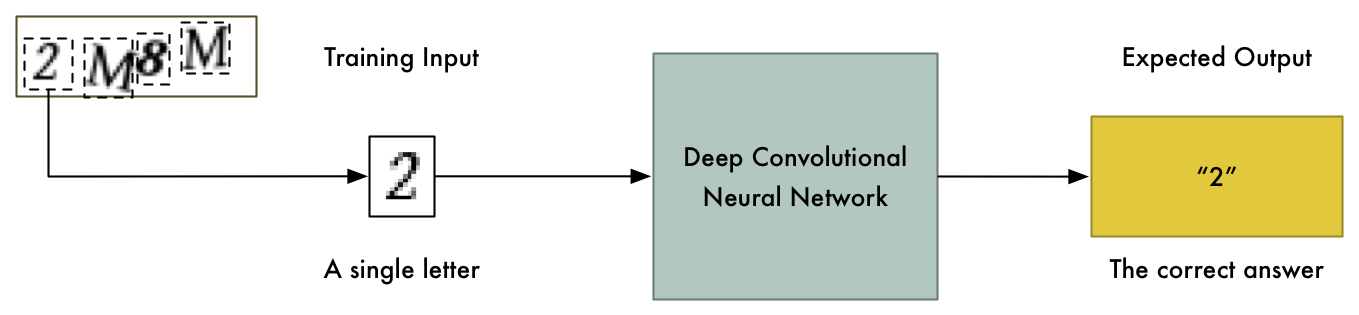
幸运的是这些CAPTCHA图片始终只有4个字母组成,如果我们能够把图片分割开让每个字母成为一张独立的图片,那么我们就可以训练神经网络让它逐个识别字母。
手动用PS分割图片显然是不现实的——我们现在只剩下10分钟了。同时,我们也无法把那些图像进行四等分的切割,因为CAPTCHA系统为了防止如下情况(如左侧动图),会随机地把字符放置在不同水平高度的位置上。
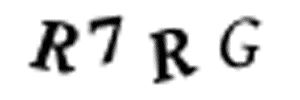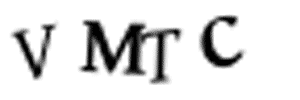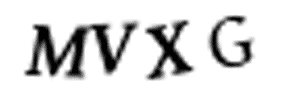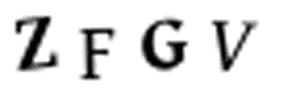
字符在每张图片中是随机放置的,使得分开这些字符变得略为困难
幸运的是,我们仍可以自动化实现这个过程。在图像处理的过程中,我们通常需要探测出那些颜色相同的像素“斑点”,而环绕这些连续的像素斑点的边界则被称为“轮廓线”。OpenCV恰好有一个自带的叫做findContours()的函数,可以用于检测那些连续的区域。
那么,我们首先从一张未经处理的CAPTCHA图片开始:
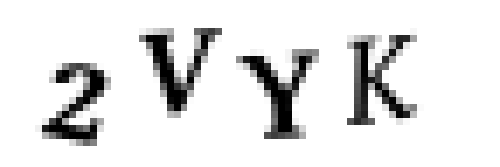
然后为了方便我们找到那些连续的区域,我们要将这种图片转化成纯粹的黑白图像(这个过程被称作二值化):
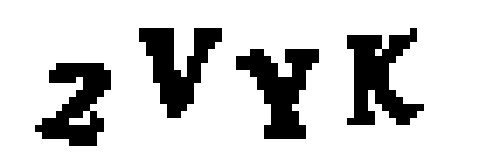
接下来,我们将要使用OpenCV的findContours()函数去检测出那些包含了连续且颜色相同的像素斑点的部分:
之后我们需要做的事情很简单,只要把每个区域作为独立的图像文件保存下来就好了。同时,因为我们已知每张图片包含了从左到右排列的四个字母,在保存每个字母图像的时候我们可以按照排列的顺序来进行标记。只要我们保存图片的顺序是无误的,那么我们就能够保证用正确的字母来标注每个图片。
但在这时,我突然发现了一个问题!这些验证码图片的字母有的时候是重叠在一起的:
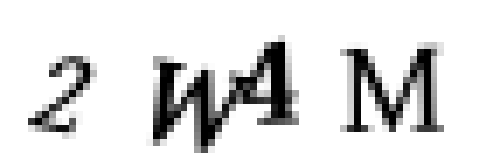
这意味着某些提取出来的图像,在一个独立的区域里实际上混合了两个字母:

如果我们不及时解决这个问题,那么我们生产出来的将是一堆劣质的训练数据。为了防止机器误以为这种由两个字母挤成一团的图像当成是一个字母,我们必须要修正这个问题。
这里有一个简单的小技巧:如果一个单独等高线内的区域的宽度远远大于它的高度,那么我们可以推测这个区域内可能有两个字母挤压在一起了。在这种情况下,我们可以直接把合并的字母对半切割并当作两个独立分开的字母:
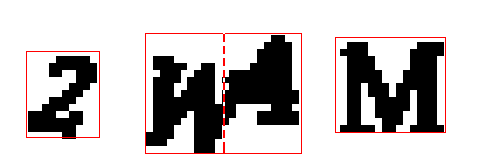
我们将会对半分开任何宽度远大于高度的区域,并将其按两个独立的字母来处理。这个技巧听起来有点不靠谱,但是应用在这些CAPTHCA验证码图片上的效果却很不错。
现在我们已经有了提取单独字母的方法了,接下来可以用来处理我们手头上所有的CAPTCHA验证码图片了。我们的目标是收集每个字母的不同变体,并且把这些变体统一整理归类在其所属字母的文件夹里。
下面这张图展示的就是我在对所有图片进行字母提取之后装着所有“W”的文件夹:

其中有些“W”字母是从那10,000 CAPCHA图片中提取出来的,我最后得到了1,147个不同的“W”图像。
目前用时:10分钟
训练神经网络
由于我们只需要辨识单个字母和数字的图片,我们不需要用到非常复杂的神经网络结构,毕竟辨识字符要比辨识一些如小猫小狗之类的较复杂的图片简单得多了。
我们将要使用的是一个结构简单的卷积神经网络,里面有两个卷积层和两个完全连接的隐藏层和输出层:

如果大家想知道更多关于卷积神经网络如何运作,以及为什么它们是图像识别的理想方法,可以去看看这篇文章
(https://medium.com/@ageitgey/machine-learning-is-fun-part-3-deep-learning-and-convolutional-neural-networks-f40359318721)或者这本书
(https://www.pyimagesearch.com/deep-learning-computer-vision-python-book/)。定义这个神经网络结构只需要利用Keras来写上几行代码:
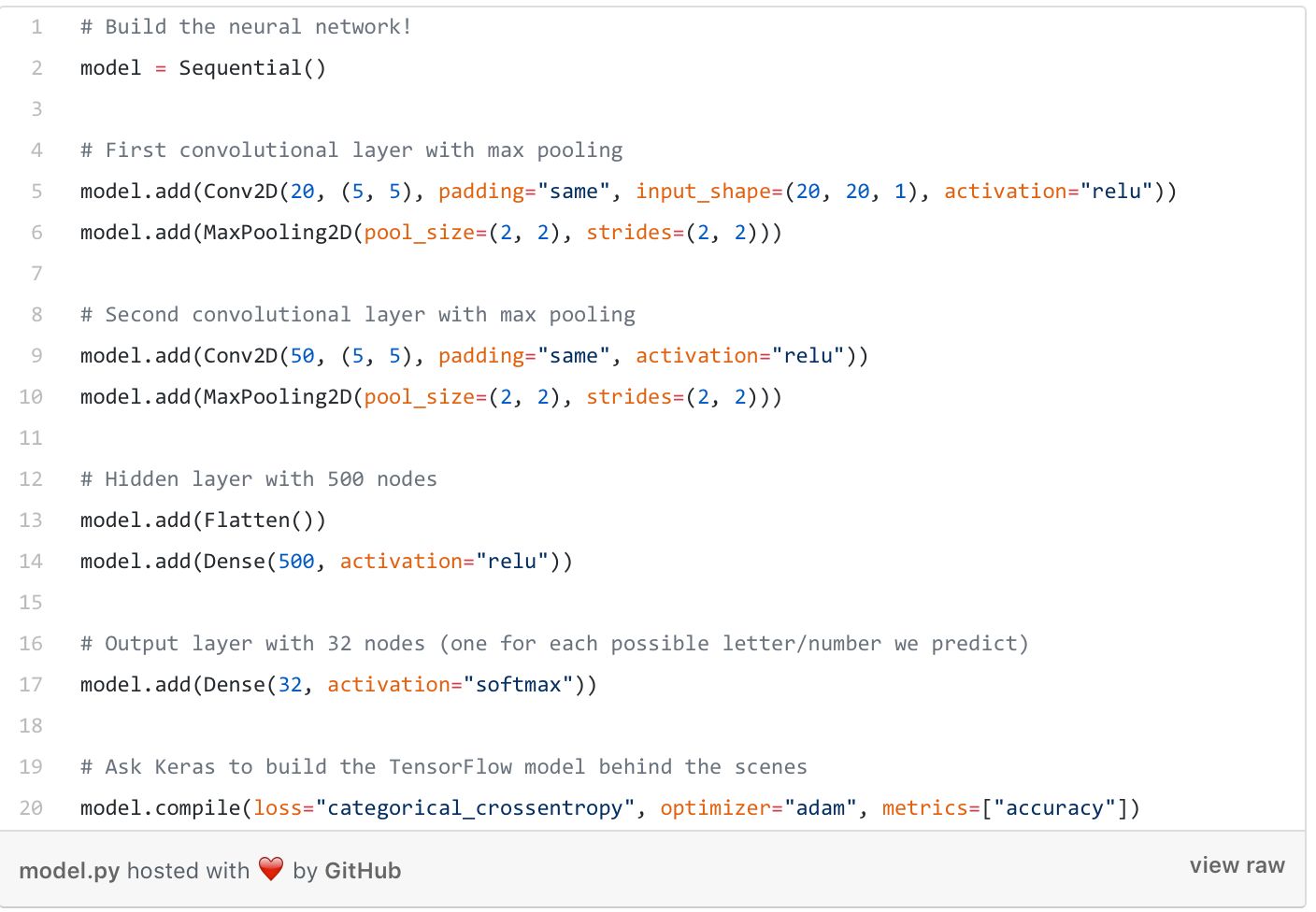
现在,我们可以进行训练了!

在对训练数据集进行了10个循环的训练之后,我们得到了几乎100%的准确率。这时候,我们应该就能够随时随地自动绕过这个CAPTCHA系统了!
目前用时:15分钟(哈!)
牛刀小试
好了,现在我们有一个已经训练好的神经网络模型了,接下来破解一个真正的CAPTCHA系统就相当简单了:
从一个网站上抓取一个使用WordPress插件的真实CAPTCHA图像。
利用我们刚刚创建训练数据集的方法,把一张CAPTCHA验证码图片分成四张独立的字符图片。
让我们的神经网络对每个字母图片进行预测。
将模型预测出的4个字符作为验证问题的答案。
新年第一黑完美收工!
我们最后得到的验证码破解系统长这样:

也可以用终端实现破解:
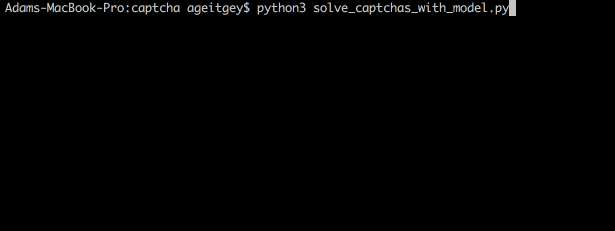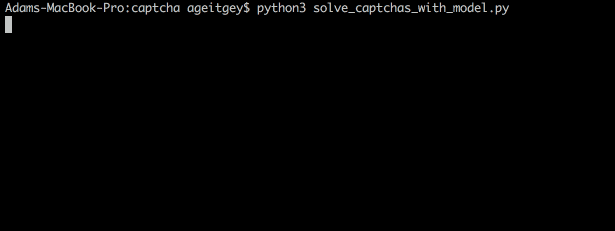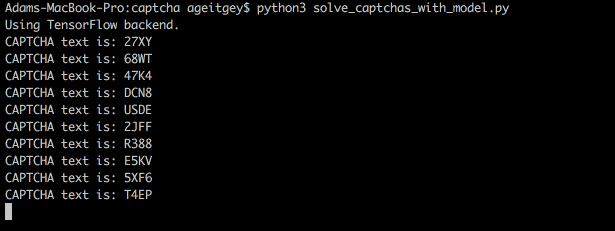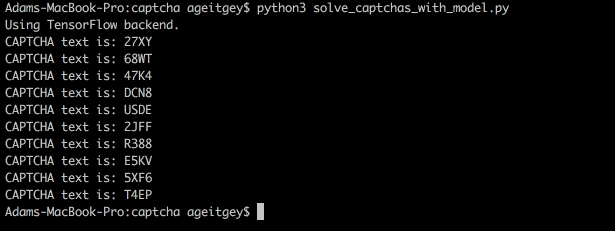
动手来试试吧!
这篇教程每个步骤设计的代码都保存在了这儿:
https://s3-us-west-2.amazonaws.com/mlif-example-code/solving_captchas_code_examples.zip
压缩包中的REAME文件说明了这些代码该如何运行。里面也包含了10,000训练样本图片。
简直不敢信,全球最流行的验证码就这么被我们黑掉了。不过也没啥好高兴的,毕竟面对下面这种验证插件,现在的AI是一点脾气也没有的。

原文链接:
https://medium.com/@ageitgey/how-to-break-a-captcha-system-in-15-minutes-with-machine-learning-dbebb035a710

志愿者介绍
回复“志愿者”加入我们



往期精彩文章
点击图片阅读
我不是修电脑的!新年餐桌上,如何让老妈搞懂自己的“技术”工作







