Kaggle美女自述:我是怎么成为竞赛中Top 0.3%的
原文:Lavanya Shukla
铜灵 编译整理
量子位 出品 | 公众号 QbitAI
但每年的Kaggle参赛团队众多,通常一个项目都有数千人至上万人报名,如何在其中脱颖而出?最近,自动化数据准备及协作平台Dataland的联合创始人Lavanya Shukla,在博客上分享了她在Kaggle竞赛中最终成为0.3%的获奖经验。

小姐姐在推特中表示,这份攻略里全都是干货,网友纷纷为其点赞。有网友表示,这份攻略非常棒,才知道脊回归如此强大!

*先放上原文地址:*
*https://www.kaggle.com/lavanyashukla01/how-i-made-top-0-3-on-a-kaggle-competition*
长文干货预警,建议先码后看:
开始一场数据科学竞赛是一项庞大的工作,所以我写了这篇在Kaggle经典房价预测题目(Advanced Regression Techniques)中获得TOP 0.3%成绩的比赛经验。
欢迎大家fork这份干货,也欢迎在实际问题中亲自实践这些代码。
祝你好运!
目标
数据集中每一行都描述了房子的特征。
我们的目标是根据这些特征,预测销售价格。
评估模型好坏是根据模型预测的销售价格与实际销售价格之间的均方根误差(RMSE)。将RMSE转换成对数尺度,确保预测昂贵房屋和便宜房屋时的误差会对产生的分数影响相当。
模型训练过程中的关键特性
交叉验证:使用12折交叉验证。
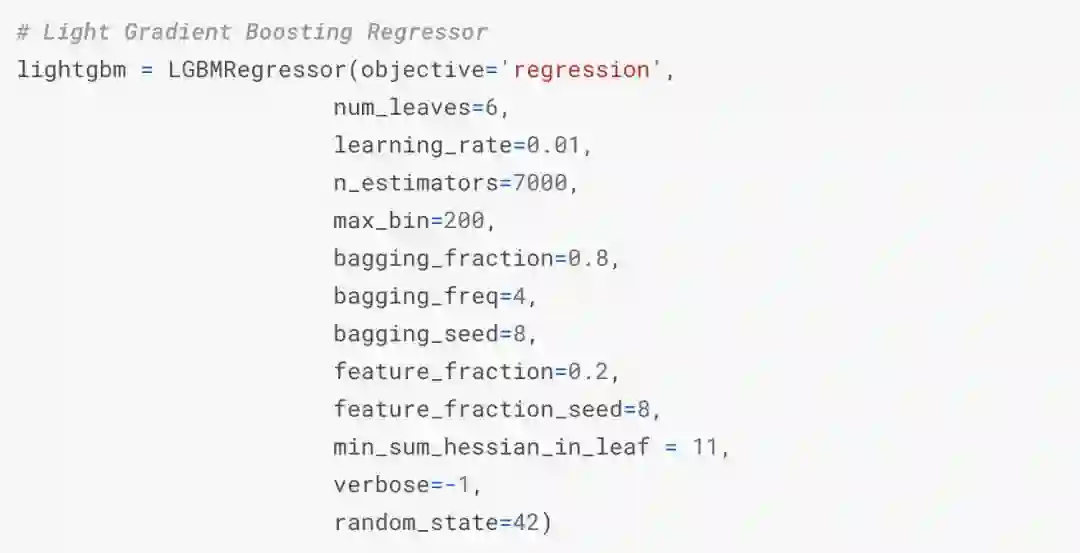
模型:每次交叉验证拟合7个模型(包括ridge、svr、gradient boost、random forest、xgboost、lightgbm regressors等)
堆叠:此外,我用xgboost训练了一个元StackingCVRegressor。
混合:所有训练过的模型在不同程度上都存在对训练数据的过拟合。因此,为了做出最终的预测,我将它们的预测混合在一起以得到更可靠的预测。
模型表现
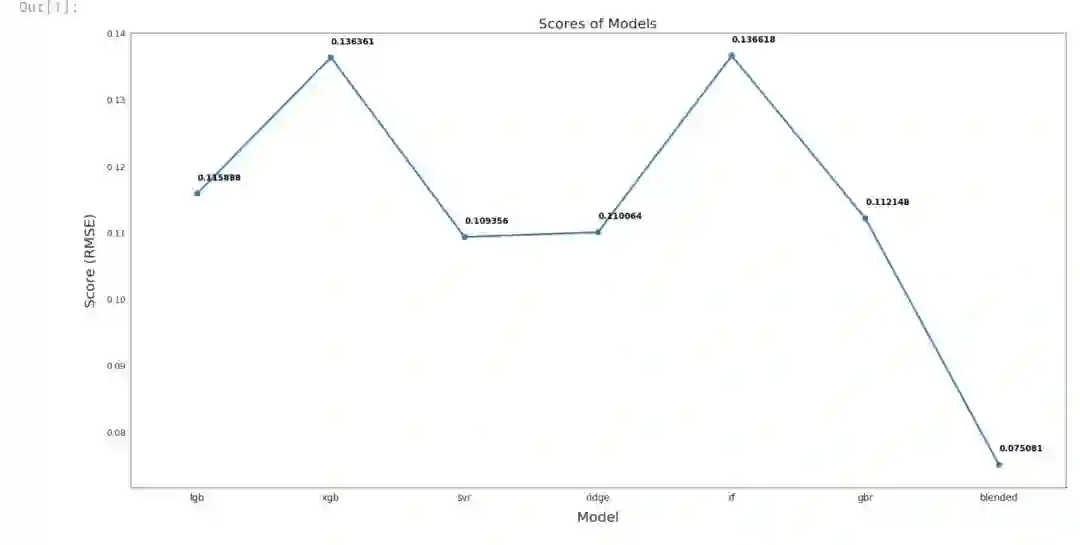
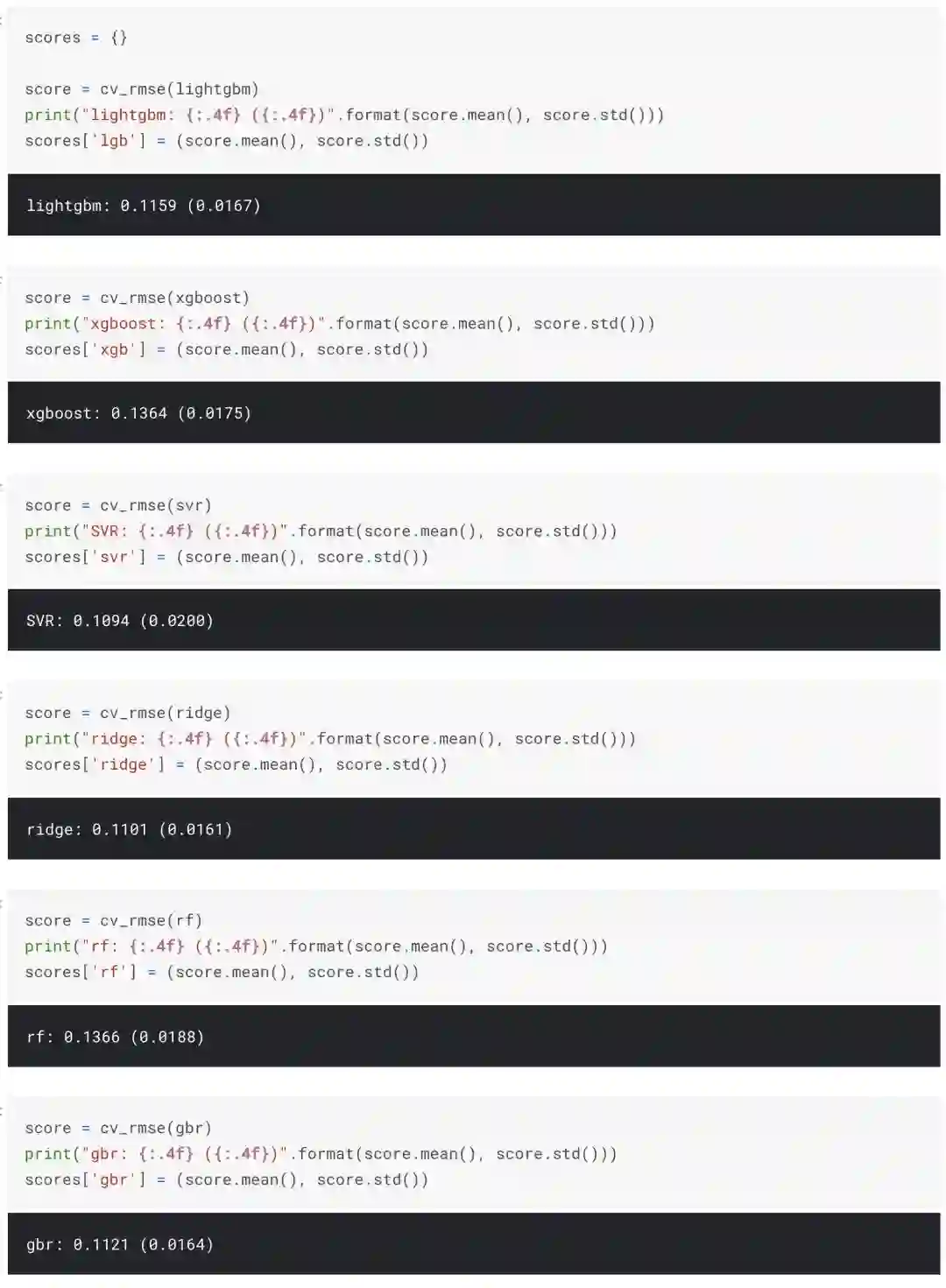
从下图可以看出,混合模型的RMSLE(均方根对数误差)为0.075,远优于其他模型。
这是我用来做最终预测的模型:

现在我们已经知道了一些信息,可以开始着手了:
EDA
目标
数据集中每一行都描述了房子的特征。
我们的目标是根据这些特征预测销售价格。

销售价格:我们打算预测的变量

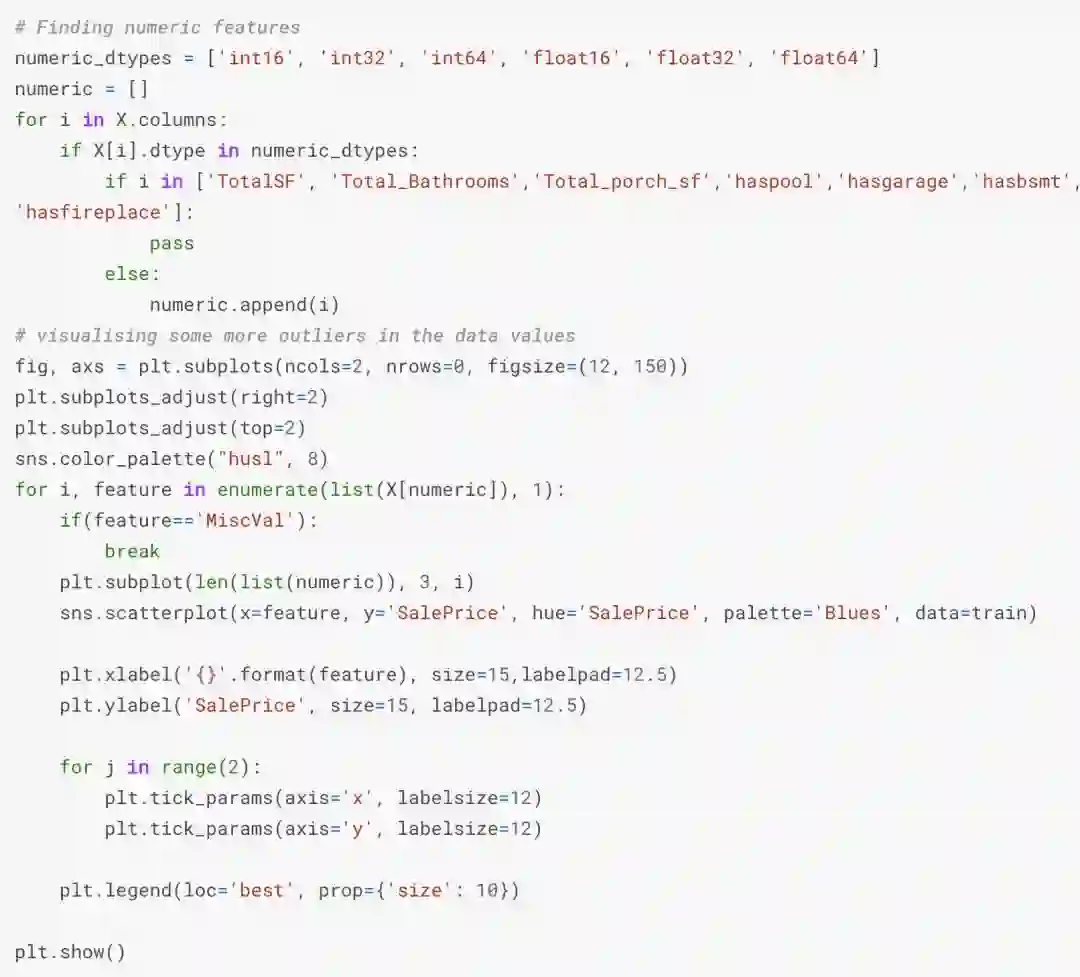
特征处理
我们先将数据集中特征进行可视化:
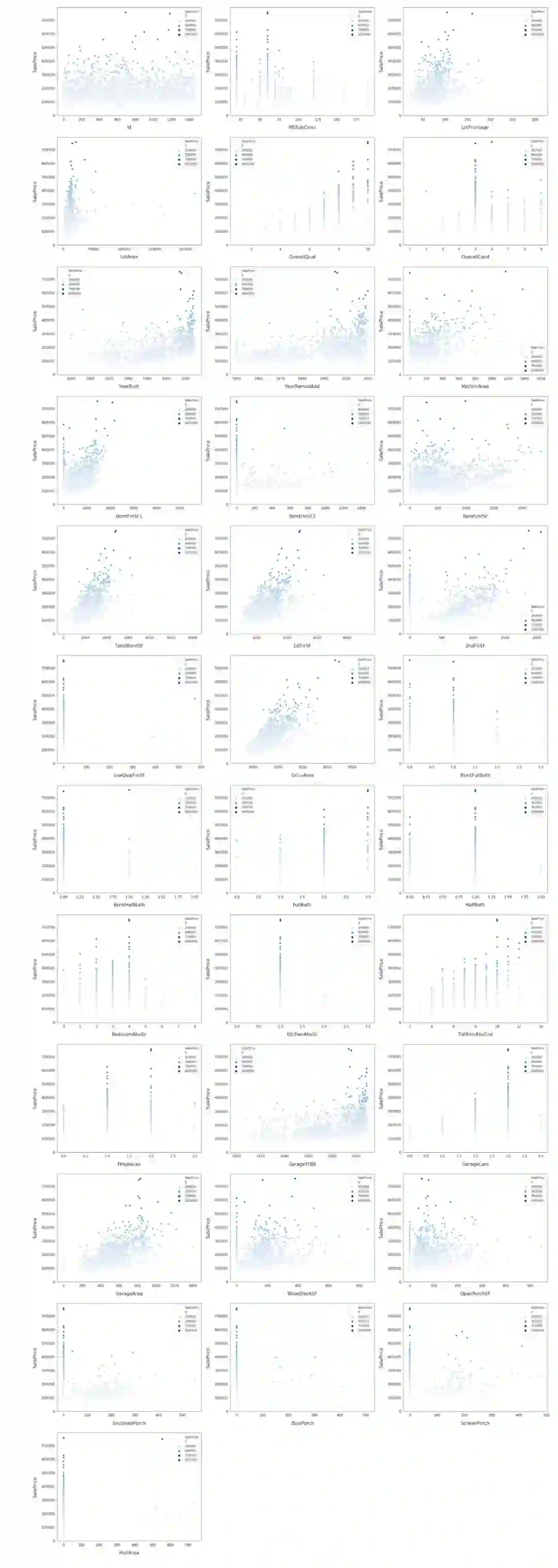
并绘制出这些特征之间的关系,以及它们与销售价格的关系。

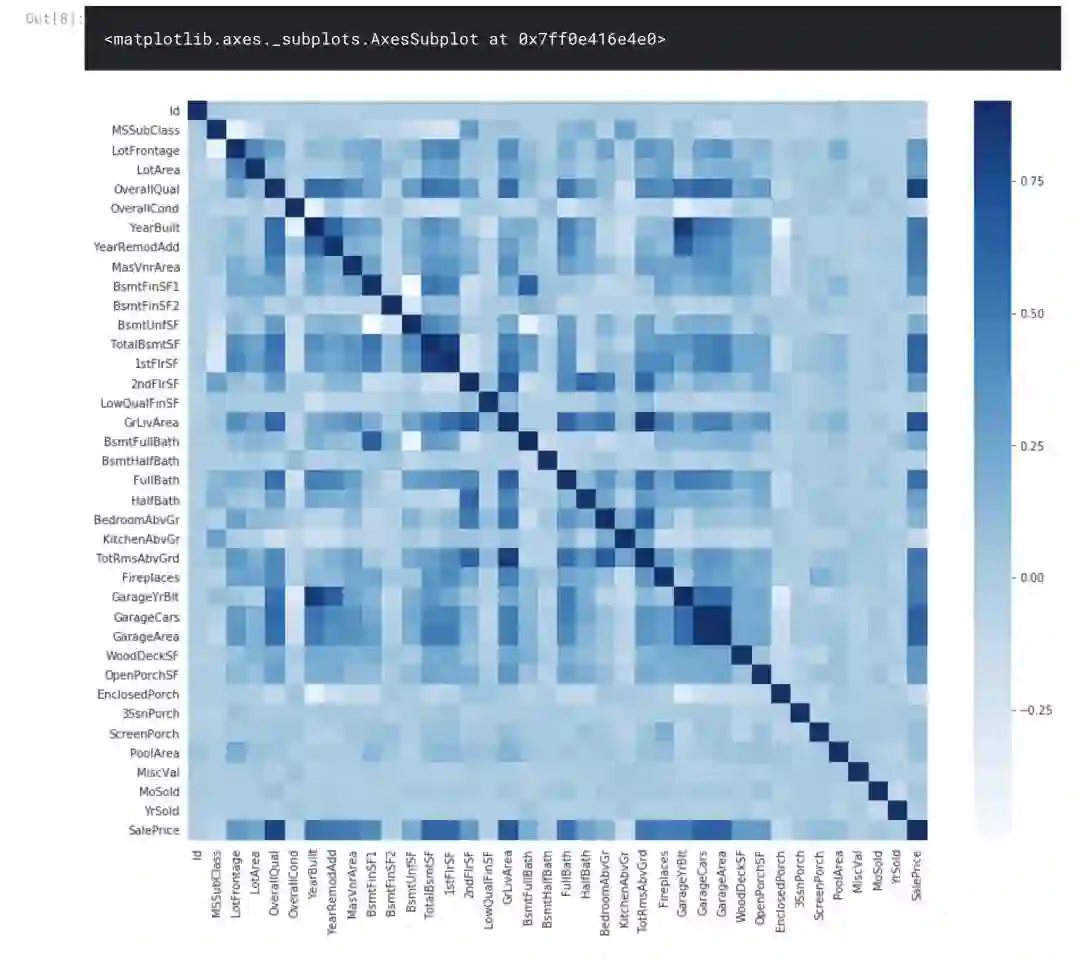
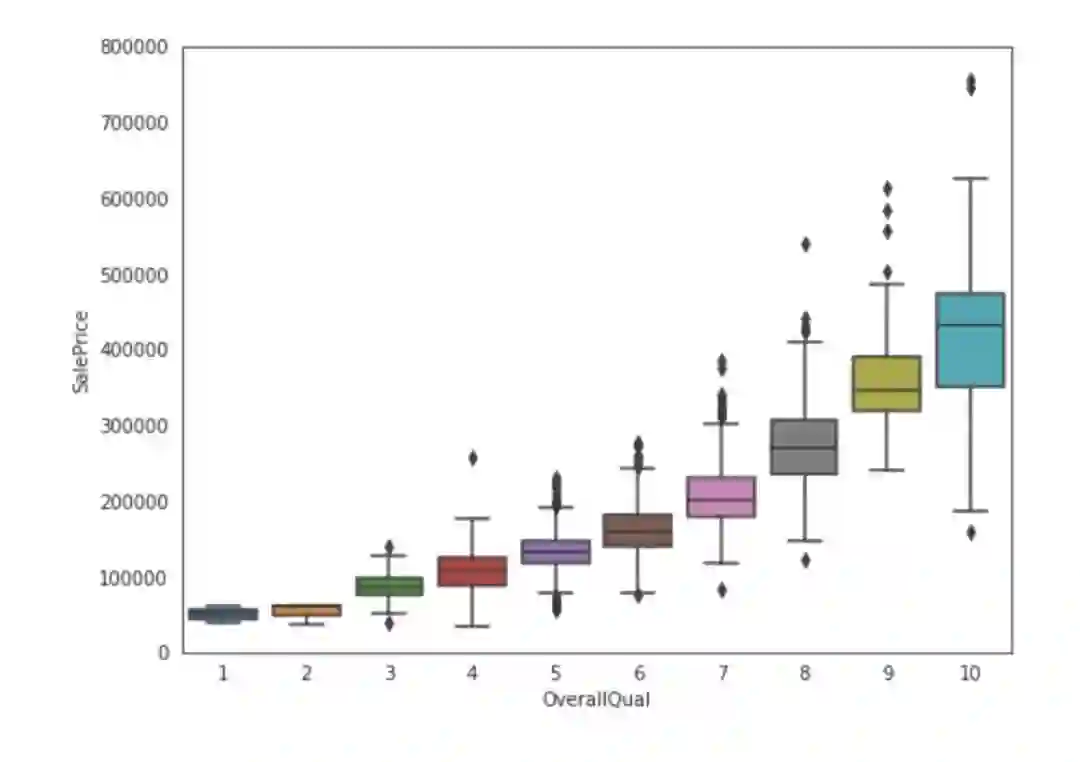
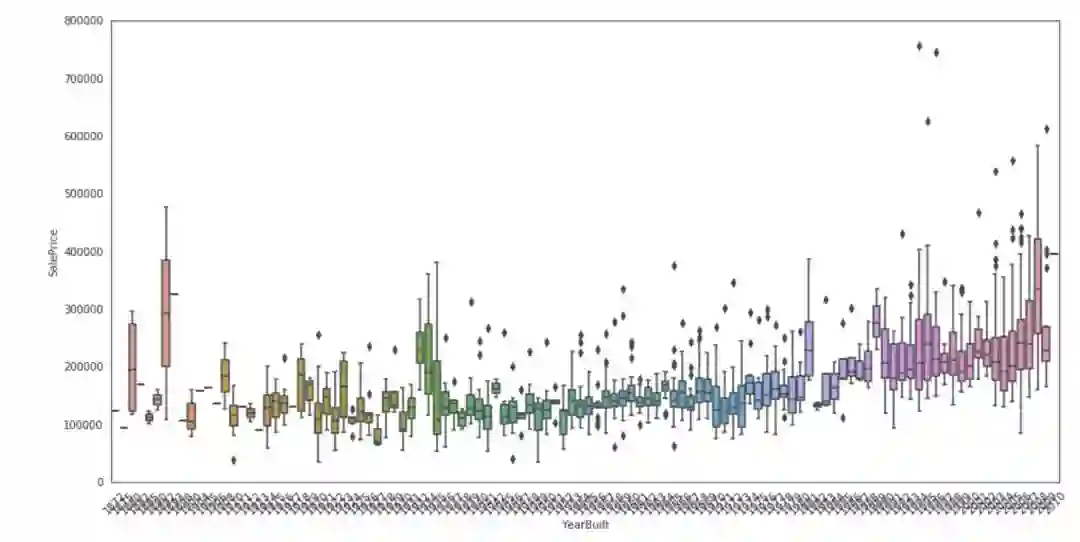
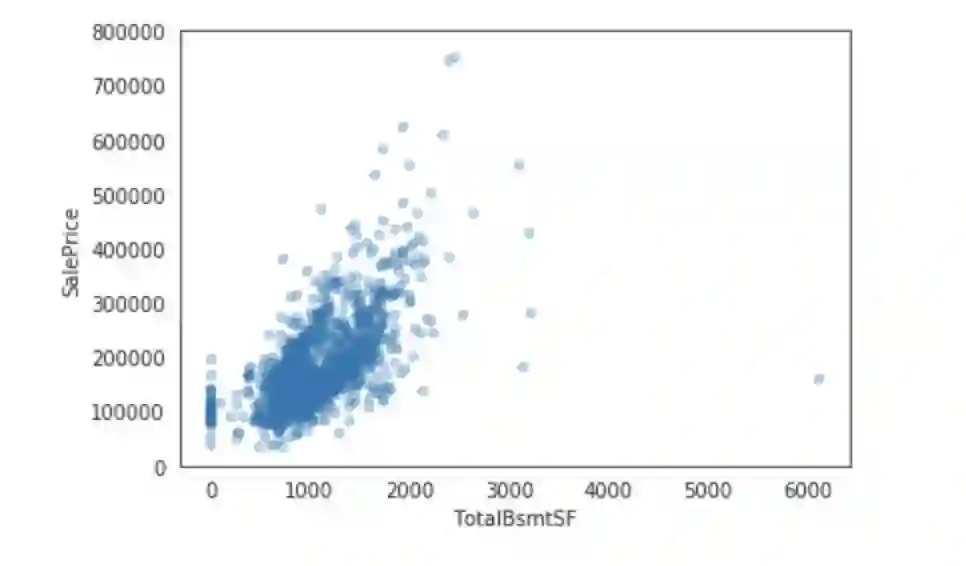
让绘制销售价格与数据集中的一些特性之间的关系。




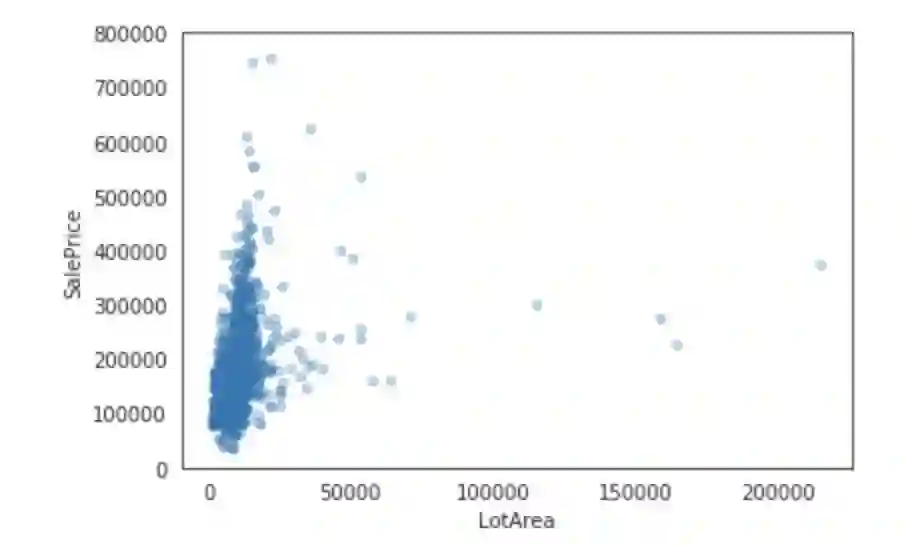

特征工程
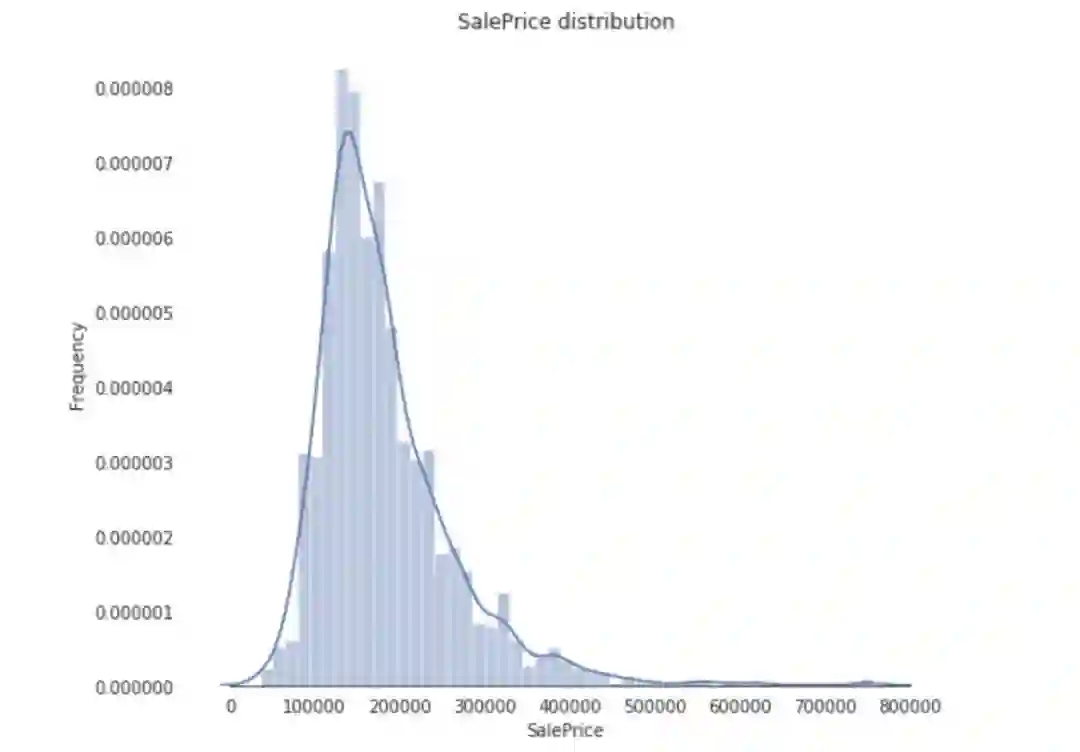
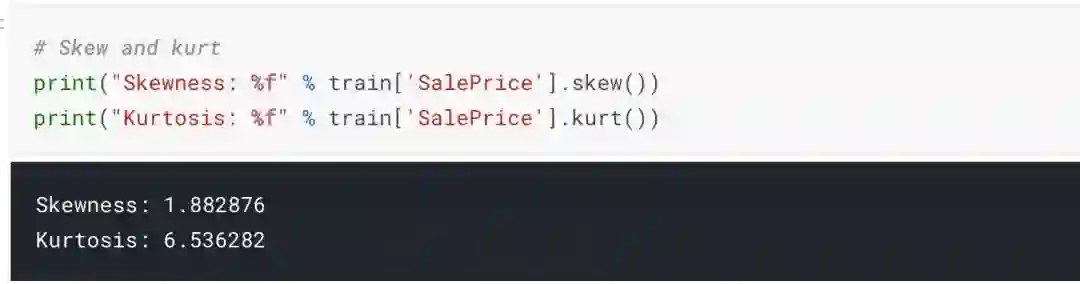
来看一下房子售价的分布情况。
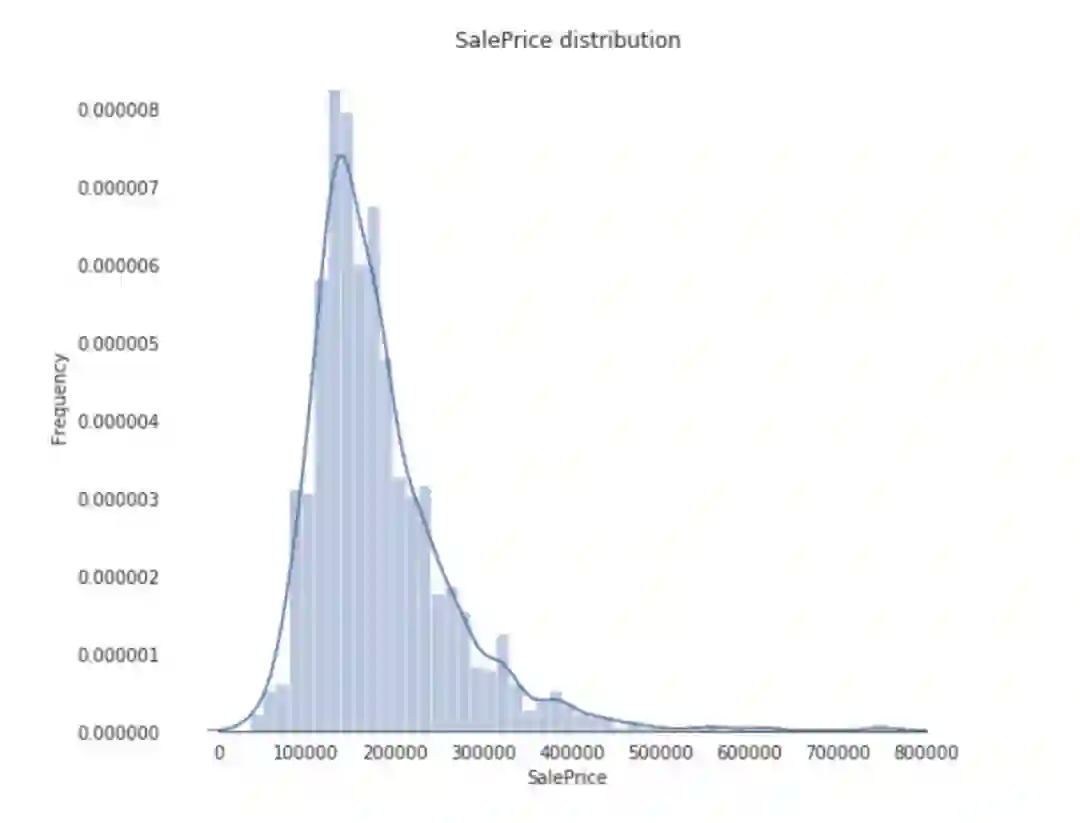
可以看出,销售价格在右边倾斜,这是因为大多数ML模型不能很好地处理非正态分布数据。
我们可以应用log(1+x)变换来修正倾斜。

再画一次销售价格的分布:
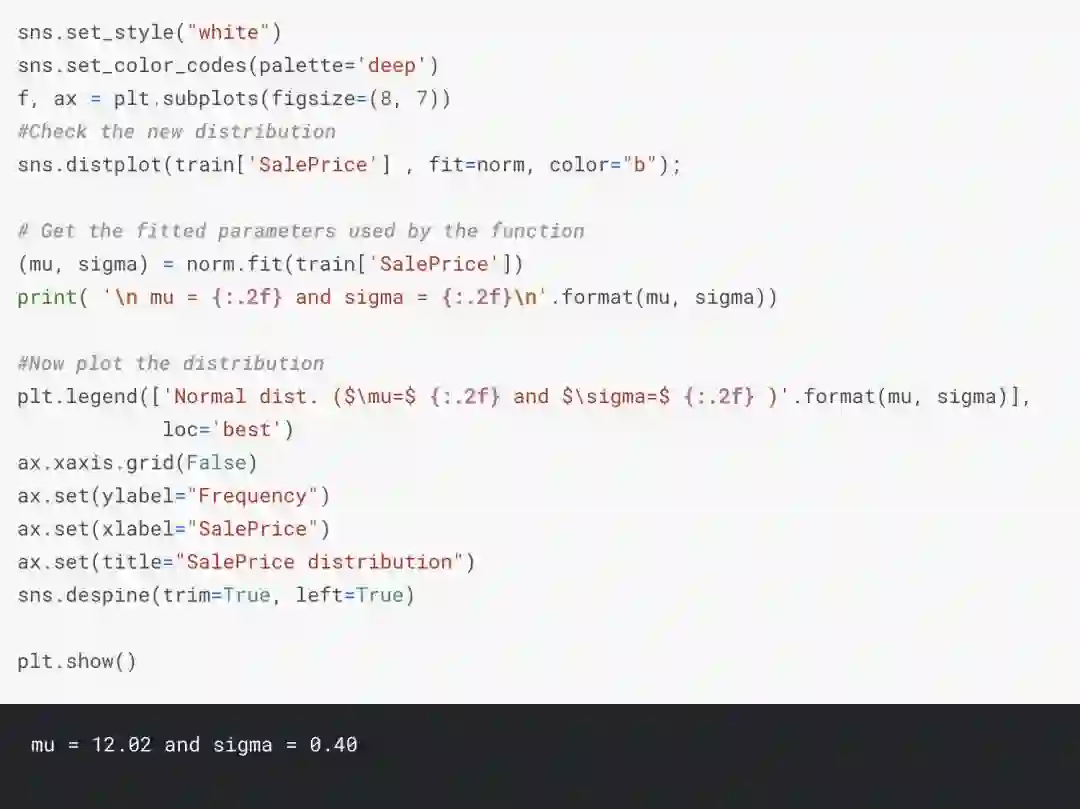
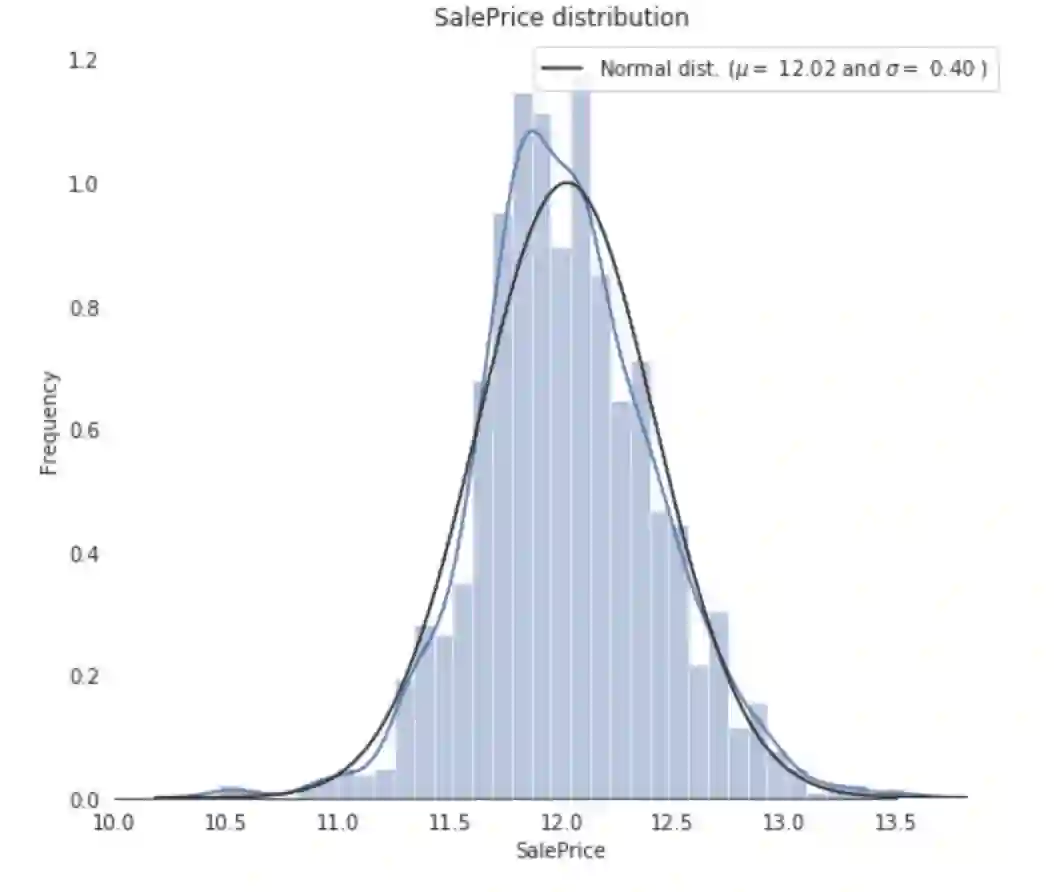
现在,销售价格是正态分布的了。

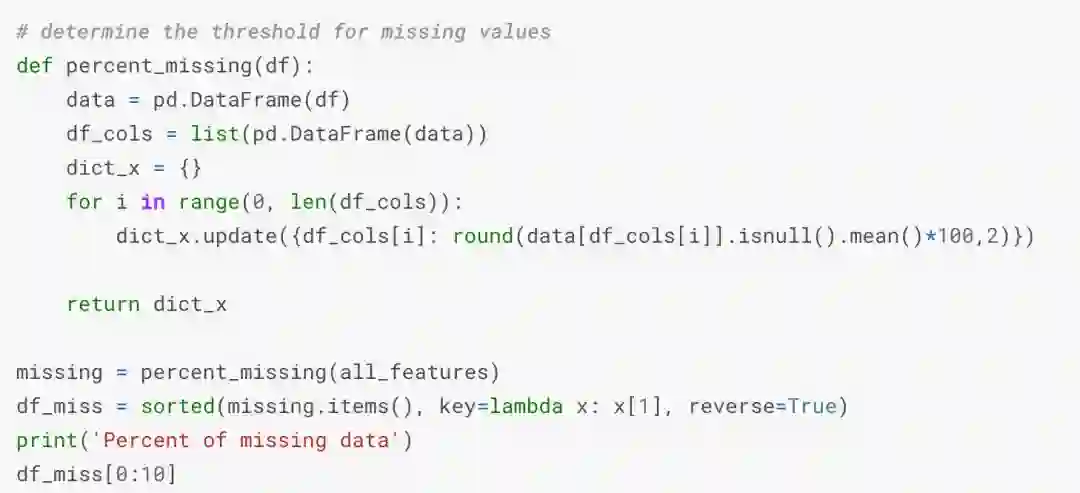
添补缺失值
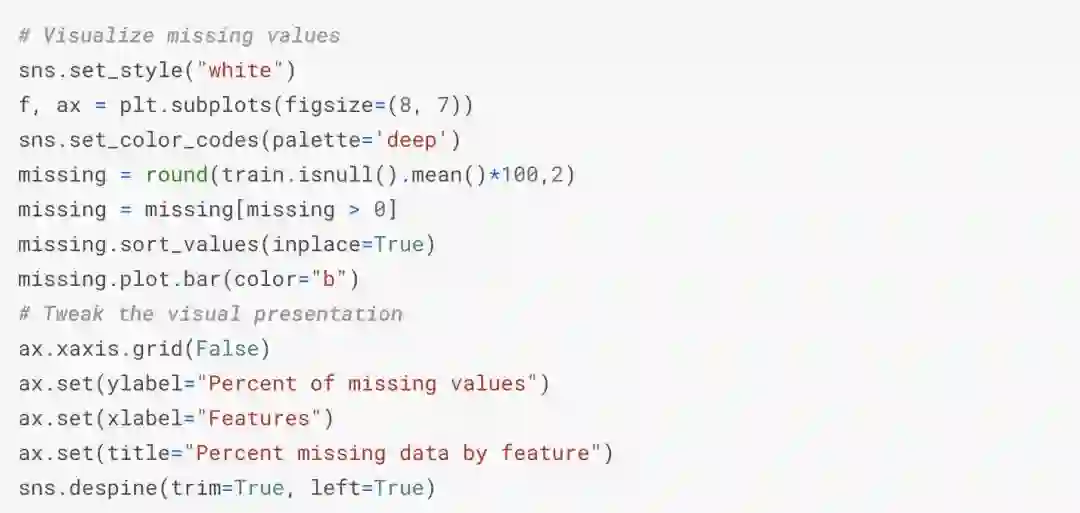
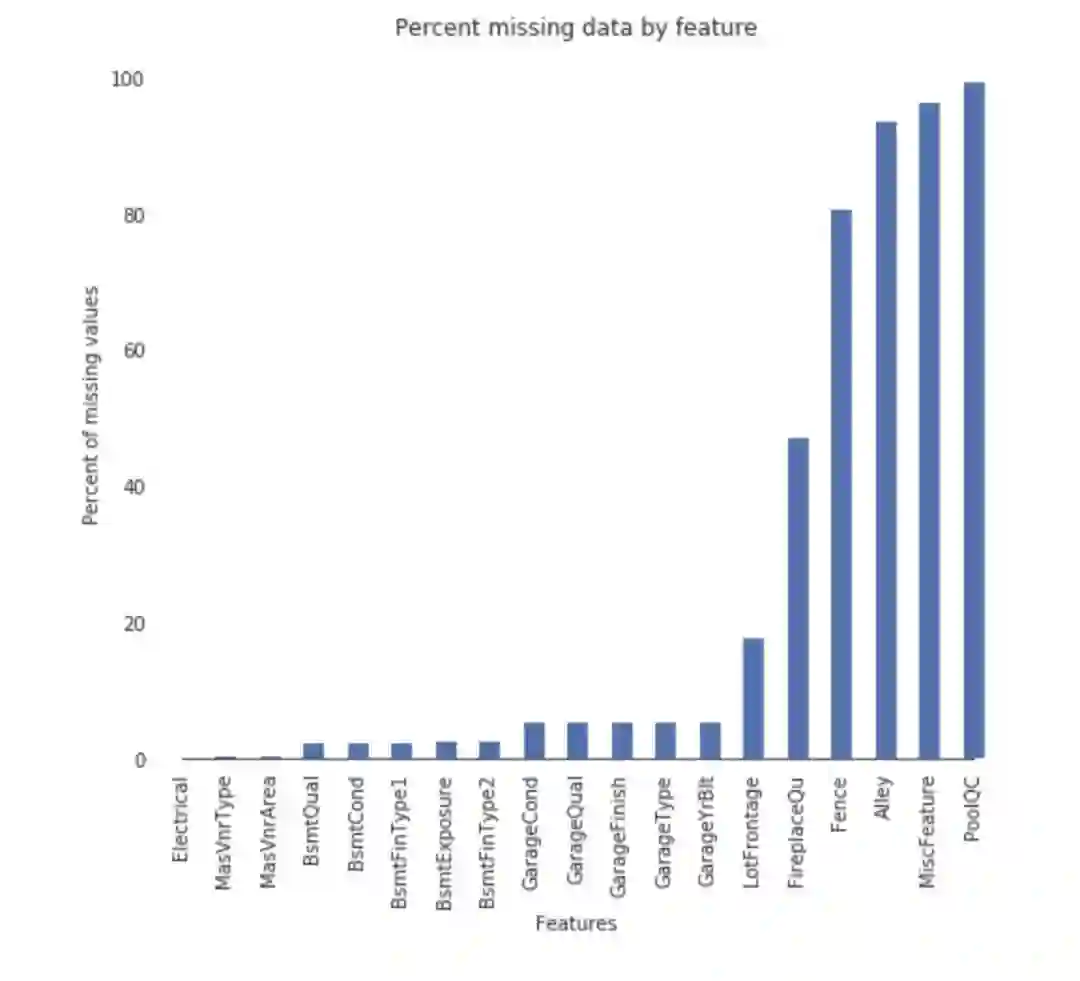
现在,我们可以为每个特性添加缺失的值。

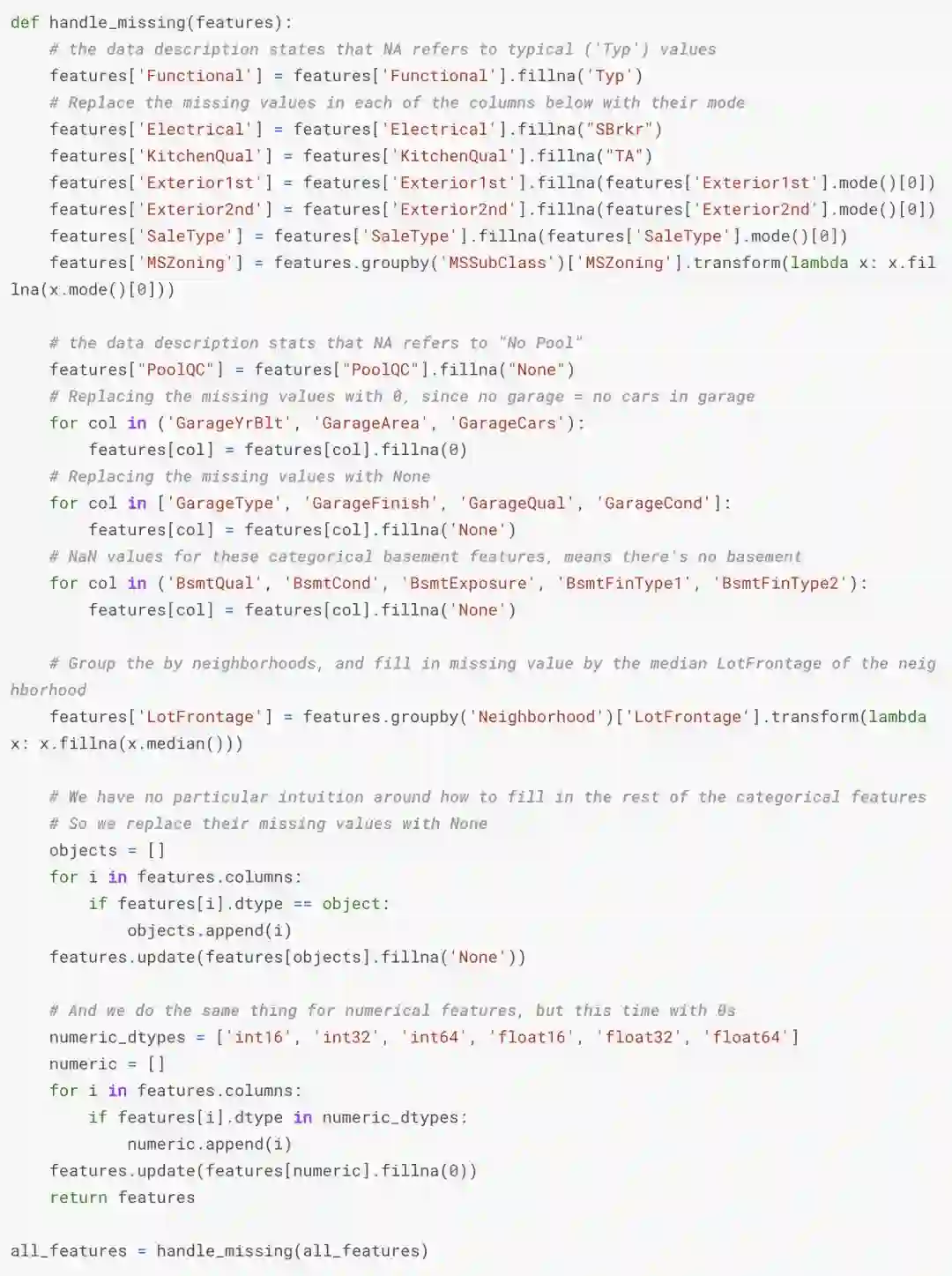
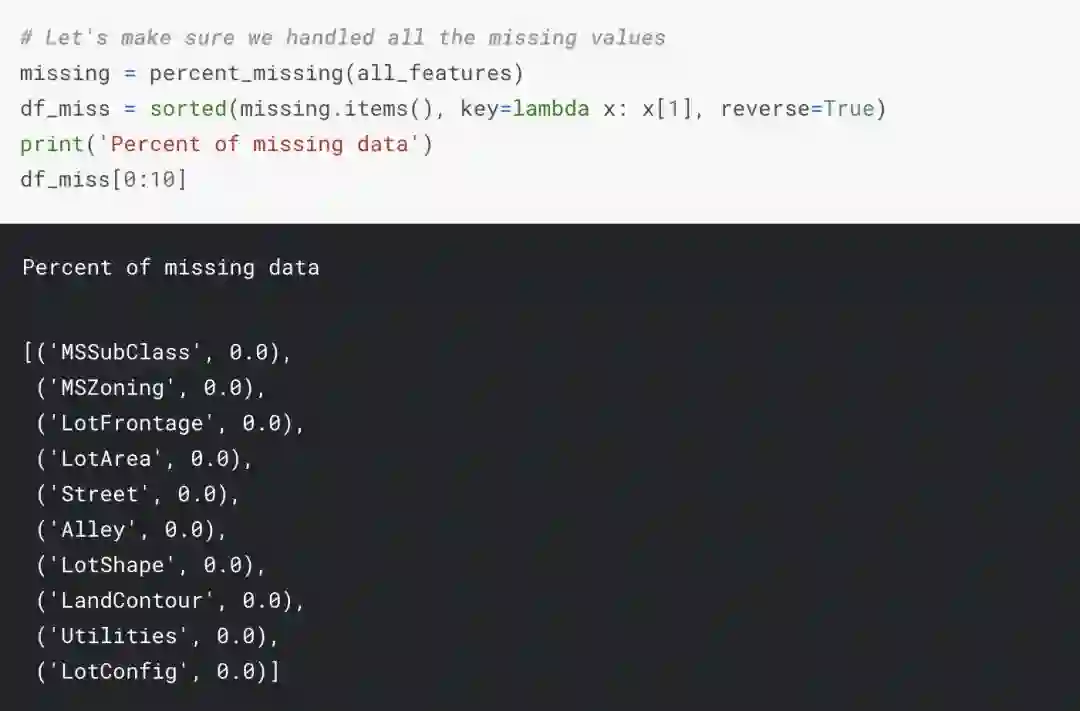
这样一来,这不就没有缺失值了……
解决倾斜特征


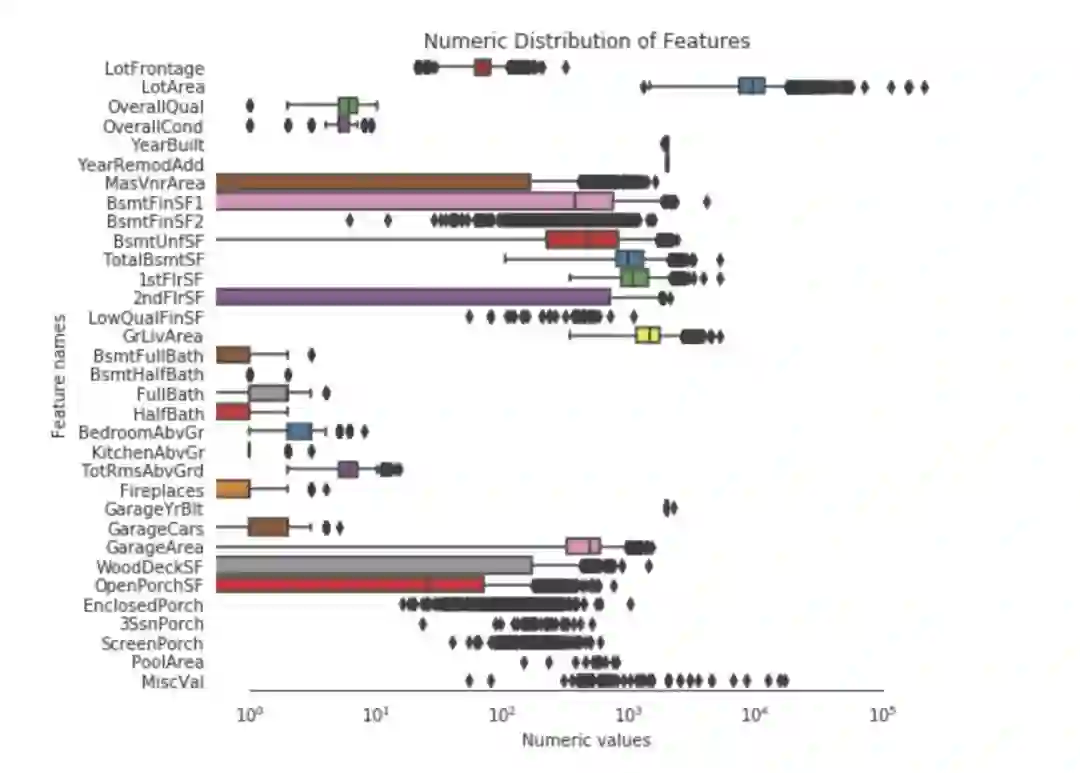
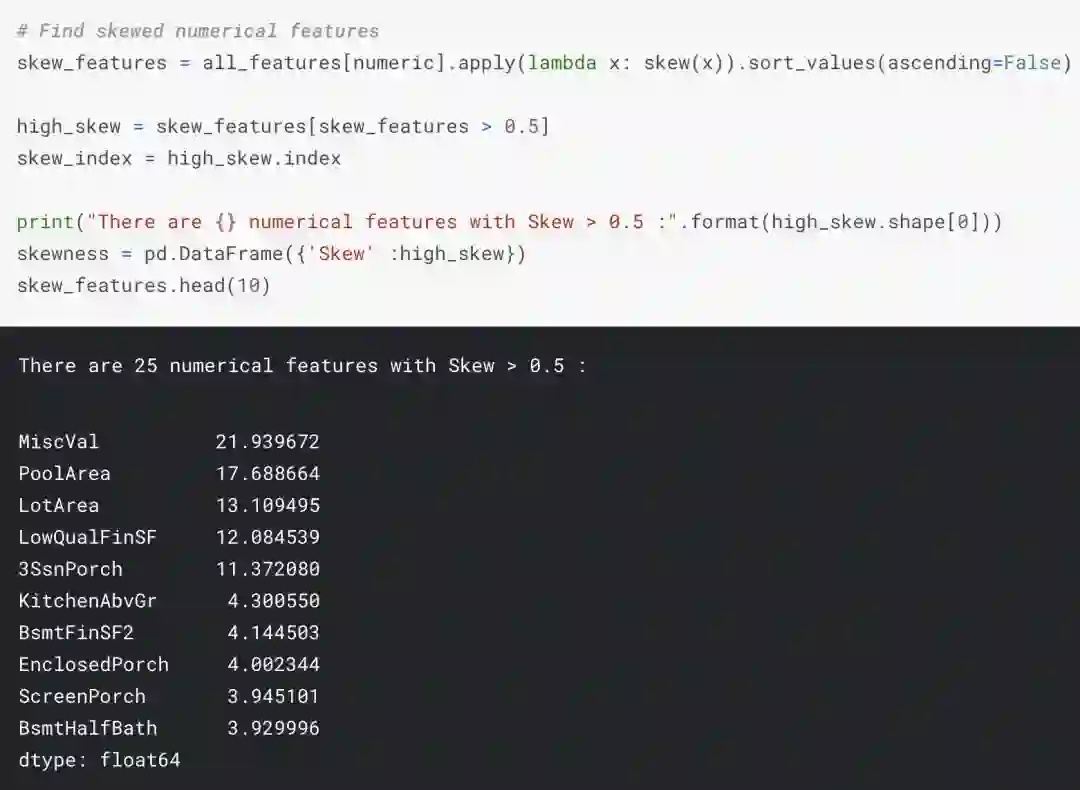
我们用scipy函数boxcox1p来计算Box-Cox转换。我们的目标是找到一个简单的转换方式使数据规范化。


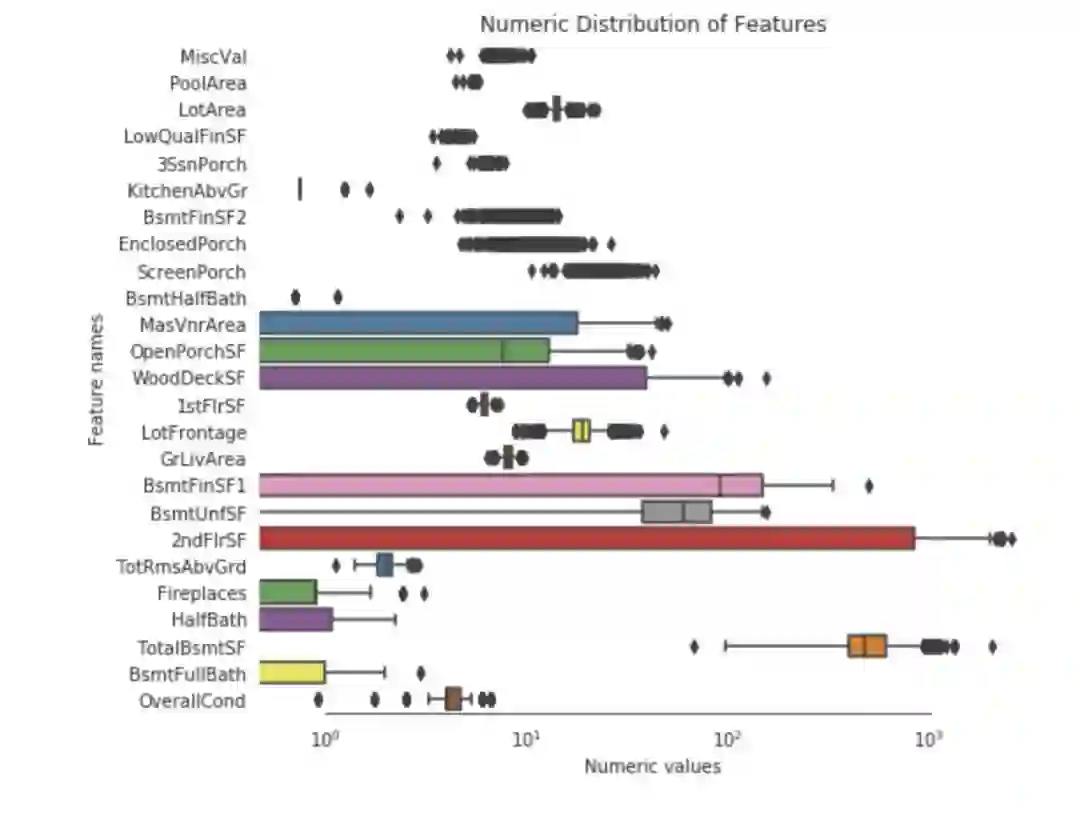
现在,所有的特种看起来都是正态分布的了。
创造有趣的特征
ML模型很难识别更复杂的模式,所以我们可以基于对数据集的直觉创建一些特征来帮助我们的模型,比如,每个房子地板总面积、浴室和门廊面积。

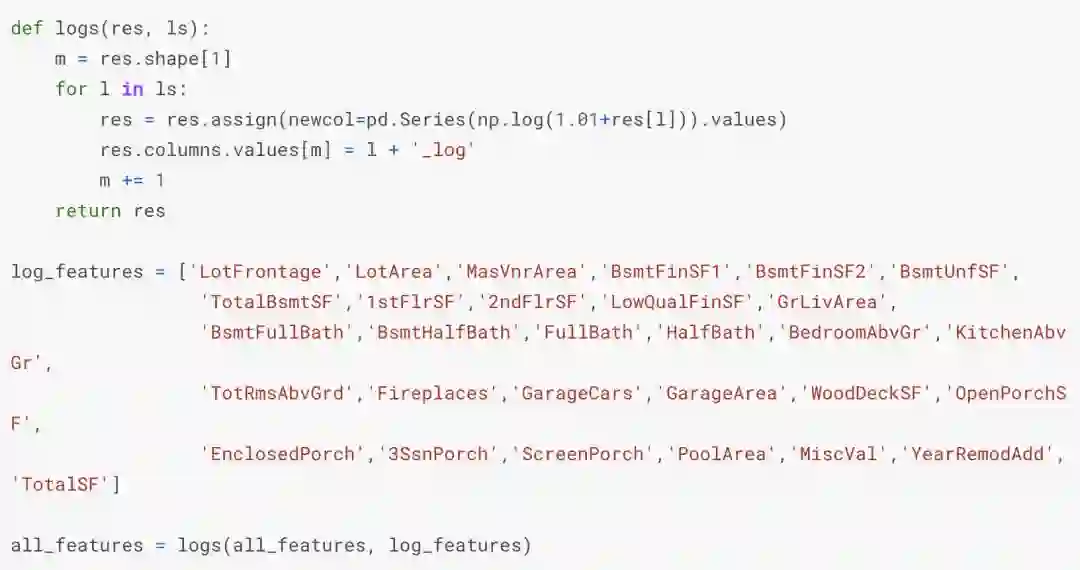
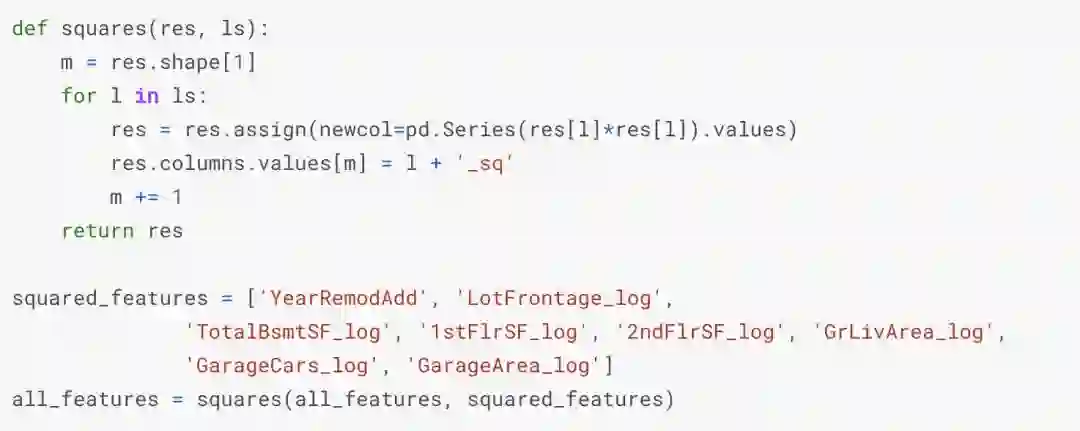
特征转换
我们通过计算数值特征的对数和平方变换来创建更多的特征。
编码分类特征
因为大多数模型只能处理数字特征,所以采用数字编码分类特征。
重新创建训练和测试集
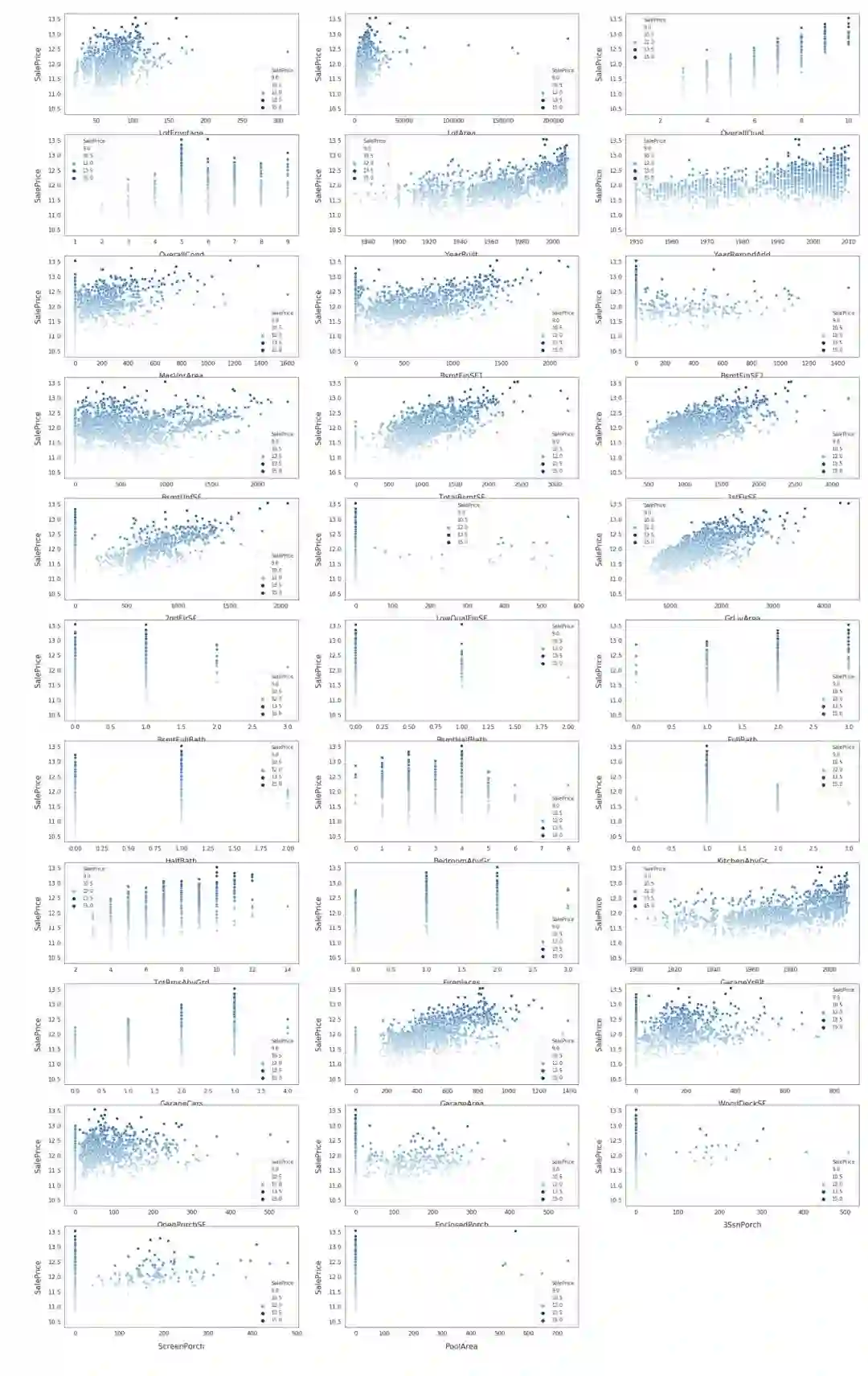
可视化我们要训练模型的一些特性。
训练模型
设置交叉验证并定义错误度量

设置模型
训练模型
获得每个模型的交叉验证分数。
混合模型逼格得到预测值
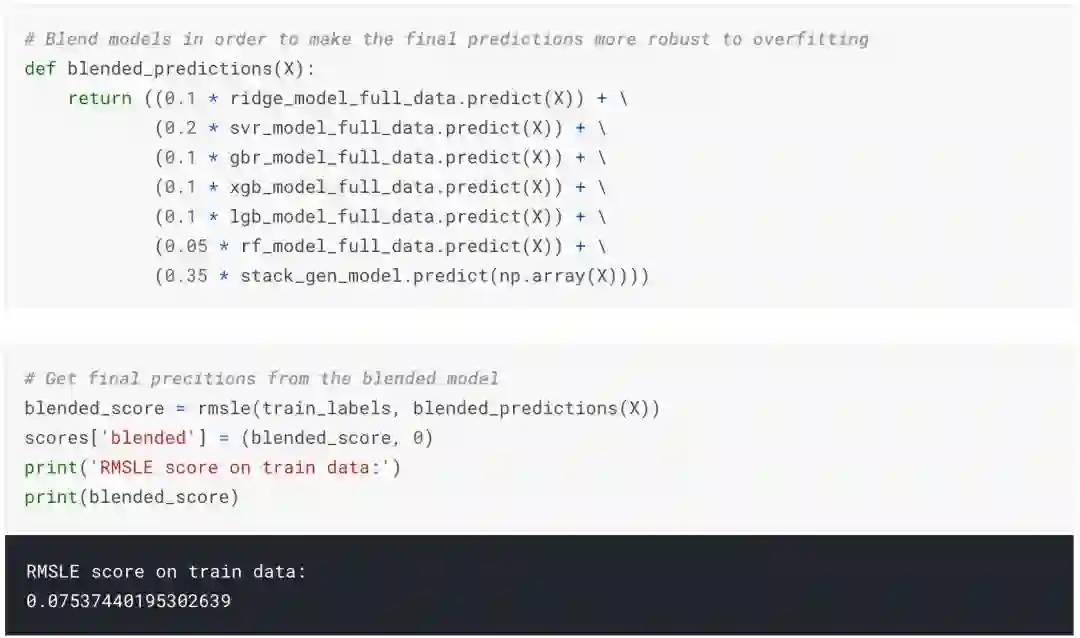
确定性能最佳的模型
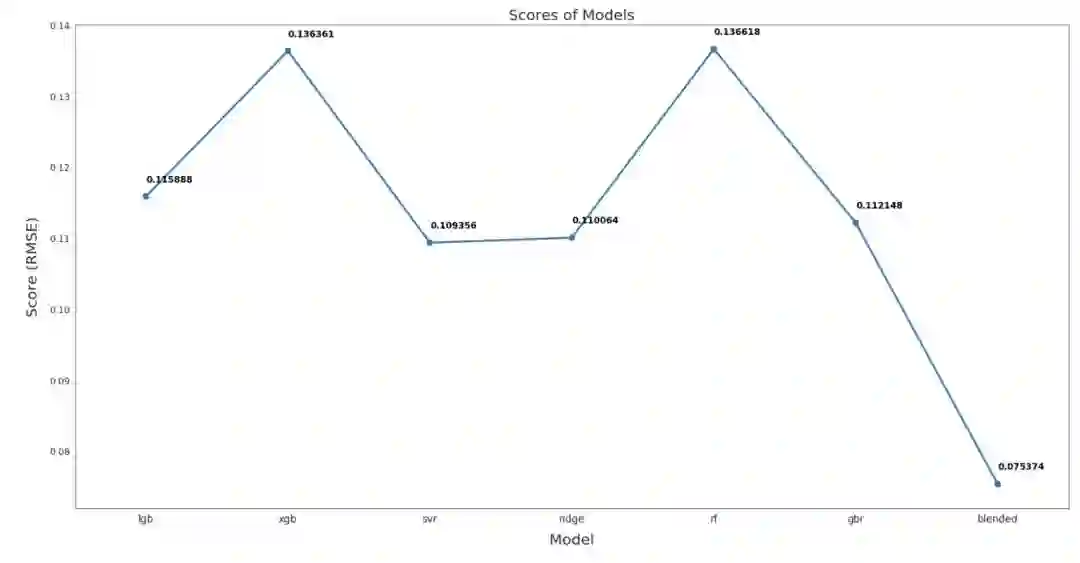
从上图中我们可以看出,混合模型的RMSLE为0.075,远远优于其他模型。这是我用来做最终预测的模型。
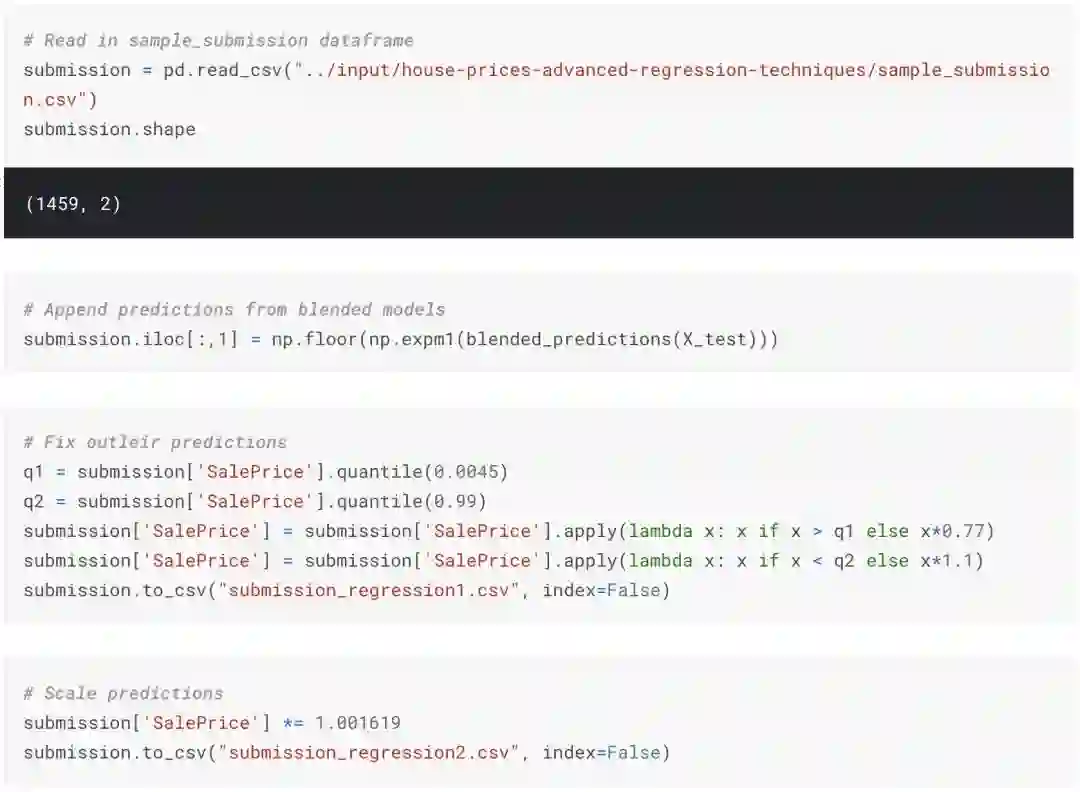
提交预测值
文章原文:
https://www.kaggle.com/lavanyashukla01/how-i-made-top-0-3-on-a-kaggle-competition
小姐姐的博客:
https://lavanya.ai/
推荐阅读
拿不到offer全额退款 | 第四期人工智能 NLP / CV 课 培训招生

喜欢就点击“在看”吧!




