滴滴推理引擎IFX:千万规模设备下AI部署实践


文章作者:蔡金平 滴滴专家工程师
内容来源:滴滴技术
01

架构
在服务业务的过程中,我们发现纯粹的推理引擎已经很难满足业务高效的发展,因此,我们对平台进行了逐步的迭代与升级,将其分为 4 层结构:接入层,软件层,引擎层,算力层。

-
local inference 需求:提供各类编程语言接口的 SDK -
remote inference 需求:提供 http/thrift/grpc 等接口的标准服务化 api -
授权与埋点:提供安全授权接入方案,提供业务模型 inference 相关可视化报表
-
模型瘦身:提供更小的模型文件,降低 SDK 大小,同时提升在线升级模型速度 -
模型加密:确保模型结构安全性,不容易被破解 -
版本管理:解决业务迭代过程中,多个模型版本管理问题 -
自动测试:模型解析,带来精度差异,自动测试保证训练模型和推理模型表达一致性,同时也会测试模型推理性能以及硬件设备适配工作
性能诊断器:为引擎层提供离线性能诊断工具,剖析模型在不同硬件设备上的表现,同时指导 kernel 优化,模型结构优化等工作
引擎瘦身与混淆:提供更小的体积以及安全的内核
算子优化:主要整合低精度、图优化、异构调度、汇编优化等能力,同时提供 auto tuning kernel 的能力,为专用硬件提供最佳的汇编实现
系统优化:除了计算本身,提供系统调度、I/O、预/后处理等耗时环节的优化
基于架构的升级,IFX 团队进一步打造 AI 部署产品化解决方案,争取为业务提供更加系统化的支持。主要围绕以下 6 个方面进行能力建设。
▍高性能
为保障业务的核心竞争力,模型执行速度对于成本、安全、业务效果等影响非常大,我们针对推理引擎内核以及全链路进行了一次性能改造,在业务性能上,得到了不错的效果。
汇编级优化:核心 op 汇编优化,模型性能提升 40% - 200%
全链路优化:预处理、后处理、网络调用链路优化,服务化性能提升 30 - 260%
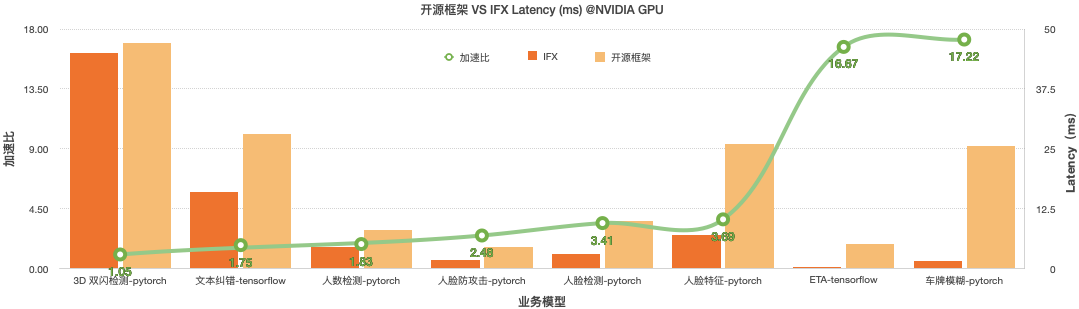
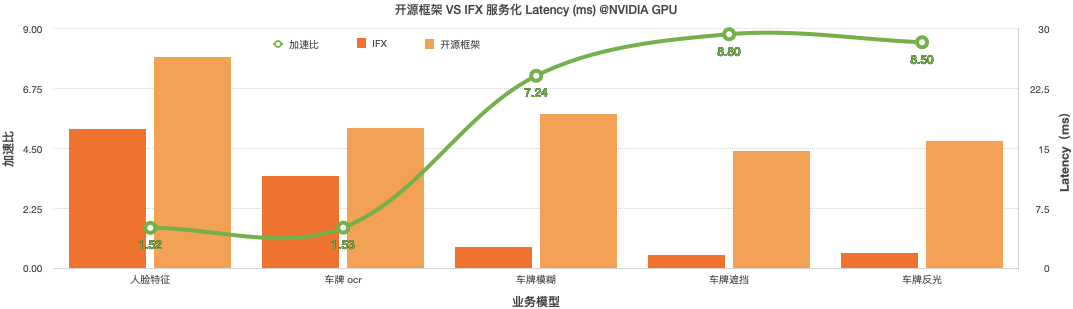
服务化性能对比
▍精巧性
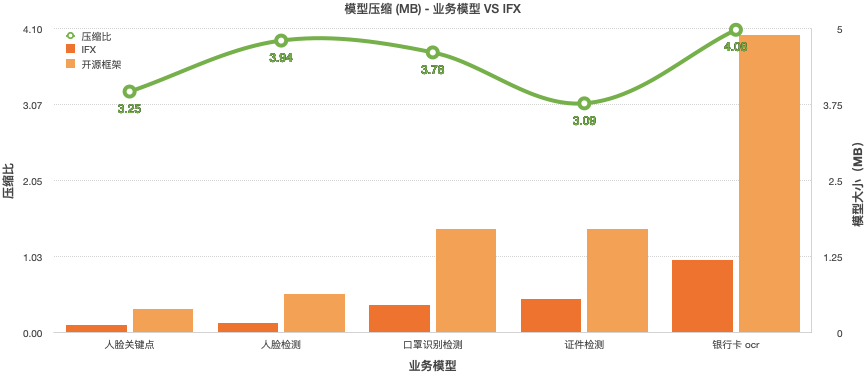
为降低 APP 包大小,提升用户体验,我们专门针对引擎以及模型,做了大量的裁剪和压缩工作。
模型压缩:多种压缩策略联合驱动,压缩不降低精度,压缩率 < 25%
引擎压缩:二进制 elf 压缩,进一步降低 SDK 大小,通常压缩率在 50% 左右
▍统一性
为了提升接入效率,提供更加高效的接入方案,针对云、端、边等多种场景,IFX 可以提供统一的接入方案,同一个算法模型,支持部署到多种不同硬件设备。

▍多框架
业务方选用的算法框架相对比较自由,为让体验和接入流程一致,IFX 支持将 TensorFlow,PyTorch,Caffe,Darknet 等不同的深度学习训练得到的算法模型,转换成 IFX 支持的模型,并提供兼容性设计,满足业务迭代以及算法升级的需求。
▍自动化
AI 模型落地的过程中,存在较大的人工操作,为了降低每一个环节人工干预的程度,我们梳理了一些值得自动化实施的环节,帮助业务更快进行开发。
SDK 自动化生成
服务自动化压测
模型正确性评测
功耗、CPU Loading 等自动化测试
▍安全性
滴滴有大量的算法部署在端侧,目前我们发现软件系统会受到一些外部的攻击,为了更好的提升 AI 软件的运行安全性,保障滴滴业务的同时,更好的对外输出,我们进行了一次架构安全升级。
-
接入层:离线、在线授权方案,严控接入设备 -
SDK层:IOS,Android,Linux 代码混淆,保护业务逻辑 -
引擎层:函数级别加密和混淆,杜绝反调试,反编译 -
模型层:模型文件加密,保护算法结构
当前,IFX 已经服务了内部不少的业务,但是在 AI 部署的过程中,依然存在很多低效的环节需要迭代和优化。IFX 团队也将继续在这个过程中进行能力建设,后续我们计划将整个开发和生产流程线上化,采用统一的开发环境,整合开发、测试、验证、分析、上线流程,需要做的工作还很多,但未来可期。
今天的分享就到这里,谢谢大家。

团队介绍
▬ 滴滴云平台事业群滴滴机器学习平台团队是一个由技术和梦想驱动的团队。在高性能计算,异构计算领域有独到的技术优势,团队主要成员曾推出了国内最早的云上 GPU,HPC 产品。在滴滴,机器学习平台团队致力于构建稳定、安全、高效、高性能、易用性强的 AI 一站式开发和部署平台,包括高效的滴滴机器学习平台建设、业务价值创造和落地的滴滴云平台建设、追求极致高性能的推理引擎建设。
作者简介
▬ ![]()
机器学习平台框架组负责人,现负责异构计算、AI系统 优化等工作,为公司提供端/云AI优化和部署方案。曾就职于阿里,参与异构计算集群、阿里云 HPC 产品等研发工作。
![]()
社群推荐: 欢迎加入 DataFunTalk 算法交流群,跟同行零距离交流。如想进群,请识别下面的二维码,根据提示自主入群。
文章推荐:
关于我们:
DataFunTalk 专注于大数据、人工智能技术应用的分享与交流。发起于2017年,在北京、上海、深圳、杭州等城市举办超过100场线下沙龙、论坛及峰会,已邀请近500位专家和学者参与分享。其公众号 DataFunTalk 累计生产原创文章300+,百万+阅读,7万+精准粉丝。
🧐分享、点赞、在看,给个三连击呗!👇






