2020 年 2 月 7 日-2 月 12 日,AAAI 2020 将于美国纽约举办。不久之前,大会官方公布了今年的论文收录信息:收到 8800 篇提交论文,评审了 7737 篇,接收 1591 篇,接收率 20.6%。本文介绍了滴滴 AI Labs 与美国东北大学合作的一篇论文《AutoCompress: An Automatic DNN Structured Pruning Framework for Ultra-High Compression Rates》
近年来,随着深度神经网络模型性能不断刷新,模型的骨干网络参数量愈发庞大,存储和计算代价不断提高,从而导致难以部署在资源受限的嵌入式平台上。滴滴 AI Labs 与美国东北大学王言治教授研究组合作,联合提出了一种基于 AutoML 思想的自动结构化剪枝的算法框架 AutoCompress,能自动化的去寻找深度模型剪枝中的超参数,去除模型中不同层的参数冗余,替代人工设计的过程并实现了超高的压缩倍率。从而满足嵌入式端上运行深度模型的实时性能需求。
相较之前方法的局限性,该方法提出三点创新性设计:
(2)采用高效强大的神经网络剪枝算法 ADMM(交替乘子优化算法)对训练过程中的正则项进行动态更新;
(3)利用了增强型引导启发式搜索的方式进行行为抽样。在 CIFAR 和 ImageNet 数据集的大量测试表明 AutoCompress 的效果显著超过各种神经网络压缩方法与框架。在相同准确率下,实际参数量的压缩相对之前方法最大可以提高超 120 倍。
![]()
论文全文:https://arxiv.org/abs/1907.03141
深度神经网络模型压缩技术成为解决上述问题不可或缺的关键。其中具有代表性的方法 -- 模型权重剪枝(weight pruning)技术可以有效地将大模型压缩,进而高效地进行推理加速。
这其中,结构化剪枝(structured pruning)作为能够真正在平台层面解决硬件执行效率低,内存访问效率差,计算平行度不高问题的合理有效的剪枝维度,受到了学术界与工业界的重视。然而权重剪枝在算法实现过程中涉及到到大量的超参数设置 -- 例如如何确定模型的压缩维度,或者如何确定模型中每层的压缩比例等等。由于设计空间巨大且需要专业知识指导,人工设计这些超参数的过程冗长且复杂,并且在很大程度上依靠相关人员的参数调节经验。因此,作为一种更加激进的剪枝模式,结构化剪枝技术在算法实现层面面临着更大的挑战。
为解决结构化剪枝中超参数的决策问题,将超参数的设置转变为一种自动化过程将大大提高模型权重剪枝的算法实现效率。在近期的研究中,比如 AMC 等利用了深度增强学习(Deep Reinforcement Learning(DRL))的方法去决策每层的剪枝比例,然而,这种自动化的剪枝方法存在三方面的局限性:
(1)只采用了单一的输出通道(filter)剪枝维度;
(2)为了得到稀疏化模型,其所采用的剪枝方法仅仅是在模型训练过程中引入一个静态的正则项;
(3)更深层次的局限性在于其所采用的基于 DRL 框架的剪枝方法本质上与剪枝问题难以兼容。但由于 DRL 框架并不适合解决模型权重剪枝的超参数设置问题,AMC 研究的结果也佐证了这一观点,其结果中最高压缩率只有非结构化(non-structured)的 5 倍压缩倍率。
![]()
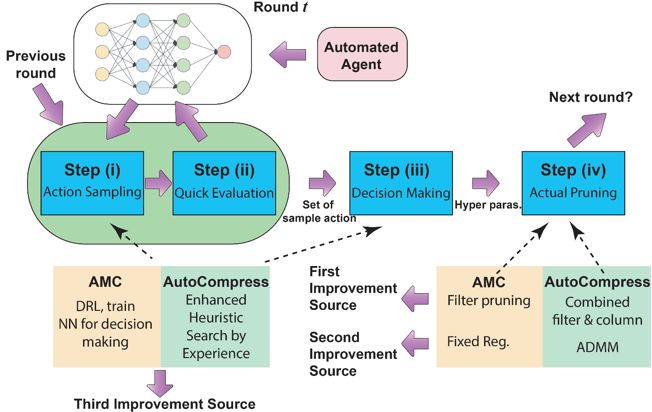
图 1. 自动化超参数决策框架的通用流程,以及性能提升来源
为了改进以上的不足,我们提出了神经网络权重剪枝问题超参数设置自动化过程的通用流程(generic flow),如图 1 所示。整个自动化通用流程主要可以分为 4 步。步骤 1 为行为抽样,步骤 2 为快速评估,步骤 3 为确定决策,步骤 4 为剪枝操作。
由于超参数的巨大搜索空间,步骤 1 和步骤 2 应该快速进行,因此无法进行再训练(re-training)后去评估其效果。因此根据量级最小的一部分权重直接进行剪枝评估。步骤 3 根据工作抽样和评估的集合对超参数进行决策。步骤 4 利用剪枝核心算法对模型进行结构化剪枝并生成结果。
基于上述通用流程,并针对之前方法的局限性,进一步提出如下三点创新性设计,通过综合现有的深度神经网络与机器学习框架首次实现了目前最高效的深度神经网络自动化结构化剪枝的通用框架 AutoCompress。该框架在滴滴已经得到了实际有效应用。
三点创新性设计为:(1)提出混合型的结构化剪枝维度;(2)采用高效强大的神经网络剪枝算法 ADMM(交替乘子优化算法)对训练过程中的正则项进行动态更新;(3)利用了增强型引导启发式搜索的方式进行行为抽样。
![]()
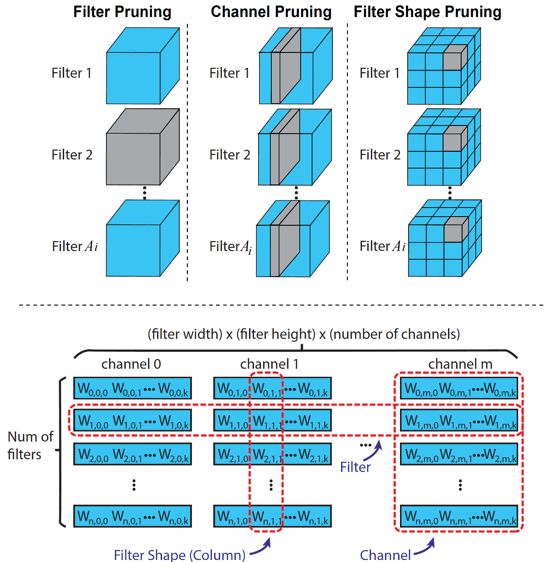
图 2. 不同的结构化剪枝策略: 基于卷积核的角度和通用矩阵乘算法(GEMM)的角度
首先,结构化剪枝包含三种剪枝维度,输出通道剪枝(filter pruning),输入通道剪枝(channel pruning)和输出通道形状剪枝(filter shape/column pruning),如图 2 上所示。输出通道剪枝即直接删除一个卷积核。输入通道剪枝为删除每个卷积核对应的输入通道。输出通道形状剪枝为删除每个卷积核上相同位置的权重。下半部分展示了推理过程中卷积层展开的通用矩阵乘法(GEMM)矩阵。其中每行代表一个卷积核(对应 filter pruning),每列对应的是每个卷积核上相同位置的权重(对应 filter shape pruning)。一段连续列则代表一个输入通道(对应 channel pruning)。通过结合了输出通道形状剪枝(filter shape/column pruning)和 输入通道剪枝(filter pruning)两种结构化剪枝维度,剪枝后的模型仍然可以维持一个完整的矩阵,从而可以最大限度地利用硬件结构实现加速。
其次,采用 ADMM 算法,将剪枝问题转化为数学优化问题,在剪枝的同时训练剩余权重。ADMM 可以将原始剪枝问题分解为两个子问题,用传统梯度下降法求解子问题一,并引入一个二次项迭代求解子问题二。在不同量级的神经网络下,ADMM 均取得非常好的训练效果(高精度),同时保持了较高的训练效率(快速收敛)。最后,采用有效的启发式搜索的方式解决 DRL 框架的局限性。考虑到基于人类经验的启发式搜索可以执行导向搜索(guided search),这是采用启发式搜索的另一个优势。
![]()
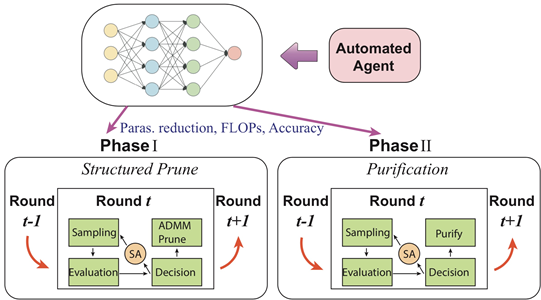
基于上述三点创新性设计,我们搭建了 AutoCompress 框架,如图 3 所示。通过基于启发式搜索算法的自动化代理模块的指导,AutoCompress 框架进行模型自动化剪枝主要分为两个步骤,步骤 1:通过基于 ADMM 算法的结构化剪枝,得到权重分布结构性稀疏化的模型;步骤 2:通过网络结构净化(Purification)操作,将 ADMM 过程中无法完全删除的一小部分冗余权重找到并删除。值得注意的是,这两个步骤都是基于相同的启发式搜索机制。
针对 AutoCompress 中最核心的搜索算法设计,我们利用了搜索算法中的模拟退火算法为搜索算法的核心。举例来讲,给定一个原始模型,我们会设置两种目标函数 -- 根据权重数量设置或根据运算量(FLOPs)设置。搜索过程进行若干轮,比如第一轮目标为压缩两倍权重数量,第二轮为压缩四倍权重数量。在每一轮搜索过程中,首先初始化一个行为(超参数),然后每次对行为进行一个扰动(超参数的小幅变化)生成新的行为,根据模拟退火算法原理,评估两个行为,如果新的行为评估结果优于原结果则接受该行为,如果新的行为评估结果劣于原结果则以一定概率接受该行为。每一轮算法中的温度参数 T 会下降,直到 T 下降到某个阈值后即停止搜索,该结果即为图 1 中的步骤 3 输出。最后,根据搜索得到的超参数,对神经网络进行结构化剪枝操作。
![]()
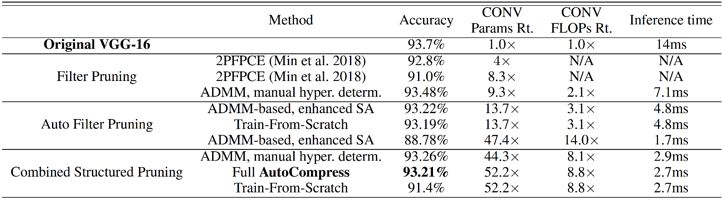
表 1. 在 VGG-16 上基于 CIFAR-10 数据集的权重剪枝对比结果。
![]()
表 2. 在 ResNet-18 (NISP 和 AMC 结果为 ResNet-50) 上基于 CIFAR-10 数据集的权重剪枝对比结果。
![]()
表 3. 在 VGG-16 上基于 ImageNet 数据集的结构化权重剪枝
![]()
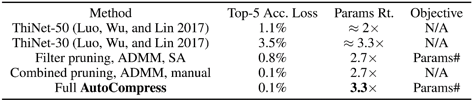
表 4. 在 ResNet-18/50 上基于 ImageNet 数据集的结构化权重剪枝对比结果。
![]()
表 5. 在 ResNet-50 上基于 ImageNet 数据集的非结构化权重剪枝对比结果。
表 1,2,3,4,5 展示了 AutoCompress 框架在代表性的深度神经网络和数据集上的剪枝效果。
可以看到,AutoCompress 框架对深度模型压缩效果极为显著,例如 VGG-16 在 CIFAR-10 数据集上,结构化剪枝压缩率高达 52.2 倍,无精度损失,在 Samsung Galaxy S10 智能手机上测试(使用代码生成优化版编译器),其运行速度为 2.7ms。ResNet-18 在 CIFAR-10 数据集上更是达到了 54.2 倍结构化剪枝压缩率无精度损失。
相比之前的方法,如果考虑到 ResNet-18 与 ResNet-50 本身的大小差距(我们使用更小的 ResNet-18),可以在准确率有所上升的情况下比之前的方法减小 120 倍权重参数。在 ImageNet 数据集上,VGG-16 达到了 6.4 倍结构化压缩率,精度损失仅为 0.6%,ResNet-18 达到了 3.3 倍的结构化压缩率,无精度损失;最后,值得指出的是,AutoCompress 框架也可以应用于非结构化剪枝,其压缩结果使 ResNet-50 在 ImageNet 数据集上可以做到 9.2 倍无精度损失的压缩,更能达到 17.4 倍的压缩率,仅损失 0.7% 的精度。
与其他方法相比,AutoCompress 的效果超过各种神经网络压缩方法与框架。这一研究使得高效率,高精度地获取深度神经网络高压缩率模型成为可能,并且得到的高效神经网络模型可以在嵌入式移动系统中实现实时推理运算。
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
![]()
专知,专业可信的人工智能知识分发,让认知协作更快更好!欢迎注册登录专知www.zhuanzhi.ai,获取5000+AI主题干货知识资料!
欢迎微信扫一扫加入专知人工智能知识星球群,获取最新AI专业干货知识教程资料和与专家交流咨询!
点击“
阅读原文
”,了解使用
专知
,查看获取5000+AI主题知识资源