这个CV数据集生成器火了,支持13类复杂CV任务,DeepMind谷歌MIT等打造丨开源
萧箫 发自 凹非寺
量子位 | 公众号 QbitAI
这年头,AI玩家们想找到合适的图像数据集,简直是越来越难了。
不仅数据质量参差不齐,合适的数据类型也难找(如光流图、深度图等)。
为了解决这些问题,来自谷歌、MIT、DeepMind、MILA和剑桥大学等11家机构的34名研究人员,联手打造了一个名叫Kubric的数据集生成器,不仅能自己渲染,而且图像效果也非常真实。
不仅各种图像数据都能做,像语义分割、深度图或光流图这种“特殊数据”都能一键生成:

还能控制渲染的真实度,渲染出的视频可以达到以假乱真的效果:

据作者们表示,目前Kubric支持13类CV任务的数据类型生成,效果也不比用已有数据集训练出来的差。
这样的一个数据集生成器,到底要怎么上手?
可生成13类CV任务所需数据
先来看看这个Kubric数据集生成器究竟是个啥。
简单来说,它有点像是一个专为图像AI打造的“数据车间”,基于跨平台开源物理引擎PyBullet和3D图像渲染软件Blender打造。
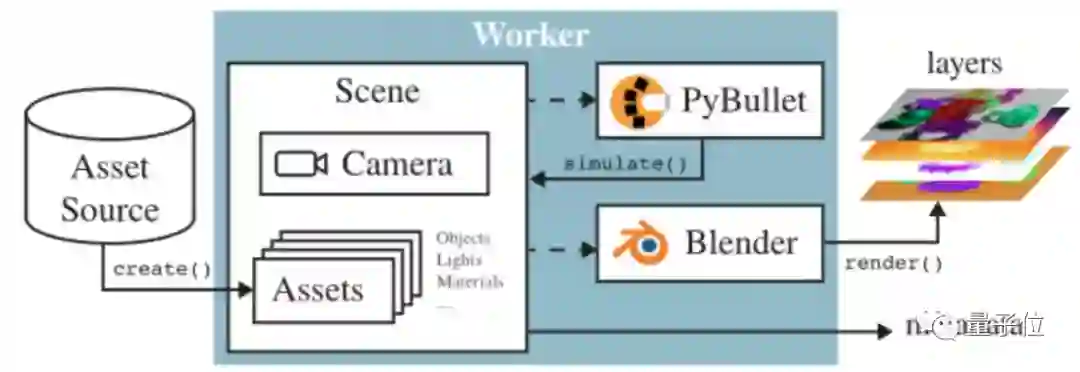
其中,PyBullet给用户提供了一个模拟3D物体运动的平台,例如两个球之间的弹性碰撞参数就可以用它来模拟。(当然,除了PyBullet以外,也可以扩展到其他物理引擎如MuJoCo上)
Blender则是一个渲染3D动画的平台,但它的优势在于操作方便,而且既可以做出照片级逼真的渲染图像,也可以输出3D动画效果。(例如有设计师拿它设计服装纹理)
可能这时候你会问,Kubric相比自己手动渲染视频或图像数据集,方便在哪?
一方面,Kubric自带一系列预处理的基础图像数据库。
除了11个基础3D模型以外:

还内置了Google Scanned Objects(GSO)室内家具物品数据集中的一系列模型,以及包含背景、光照、材料纹理等参数的Polyhaven数据集,还有ShapeNet数据集等(包含55种常见的物品类型及51300个3D模型)。
也就是说,如果你对渲染不太了解,也能利用内置的数据库快速生成想要的图像。
另一方面,Kubric直接提供了从“渲染数据”到输出“AI训练数据”的管道,省去了将渲染图像转成特殊数据(如深度图、光流图)、或是额外收集如视场、相机参数、光照等数据的麻烦。
这也使得Kubric支持生成13类CV任务所需的图像数据,具体包括光流、NeRF、姿态估计、3D重建等。
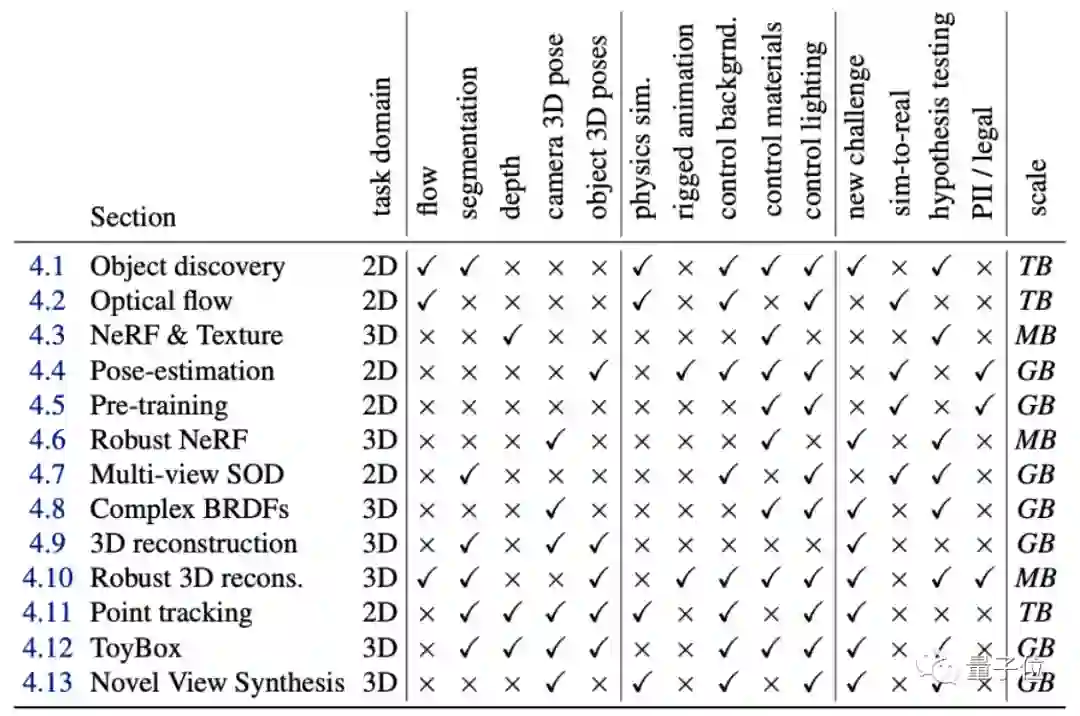
没错,即使这些生成的图像中有2D也有3D类型,需要的数据量也从MB到TB级别不等,但Kubric都能满足。
嗯,作者们还专门针对各种视觉任务,用Kubric生成的数据集一个个试了试,强调“用他们生成的数据集效果更好”。

△Kubric生成的光流图
那么,这样的数据集生成器究竟要怎么用呢?
自带Python接口
作者提供了一些简单的操作流程。
在安装之后,第一步就是创建默认场景:

然后,再通过这两步,分别创建一块地板、和一个球体(也可以换成其他形状):

接下来就是在场景中加一个照明,以及渲染摄像头采集图像:

导出文件后,就能获取一个3D球体的图像了:
△Blender中的效果
如果需要深度图、灰度图等特殊图层的话,也是几行代码就能搞定:

比自己手动导出要更方便一些:

当然,如果还是感觉上手较难,作者也直接提供了示例代码,改改参数就能用:

在原基础上,再加5行代码就能直接运行出动态视频版:

看起来,做完数据集后,即使不懂渲染的也能成为半个行家了(doge)
目前新的一批内置数据集还在施工中,感兴趣的小伙伴可以先上手试玩~
项目地址:
https://github.com/google-research/kubric
论文地址:
https://arxiv.org/abs/2203.03570
参考链接:
https://twitter.com/taiyasaki/status/1501288630697877504
— 完 —
「人工智能」、「智能汽车」微信社群邀你加入!
欢迎关注人工智能、智能汽车的小伙伴们加入我们,与AI从业者交流、切磋,不错过最新行业发展&技术进展。
ps.加好友请务必备注您的姓名-公司-职位哦~

点这里👇关注我,记得标星哦~
一键三连「分享」、「点赞」和「在看」
科技前沿进展日日相见~




