一连串实用更新:TensorFlow Lite 针对自然语言处理的最新功能

文 / Tian Lin、Yicheng Fan、Jaesung Chung 和 Chen Cen
TensorFlow World 第二日演讲 [第 50 分钟起]
-
新的预训练 NLP 模型 -
创建您自己的 NLP 模型 -
TensorFlow NLP 模型转换为 TensorFlow Lite 更轻松 在移动设备上部署这些模型
使用新的预训练 NLP 模型
参考应用是一组开源移动应用,封装了预训练的机器学习模型、推理代码和可运行的演示。我们提供了一系列与 Android Studio 和 XCode 集成的 NLP 应用,因此开发者只需点击一下就可以将其构建并部署在 Android 或 iOS 手机上。
移动应用
https://tensorflow.google.cn/lite/examples模型
https://tensorflow.google.cn/lite/models
-
文本分类:模型根据给定的文本数据预测标签
https://tensorflow.google.cn/lite/models/text_classification/overview -
问答应用:给定文章和用户问题,模型可以根据文章的内容回答问题
https://tensorflow.google.cn/lite/models/bert_qa/overview 智能回复 (Smart reply):基于给定的上下文,模型可以预测并生成潜在的自动回复
https://tensorflow.google.cn/lite/models/smart_reply/overview
上述参考应用中使用的预训练模型可在 TensorFlow Hub (https://tfhub.dev/s?module-type=text-embedding) 中找到。下表显示了模型之间的延迟、大小和 F1 得分。
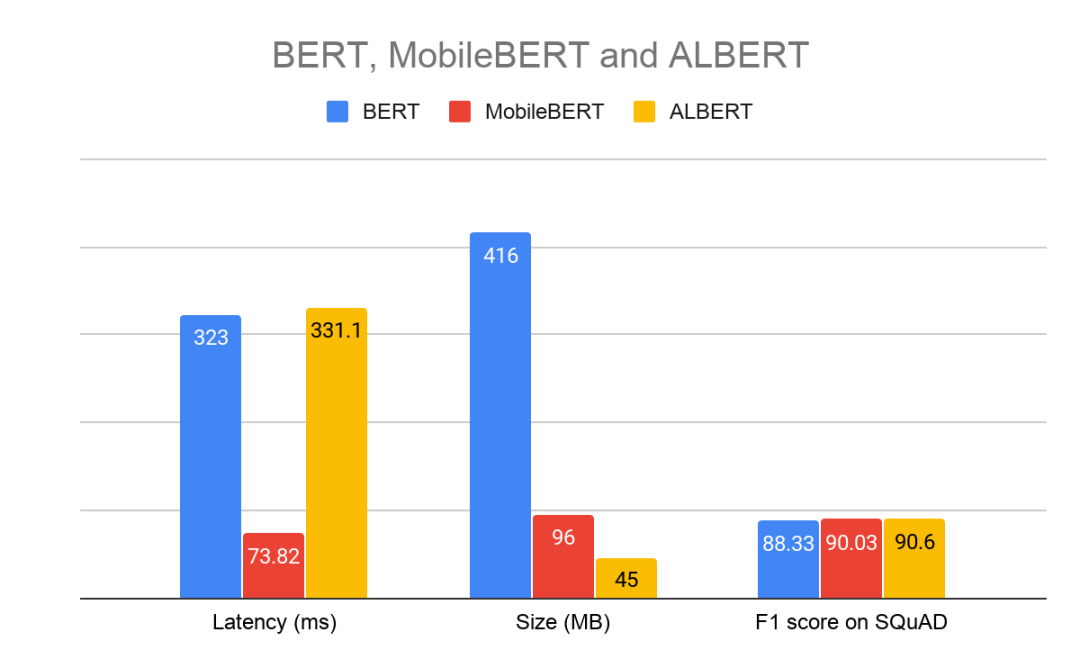
Pixel 4 CPU、4 线程基准测试,2020 年 3 月
模型超参数:序列长度 128,词汇量 30K
与服务器端模型相比,设备端模型有不同的约束。它们运行在内存较低、芯片速度较慢的设备上,因此需要针对模型大小和推理速度进行优化。以下是我们如何针对 NLP 任务优化模型的几个示例。
MobileBERT 是在 GitHub 上开源的紧凑型 BERT 模型。它的大小约为基础版 BERT (float32) 的四分之一,速度也比后者快 5.5 倍,并且能够在 GLUE 和 SQuAD 数据集上实现相当的结果。
GitHub
https://github.com/google-research/google-research/tree/master/mobilebert
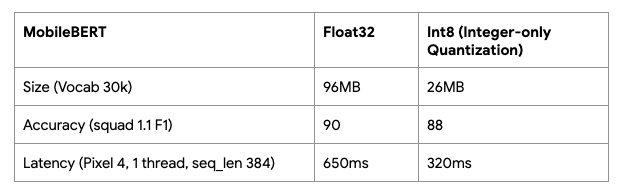
在初始版本后,我们进一步改进了模型 - 使用量化优化模型大小和性能,使其能够利用 GPU/DSP 等加速器(如果有)。量化后的 MobileBERT 的大小为基础 BERT 的十六分之一,速度加快 8 倍,却几乎没有准确率损失。MLPerf for Mobile 社区正在利用量化 MobileBERT 模型进行移动推理基准测试,该模型还可以通过 TensorFlow.js 在 Chrome 中运行。
量化
https://tensorflow.google.cn/lite/performance/model_optimization#quantizationMLPerf for Mobile
https://github.com/mlperf/mobile_appChrome
https://blog.tensorflow.org/2020/03/exploring-helpful-uses-for-bert-in-your-browser-tensorflow-js.html
下表显示了量化后的 MobileBERT 与基础版 BERT 基础模型 (416MB) 在相同设置下的性能比较。
语言识别是对给定文本的语言进行分类的一种问题类型。最近我们开源了两个使用投影方法的模型,即 SGNN 和 PRADO。
开源
https://github.com/tensorflow/models/tree/master/research/sequence_projection
我们使用 SGNN 展示了使用 Tensorflow Lite 处理 NLP 任务的简单和高效。SGNN 将文本投影到固定长度的特征,然后是全连接层。利用注释来告知 TensorFlow Lite 转换器融合 TF.Text API,这样我们可以获得一个更高效的模型在 TensorFlow Lite 上推理。以前,该模型在基准上运行需要 1332.87 μs;而在融合后,在同一台机器运行,需 64.06 μs,带来了 20 倍加速。
SGNN
https://research.google/pubs/pub48711/
我们还演示了名为 PRADO 的模型架构。PRADO 首先从单词分词序列中计算出可训练的投影特征,然后应用卷积和注意力将特征映射到固定长度编码。通过结合投影层、卷积和注意力编码器机制,PRADO 实现了与 LSTM 相似的准确率,但模型大小却是后者的百分之一。
PRADO
https://www.aclweb.org/anthology/D19-1506.pdf
这些模型背后的理念是使用投影来计算文本中的特征,这样模型就不需要维护一个很大的嵌入向量表来将文本特征转换为嵌入向量。通过这种方式,我们证明了该模型将比基于嵌入向量的模型要小得多,但是能够保持相似的性能和推理延迟。
创建您自己的 NLP 模型
除了使用预训练的模型外,TensorFlow Lite 还为您提供了诸如 Model Maker 之类的工具,让您可以根据自己的数据自定义现有模型。
TensorFlow Lite Model Maker 是一款易于使用的迁移学习工具,可根据您的数据集调整最前沿 (SOTA) 的机器学习模型。借助 Model Maker,移动开发者在没有任何机器学习专业知识的情况下也可以创建模型,通过迁移学习减少所需的训练数据并缩短训练时间。
TensorFlow Lite Model Maker
https://tensorflow.google.cn/lite/guide/model_maker
在专注于视觉任务的初始版本之后,我们最近向 Model Maker 添加了两个新的 NLP 任务。您可以按照文本分类和问答的 Colab 和指南进行操作。执行以下操作以安装 Model Maker:
pip install tflite-model-maker
开发者需要编写几行 Python 代码来自定义模型,如下所示:
# Loads Data.
train_data = TextClassifierDataLoader.from_csv(train_csv_file, mode_spec=spec)
test_data = TextClassifierDataLoader.from_csv(test_csv_file, mode_spec=spec)
# Customize the TensorFlow model.
model = text_classifier.create(train_data, model_spec=spec)
# Evaluate the model.
loss, acc = model.evaluate(test_data)
# Export as a TensorFlow Lite model.
model.export(export_dir, quantization_config=config)
文本分类
https://tensorflow.google.cn/lite/tutorials/model_maker_text_classification问答
https://tensorflow.google.cn/lite/tutorials/model_maker_question_answer
转换:NLP 模型转换为 TensorFlow Lite 更轻松
由于 TensorFlow Lite 内置算子库仅支持部分 TensorFlow 算子,因此在将 NLP 模型转换为 TensorFlow Lite 时可能会遇到问题,原因可能是缺少算子或不受支持的数据类型(如 RaggedTensor 支持、哈希表支持和资源文件处理等)。以下是有关在这些情况下如何解决转换问题的一些提示。
部分
https://tensorflow.google.cn/lite/guide/ops_compatibility
我们增强了选择 TensorFlow 算子以支持各种情况。按照“选择 TF 算子”的说明操作,开发者可以在没有内置 TensorFlow Lite 等效算子的情况下利用 TensorFlow 算子在 TensorFlow Lite 上运行模型。例如,在训练 TensorFlow 模型时通常会使用 TF.Text 算子和 RaggedTensor,现在这些模型可以轻松转换为 TensorFlow Lite 并采用必要的算子运行。
选择 TensorFlow 算子
https://tensorflow.google.cn/lite/guide/ops_selectTF.Text
https://tensorflow.google.cn/tutorials/tensorflow_text/intro
此外,我们还提供使用算子选择性构建的解决方案,获得用于移动部署的精简二进制文件。它可以在最终的构建目标中选择一小组使用过的算子,从而缩减部署中的二进制文件大小。
构建
https://tensorflow.google.cn/lite/guide/reduce_binary_size
在 TensorFlow Lite 中,我们为 NLP 提供了一些新的适合移动设备的算子,例如 Ngram、SentencePieceTokenizer、WordPieceTokenizer 和 WhitespaceTokenizer。
适合移动设备的算子
https://github.com/tensorflow/tflite-support/tree/master/tensorflow_lite_support/custom_ops
以前,有一些限制会阻止 SentencePiece 模型转换为 TensorFlow Lite。面向移动设备的新 SentencePieceTokenizer API 解决了这些难题,同时优化了实现,使其运行更快。
SentencePiece
https://github.com/google/sentencepiece
同样,Ngram 和 WhitespaceTokenizer 现在不仅受支持了,而且能够在设备上更高效地执行。
TensorFlow Lite 最近推出了与 MLIR 的算子融合。我们使用相同的机制将 TF.Text API 融合到自定义 TensorFlow Lite 算子中,显著提高了推理效率。例如,WhitespaceTokenizer API 由多个算子组成,在 TensorFlow Lite 的原始计算图中运行需要 0.9 ms。在将这些算子融合成一个单独的算子后,只需 0.04 ms 即可完成计算,速度提高了 23 倍。事实证明,这种方式在上述 SGNN 模型中可以大幅改善推理延迟。
哈希表对于许多 NLP 模型都很重要,因为我们通常需要通过将单词转换为 token ID 来在语言模型中利用数字计算,反之亦然。哈希表将很快在 TensorFlow Lite 中启用。其支持方式是以 TensorFlow Lite 格式原生处理资源文件并将算子内核作为 TensorFlow Lite 内置算子。
部署:如何在设备端运行 NLP 模型
现在,使用 TensorFlow Lite 运行推理比以前要容易得多。仅需 5 行代码您便可以使用预构建的推理 API 集成模型,或者使用实用工具构建自己的 Android/iOS 推理 API。
-
NLClassifier:将输入文本分类为一组已知类别。
https://tensorflow.google.cn/lite/inference_with_metadata/task_library/nl_classifier
-
BertNLClassifier:为 BERT 系列模型而优化的文本分类。
https://tensorflow.google.cn/lite/inference_with_metadata/task_library/bert_nl_classifier
BertQuestionAnswerer:根据给定段落的内容,使用 BERT 系列模型回答问题。
https://tensorflow.google.cn/lite/inference_with_metadata/task_library/bert_question_answerer
Task Library 可在 Android 和 iOS 上跨平台运行。以下示例显示了使用 Java/Swift 代码的 BertQA 模型推理:
// Initialization
BertQuestionAnswerer answerer = BertQuestionAnswerer.createFromFile(androidContext, modelFile);
// Answer a question
List answers = answerer.answer(context, question);
用于 Android 的 Java 代码
// Initialization
let mobileBertAnswerer = TFLBertQuestionAnswerer.mobilebertQuestionAnswerer(modelPath: modelPath)
// Answer a question
let answers = mobileBertAnswerer.answer(context: context, question: question)
用于 iOS 的 Swift 代码
自定义推理 API
如果现有任务库不支持您的用例,您还可以利用 Task API Infrastructure,使用同一仓库中的通用 NLP 实用工具(如 Wordpiece 和 Sentencepiece 分词器)构建自己的 C++/Android/iOS 推理 API。
Task API Infrastructure
https://tensorflow.google.cn/lite/inference_with_metadata/task_library/customized_task_api仓库
https://github.com/tensorflow/tflite-support
结论
在本文中,我们介绍了 TensorFlow Lite 中对 NLP 任务的新支持。利用 TensorFlow Lite 的最新更新,开发者可以轻松地在设备端创建、转换和部署 NLP 模型。我们将继续提供更多实用的工具,并加快从研究到生产的设备端 NLP 模型的开发流程。我们希望听到您对新的 NLP 工具与实用工具的反馈和建议。请向 tflite@tensorflow.org 发送电子邮件或在 GitHub 为 TensorFlow Lite 提 issue。
GitHub
https://github.com/tensorflow/tflite-support/issues/new
致谢
感谢 Khanh LeViet、Arun Venkatesan、Max Gubin、Robby Neale、Terry Huang、Peter Young、Gaurav Nemade、Prabhu Kaliamoorthi、Ping Yu、Renjie Liu、Lu Wang、Xunkai Zhang、Yuqi Li、Sijia Ma、Thai Nguyen、Xingying Song、Chung-Ching Chang、Shuangfeng Li 对本文的贡献。


了解更多请点击 “阅读原文” 访问官网。





