ToB产品必备特性:Pravega的动态弹性伸缩做得怎么样?

以上特性通俗来讲,就是流量数据到达量有峰有谷,且可能不可预知。正因如此,Pravega 作为一款流存储的产品,必须能够应对瞬时的数据洪峰,做到“削峰填谷”,让系统自动地伴随数据到达速率的变化而伸缩,既能够在数据峰值时进行扩容提升瞬时处理能力,又能够在数据谷值时进行缩容节省运行成本,而读写客户端无需额外进行调整。
这一特性对于面向企业开发产品尤其重要,Devops 开销在企业中都会被归入产品 TCO(Total Cost of Ownership) , 所以产品自身的动态自适应能力将会是必备条件,这也是回应我们在系列文章第二篇中提到的三大挑战最后一条。
更多干货内容请关注微信公众号“AI 前线”(ID:ai-front)
下面我们就详细讲述 Pravega 动态弹性伸缩特性的实现和应用实例。
对于分布式消息系统来说,一个设计良好的,可扩展的分区机制必不可少。分区机制使得读写的并行化成为可能,而一个良好的分区扩展机制使得企业在面临业务增长时可以变得更得心应手。和许多基于静态分区,或者需要手动扩展分区(如 Kafka)的系统不同的是,Pravega 可以根据数据负载动态地伸缩 Stream,以此来实时地应对流量负载的变化。
在当前的大数据技术环境下,我们通过将数据拆分成多个分区并独立处理来获得并行性。 例如,Hadoop 通过 HDFS 和 map-reduce 实现了批处理并行化。 对于流式工作负载,我们今天要使用多消息队列或 Kafka 分区来实现并行化。 这两个选项都有同样的问题:分区机制会同时影响读客户端和写客户端。 面对持续数据处理的读 / 写,我们的扩展要求往往会有不同,而一个同时影响读写的分区机制会增加系统的复杂性。 此外,虽然你可以通过添加队列或分区来进行扩展,但这需要分别对读、写客户端和存储进行手动调整,然后需要手动协调调整后的参数。 这样的操作很复杂,而且不是动态的,并需要人工介入。
而使用 Pravega 的话,我们可以轻松地、弹性并且独立地扩展数据的摄入、存储和处理,即协调数据管道中每个组件的扩展。
Pravega 对动态伸缩的支持源自于把 Stream 被划分成 Segment 的想法。 在之前的文章中有介绍过,一个 Stream 可以具有一个或多个 Segment。我们可以把一个 Segment 类比成一个分区,写入 Stream 的任何数据都会根据指定路由键,通过哈希计算路由至某一个 Segment。 实际应用场景下,我们建议应用开发者基于一些有应用意义的字段,比如 customer-id,timestamp,machine-id 等来生成路由键,这样就可以确保将同类的应用数据路由至同一个 Segment。
Segment 是 Stream 中最基本的并行单元。
并行写:一个具有更多个 Segment 的 Stream 可以支持更大的写入并行度,多个写客户端可以并行地对多个 Segment 进行写入,而这些 Segment 可能在物理上分布于集群中的多台服务器上。
并行读:对于读客户端来说,Segment 的数量意味着最大的读并行度。一个具有 N 个读客户端的读者组可以以最大为 N 的并行度来消费同一个 Stream。这样,当一个 Stream 中的 Segment 数量被动态增加时,我们可以相应地增加同等数量的读客户端(同一读者组)来增加并行度;反之亦然,当 Segment 数量动态减少时,我们也可以减少相应的读客户端来节省资源。
Stream 可以被配置为随着更多数据写入而增加 Segment 的数量,并在数据量下降时缩小 Segment 数。 我们将这种配置称为 Stream 的服务级目标(Service Level Objective,SLO)。Pravega 监控输入到 Stream 的数据速率,并根据 SLO 在 Stream 中动态增加或移除 Segment。 当需要增加 Segment 时,Pravega 会通过拆分 Segment 来生成更多的 Segment;而当需要减少 Segment 数量时,Pravega 通过合并 Segment 来减少 Segment 数量。
实际应用中,应用程序还可以对接 Pravega 提供的元数据,根据 Stream 的伸缩性来做相应的伸缩。举例来讲,Flink 可以根据元数据中的 Segment 数量来调整 Flink 作业的并行度,或者可以依赖容器平台(如 Cloud Foundry,Mesos/Marathon,Kubernetes 或者 Docker Stack)提供的动态扩缩容机制来动态调整容器实例的数量,以此来应对数据流量的变化。
Pravega 根据一致性散列算法将路由键散列至“键空间”,该键空间被划分为多个分区,分区数量和 Segment 数量相一致,同时保证每一个 Segment 保存着一组路由键落入同一区间的事件。
根据路由键,我们将一个 Stream 拆分成了若干个 Segment,每一个 Segment 保存着一组路由键落入同一区间的事件,并且拥有着相同的 SLO。
同时,Segment 可以被封闭(seal),一个被封闭的 Segment 将禁止写入。这一概念在动态伸缩中将发挥重要作用。
假设某制造企业有 400 个传感器,分别编号为 0~399,我们将编号做为 routing key,并将其散列分布到 (0, 1) 的键空间中(Pravega 也支持将非数值型的路由键散列到键空间中)。随着部分传感器传输频率的变化,我们来观察其 Segment 的变化。
如图 1 所示,在 0~1 区间的键空间中,Segment 的合并和拆分导致了路由键随着时间的推移而被路由至不同的 Segment。
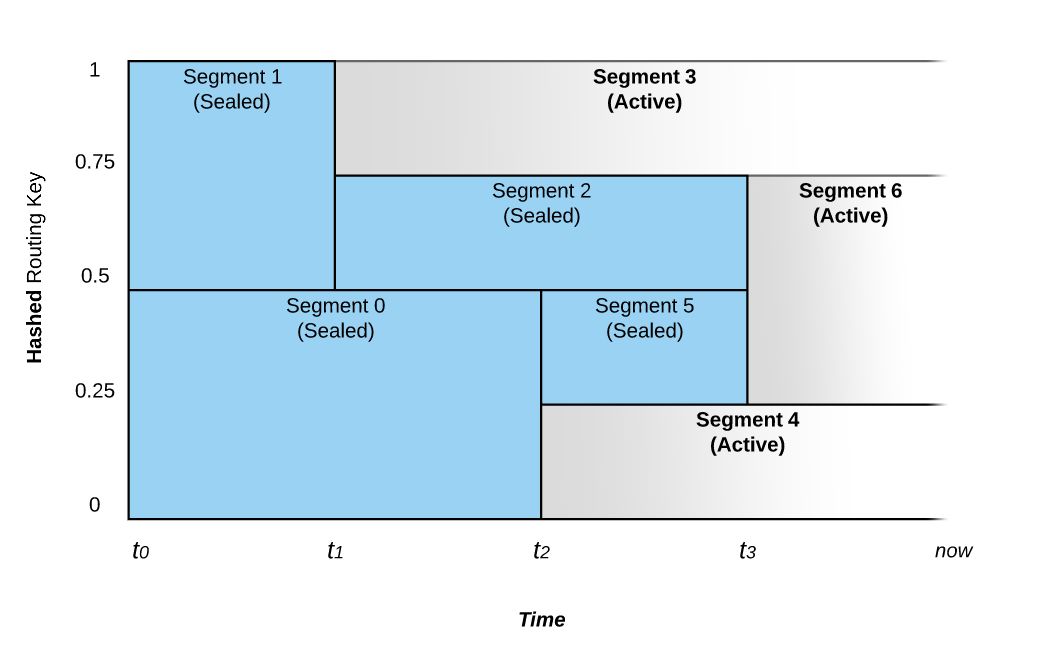
图 1: Segment 的合并和拆分对事件路由的影响
上图所示的 Stream 从时间 t0 开始,它被配置成具有动态伸缩功能。 如果写入流的数据速率不变,则段的数量不会改变。
在时间点 t1,Pravega 监控器注意到数据速率的增加,并且选择将 Segment 1 拆分成 Segment 2 和 Segment 3 两部分,这个过程我们称之为 Scale-up 事件。在 t1 之前,路由键散列到键空间上半部的(值为 200~399)的事件将被放置在 Segment 1 中,而路由键散列到键空间下半部的(值为 0~199)的事件则被放置在 Segment 0 中。在 t1 之后,Segment 1 被拆分成 Segment 2 和 Segment 3;Segment 1 则被封闭,即不再接受写入。 此时,具有路由键 300 及以上的事件被写入 Segment 3,而路由键在 200 和 299 之间的事件将被写入 Segment 2。Segment 0 则仍然保持接受与 t1 之前相同范围的事件。
在 t2 时间点,我们看到另一个 Scale-up 事件。这次事件将 Segment 0 拆分成 Segment 4 和 Segment 5。Segment 0 因此被封闭而不再接受写入。
具有相邻路由键散列空间的 Segment 也可以被合并,比如在 t3 时间点,Segment 2 和 Segment 5 被合并成为 Segment 6,Segment 2 和 Segment 5 都会被封闭,而 t3 之后,之前写入 Segment 2 和 Segment 5 的事件,也就是路由键在 100 和 299 之间的事件将被写入新的 Segment 6 中。合并事件的发生表明 Stream 上的负载正在减少。
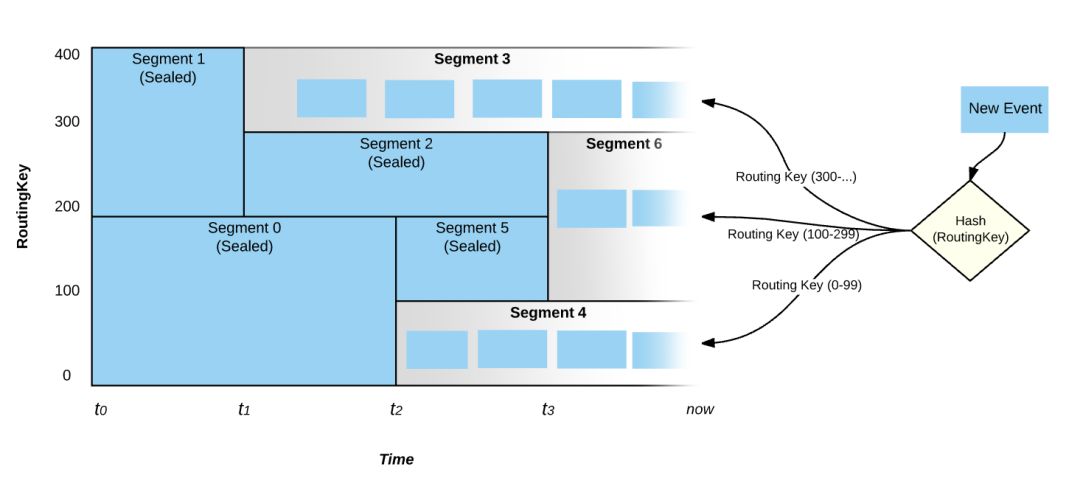
图 2: 事件的路由
如图 2,在“现在”这个时刻,只有 Segment 3,6 和 4 处于活动状态,并且所有活跃的 Segment 将会覆盖整个键空间。在上述的规则 2 和 3 中,即使输入负载达到了定义的阈值,Pravega 也不会立即触发 scale-up/down 的事件,而是需要负载在一段足够长的时间内超越策略阈值,这也避免了过于频繁的伸缩策略影响读写性能。
我们在创建 Stream 时,会使用伸缩规则来配置 Stream,该规则定义了 Stream 如何响应其负载变化。 目前 Stream 支持三种配置规则:
1. 固定规则,即无动态伸缩。 在此规则下,Segment 的数量不随负载而变化。其配置接口如下:
static ScalingPolicy fixed(int numSegments)
其中numSegment指 stream 中固定的 segment 数量。
2. 基于大小的伸缩规则。在此规则下,当写入 Stream 的每秒字节数超过某个目标速率时,Segment 的数量将增加,部分 Segment 将被拆分;如果它低于某个程度,则 Segment 数量将减少,部分 Segment 将被合并。其配置接口如下:
static ScalingPolicy byEventRate(int targetRate, int scaleFactor, int minNumSegments)其中targetRate指每个 segment 所能承受的最大负载(每秒的 event 数量),scaleFactor是指每一次 scale-up 事件中的分裂系数,即 segment 一分为几,如上例应设为 2,minNumSegments指 stream 中所有的 segment 数量的最小值,用以防止过度 scale-down。
3. 基于事件数的伸缩规则。此规则与规则 2. 相似,不同点在它是用事件数而不是字节数来作为伸缩的判定依据。其配置接口如下:
static ScalingPolicy byDataRate(int targetKBps, int scaleFactor, int minNumSegments)
其中targetKBps指每个 segment 所能承受的最大负载(每秒数据量大小,以 KB 计数),其他同上。
使用时,在创建 Stream 时,将对应的ScalingPolicy对象传递给 Stream 的配置对象StreamConfig即可。
StreamManager streamManager = StreamManager.create(controllerURI);
StreamConfiguration streamConfig = StreamConfiguration.builder()
.scalingPolicy(ScalingPolicy.byEventRate(100, 2, 1))
.build();
streamManager.createStream(scope, streamName, streamConfig);Pravega 从设计初始就旨在解决流式数据的读写客户端独立扩展问题,以求达到读写扩展具有弹性,互不影响。我们来看一下以下两种场景:
场景 1:写速率<处理速率
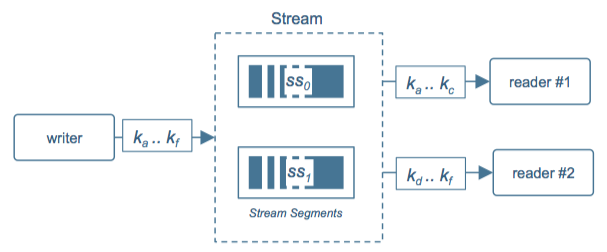
图 3: 写速率 < 处理速率
在图 3 中,处理速度大于写入速度,所以虽然只有一个写客户端,我们仍然可以将 Stream 拆分成多个 Segment,由读客户端 reader#1 来读路由键区间为 ka .. kc 的事件,而客户端 reader#2 读路由键区间为 kd .. kf 的事件。在同一读者组(Reader Group)内的读客户端会根据自身读客户端数量,自动以负载均衡的方式对应到零到多个不同的 segment 实现并行的读。而 Pravega 的弹性伸缩机制也允许读者组跟踪 segment 的缩放并采取适当的措施,例如:在运行时添加或删除读客户端实例,使整个系统能够以协调的方式动态扩展。Pravega 团队已经和 Flink 社区合作,通过监听 segment 数量改变 Flink 读取和处理 Pravega 数据的并行度,实现了 Flink Pravega Source 的动态伸缩。
场景 2: 写速率 > 处理速率
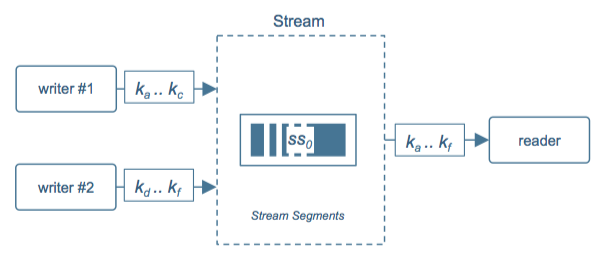
图 4: 写速率 > 处理速率
在图 4 中,处理速度小于写入速度,所以我们可以在写客户端进行并行化(由应用完成),但只需分配一个读客户端来读。由于有了 stream 和 segment 的抽象,数据存储的真正的分区会在 stream 内部实现,只要路由键不发生改变,写客户端的并行、数据量的增加并不会影响数据的正常分区。
现实情况下,我们往往会处于上述两种情况之间,并且伴随着数据源的变化和时间的推进而发生改变。对写客户端来说,Segment 的拓扑是透明的,它们只需负责路由键的分区。对读客户端来说,只需简单指向 Stream,而 Segment 的动态变化会自动反馈给读客户端。
至此,读客户端和写客户端可以分别独立地进行弹性缩放,而不受彼此影响。
我们使用由美国纽约市政府授权开源的出租车数据 (http://www.nyc.gov/html/tlc/html/about/trip_record_data.shtml), 包括上下车时间,地点,行程距离,逐项票价,付款类型、乘客数量等字段。我们把历史数据集模拟成了流式数据实时地写入 Pravega。所取的数据集涵盖的是 2015 年 3 月的黄色出租车的行程数据,其数据量为 1.9GB,包括近千万条记录,每条记录 17 个字段。我们选取了其中 12 个小时的数据,形成如图 4 所示数据统计:
黄色和绿色的出租车行程记录包括捕获提货和下车日期 / 时间,接送和下车地点,行程距离,逐项票价,费率类型,付款类型和司机报告的乘客数量的字段。我们把历史数据集模拟成了流式数据实时地写入 Pravega。所取的数据集涵盖的是 2015 年 3 月的黄色出租车的行程数据,其数据量为 1.9GB,包括近千万条记录,每条记录 17 个字段。我们选取了其中 12 个小时的数据,形成如图 5 所示数据统计:
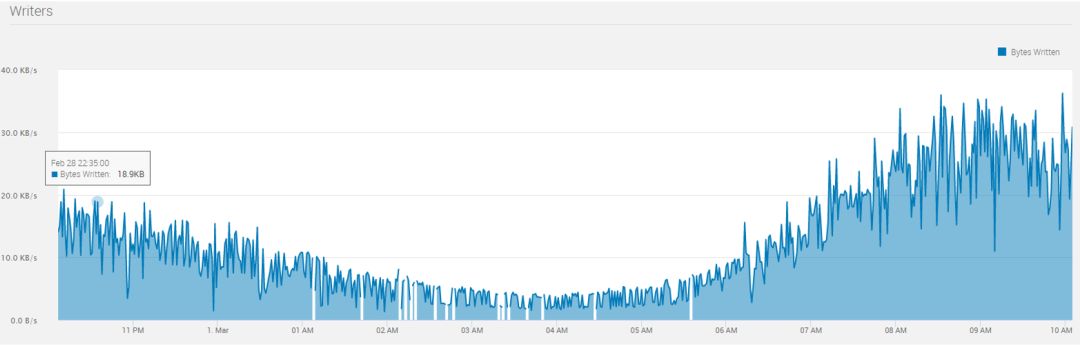
图 5: 出租车数据流量记录
由上图我们可以观察到,数据流量在早上 4 点左右处于谷点,而在早晨 9 点左右达到峰值。峰值流量的写入字节数大约为谷点流量的 10 倍。我们将 Stream 的伸缩规则配置为上述规则 2(基于大小的伸缩规则)。
相对应地,Stream 的 Segment 热点图如图 6 所示动态变化:
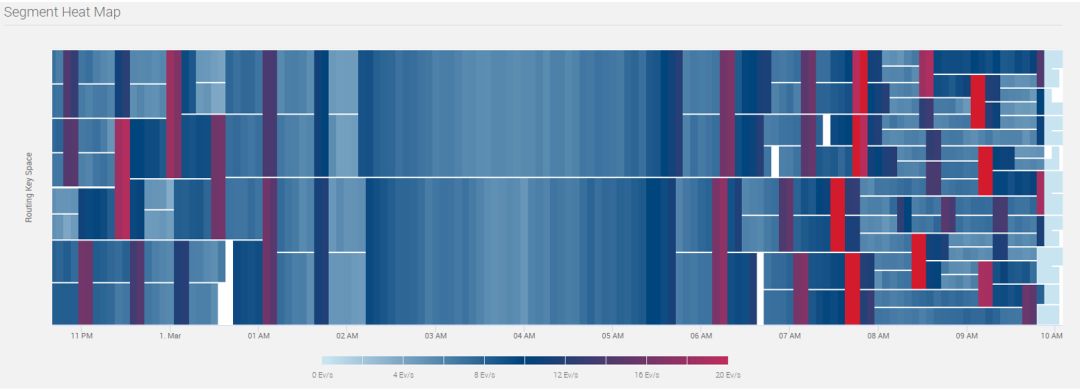
图 6: Segment 热点图
从上图可以看出,从晚 11 点至凌晨 2 点,Segment 逐渐合并;从早晨 6 点至 10 点,Segment 逐步拆分。从拆分次数来看,大部分 Segment 总共拆分 3 次,小部分拆分 4 次,这也印证了流量峰值 10 倍于谷底的统计值(3 < lg10 < 4)。
我们使用出租车行程中的出发点坐标位置来作为路由键。当高峰来临时,繁忙地段产生的大量事件会导致 Segment 被拆分,从而会有更多的读客户端来进行处理;当谷峰来临时,非繁忙地段产生的事件所在的 Segment 会进行合并,部分的读客户端会下线,剩下的读客户端会处理更多地理区块上产生的事件。
Pravega 的动态伸缩机制可以让应用开发和运维人员不必关心因流量变化而导致的分区变化需要,无需手动调度集群。分区的流量监控和相应变化由 Pravega 来进行,从而使流量变化能够实时而且平滑地体现到应用程序的伸缩上。
独立伸缩机制使得生产者和消费者可以各自独立地进行伸缩,而不影响彼此。整个数据处理管道因此变得富有弹性,可以应对实时数据的不断变化,结合实际处理能力而做出最为适时的反应。
Pravega 根据 Apache 2.0 许可证开源,0.4 版本 已于近日发布。我们欢迎对流式存储感兴趣的大咖们加入 Pravega 社区,与 Pravega 共同成长。本篇文章为 Pravega 系列第四篇,后面的文章标题如下(标题根据需求可能会有更新):
ToB 产品必备特性: Pravega 的动态弹性伸缩
Pravega 的仅一次语义及事务支持
分布式一致性解决方案:状态同步器
与 Apache Flink 集成使用
滕昱:就职于 DellEMC 非结构化数据存储部门 (Unstructured Data Storage) 团队并担任软件开发总监。2007 年加入 DellEMC 以后一直专注于分布式存储领域。参加并领导了中国研发团队参与两代 DellEMC 对象存储产品的研发工作并取得商业上成功。从 2017 年开始,兼任 Streaming 存储和实时计算系统的设计开发与领导工作。
黄一帆,毕业于上海交通大学计算机专业,现就职于 DellEMC,10 年分布式计算、搜索以及架构设计经验,现从事流式系统相关的设计与开发工作。
周煜敏,复旦大学计算机专业研究生,从本科起就参与 DellEMC 分布式对象存储的实习工作。现参与 Flink 相关领域研发工作。
http://pravega.io/docs/latest/pravega-concepts/#autoscaling-the-number-of-stream-segments-can-vary-over-time
http://pravega.io/docs/latest/key-features/#auto-scaling

喜欢这篇文章吗?点一下「好看」再走👇


