一个App卖了4亿美元,这家听声识曲公司为何得到Apple的青睐?

作者 | 琥珀
出品 | AI科技大本营(ID:rgznai100)
是否可以将 Shazam 称为有听歌识曲功能应用的鼻祖?
2018 年 9 月,苹果最终以 4 亿美金完成对 Shazam 公司的收购,让不少人为之振奋,在当时对外公布的一份声明中可以看到,自Shazam应用登陆App Store以来,是其最受欢迎的iOS应用之一。
其实早在苹果 iPhone “出道”之前,Shazam 提供的音乐识别服务和技术就已戳中了不少用户的痛点。例如,当外界播放一首你喜爱的歌曲时,手机应用能识别出该歌曲并调出手机内同样的歌曲/原唱,完成后在手机上播放出来。
像最早流行的 Gracenote、SoundHound、Track ID、Tunatic,以及如今的第三方音乐 App 如 QQ音乐、网易云音乐,甚至微信“摇一摇”等也都具备音乐识别的功能。
只不过,据资料显示,在Shazam 公司 1999 年成立之初,以非常“原始”的方式提供服务的:“用户听到歌曲,打一个服务短号码,让电话那头听到,然后自动挂断,歌曲信息以短信的形式发到用户手机上。”
如今,无论被收购之后的 Shazam 是因何种战略地位为苹果生态提供服务,与其他类似的音乐识别软件在操作界面、细节功能有哪些不同,Shazam 仍受到大众的认可。抛开此前与苹果的关系、服务能力不提,Shazam 在音频识别上的技术能力得到公认的。
实际上,早在 2003 年 Shazam 联合创始人之一的 Avery Li-Chun Wang 就发表了一篇论文“An Industrial-Strength Audio Search Algorithm”(《一种工业级音频搜索算法》),提出了基于指纹(fringerprint)的音乐搜索算法,因其检索准确率较高,得到了不少算法工程师的关注。
编者注:来自维基百科:声学指纹(Acoustic fingerprint)是通过特定算法从音频信号中提取的一段数字摘要,用于识别声音样本或者快速定位音频数据库中的相似音频。

根据论文资料,Shazam 设计了一套非常灵活的音频搜索引擎。其算法抗噪声和扰动能力强,计算复杂度低,同时具有很高的可扩展性。即使外界噪音很强,它也可以迅速通过手机录制的一小段压缩音频从百万级的曲库中辨识出正确的歌曲。该算法运用分析音频频谱上的星状图来组合时间-频率信息构造哈希,从而可以将混合在一起的几首歌都辨识出来。此外,针对不同的应用,即使曲库非常大,检索速度也能达到毫秒级。
其核心简言之是,用户将某段音频中的一个片段上传至 Shazam,Shazam 会首先提取指纹,然后查询数据库,最后利用其精准的识别算法返回歌名。指纹可以看做该音频的哈希值(Hash),一个带有时间属性的数字集合。
2015 年,一位名叫 Christophe 的工程师写了篇万字长文,完整分析了Shazam的原理是什么,并表示,在过去的三年时间里,他用了大概 200 个小时来理解信号处理的概念,其背后的数学原理,并制作了自己的Shazam原型。他甚至直言:“写这篇文章是因为此前从没有找到一篇真正理解 Shazam 的文章”。
那么,如何更快更好理解 Shazam 背后的算法奥秘呢?前不久,YouTube上一个专门普及工程知识的频道 Real Engineering 上传了一段 10 分钟视频,可帮助人们快速 Get 到相关知识点。
传送门:https://www.youtube.com/watch?v=kMNSAhsyiDg
相比起人类,计算机对音乐没有直观的理解,它只能将歌曲与其数据库中的其他歌曲进行对比匹配。为此,视频中 Real Engineering 重点提及了两个概念:“星状图”和“哈希函数”,并对基于“指纹”的搜索算法进行了通俗化解释。
例如,人类大脑可很容易区分钢琴和吉他的音色,但对计算机来讲,就需要一种能够量化这些特征以便进行识别的方法,即频谱图,一种声音的视觉显示。
在视频中,研究者尝试用一张三维图来表示:x 轴代表时间,y 轴代表频率,z 轴代表振幅/响度(通常用某种颜色表示)。
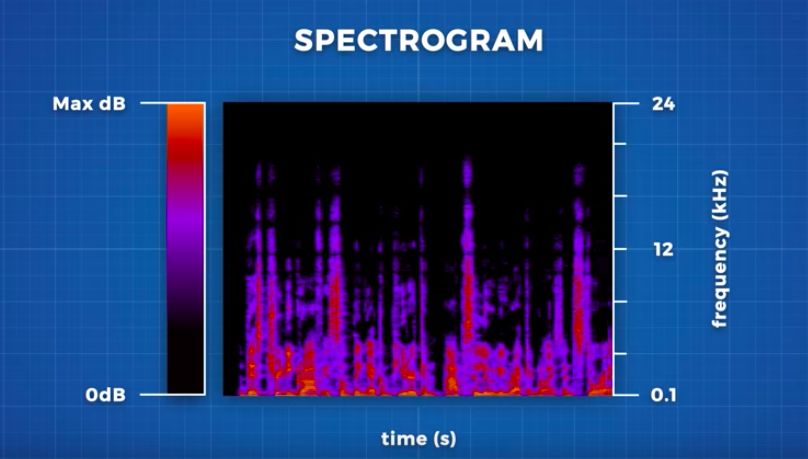
如此,计算机就可以通过这个三维图来识别声音并存储数据。不过,会有个问题:频谱图中有大量这样的数据,而且数据越多,需要通过计算匹配的时间就越长。
所以,减少计算时间的第一步就是减少分类歌曲的数据。
Shazam 采用的称之为“指纹”的技术,可将这些频谱图转换成看起来像的“星状图”。
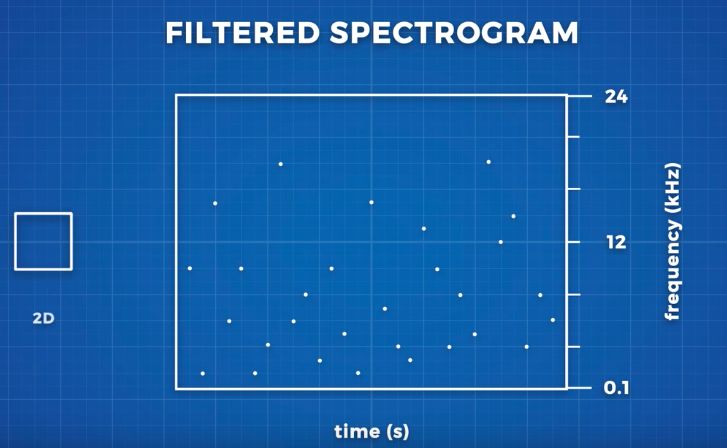
每颗星星代表特定时间最强的频率。如此,不仅降低了频谱图的维度,还减少了图表上数据点的数量。
然后,Shazam 数据库中的每首单曲都以“指纹”的形式存储起来。
当用户打开 Shazam 应用时,后台将访问手机的麦克风,并创建一组接收到的声波“指纹”。不过,这种方式也有助于应用过滤噪声,因为它只会创建突出频率的数据点。
音频创建完成,并将其发送到服务器。此时,Shazam的识别过程正式开始,即“快速组合哈希”(Fast Combinatorial Hashing)。
论文链接:https://www.ee.columbia.edu/~dpwe/papers/Wang03-shazam.pdf
Shazam 会将“指纹”进行分类,并搜索在该音频中的某个特定时间点里分别存在哪几个音符,这也是哈希表的可搜索地址。
注:在计算机领域,哈希和哈希函数应用十分广泛。例如,在谷歌的搜索引擎算法中就应用了哈希函数,以确保文件可被下载。一句话解释就是,任意长度的输入通过哈希函数变换成固定长度的输出,该输出就是哈希值。
实践中,输入可以是一小段文字如密码,也可以是像整部电影一样的长数据流。
为免枯燥乏味,视频里还举了个生动的例子:在图书馆如何通过搜索书的标题确定书的位置?
可以通过哈希函数来决定,书的标题为输入,书架的位置为输出。在这个过程中,我们会遇到书籍不均匀分布、书目冲撞、以及如何快速找到所需书目的问题。

例如,如果图书馆只有两个架子,那么书目冲撞(一个书架上有相同标题的书)的问题将十分突出;但如果图书馆有十亿书架,那哈希函数得出的书目冲撞结果应该会很小。
回到以上提到的案例,如果通过哈希函数,选择两组频率数据,分别除以时间并作为输入,输出的数字介于 1 至 10 亿之间。

首先,计算机将浏览歌曲数据库并计算每个锚点(anchor point)的哈希;一首歌曲将包含多个锚点,将有助于计算机对音频片段按锚点、后面的以及之间的频率进行分类。
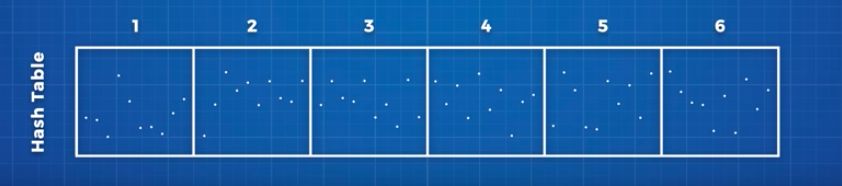
然后,对每个锚点按哈希进行排列。
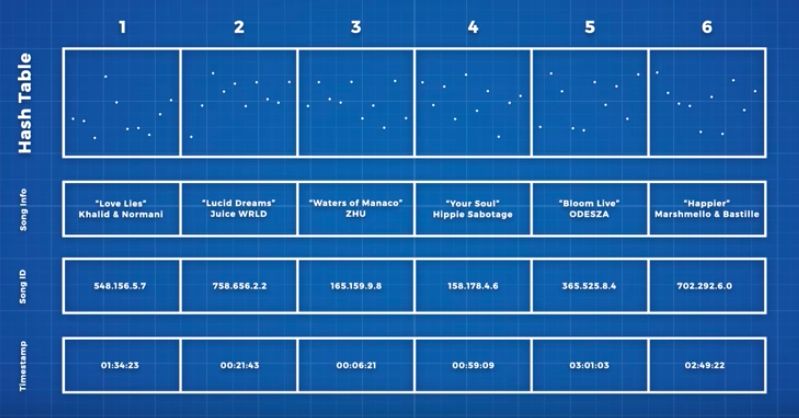
这些地址同样以歌曲 ID 和时间戳进行分类。
如此,便可以更快定位,并找到本来需要多个锚点才能找到的音乐。
以上只是大致介绍,想要了解 Shazam 听歌识曲背后的详细原理,可以查看Christophe 写的万字长文。
传送门:http://coding-geek.com/how-shazam-works/
(本文为AI科技大本营原创文章,转载请微信联系 1092722531)

推荐阅读:

点击“阅读原文”,打开CSDN APP 阅读更贴心。





