Tumblr扫黄正式开始!AI鉴黄也许是老司机们的头号敌人
机器之心原创
作者:李亚洲、李泽南
大家喜闻乐见的 Tumblr(汤不热)凉了……
12 月初,美国著名图片博客网站 Tumblr 宣布将全面禁止任何成人内容。新规定将于 12 月 17 日正式施行。这一行为看来是主动在和「互联网的 30% 流量」说再见,长久混迹 Tumblr 的老司机们送了一首「凉凉」予它。

自 2007 年上线以来,Tumblr 一直以允许 NSFW 内容而闻名(也可能是臭名昭著),这是公司管理层一时的头脑发热还是想要「改过自新」了?不论 Tumblr 的意图如何,想要为社交网络加入审核机制,过滤色情图片/视频是需要投入技术和人力的。
在 Tumblr 的官方通告中,公司 CEO Jeff D’Onofrio 表示,「……(Tumblr) 将采用产业标准的机器监控、不断加大的人类监控等方式禁止成人内容。」
但是,才「睁开眼睛」的计算机并不那么完美。」Wired 在近日的一篇文章中称。许多 Tumblr 用户在 Twitter 上抱怨其鉴别系统存在许多误判行为。如据 Wired 文章,奥克拉荷马大学法学院教授 Sarah Burstein 只是发布了几张设计专利图,就被标记了。文章表示这不仅效率低下,而且伤害了用户的感情。不少 Tumblr 的用户失望地涌向推特,《纽约时报》称这些用户是「弃船而逃」。
其实在多年前,Tumblr 就面临着准确识别 NSFW 内容的问题。2013 年,Yahoo 11 亿美元收购 Tumblr,4 年后 Verizon 收购雅虎,Tumblr 归于 Verizon 子公司 Oath,并在不久之后推出了「安全模式」,能在搜索结果中自动过滤成人内容。
人工智能虽然可以同时处理大量图片,但毕竟不是人类,难免会出现一些令人哭笑不得的差错。特别像 Tumblr 这样的微博客平台,用户群体复杂,色情与非色情的界限非常难以把握。图普科技产品运营总监姜泽荣表示,「(这样的平台在制定标准时)标准过严可能会把摄影作品、艺术作品之类的内容识别为色情内容,伤害用户体验;标准过低则会让平台上的色情内容继续泛滥。此外平台上的内容类型繁多,包含文字、图片、视频、直播等,各个类型的内容实时性不一,审核标准差异大,这无疑都对开发、运营等团队提出高要求。」
图普科技是国内较早使用深度学习技术提供图像和视频内容审核服务的 AI 创业公司。在平台色情内容审核等问题上,图谱向机器之心解释了一些问题。
图像鉴黄系统流程是什么?
鉴黄系统的工作流程是这样的:首先是要建模,其次是制定色情图片的分类标准,然后收集大量素材,进行分类标注,最后用这些标注好的素材进行训练,让机器去学习各个分类里面的特征,不断调整自己模型的参数并最终得到最佳的识别模型。
而当机器对图像进行识别以后,这些图像数据会转化为数字化的信息,带入到模型里面进行计算, 根据计算值将图片标注为「正常、性感、色情」三个类别。
因为「识别」的不完美性,这样的系统也会有人类的参与。在经过识别之后,系统把判断结果和概率告诉使用方,使用方会再根据结果做对应处理,比如自动删除、或者人工接入复审。如果在人工复核环节发现机器识别有误,则会有针对性地对相同场景的图片进行数据学习, 并调整参数, 直到错误率达到最低值。
AI 鉴黄的技术核心是深度学习理论(Deep Learning)。通俗来讲,可以把深度学习理解为一个空白的大脑,海量数据就是灌输进来的经验。当我们把大量的色情、性感、正常的样本的属性告诉深度学习的引擎,让引擎不断学习,然后把他们做对的进行奖励,做错的就惩罚,当然这些奖励和惩罚都是数学上的,最后空白的脑袋就会学成了一种连接的模型,这种模型就是为了鉴别色情与非色情而生的。
深度学习就是人工神经网络(Artificial Neural Network,以下简称 ANN)。要了解 ANN,让我们先来看看人类的大脑是如何工作的。
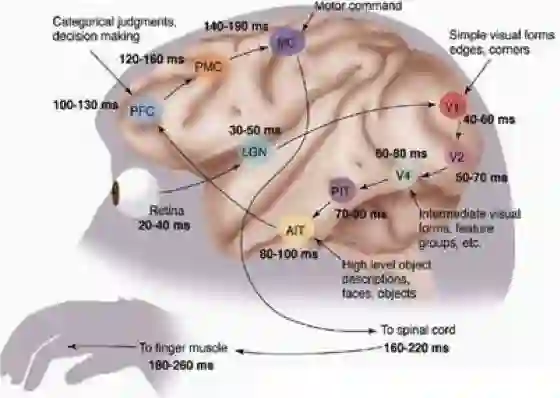
人脑的视觉处理系统(图片来源:Simon Thorpe)
上图表示人理解外界视觉信息的过程。从视网膜(Retina)出发, 经过低级的 V1 区提取边缘特征,到 V2 区的基本形状或目标的局部,再到高层的整个目标(如判定为一张人脸),以及到更高层的 PFC(前额叶皮层)进行分类判断等。也就是说高层的特征是低层特征的组合,从低层到高层的特征表达越来越抽象和概念化,也即越来越能表现语义或者意图。
深度学习恰恰就是通过组合低层特征形成更加抽象的高层特征(或属性类别),然后在这些低层次表达的基础上通过线性或者非线性组合,来获得一个高层次的表达。此外,不仅图像存在这个规律,声音也是类似的。
现在来看深度学习的简易模型。
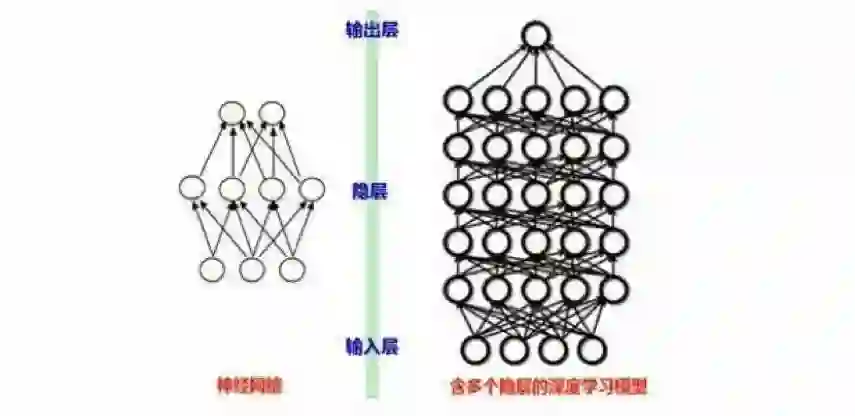
传统的神经网络与深度神经网络(图片来源网络)
深度学习的一个主要优势在于可以利用海量训练数据(即大数据),在学习的过程中不断提高识别精度,但是仍然对计算量有很高的要求。而近年来,得益于计算机速度的提升、大规模集群技术的兴起、GPU 的应用以及众多优化算法的出现,耗时数月的训练过程可缩短为数天甚至数小时,深度学习才逐渐可用于工业化。
对于开发团队来说,做该领域的产品困难在于如何获取大规模已标注数据、集成有 GPU 的计算集群以及针对自己的项目调参数,团队需要不断地输入新数据,持续迭代以提高机器识别准确率。
既有图片又有视频怎么办?
在短视频流行的今天,各家科技公司还要面对海量的视频内容。图片是静态的,视频/直播是动态的,而视频内容的完整审核包括对图片、文字、语音的审核,所以会更加复杂。以对视频图片审核为例,在鉴别视频和直播时,可以先把动态的内容解码成图片帧,这就与静态图片鉴别方法相似了。
直播实时性强,对响应时间要求高,并且里面的场景和人物变化比较大,审核要求比较严格,所以识别难度会相对比较大,需要实时不断对房间进行截帧传输识别,并且结合人工来实现预警处理;视频在画质整体上比图片和直播差,一定程度会影响识别效果,通常是以视频为单位进行等时间间隔截图,以一个视频多张截图的结果来综合判断视频是否色情违规。
如果企业对视频或直播的每一帧图片都进行识别,数据量将变得非常巨大,运营成本会很高。面对这类情况,一般会采用对视频抽帧的方式进行处理。例如,一分钟视频,可以按照时间段来抽取 6-15 帧左右的图片进行识别处理,以此减少计算成本。
审核能否完全依赖机器?
针对人们屡屡吐槽的「误杀」问题,图谱认为在提高 AI 算法准确度的同时目前还需依靠人类做最后的判断。误判分为两大类型:把色情内容误判为正常内容,以及把正常内容误判为色情内容。
1)色情判正常:在光线昏暗场景,或者距离很远时背景干扰比较大的场景下,以及有特效干扰的情况都有可能造成误判;衣着正常但实际上露点、隐晦的动作和姿势等。
2)正常判色情:穿着暴露但实际没露点,物体形似性器官,接近于色情动作但实际不是(譬如手抓棍状物体、手正常放在敏感部位)等。
机器能够帮助企业大幅提升审核效率和准确率。以图普科技的鉴黄系统为例,每天可审核近 10 亿张图片,识别准确率高于 99.5%,可为企业节省 95% 以上的审核人力。但在现阶段甚至很长一段时间内,人工智能鉴黄无法完全代替人工鉴黄。因为机器还很难理解内容背后的深意,也不会在不同文化场景中做自由切换。所以推荐以机器+人工的审核方法。
单纯的算法和模型是可以把机器训练到完全正确地判断情况的,但是在实际应用中,机器没有自主思考和自己的主观意识,仍然需要人工辅助进行确认。例如客户提供的画面过于模糊或者说光线过暗,以及训练数据的不能完全覆盖性等种种客观原因影响下,机器打不出很高的分确认图片,这都需要人工来辅助。
「Tumblr 网友:即使这样我也爱你。」
看来,AI 图像识别系统可以用现有的,「鉴黄师」则非请不可。在宣布禁止成人内容之后,Tumblr 的 app 终于再次出现在苹果应用商店里。这辆车最终会开向何处?让我们拭目以待。

参考链接:https://www.wired.com/story/tumblr-porn-ai-adult-content/






