UCan下午茶武汉站,为你全面挖宝分布式存储

11月10日,UCan下午茶武汉站的活动在武汉青年光谷咖啡馆召开,在此次沙龙上,UCloud文件存储研发工程师邓瑾、块存储研发工程师叶恒、奥思数据创始人兼CTO李明宇、深信服科技存储研发专家卢波四位存储专家为到场的近百位观众详细讲解了分布式文件系统和分布式存储的技术原理和应用实践。
UCloud分布式文件系统产品架构解析
UCloud存储研发工程师邓瑾首先就UCloud分布式文件系统产品架构进行了解析。
分布式文件系统简介
邓瑾表示,分布式文件系统从概念上来说,就是经典文件系统的一个延伸,通过一些分布式技术,包括现在公有云的规模,带来了传统文件系统所不能达到的功能和特性。分布式文件系统的经典能力,第一是Scale Out,这是分布式系统的经典特性也是其基本门槛,Scale Out能在文件系统上带来线性或者近线性的容量和性能的提升。第二,通过分布式技术,依靠多副本、分布式协议、一致性协议,分布式系统可以提升单节点不能提供的高可用性和高可靠性,让上层系统可以屏蔽硬件上的故障。第三,通过公有云厂商的规模效应,它能够给应用层的用户提供比较低的TCO。
邓瑾接着回顾了比较经典的几种系统,他表示,最早期的分布式文件系统是谷歌File System,以及基于GFS开发的一个开源的文件系统HDFS,它是一种面向高吞吐场景的文件系统,它还有一个特点,就是它是一种索引,并且有一些管控节点是中心化的。
第二类系统是淘宝的TFS或者是Facebook的Haystack,它们是小文件的场景,而且是一类存放图片的对象存储系统,一个图片写入之后就不会修改了。
第三类系统是GluesterFS和CephFS,它们的共同点是都是开源的,设计理念是基于去中心化的,基于动态算法来决定存储系统的寻址,这也是大型系统比较流行的设计理念。
第四类是通用存储系统,一类是以微软Azure Blob Storage为代表的,包括阿里的盘古也是这套系统,它通过一个底层拓展性非常强的一个统一存储的接口,来支撑上面不同的业务,微软的Blob Storage都是靠这套系统来支撑的。
第五类是一些比较特定场景下的文件系统,它也是一种比较典型的设计理念,例如WAFL和PolarFS,它们都是为某些特定场景优化的,PolarFS是阿里云的一款底层的存储系统,支持的就是PolarFS对底层系统的要求所具有的特定的一些特点。
邓瑾还比较了对象存储、KV和文件存储三大类存储系统,他表示,对象存储在设计上其实是比较简单的,它是一种immutable storage,写一次后面再不会改,但是可以多次的读,例如,S3,它天生基于面向Web的优势,现在与CDN的结合,整个生态非常广泛,应用也非常广泛。但是对一些传统的应用,它需要做改造,或者需要在客户端上把这个API传成对象存储的API。对于传统厂商,比如说医院的设备,就不太愿意做这个改造,对象存储可能有一些劣势,但它的优势是文件大小没有上限。
KV的特点就是面向一些递延式场景,因为它通常会用于一些缓存场景,KV系统有非常多的变种,因此在KV选择上提供了非常高的灵活性。但是一般来说,KV系统存储容量不会太大,因为它追求高效性。
文件存储最大的优势是有一套通用的文件API,现在能够比较接近模拟API的是NFS接口。文件存储规模可以很大,而在用单机文件系统的时候,到TB级或者百TB级就会遇到瓶颈,这个瓶颈不仅是容量上的,还有处理能力上的。分布式文件系统系统主要致力于解决消除这些瓶颈,提供一个高可用的服务。
UFS发展历程
邓瑾表示,UFS是一个UCloud在前年开始研发的一个完全自主研发,面向公有云设计的一款分布式文件系统,公有云产品有非常多的类型,因为一些特定需求,在公有云场景下,怎么把这些主机融入到分布式文件的访问客户端之内,都在UCloud文件系统设计的范畴之内。
从功能上来说,UFS现在支持V3和V4,2019年会支持Windows SMB系列,UFS的基本使命是给客户提供高可用、高可靠的存储服务。UCloud有一些比较典型的产品,这些产品与对象存储、KV存储有一些区别,它有四类场景,首先是容量型文件存储类场景,即备份场景, 再就是数据分析类场景,像Hadoop数据分析平台,广电的渲染,在高性能的文件存储上都可以得到应用。第三类就是数据共享。第四类对开发者比较有用,适用于实现Layer storage,上层做一个中间层,冗余可以丢到下层,如果文件系统可以提供高可用、高可靠数据服务的话,甚至可以把它当成一个选址服务,这是对开发人员比较大的支持。
邓瑾表示,UFS的设计是利用开源软件GlusterFS快速在公有云环境中进行产品原型验证,然后从运营角度积累分布式文件产品在多租户的公有云环境中的痛点和难点,进行自研产品的设计改进,同时吸收社区经验,经过这样的过程,UFS 1.0诞生了。
1.0整体架构
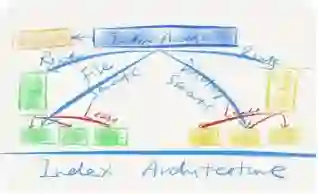
UFS 1.0首先是一个索引和数据分离的架构,它是对传统文件系统一个最直接的延伸,它不采用中心节点存储索引,而是直接把文件系统概念在分布式磁盘上模拟出来。另外,UFS 1.0的索引有一套索引管理系统,有着自定义的索引结构和语义,这将便于后续拓展非NFS协议。同时,它还具有独立设计的存储服务,并支持set管理、灰度等策略,还支持百万级大目录和TB级文件大小,也支持QoS,对多租户场景下用户的访问也做了一些隔离。最后,相比GluserFS来说,UFS 1.0数据安全性较高。
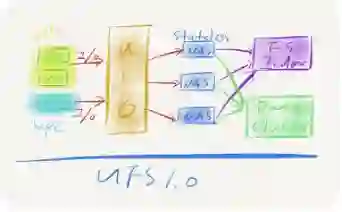
上图是UFS 1.0的整体架构,它有一个管理平面和一个数据平面,在数据平面,左边是用户访问入口,用户在他自己的网络专区,会有自己的很多主机,包括虚拟的云主机,物理云主机,托管云主机等等,都是通过VPC网络来访问接入服务,接入服务会通过UCloud的ULB负载均衡器,然后把流量导入接入服务,接入服务就是图上的NAS。
它的特点非常明确,是一个无状态的服务,包括NFS协议本身,这实际上是为了提升故障恢复的时候,客户端的启动不需要去记忆一些信息。对比单机文件系统,它也有两类功能,一类是索引,包括寻址的功能,另一类就是数据访问操作,UFS 1.0把这两类东西抽象成两个部分,紫色部分叫system index,包括目录索引,文件索引两部分。下面是数据集群,存储文件的数据,在里面做一些多副本、高可靠、高可用的文件。

索引层
如下图所示,在索引层主要就是模拟两个概念,一个是目录树,传统文件系统一个比较大的特点,就是它会有一段目录树,在下图右边有一个DIAdex,把整个目录树模拟下来。左边比较简单,它不会有层级结构,而是KV平台的结构,它会把文件需要的一些属性记录下来,这里最关键的是它跟下层的数据层会存在同一个链接中,这里会记一个FH,叫做文件距离。
这里面比较重要的一点,是如果去做一个文件或者目录索引,非常简单,就是实现一个文件和目录操作就可以了。但是它面临的一个很大的问题,如何做到水平拓展?在多节点的操作上怎么保证原数据操作的一致性?因此,UFS 1.0会把它分成很多范围,某个文件可能会在A节点上处理,某些文件在B节点上处理。因为在分布式系统当中,经常会遇到宕机,或者网络导致的节点丢失,可能某个节点就没法访问了,这时候就需要维护一个租约,这个租约会定期续约,保证系统对这个节点的某个范围,或者某个文件有处理权限,当失去这个租约的时候,必须把自己从集群当中踢掉,否则会出现两个节点都对同一个文件进行操作,就会破坏后端文件系统的结构。
USF 1.0就是靠这一套系统来实现了之前一些单机文件系统不能提供的一些功能,包括处理能力的线性拓展,因为节点处理空间非常大,几十万甚至上百万的节点对它进行调度,也可以依赖它来实现一个大文件和大目录的支持,这主要还是模拟单机文件系统的概念,UFS 1.0会把一个大文件分成很多二级或者三级的一小段一小段的数据,存到这个索引中。
数据层
在数据层,一个文件存储需要经过以下过程,首先,用户从主机发一段数据到NAS接入层,UFS 1.0会把流失的数据,就是FH代表的文件,按4M进行切分,每4M生成一个独立的IO请求发往存储层,存储层会做一个模拟,把这4M进行切分,切成64K。文件切分主要是考虑如果把一个大文件直接往存储集群上落,磁盘空间可能会不足。因此,需要把它打散,打散有两个好处,一是存储会落在各个地方,IO比较平均,也不会有特别大的热点。另外,这样可以充分利用整个集群的容量。
之后在存储层,会把整个集群分成很多个,因为它本身有很多机器,每个机器上有很多磁盘,UFS 1.0把每块磁盘分成很多个chunk,把空间分散之后,还会带来一个好处,当发生某个chunk有热点的时候,可以把它调到别的地方去,但如果chunk非常大,调度也没有特别大的意义,所以要先做一个chunk切分,每个chunk有三个副本,这三个副本组成了chunk group。当一个IO请求进来的时候,这是一个最多4M的文件,会切成64K,每个64K会写到某一个chunk group上,这64K就并发往这些chunk gourp上去写。
下图就是存储层一个简单的模型,右边蓝色的就是多集群灰度管理的系统,它可以暴露给前端业务,说明有多少集群可用。紫色的index是记录4MB分片切成64K的一个对应关系,为什么要存这个呢?因为必须要知道这个64K是存在哪个chunk的,通过查询它在哪个chunk,再去定位到真正的chunk所在的三个副本当中的任意一台机器。
UFS 1.0的局限
邓瑾介绍,UFS 1.0运营了一段时间后,发现这个存储模型,因为支持NAS的一些随机或者覆盖写引入小分片的概念,但这个分片太小了,导致存储层那边很难模拟一个超大文件。 然后就是底层的存储,它是一个固定的64K,不管写不写满64K,都要占用64K,这在规模很大的时候,会形成一定的空间浪费。第三是存储层支持的文件尺度较小。第四就是对随机写的支持不够,在做FIO,做4K这种写的时候会发现延时会比较高。

UFS 2.0存储架构
针对UFS 1.0的局限,UCloud进行了2.0架构的升级,主要对存储层进行了优化,优化不仅仅针对NAS服务,而是进行了面向统一存储场景的整体设计和优化,它支持超大文件,冗余机制也更灵活,同时,它通过与新硬件和软件技术栈的结合来实现低延时高性能的场景。

Append-only模型
在底层的Stream layer,是真正的统一存储的概念。每个存储的文件,称为Stream,每个Stream是永远可以追加写的,但是它分成了很多小分片,叫做Extent,UFS 2.0把这个Stream切成了一大段一大段很大的Extent,而且只有最后一个Extent是可以进行追加写的,中间一旦写完之后就再也不能改变。它带来的好处,是这种模型非常简单,不会担心数据篡改或者曾经写过的数据被覆盖掉,或者没有办法回轨,因为Append-only可以很好模拟快照功能,有整个操作的历史记录。每个Extent被分配三个或者N个多副本,会满足一定容灾的要求,来保证副本的高可用。
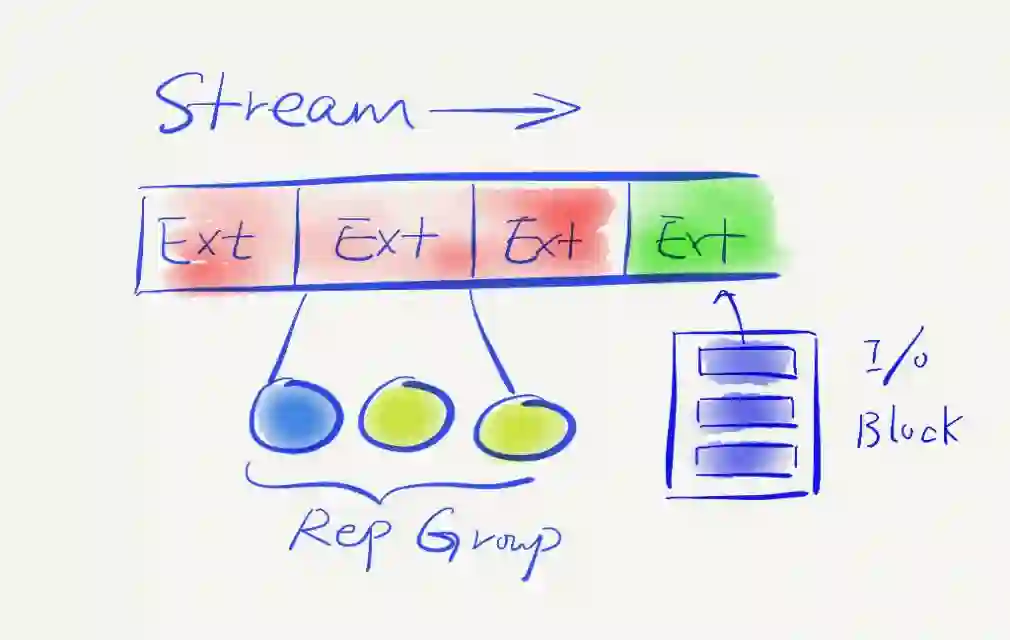
每个Extent是以文件的形式落在存储介质上,文件可能会比较大,现在是4GB一个Extent。用户在写的时候是以Block为单位,往Extent上面追加,这个Block是不固定的,每次往里面追加写之后,Extent觉得达到一定的量就可以关掉,再新开一个,这即是Append-only整个的模型。
数据层
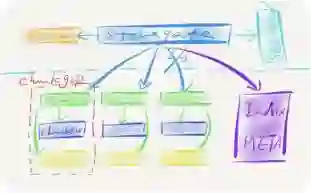
Append-only模型里有几个模块,绿色的streamsvr,它管理Stream的功能,做Stream的创建,分配副本,副本所在的位置等。它会把原数据存储在数据库当中,Streamsvr会有一个master对外提供服务。Extentsvr做一些数据的持久化。
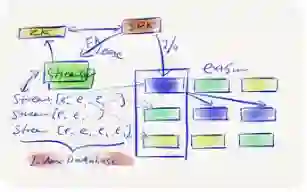
Extentsvr的存储引擎设计有两个功能,一是消除写入毛刺,另一个是功能持久化一些还没有落地的索引更新或者是更新操作。数据来了之后,会先落,然后更新,把它放在内存里,这个时候就可以返回成功了,业务侧就可以收到,进行访问。FileLayer的机器是高内存的,可以对数据进行缓存,它可以把整个热点给打散,降低单节点访问压力以及数据读取的毛刺。FileLayer还把整个底层Stream提供的存储空间切分成很多个数据单元,以便于做负载均衡。
针对随机写,依然是利用底层的方式,把数据先追加下去,追加是追加在Date Uint(DU)提供的文件上,这样就可以直接反馈给用户这个随机写完成了,而不需要去读老数据进行合并。带来的开销可以通过软件方法去优化它。此外,针对没有办法结束对DU写的问题,会对数据进行分片,每个分片的最小颗粒度是100GB,每个DU只有一个fserver进行处理,从而实现随机写逻辑。
分布式存储中的数据分布算法
奥思数据创始人兼CTO李明宇则具体讲解了分布式存储中的数据分布算法,他的讲解分为四部分:一致性哈希算法及其在实际应用中遇到的挑战、典型的“存储区块链”中的数据分布算法、典型的企业级分布式存储中的数据分布算法以及比较和总结。
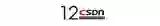
一致性哈希算法及其在实际应用中遇到的挑战
李明宇表示,常见的在分布式系统中的数据分布式算法,就是一致性哈希算法,一致性哈希算法在实际应用中会遇到很多挑战,一方面是应用在云存储或者企业级存储里面的挑战。另外就是在比较新的一些研究方向,比如说区块链或者区块链存储等的方面,也会遇到一些挑战。

哈希表及其在分布式系统中的问题
如果用一致性哈希做数据分布,经常会用到数据结构是哈希表,哈希表是把一个空间划成N个区域,比方有一个字符串,假如这个字符串是一个文件名,根据这串字符串,会得到一个哈希。现在假如说有八个存储位置,那么,这些数据会放在哪个存储位置呢?哈希算法正是有着这样的作用,因为哈希具有非常好的随机性,因此,通过哈希算法对文件的文件名字符串进行哈希,就可以把这些数据均匀地分布到六个设备上。
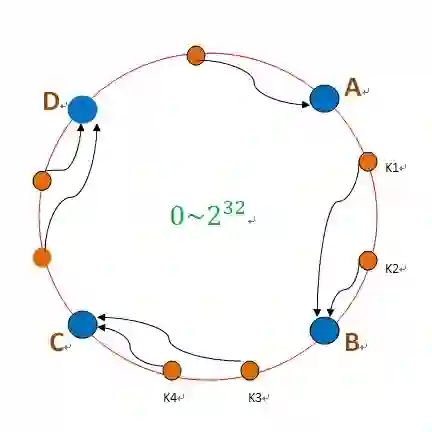
但这种算法看起来很好,却会带来一个问题,因为在分布式存储里面,随着存储的数据越来越多,系统可能就要扩充节点。而这时如果用哈希算法来算,很多数据都需要重新去分布。而当增加的节点越来越多时,几乎所有的数据都要去移动,数据迁移的开销是非常巨大的,系统将会无法承受。为了解决这个问题,有人发明了一种算法,将存储平面圈起来,形成一个哈希圈,首尾相接,这样就可以让增加的数据更均匀的分布在设备上,而且不需要移动太多数据,比传统的哈希表好很多。
但即使是这样,如果需要增加一块硬盘,还是要移动很多数据,为此,就引入了虚拟节点的概念,一块盘不再对应一个位置,而是对应多个位置,这样,从概率上,分布的均衡性就会好很多。此外,当有硬盘出现故障需要退出时,这种方法也会分散数据迁移的压力,这就是一致性哈希算法。一致性哈希算法具有不需要查表或通信过程即可定位数据,计算复杂度不随数据量增长而改变,效率高、均匀性好、增加/减少节点时数据迁移量小等优点,但在企业级IT和存储区块链场景,仍然面临很大的挑战。
企业存储会用到一些方式,比方说多副本,如果随机找几个位置去分布,很可能会造成副本落在同一台服务器上的情况,这种情况,企业级IT是无法容忍的。还有在存储区块链场景下,它需要用到全球的资源,让大家自发参与进来,组成一个跨全球的大的分布式存储系统,如果在这里面根本不知道有多少设备,也无法控制所有设备,如果来了一个存储对象,算出了一个哈希值,就不会知道这个哈希值究竟会映射到哪个设备上,因为这个设备可能随时出现,随时退出,是全球参与者自发参与的,无法控制。所以几乎不可能获得一个全局视图,而且一致性哈希环中的设备是随时都会发生变化的,甚至没有一刻是稳定的,这将带来很大的问题。

典型“存储区块链”中的数据分布算法
那么,存储区块链刚才说的这种场景,应该怎么解决?在此之前,首先需要清楚存储区块链的概念,它是分布式存储或者去中心存储或者P2P的存储加上区块链,它的目的是通过区块链的机制,通过token的机理,鼓励大家贡献存储资源,一起组成一个大的存储系统。存储区块链的代表项目有Sia,Storj,IPFS+filecoin。
但如果是全球用户自发参与,就没有去中心化的存储系统的寻址和路由的问题,但因为参与者随时可以加入和退出这个网络,就需要解决这个问题,这在历史上已经有一些代表算法,比方说Chord、Kademlia等等。
这些算法,实际上最根本的还是一致性哈希算法,Chord更难理解一些,如果有一个数据要存储,这个数据文件名是K,数据相当于是V,整个P2P存储网络里面有一些节点,这些节点算出来的哈希值是14、21、32、42等,如果算出来哈希值是10,它比8大,比14小,它就应该顺时针放到8和14之间的节点上,以此类推。在一个真正的P2P存储网络中,节点数量是众多的,所以按照这样顺时针存,和一致性哈希没有任何区别。现在问题是,在没有任何节点知道到底有哪些节点参与到这个网络中时到底应该怎么办?Chord采用的方法是,既然没办法维护,就不维护,如果有一个数据,K就是其文件名,算出来的哈希值是54,那么,它先不管数据到底存在哪儿,首先和最近的一个节点比较哈希值,如果比临近的大就继续往下寻找,如果比自己的小,就存储在该位置,并进行反馈。这样,新加的节点并不需要其他节点知道,因为新加入的节点会向周围的节点去广播自己的存在,按道理说,总有概率说有些节点知道是新加入进来的,这样找下去,总是能找出来。
Chord
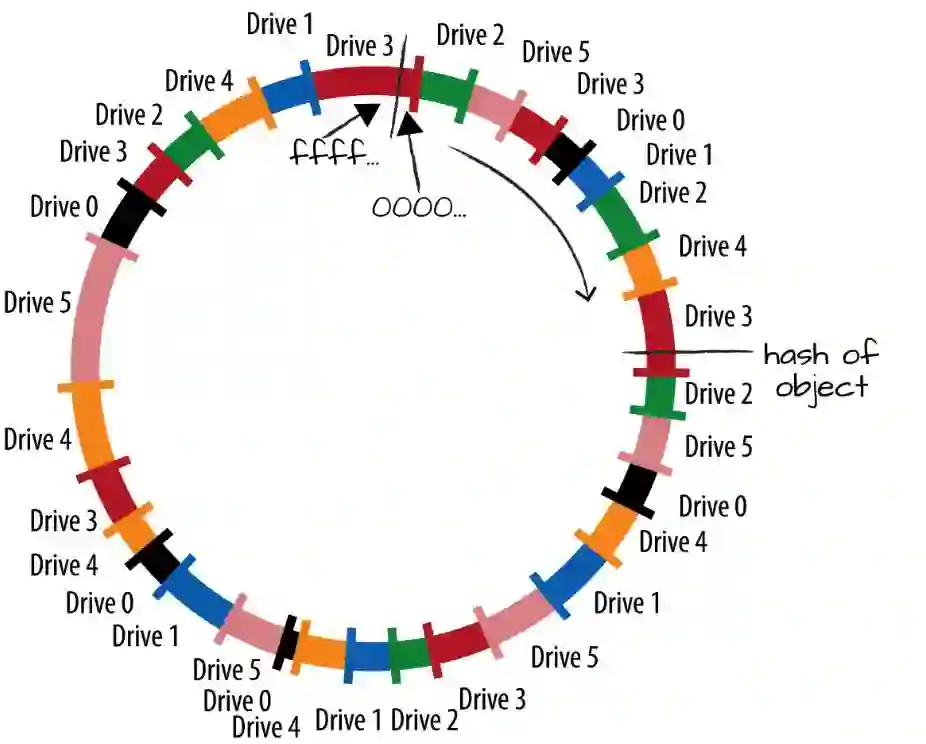
但这样的算法非常低效,一圈下来,延时很高。而降低这个延时有两种办法,一种办法是多存几份,降低延时的同时能提高可靠性,Chord中的一个最大的改进是Finger table,它不仅仅记录自己的下一个节点,最临近的节点,还记录自己的2的i次方加1的那个位置,这个i的最大值就取决于Finger table用几位来表示产生的索引,所以它能够记录最临近的,最远的,或者说是一半远的,1/4远的,等等的节点。这样的话,如果要搜索一个数据,就没有必要像刚才那样挨个去找,可以直接进行跳转,这样就把计算复杂度降低了,这就是Chord算法。
Kademlia
在此基础上还有另外一个算法,就是Kademlia,它跟Chord算法比起来有几个不一样的地方,首先计算距离的时候,并不是在用数值的大小去计算,而是用XOR计算,因此计算的复杂度就会降低。另外一方面,它设计了一个数据结构叫做K-桶,比如当前节点的id是0011,最近的节点是0010,所以它就用这种方式来表示距离,而在寻找的时候,其方法是与Chord算法是形同的。
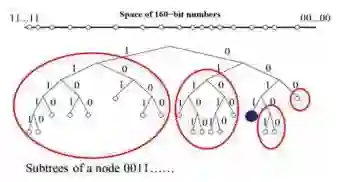
另外与Chord相比,它支持并行搜索,这样就解决了没有全球视图的问题。因为不需要掌握全局到底有哪些节点参与的情况,每个节点都会周期性的向周围发请求,如果有节点退出,就会被发现。如果有新节点加入,新加入的节点会往临近节点广播它的存在,所以也会被发现,节点之间互相可以联系上。
典型的企业级存储中的数据分布算法
具体到企业级存储里面,这个问题变得更加复杂,关于企业级存储中间典型的数据分布算法也有一些,比如像Dynamo里有Amazon,Ceph里有CRUSH的算法等等。这些算法都有一定的相似度,都是要对数据算哈希,对数据的K算哈希等等,然后再做映射关系。这些算法还引入了对数据中心物理拓扑的建模。比如Cluster Map,一个大的存储集群,分几个数据中心,每个数据中心下面可以再分zone,zone下面再分机柜,机柜下面再分节点等等,它会把这种拓扑结构给记录下来。这样的话,数据的分布就会根据Cluster Map分布到不同的故障域里面,这样当一个故障域出现问题的时候,数据不会丢失,数据仍然可以访问。这些算法中还有对节点划分的权重,数据分布和容量/性能匹配,辅助扩容以及多种存储策略选择。
李明宇最后表示,归根到底,各种算法的源头都是一致性哈希,因为不同的需求,有不同的改进方向。企业级的更注重副本故障域的分布,对于P2P存储更注重在节点随时退出随时加入的情况下,怎么样保证数据能够在有效时间内寻址。
云硬盘架构升级和性能提升
UCloud块存储研发工程师叶恒主要就云硬盘架构升级和性能提升进行了讲解。
云硬盘架构升级目标
叶恒首先介绍了云硬盘架构的升级目标,第一,解决老架构不能充分使用后段硬件能力的弊端。第二,支持SSD云盘,提供QoS保证,可以用满后端NVME物理盘的IOPS和带宽性能,单个云盘可达2.4W IOPS。第三,充分降低热点问题。第四,支持超大容量盘,一个云硬盘可以支持32T,甚至可以做到无限扩容。最后就是新架构上线之后,怎么样让老架构迁移到新架构。
IO路径优化
而叶恒认为要达成这样的目标,首先需要对IO路径进行优化。下图是新老架构的架构图,主要是IO路径上的,左边是旧架构,VM、Qamu,云硬盘是挂在虚机里面的,通过虚机来到Qamu的驱动,然后转化到Client,Client之后会将IO转到后端的存储集群上,分两层,第一层是proxy,IO的接入层,然后再分到chunk,就是读写一块磁盘,后端的chunk是一个副本的形式。
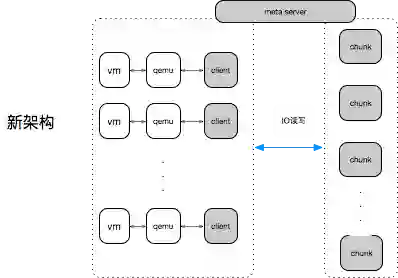
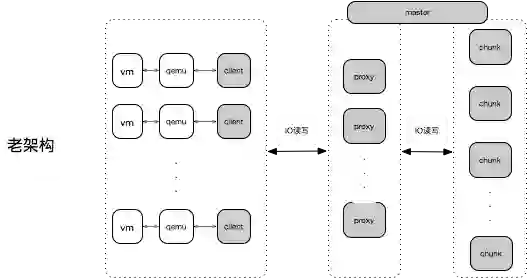
而在新架构中将IO的接入层去掉,直接将路由的功能做到client,直接连接到后端的存储节点。这样的话,在写的时候,从client直接到chunk,因为三副本内容是完全一致的,读只要读主chunk就可以了。因此,读路径上就减少了一次网络转发,相比于老架构的话,由于软件的升级,随机测下来,写延时也有所降低。
元数据优化
在老架构中,分片大小是1G,新架构中,支持了1M大小的分片。1G的分片最多只能发挥一块物理磁盘的性能,对于普通硬盘,它后端的存储介质是机械盘,性能有瓶颈。1M的分片会带来很多好处,首先解决了热点的问题,还可以充分发挥后端集群性能,因为1M的分片,如果客户的写在1G的范围内,端能用到1024的分片,整个集群的性能就会全部发挥出来。
在数据组织方式方面,在老架构中,按索引的方式来组织元数据,申请一块云盘时,所有元数据分配成功,并持久化到元数据模块,挂载云盘时,将所有元数据load到内存中,后续IO访问直接从内存获取路由。这样看起来似乎没有什么问题,但在并发创建和挂载的情况下,如果有几千个盘同时挂载,如果按1G的分片,300G的云盘,300条的元数据,按1M的分片,300G是30万条,它同时创建100块300G的云盘,需要分配3千万条元数据,挂载也是一样的,同时要从元数据模块加载3千万条数据,这对元数据模块的设计难度是极大的,它会成为一个瓶颈。
因此在设计过程中,考虑过多种方案,方案一仍然保持带索引的存储方式,但在创建的时候不分配,把元数据延时分配,只有当云硬盘上某个分片上有读写的时候,才向元数据请求,这样的IO延时分配,好像是能解决问题。但如果这个时候用户开机了,几千台一起开机创建好了,想做个测试,或者开始用了,同时对这100块300G的云盘做一个随机的写,随机的写会落到每个分片上去,这样看,元数据模块仍然是个瓶颈。
第二种方案,选用了一个一次性哈希,一个节点下线了,但是没有机会去迁移或者分配到同一个故障率里面去,这时通过后端的chunk服务,按三个三个一组,组成一个所谓的PG,PG就是备份组,将这个备份组作为物理节点,因此,物理节点就不是一个存储节点了,而是一组备份级。当这个组作为物理节点插到这个环上之后,会作为虚节点放大,放大三、四千倍,保证这个环大概在几十万左右,不能超过百万,因为构建这个环需要时间,如果这个环太大,重启时间就会过长。而且这三个chunk也不是随便写三个chunk,按照容灾的策略,这三个chunk组成一个PG,分别在三个机架中,如果机架断电,最多影响一个。
把这三个chunk组成一个PG作为物理节点插入到这个环上,然后一个节点放大成几千个虚节点,用户创建一块盘,上面每个分片派来IO之后,用这个盘唯一的ID,加上这个分片,去做哈希,哈希之后落到中间,找到了PG之后,它里面包含了三条chunk的路由,将这个IO转发到后端的主节点,由主节点去同步,主节点直接返回就可以了。
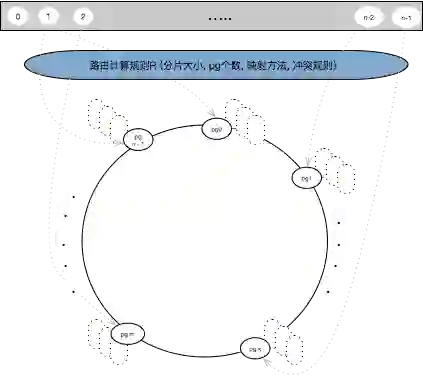
通过这个方案,以前动辄几千万的数据量,就是PG的个数,后端是chunk的一个路由,然后就是构建这个环的几个参数,一个是映射的算法,一个是虚节点的放大倍数,以及冲突解决参数。这样当云构建起来之后,向元数据模块请求这几个参数,最多是几千条,之后再构建这个环,这个环构建好了之后,有IO过来的时候,只需查这个环。而当查第一次的时候,系统会把计算好的路由记住,最后就可以直接找过去,非常快。这样的话就完全解决了上述问题,同时创造几千个盘是完全没有问题,同时读写也没有问题,这时因为读写过程中不需要去分配,因为全是计算出来的。

线程模型设计
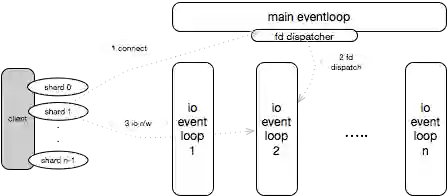
具体到软件设计就是线程模型设计,我们知道HDD与NVME性能差别有几百倍。原来的软件设计用一个线程就可以,一个CPU用满的话,一个核跑几万没有问题。但现在的软件没办法去发挥这种硬件的能力,所以需要改变线程的模型。
在新的架构中,在云端,采用了多线程的方式,每挂载一块云盘的时候,会分配一个线程专门用于IO转化,后端是线程池,main eventloop就是IO线程,当某一个分片查这个环,发现要跟后端的某个chunk通信,第一个连接分配到IO路径1,循环派发,整个IO线程负责的连接就是均匀的。假如一个IO线程跑满能跑5万IOPS的话,现在跑130NVME,用它来管理线程30万的NVME的话,六个这样的线程就可以了,完全可以发挥硬件的性能。
防过载策略
任何一个存储系统,都有一个过载保护的功能,比如说挂载了几千块盘或者几百块盘,用户同时测试,落在存储的某一个硬盘上,并发有几千NVME,如果不做过载保护,IO将会全部超时。在新架构中,对于普通的云硬盘,会限制物理盘上IO提交队列的深度。
在实际代码实现的时候,要考虑到权重,云硬盘的大小不一样,大的云硬盘,用户要多付费,更大的云硬盘,会获得更多的发送机会。对于SSD云盘,传统的单个线程会是瓶颈,难以支持几十万的IOPS以及1到2GB的带宽。新架构会监控每个chunk的IO线程CPU的使用率,如果发现长时间CPU使用率都是95%或者100%,就会去通知这个chunk,断开IO线程里面一部分连接,分配到其他线程,实现了负载均衡的效果,使得每个线程的压力都是均匀的。
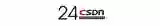
在线迁移
叶恒介绍,为了帮助用户从老架构向新架构迁移,UCloud为用户提供了一套在线迁移系统,在进行迁移时,首先要把下图中上部的clond old断掉,连上trons cilent,同时写一份到新老架构,然后通过trocs模块,当所有的存量数据都搬迁完成之后,这一次迁移就完成了。迁移完成之后,qemu就可以跟trons cilent断开连接,连上一个新的cilent。这样在迁移的过程中即使出现什么故障,重启之后,老架构仍然可用,从而降低了迁移的风险。

超高性能云盘
叶恒还介绍了UCloud正在研发的下一代超高性能的云盘,单个延时可以降低到100us,IOPS单盘可以突破百万。而要达到百万的IOPS的话,则需要用到用户态、zero copy、polling mode,这几个技术。用户态就是把原来在内核态做的事情,比如网卡驱动,磁盘驱动,拿到用户态来做,直接在用户态操作设备。polling mode,是为了解决CPU与存储硬件的性能差异,使用polling mode,将会大大提升性能。zero copy,是指原来数据发一个包,需要从这个态拷到那个态,但现在完全在用户态操作硬件的话,就是零拷贝,可以直接发出去。
UCloud是全链路的改造,因此,client端用了VHOST,网络端用RDMA,后端提交用SPDK。分别看一下这三个技术,在clinet端,原来数据从qume拷贝,现在数据直接VM,直接与clinet共享,这样,只要做虚机的物理地址到后端物理地址映射,直接通过共享内存的方式就可以了。
在网络通信部分,采用RDMA,DMA直接访问内存,绕过CPU,从而降低CPU的使用率。RDMA直接访问远端的内存,这样就实现了通信的作用。
在后端,直接是SPDK,SPDK直接从用户态来操作固态硬盘,当挂一个盘到机器上,在内核里看不到,通过采用polling的方式,实现零拷贝,IO提交的延时非常低。
叶恒透露,在测试中,该高性能云盘,单盘IOPS突破了百万。预计此款超高性能云盘将会在12月底推出公测版。
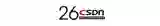
基于Cephfs的改进及优化
深信服科技存储研发专家卢波最后一个登场,他就Cephfs的改进和优化进行了详细的分析。

Ceph及CephFS的背景
卢波表示,Ceph是分层的架构,底层基于CRUSH,Ceph分布的策略是针对分级的哈希,跟一致性哈希有区别,它是区分故障域的,分了两级,第一级是对象到PG的映射,就是根据对象进行一个哈希值,然后根据PG数举模,最后得到这个数据对象分布在哪个PG上面。PG到Ceph底下,它的每一个存储设备OSD,叫做对象存储设备,PG到OSD之间,就是通过CRUSH算法来进行的路由。它的底层是基于RADOS,它是可靠,自动的分布式的一个对象存储,具备的特性可以自修复,迁移,容错,上层提供了对象存储、块存储和文件系统访问三种方式。CephFS支持多种协议,最早起源于2007年Sage Weil的博士论文研究,最开始Ceph针对的应用场景更多是针对高性能计算,需要高扩展性大容量的文件系统。
像Ceph这样的分布式操作系统的出现,源于传统单机文件系统的局限,第一是共享没办法在多个机器中提供应用访问。第二就是单个文件系统容量是有限的。第三是性能,传统的文件系统它可能没办法满足应用非常高的读写性能要求,就只能在应用层面做拆分,同时读写多个文件系统。第四是可靠性,受限于单个机器的可靠性以及单个硬盘的可靠性,容易出现故障导致数据丢失。第五是可用性,受限于单个操作系统的可用性,故障或者重启等运维操作会导致不可用。
而这些特点对于企业级的应用或者私有云来说,是无法接受的,在这种情况下,就出现了CephFS。CephFS最早是一个博士论文研究,它实现分布式的元数据管理以及可以支持EB级的数据规模,后续专门成立了一个公司来做CephFS的开发,在2014年被Redhat收购,2016年CephFS发布可用于生产环境的稳定版本发布了,目前主要应用还是单MDS。

CephFS的架构
CephFS的架构不只是CephFS,包括Ceph也在里面,第一个部分是客户端,第二部分就是元数据。文件系统最核心的是数据,所有文件的访问,首先离不开源数据的访问,与块存储不一样,块存储就是直接指定哪个硬盘的哪个位置,有了地址,就可以去读取那个固定的数据。但Ceph的文件系统是有目录结构和层级结构,要管理这样的目录结构,需要通过元数据来实现。
Ceph MDS也是元数据架构,可以理解为它是一个元数据的缓存,是一个元数据服务,本身并不存储数据,它最终的数据是存在底下的RADOS的集群下面,MDS本身是不存储数据的。当客户端要写一个文件,首先要打开这个文件,这个时候客户端会跟MDS通信,去获取它的距离,客户端拿到之后,通过一个哈希,找到它位于哪个PG里面,直接通过计算的方式,不再需要去跟MDS交付,确定了哪个PG之后,再把数据发到对应的数据值上面去,并且它的元数据和数据是分开的,可以存在不同的存储池中,这种设计也是分布式文件系统设计的跟传统文件系统不一样的地方。

MDS的作用
MDS作为元数据的缓存,同时控制元数据的并发处理,主要的作用有下面几个:第一,要提供文件资源,要对客户端以文件的方式,同时兼容POSIX的语义。第二,要提供一个文件系统命名空间,它要通过MDS能够构建出分布式文件系统的一个目录树,一个层级结构。第三,要管理文件的元数据,比如inode、dentry这样的文件元数据。第四,它需要持久化文件元数据,把元数据存储到一个可靠的存储设备上面去,在异常的情况下,保证这个数据是持久化的,可读的,不会丢失数据。
MDS具有并发控制的流程,多个客户端可以同时跟MDS通信,MDS通过一个锁来处理这个请求,同时客户端跟元数据交互的时候,除了获取元数据信息之外,它还要知道客户端是不是一个有效的客户端,这个客户端是不是能进行读或者写操作,以保证数据的一致性。
当MDS收到这样的请求之后,会通过lock machine的模块,去判断这个请求是不是可以正向操作,以及去覆盖刚才访问的权限,最后会把这个请求返回给客户端,然后会返回文件的元数据信息。
MDS是CephFS的一部分,另外CephFS还有三个点,MDS是实现元数据的分离,管理元数据,作为元数据的缓存,另外MDS是一个集群,可以有多个MDS,它是利用动态指数分区的技术,每一个MDS管理一部分的目录,一个MDS可能负责一部分目录层级,另外一个MDS负责另外一部分层级,这样它可以做到很好的扩展性,它的性能也能得到提高,达到一个线性提升的目的。当然,现在还是单MDS的方式相对可靠一些,这是未来的方向。

Ceph的优化实践
针对Ceph的问题,最直接和比较常见的想法,是缩短它的IO路径,解决小IO的写放大问题,第二,当前Ceph的IO路径过长,延时高。第三,提升文件的元数据写操作的性能。第四就是支持写缓存的方式。第五,对读也可以通过缓存进行加速。第六,Ceph最早出现是针对廉价的节点或者是服务器来设计的,但是现在的技术发展,有些在设计之初没有考虑到,当然现在也在改进,这个优化也是能够充分利用SSD或者新的网络传输介质这样的优点来提高它的性能。
在业界,在这方面优化的思路有几种,OceanStor9000的缓存,是一个典型的分布式文件系统,它通过全局的缓存,来实现任意节点上的文件,它会对文件进行分条,任意节点收到数据访问请求之后,都会从这个缓存里面去看,是不是这个缓存命中了,如果命中的话,这个时候直接返回客户端。写的话,首先直接也是写到这个缓存里面,通过缓存的全局化,以后后台缓存数据的全局化,去实现性能加速。缓存的一个目的除了缩短IO路径,还有一个好处,是可以把小的IO合并,形成一个大的IO这样一起写下去。
Fusion storage的处理思路是一样的,也是用到了EC,如果是大IO直接写EC,大IO直接用硬盘的存储能力。但是小IO,就会通过EC Cache,写到Cache里面,这次IO结束了,就直接返回到客户端。但后台要保证这个Cache的数据最终持久化到HDD上面去,同时会进行IO的聚合。
Isilon是另外一个,这是NAS最早的一个产品,它里面缓存的分层分三层,第一是内存,第二层用到NVRAM的介质。第三层才是SSD。
Intel的思路是一样的,因为它的IO路径比较长,Intel提出了Hyper Converged Cache的思路,把这个开源了,这个思路是说,在客户端就是由SSD来进行读写加速,它把后端的Ceph作为一个慢存储来使用,在块和RGW场景中,作为读缓存没有问题,如果要作为写缓存,就涉及到冗余的问题,所以在它的设计里面,做写缓存的时候,是用到了DRBD这样的双拷贝,写到缓存里面的时候,会做一个多副本。
通过加了这样的缓存之后,可以看到Datrium公司基于这样的架构,做了一个缓存的实践,给出了一个性能,可以看到对于IOPS提升是非常可观的。这里有一个问题,多了一个缓存对于Ceph来讲是很难受的,为什么?因为通过DRBD的方式,可靠性还是比较差的,对Ceph扩展性是打了折扣的。另外一个,这个缓存要实现数据的持久化,不可能是主备的方式,因为这样也是会降低可靠性的,所以要实现这样的缓存,是要实现分布式的一个管理逻辑。
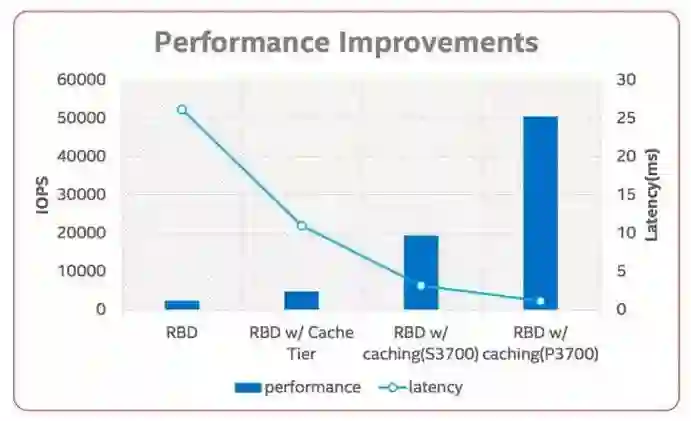
卢波介绍说,针对这些问题,整体的思路跟前面几种产品是一样的,通过增加的块存储,来缩短IO路径,进而提高小IO的性能。但是这个缓存底下是一个分布式的使用场景,所以这个缓存本身也是一个分布式的缓存,下面是此架构的架构图。
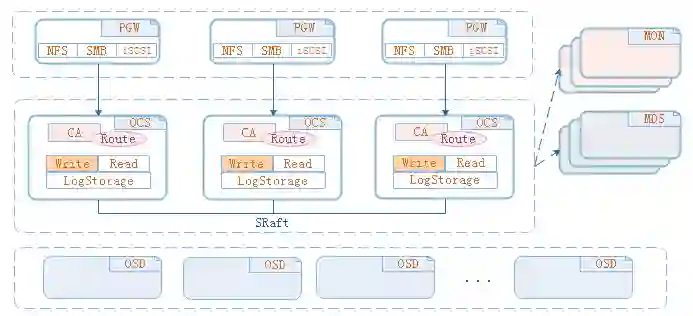
这个架构与Ceph相比,只是在中间多了一个OCS的缓存服务,缓存是一个独立的服务,从客户端请求,也叫做CA,是NFS过来的请求,都会转化到缓存服务上面来,在缓存服务里面,根据数据分布策略,就知道这一次操作到底要写在哪一个缓存节点上面去,选到这个缓存节点之后,缓存节点实现多副本的数据分发,等多处副本完成之后,再返回给客户端,这次操作完成,这是一个正常的写入流程。
写入之后,这个数据后台是会定期根据水准高低,把缓存的数据直接放到底层的Read存储上面去。一方面利用了缓存加速的性能,另外一方面,可以利用Read的全局化性以及它的扩展性。
读流程也是一样的,因为缓存对于小IO可以最大限度发挥空间的优势,但是对于大IO,不需要经过缓存,直接写到底层的Read上去。另外通过索引的方式,也可以知道具体写到哪个缓存节点上去,大体流程就是这样。而经过这样改进之后,该系统的IOPS确实得到了提升。
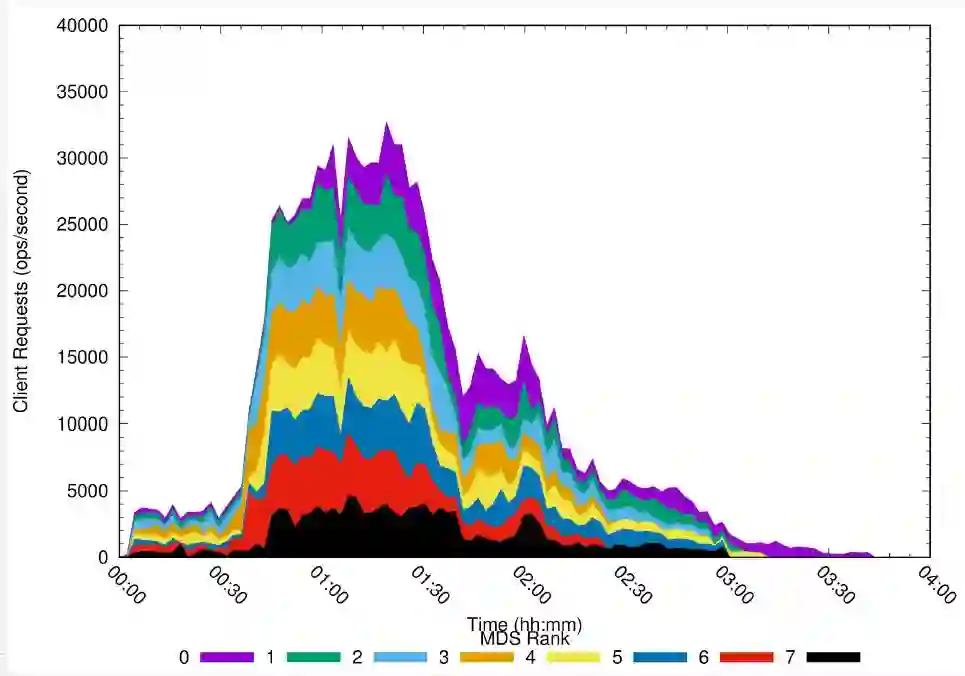
Ceph未来展望
最后,卢波认为,CephFS最有杀伤力的一个东西,就是多MDS,即动态指数分区这样一个技术,这方面在社区也会有一些深度的开发和讨论,也在进行一些测试。下图就是多MDS的技术原理,多个MDS去负责不同的目录树的元数据访问,当客户端来请求的时候,会去到不同的MDS,在这个MDS里面,它去实现元数据的管理以及数据间的访问。这是多MDS性能的对比,明显可以看到,当8个MDS并发测试的时候,其性能基本上是可以达到线性增长的。