学界 | 词错率2.97%:云从科技刷新语音识别世界纪录
机器之心编辑
参与:淑婷、张倩、李泽南
10 月 29 日,云从科技宣布在语音识别技术上取得重大突破,在全球最大的开源语音识别数据集 Librispeech 上刷新了世界纪录,错词率(Worderrorrate,WER)降低至 2.97%。这一研究将 Librispeech 的 WER 指标提升了 25%,超过阿里、百度、约翰霍普金斯大学等公司和机构,刷新原记录。
云从表示,这已是云从在近半年以来第二次宣布刷新世界纪录。今年 4 月,云从科技跨镜追踪技术(ReID)技术在 Market-1501,DukeMTMC-reID,CUHK03 三个数据集刷新了世界纪录,其中最高在 Market-1501 上的首位命中率(Rank-1 Accuracy)达到 96.6%,让跨镜追踪技术(ReID)技术在准确率上首次达到商用水平。
据介绍,云从科技核心技术闭环包括人脸识别、智能感知与智能分析三个阶段。语音识别技术是智能感知的重要部分,通过语音识别,机器就可以像人类一样理解语言,进而能够展开处理,进行反馈。
近年来,在深度学习技术的帮助下,语音识别取得了很大进展,从实验室开始走向市场,走向实用化。基于语音识别技术的输入法、搜索和翻译等人机交互场景都有了广泛的应用。
Librispeech 是当前衡量语音识别技术的最权威主流的开源数据集,它是世界最大的免费语音识别数据库,包含文本和语音的有声读物数据集,由 1000 小时的多人朗读的清晰音频组成,且包含书籍的章节结构。错词率(Worderrorrate,WER)是衡量语音识别技术水平的核心指标。
在技术研究的「最后一英里」,每 0.1 个百分点的进步都异常艰难。云从科技在 Librispeech 数据集上刷新了业内最好的水平,将错词率(Worderrorrate,WER)降到了惊人的 2.97%,较之前提升了 25%,已超越人类专业速记员水平。该成果有望推动语音识别技术的大幅进步。
云从科技此次推出的语音识别模型 Pyramidal-FSMN 融合图像识别与语音识别的优势,将残差卷积网络和金字塔记忆模块的序列记忆网络相结合, 能够同时有效的提取空间和时间上不同粒度的信息,对比目前业界使用最为广泛的 LSTM 模型,训练速度更快、识别准确率更高。
Pyramidal-FSMN 语音识别模型原理解析
云从科技提出的新型网络结构,能更加有效的提取空间和时间特征的角度,为语音识别进一步发展提供了一些新的思路: 模型设计采用一种残差卷积网络和金字塔记忆模块的序列记忆网络相结合的结构;
训练方式使用 lattice-free 最大互信息(lattice-free maximum mutual information,LF-MMI/Chain)与交叉熵(crossentropy,CE)损失函数相结合的多任务学习技术;解码部分采取 RNNLM rescoring 的方式,利用 RNN 提取一个句子中的长期语义信息,从而更有效地帮助声学模型得到准确的句子。
作者采用了由 6 层 ResidualCNN 和 10 层 Pyramidal-FSMN 相结合的网络结构。前端网络借鉴了图像识别中经典的 Residual CNN 结构,更有效地提取特征与时间相互的关联信息,同时 skipconnection 避免了 CNN 网络加深之后梯度消失和梯度爆炸问题。在金字塔记忆模块中,浅层的网络主要聚焦于音素本身的特征学习,所以只需抽取短时上下文信息,而深层的网络由于已经学习到了足够的固定时间的音素信息,需要学习长时间包括语义和语法特征,所以深层抽取长时间的上下文信息。利用这样的金字塔结构,既能减少参数,缩小模型结构,也能更加精巧的模拟人类处理语音信号的过程,提高识别效果。
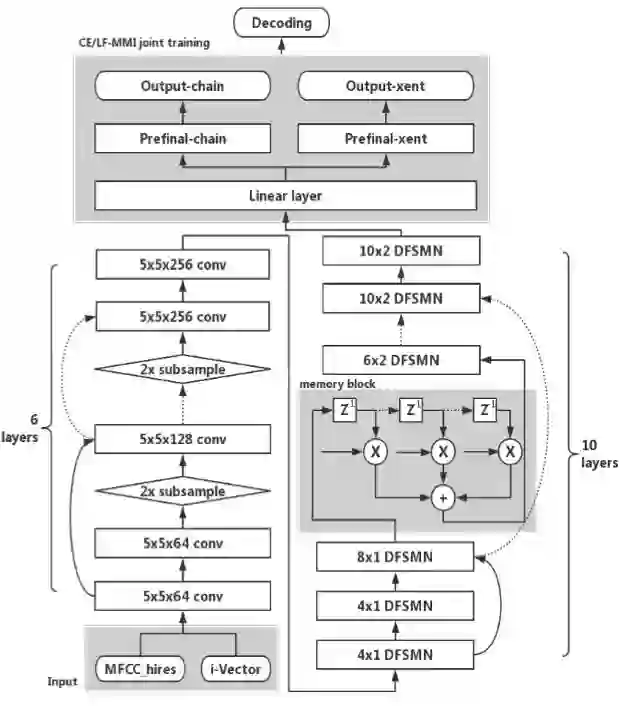
在损失函数部分,作者采用了基于 LF-MMI 的序列性训练方式。同时为了解决序列性训练容易导致过拟合的问题,又引入了传统的交叉熵损失函数,在 LF-MMI 输出之外加入另一个输出层作为一个正则技术,通过设置交叉熵的正则化系数,两个目标能够有效地学习并且避免过拟合问题。
最后,作者使用了 RNNLM rescoring 技术对解码做进一步处理。在没有 RNNLM rescoring 的情况下,Pyramidal-FSMN 已经达到了目前最好的结果,rescoring 之后又有了更进一步的提升。RNNLM 的训练数据完全基于通用的语言模型数据集,并没有额外引入其他的训练数据这样的「技巧」性策略。
论文:A NOVEL PYRAMIDAL-FSMN ARCHITECTURE WITH LATTICE-FREE MMI FOR SPEECH RECOGNITION

论文地址:https://arxiv.org/abs/1810.11352
论文介绍
近年来,除了 GMM-HMM 模型,深度神经网络(DNN)已经被用作大词汇量连续语音识别(LVCSR)系统的声学模型 [1, 2]。前馈神经网络(FNN)等早期研究 [3] 只将当前时间步作为输入。循环神经网络(RNN),尤其是长短期记忆网络(LSTM),凭借其循环连接 [4] 和序列信息的使用在语音识别任务中表现出了优异的性能。卷积神经网络(CNN)应用了局部连接、权重共享和池化等技术,性能也超越了之前的研究成果 [8, 9]。
然而,RNN 的训练依赖随时间的反向传播(BPTT)[10],可能因计算复杂而导致时间消耗过多、梯度消失或爆炸 [11] 等问题。教师强制(teacher forcing)或教授强制(professor forcing)训练可以在一定程度上解决该问题,但也会降低 RNN 的鲁棒性。最近有人提出了一个前馈序列记忆网络(FSMN)[14]。该网络可以在没有任何循环反馈的情况下建模长期关系。此外,为了构建非常深的神经网络架构,FSMN 还应用了残差连接 [15],这是对之前模型的巨大改进。与此同时,时延神经网络(TDNN)[16] 和分解的时延神经网络(TDNN-F)也大量应用了前馈网络。
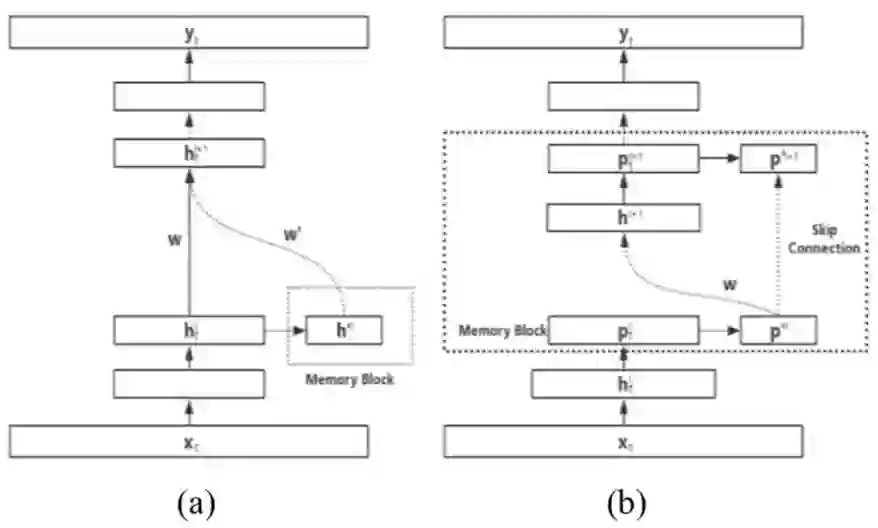
图 1:FSMN(a) 和 DFSMN(b) 架构。
传统的 DNN-HMM 混合声学模型是根据交叉熵标准训练的。由于语音识别是一个序列问题,在 CE 训练后应用了几个序列的判别训练标准,如最大互信息(MMI)[18],最小贝叶斯风险(MBR)[19] 和最小语音错误(MPE)[20]。受到 Connectionist Temporal Classification(CTC)在不同识别任务中的应用启发 [21, 22],我们开发了一种新的方法,称为 lattice-free MMI(LF-MMI/Chain model)[23]。该方法可以在没有任何 CE 初始化的情况下使用,因此需要的计算更少。
在本文中,我们提出了一种新的 CNN Pyramidal- FSMN(pFSMN)架构,该架构通过 LF-MMI 和交叉熵联合训练而得。金字塔架构被应用于记忆模块中。在该架构中,顶层包含较短的上下文信息,而深层包含较长的上下文信息,这采用了适当的时间依赖性,同时减少了参数量。除此之外,每隔几层添加一次残差连接。为了从原始的 Mel-Frequency Cepstral Coefficients(MFCCs)中提取更精确的特征,CNN 层被部署为前端。
云从科技的研究人员在不同的语音识别任务上评估了该架构的表现。在 300 小时的 Switchboard 语料库中,我们提出的架构实现了当前最低的错词率(WER),仅为 10.89%。而在 1000 小时的 Librispeech 语料库中,WER 为 3.62%。此外,在我们的实验中,RNN 语言模型(RNNLM)在解码和 rescoring 方面取得了进步,与传统的 N-gram 语言模型相比,该模型获得了 1% 以上的绝对改进。
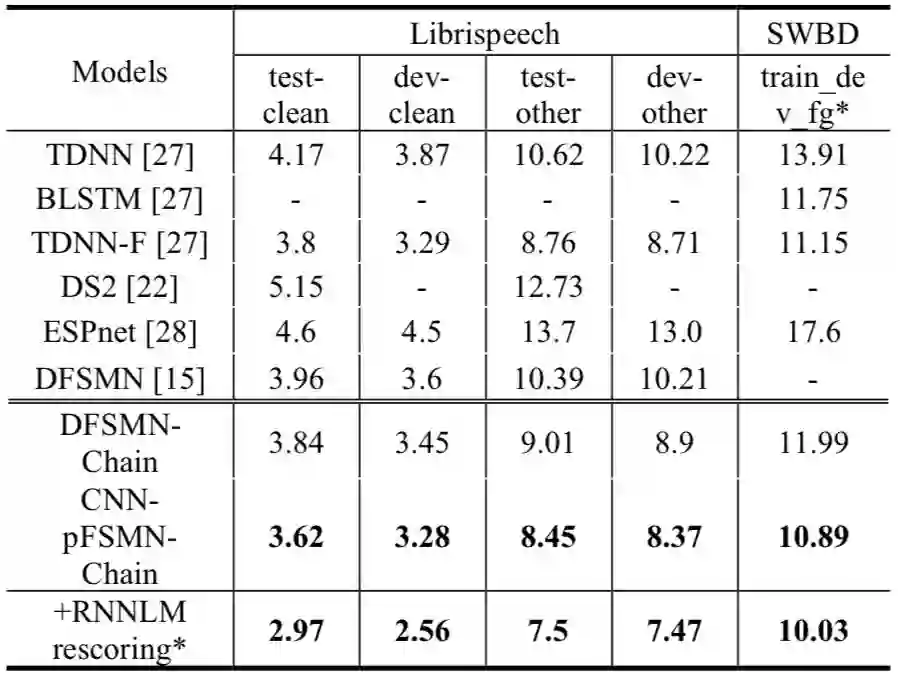
表 1:新方法与之前的方法在 Librispeech 和 SWBD-300 任务上的对比。

本文为机器之心编辑,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com



