加入极市专业CV交流群,与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度 等名校名企视觉开发者互动交流!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。关注 极市平台 公众号 ,回复 加群,立刻申请入群~
以机器自动设计网络结构为目标的神经网络搜索(NAS,Neural Architecture Search)有望为机器学习带来一场新的革命。
但是,现有的 NAS 解决方案的有效性和效率还不明确,最近的一些工作表明,许多现有的 NAS 解决方案甚至不优于随机网络搜索。
NAS 方法的无效性可能归因于不准确的网络结构评估。
具体来说,为了加快 NAS 的速度,最近的工作提出了利用共享网络参数在一个大的搜索空间中同时对不同的候选网络结构进行不充分训练,但这导致了不正确的网络结构评级,进一步加剧了 NAS 方法的无效性。
来自暗物智能研究院和蒙纳士大学、中山大学的研究者们联合提出了一种新的神经网络搜索方法,解决了上文提到的目前 NAS 方法面临的两个最大问题:效率和有效性问题。区别于现有(RL,Darts,One-shot)的神经网络搜索算法,作者基于知识蒸馏的思想,引入教师模型来引导网络结构搜索的方向。利用来自教师模型不同深度的监督信息,将原本端到端的网络搜索空间在深度上分块,实现对网络搜索空间独立分块的权重共享训练,大大降低了权重共享带来的干扰。在不牺牲权重共享的高效率的同时,也保证了对候选子模型的评估准确性,同时通过算法实现对搜索空间中所有候选结构的遍历。相关研究以「Blockwisely Supervised Neural Architecture Search with Knowledge Distillation」为题被计算机视觉顶会 CVPR 2020 接收。
背景
解决神经网络搜索问题通常包括两个迭代步骤,即搜索和评估。搜索步骤是选择值得评估的适当网络结构,而评估步骤是对搜索步骤选择的网络结构的最终性能进行估计和评级。评估步骤在神经网络搜索解决方案中最为重要,因为缓慢的评估会导致神经网络搜索的计算成本过高,搜索效率低下,而不准确的评估会导致神经网络搜索的无效性。
对候选网络结构最精确的数学评估是从无到有地训练它到收敛并测试它的性能,然而,由于巨大的成本,这是不切实际的。例如,在 ImageNet 上训练单个 ResNet50 大小的网络可能需要超过 10 GPU 天。为了加快评估速度,最近的工作(DARTS,ProxylessNAS,One-shot,SinglePO,FBNet)提出不要将每个候选网络从零开始全面训练到收敛,而是使用权重共享的方式来同时训练不同的候选网络的网络参数。
然而,共享的最优网络参数不一定表示子网(即候选结构)的最优网络参数,甚至相关性很低,因为子网没有得到公平和充分的训练,且共享同一网络参数的子网太多,导致子网无法完全训练收敛。这样的训练导致无法准确评估候选模型,不准确的评估导致了现有 NAS 的无效性。
方法
FairNAS 和 PC-NAS 提出,当搜索空间很小,并且所有候选模型都经过充分和公平的训练时,评估可能是准确的。为了提高评价的准确性,作者在深度上将超网划分为更小的子空间块,并使其相互独立的训练,以此来缩小每个块的搜索空间,减少共享权重的子网数量。
为使分块搜索空间能独立的进行训练,作者引入现有训练完成的模型的中间层特征图来监督网络结构搜索搜索。设 Y_i 为监督模型(即教师模型)的第 i 个块的输出特性图,
![]() 为超网的第 i 个块的输出特性图。采用 L2 范数作为损失函数,以 K 表示 Y 中神经元的数目,方程中的损失函数可以写为
为超网的第 i 个块的输出特性图。采用 L2 范数作为损失函数,以 K 表示 Y 中神经元的数目,方程中的损失函数可以写为
![]() , 值得注意的是,对于每个块,作者使用教师模型的第(i-1)个块的输出 Y_(i-1) 作为超网的第 i 个块的输入。如此可以有效的将超网的各模块独立开,且能以并行的方式加快超网训练速度。
搜索空间虽独立切分进行训练,但不同分块之间在搜索阶段仍可以随意组合,这样就可以保证搜索空间大小总体不变,而训练时的子模型空间大大减小。在特定的约束条件下(计算量或参数量),为了更好地模仿教师,需要根据相应教师模块的学习难度自适应地分配每个模块的模型复杂度。这使得超网在深度和宽度(层数和通道数)上的可变性尤为重要。先前工作采用的方法,例如引入不必要的 Identity 操作,分步进行宽度和操作的搜索等,有诸多问题。
得益于独立分块的搜索空间,本文作者提出在每个阶段独立地训练具有不同通道数或层数的多个小块,以确保通道数和层数的可变性。
典型的 NAS 搜索空间包含大约10^17 个子模型,这使得在训练完成后很难对所有子模型进行验证(evaluation)。在以往的 NAS 方法中,随机抽样、进化算法、强化学习、贪心算法等方法被用来从训练的超网中抽取部分子模型进行验证。考虑到的分块蒸馏,作者提出了一种新的方法来根据所有子模型的分块性能来估计它们的总体性能,并使用搜索算法巧妙地遍历所有子模型来选择满足约束条件(计算量或参数量)的性能最好的子模型。作者使用分块蒸馏任务的验证损失来衡量子模型的分块性能,并将各分块的子模型按性能排序。之后,采用优化的深度优先遍历,搜索出符合约束的最佳模型。主要算法流程如图 1 所示,详细算法请参见论文。
, 值得注意的是,对于每个块,作者使用教师模型的第(i-1)个块的输出 Y_(i-1) 作为超网的第 i 个块的输入。如此可以有效的将超网的各模块独立开,且能以并行的方式加快超网训练速度。
搜索空间虽独立切分进行训练,但不同分块之间在搜索阶段仍可以随意组合,这样就可以保证搜索空间大小总体不变,而训练时的子模型空间大大减小。在特定的约束条件下(计算量或参数量),为了更好地模仿教师,需要根据相应教师模块的学习难度自适应地分配每个模块的模型复杂度。这使得超网在深度和宽度(层数和通道数)上的可变性尤为重要。先前工作采用的方法,例如引入不必要的 Identity 操作,分步进行宽度和操作的搜索等,有诸多问题。
得益于独立分块的搜索空间,本文作者提出在每个阶段独立地训练具有不同通道数或层数的多个小块,以确保通道数和层数的可变性。
典型的 NAS 搜索空间包含大约10^17 个子模型,这使得在训练完成后很难对所有子模型进行验证(evaluation)。在以往的 NAS 方法中,随机抽样、进化算法、强化学习、贪心算法等方法被用来从训练的超网中抽取部分子模型进行验证。考虑到的分块蒸馏,作者提出了一种新的方法来根据所有子模型的分块性能来估计它们的总体性能,并使用搜索算法巧妙地遍历所有子模型来选择满足约束条件(计算量或参数量)的性能最好的子模型。作者使用分块蒸馏任务的验证损失来衡量子模型的分块性能,并将各分块的子模型按性能排序。之后,采用优化的深度优先遍历,搜索出符合约束的最佳模型。主要算法流程如图 1 所示,详细算法请参见论文。
实验
作者使用 EfficientNet-B7 作为教师模型,在 224×224 输入尺寸下,在 ImageNet 数据集上做超网训练和结构搜索。8 GPU 条件下,在庞大的 ImageNet 数据集上训练超网仅需 1 天,每个模块都增加为三种可选深度或宽度时,训练过程变为 3 天。验证和搜索过程共需 3 至 4 小时。
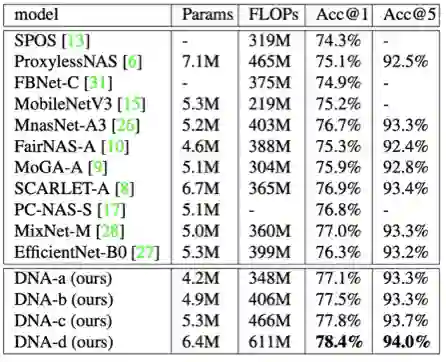
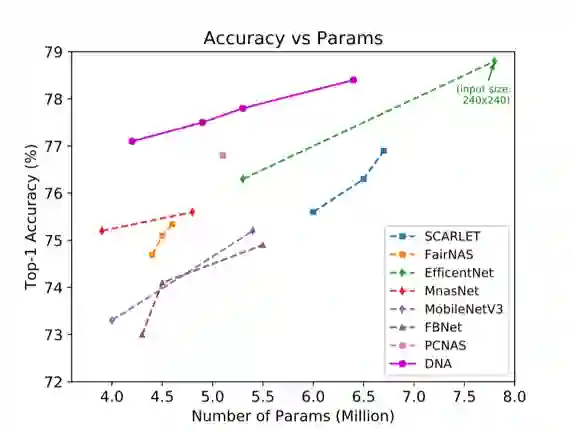
对于搜索出的结构,作者将其进行权重初始化,并在没有教师模型监督的情况下,在 ImageNet 数据集进行重新训练。结果见表 1 与图 2。
本文的 DNA 模型明显的超过了其他最新的 NAS 模型的表现。在 350M 的 FLOPs 限制条件下搜索,本文的 DNA-a 达到了 77.1% 的 Top-1 精度,精度稍低的 SCARLET-a 的参数量超出了其 2.5M(60%)。为了与 EfficientNet-B0 进行公平的比较,作者分别以 399M 计算量和 5.3M 参数量搜索得到了 DNA-b 和 DNA-c,两者的表现都远远超过 B0(1.1% 和 1.5%)。此外,DNA-d 在 6.4M 参数量和 611M 计算量下达到了 78.4% 的 Top-1 精度。当使用与 EfficientNet-B1 相同的输入尺寸(240×240)进行测试时,DNA-d 达到 78.8% 的 Top-1 精度,与 EfficientNet-B1 同样精确,但比 B1 小 1.4M。(模型结构的详细信息,请参见论文附录)
为测试模型的泛化性能,作者在 Cifar-10 和 Cifar-100 数据集上验证了模型迁移学习的能力,同样超出了现有 NAS 模型。结果见表 2。
为了证明分块蒸馏神经网络搜索算法确实提高了模型评估的准确性,作者与 SPOS(Single Path One-shot)搜索方法在模型结构的排序上做了对比。如图 3,结果表明,本文方法(蓝色)在模型排序相关性上远超 SPOS 方法(橙色)。
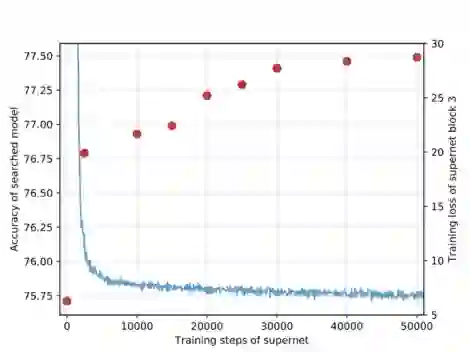
为了证明超网蒸馏训练的有效性和稳定性,作者做了训练过程中损失函数、搜索出的最佳模型性能以及超网与教师网络的特征图对比。如图 4,图 5 所示,最佳模型的性能随训练损失的降低而稳定上升,相似的特征图证明蒸馏训练使超网有效地拟合了教师模型。
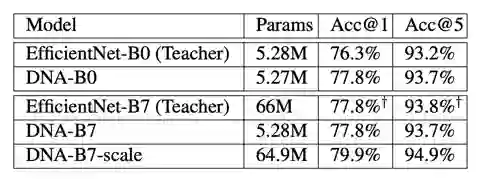
通过对比使用不同教师模型搜索得到的网络结构,作者发现 DNA 方法得到的网络结构精度不受限于教师模型的精度,可以在相同模型大小超过教师模型的精度。如表 3 所示,DNA-B0 精度超过 EfficientNet-B0 1.5%,DNA-B7 经过模型大小的扩展,精度超过 EfficientNet-B7 2.1%(此处 EfficientNet-B7 采用与蒸馏时相同的 224×224 输入尺度)。
在算法落地方面,据了解,本方法已应用于暗物智能科技自研 AutoML 平台,支持在目标任务场景自动构建高精度模型。此外该 AutoML 平台实现了 AI 模型从开发到部署的全自动化流程,配合模型的自动化超参调优,为企业开发、运用 AI 能力全面降低门槛。
极市平台视觉算法季度赛,提供真实应用场景数据和免费算力,特殊时期,一起在家打比赛吧!
![]()
添加极市小助手微信(ID : cv-mart),备注:研究方向-姓名-学校/公司-城市(如:目标检测-小极-北大-深圳),即可申请加入目标检测、目标跟踪、人脸、工业检测、医学影像、三维&SLAM、图像分割等极市技术交流群,更有每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、行业技术交流,一起来让思想之光照的更远吧~
![]()
△长按添加极市小助手
![]()
△长按关注极市平台,获取最新CV干货
觉得有用麻烦给个在看啦~ ![]()

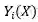 为超网的第 i 个块的输出特性图。采用 L2 范数作为损失函数,以 K 表示 Y 中神经元的数目,方程中的损失函数可以写为
为超网的第 i 个块的输出特性图。采用 L2 范数作为损失函数,以 K 表示 Y 中神经元的数目,方程中的损失函数可以写为
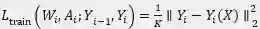 , 值得注意的是,对于每个块,作者使用教师模型的第(i-1)个块的输出 Y_(i-1) 作为超网的第 i 个块的输入。如此可以有效的将超网的各模块独立开,且能以并行的方式加快超网训练速度。
, 值得注意的是,对于每个块,作者使用教师模型的第(i-1)个块的输出 Y_(i-1) 作为超网的第 i 个块的输入。如此可以有效的将超网的各模块独立开,且能以并行的方式加快超网训练速度。