这三个普通程序员,几个月就成功转型AI,他们的经验是...

本文转载自AI科技大本营(ID:rgznai100),如有侵权烦请联系后台删除。
动辄50万的毕业生年薪,动辄100万起步价的海归AI高级人才,普通员到底应不应该转型AI工程师,普通程序员到底应该如何转型AI工程师?
以下,AI科技大本营精选了三个特别典型的普通程序员成功转型AI的案例,也是知乎上点赞量相当高的案例:
第一案例为普通程序员,经过六个月从接触机器学习到颇有心得的切身体会。
第二个案例为只懂 ACM 竞赛相关算法的普通程序员,误打误撞接触到了数据挖掘,之后开始系统地了解机器学习相关的知识,如今已经基本走上了数据科学家之路的经验分享。
第三个案例为其他行业的普通程序员,具有计算机专业的人所没有的专业知识和行业大数据,他们只是想把深度学习和神经网络当作工具,知道它们能做什么,如何去做。这类程序员经过4个月的转型学习,他们的经验和体会。
你是属于哪类程序员呢?他们的经验你又是否能用上呢?
本文的案例来自知乎,已向相关作者申请转载来源。
案例一
作者 | 子实(某科研院程序员)
本人码农,从六月开始正式接触机器学习(其实五年前的本科毕设就是在生物信息领域应用神经网络的项目,但是非常浅薄),深吸一口气,先要声明“人之患在好为人师”,我用的步骤只是适合我,下面的内容仅供参考。
第一步:复习线性代数。(学渣的线代忘了好多-_-||)
懒得看书就直接用了著名的——麻省理工公开课:线性代数,深入浅出效果拔群,以后会用到的SVD、希尔伯特空间等都有介绍 - http://open.163.com/special/opencourse/daishu.html
广告:边看边总结了一套笔记 GitHub - zlotus/notes-linear-algebra: 线性代数笔记 - https://github.com/zlotus/notes-linear-algebra
第二步:入门机器学习算法。
还是因为比较懒,也就直接用了著名的——斯坦福大学公开课 :机器学习课程(http://open.163.com/special/opencourse/machinelearning.html),吴恩达教授的老版cs229的视频,讲的非常细(算法的目标->数学推演->伪代码)。这套教程唯一的缺点在于没有介绍最近大火的神经网络,但其实这也算是优点,让我明白了算法都有各自的应用领域,并不是所有问题都需要用神经网络来解决。
多说一点,这个课程里详细介绍的内容有:一般线性模型、高斯系列模型、SVM理论及实现、聚类算法以及EM算法的各种相关应用、PCA/ICA、学习理论、马尔可夫系列模型。课堂笔记在:CS 229: Machine Learning (Course handouts) - http://cs229.stanford.edu/syllabus.html,同样非常详细。
广告:边看边总结了一套笔记 GitHub - zlotus/notes-LSJU-machine-learning: 机器学习笔记 - https://github.com/zlotus/notes-LSJU-machine-learning
第三步:尝试用代码实现算法。
依然因为比较懒,继续直接使用了著名的——机器学习 | Coursera(https://www.coursera.org/learn/machine-learning),还是吴恩达教授的课程,只不过这个是极简版的cs229,几乎就是教怎么在matlab里快速实现一个模型(这套教程里有神经网络基本概念及实现)。这套课程的缺点是难度比较低,推导过程非常简略,但是这也是它的优点——让我专注于把理论转化成代码。
广告:作业参考 GitHub - zlotus/Coursera_Machine_Learning_Exercises: Machine Learning by Andrew Ng from Coursera(https://github.com/zlotus/Coursera_Machine_Learning_Exercises)
第四步:自己实现功能完整的模型——进行中。
还是因为比较懒,搜到了cs231n的课程视频 CS231n Winter 2016 - YouTube(https://www.youtube.com/playlist?list=PLkt2uSq6rBVctENoVBg1TpCC7OQi31AlC) ,李飞飞教授的课,主讲还有Andrej Karpathy和Justin Johnson,主要介绍卷积神经网络在图像识别/机器视觉领域的应用(前面神经网络的代码没写够?这门课包你嗨到爆~到处都是从零手写~)。这门课程的作业就更贴心了,直接用Jupyter Notebook布置的,可以本地运行并自己检查错误。主要使用Python以及Python系列的科学计算库(Scipy/Numpy/Matplotlib)。课堂笔记的翻译可以参考 智能单元 - 知乎专栏(https://zhuanlan.zhihu.com/p/22339097),主要由知友杜客翻译,写的非常好~
在多说一点,这门课对程序员来说比较走心,因为这个不像上一步中用matlab实现的作业那样偏向算法和模型,这门课用Python实现的模型同时注重软件工程,包括常见的封装layer的forward/backward、自定义组合layer、如何将layer组成网络、如何在网络中集成batch-normalization及dropout等功能、如何在复杂模型下做梯度检查等等;最后一个作业中还有手动实现RNN及其基友LSTM、编写有助于调试的CNN可视化功能、Google的DeepDream等等。(做完作业基本就可以看懂现在流行的各种图片风格变换程序了,如 cysmith/neural-style-tf - https://github.com/cysmith/neural-style-tf)另外,这门课的作业实现非常推崇computational graph,不知道是不是我的幻觉……要注意的是讲师A.K的语速奇快无比,好在YouTube有自动生成解说词的功能,准确率还不错,可以当字幕看。
广告:作业参考 GitHub - zlotus/cs231n: CS231n Convolutional Neural Networks for Visual Recognition (winter 2016) - https://github.com/zlotus/cs231n,(我的在作业的notebook上加了一些推导演算哦~可以用来参考:D)
因为最近手头有论文要撕,时间比较紧,第四步做完就先告一段落。后面打算做继续业界传奇Geoffrey Hinton教授的Neural Networks for Machine Learning | Coursera(https://www.coursera.org/learn/neural-networks),再看看NLP的课程 Stanford University CS224d: Deep Learning for Natural Language Processing(http://cs224d.stanford.edu),先把基础补完,然后在东瞅瞅西逛逛看看有什么好玩的……
PS:一直没提诸如TensorFlow之类的神器,早就装了一个(可以直接在conda中为Tensorflow新建一个env,然后再装上Jupyter、sklearn等常用的库,把这些在学习和实践ML时所用到的库都放在一个环境下管理,会方便很多),然而一直没时间学习使用,还是打算先忍着把基础部分看完,抖M总是喜欢把最好的留在最后一个人偷偷享受2333333(手动奸笑
PS**2:关于用到的系统性知识,主要有:
线性代数,非常重要,模型计算全靠它~一定要复习扎实,如果平常不用可能忘的比较多;
高数+概率,这俩只要掌握基础就行了,比如积分和求导、各种分布、参数估计等等。(评论中有知友提到概率与数理统计的重要性,我举四肢赞成,因为cs229中几乎所有算法的推演都是从参数估计及其在概率模型中的意义起手的,参数的更新规则具有概率上的可解释性。对于算法的设计和改进工作,概统是核心课程,没有之一。答主这里想要说的是,当拿到现成的算法时,仅需要概率基础知识就能看懂,然后需要比较多的线代知识才能让模型高效的跑起来。比如最近做卷积的作业, 我手写的比作业里给出的带各种trick的fast函数慢几个数量级,作业还安慰我不要在意效率,岂可修!)
需要用到的编程知识也就是Matlab和Numpy了吧,Matlab是可以现学现卖的;至于Python,就看题主想用来做什么了,如果就是用来做机器学习,完全可以一天入门,如果想要做更多好玩的事,一天不行那就两天。(贴一个Python/Numpy的简要教程:Python Numpy Tutorial - http://cs231n.github.io/python-numpy-tutorial/,是cs231n的课堂福利。)
我感觉机器学习的先修就这么点,记得Adobe的冯东大神也说过机器学习简直是21世界的黑科技——因为理论非常简单但是效果惊人的好。
====
既然提到好玩的,墙裂推荐 Kaggle: Your Home for Data Science(https://www.kaggle.com) ,引用维基上的介绍:
Kaggle是一个数据建模和数据分析竞赛平台。企业和研究者可在其上发布数据,统计学者和数据挖掘专家可在其上进行竞赛以产生最好的模型。这一众包模式依赖于这一事实,即有众多策略可以用于解决几乎所有预测建模的问题,而研究者不可能在一开始就了解什么方法对于特定问题是最为有效的。Kaggle的目标则是试图通过众包的形式来解决这一难题,进而使数据科学成为一场运动。
原文:https://www.zhihu.com/question/51039416/answer/126821822
案例二
作者 | SimonS
我曾经也只是一个只懂 ACM 竞赛相关算法的普通程序员,误打误撞接触到了数据挖掘,之后才开始系统地了解机器学习相关的知识,如今已经基本走上了正轨,开始了走向 Data Scientist 的征途。
首先作为一个普通程序员,C++ / Java / Python 这样的语言技能栈应该是必不可少的,其中 Python 需要重点关注爬虫、数值计算、数据可视化方面的应用,主要是:


可以参考:怎么用最短时间高效而踏实地学习 Python?-https://www.zhihu.com/question/28530832/answer/41170900
如果日常只编写增删改查的代码的话,那可能数学已经忘得差不多了,需要重温线性代数和微积分的基础知识,这会为之后的学习立下汗马功劳。
再然后就是统计学相关基础:我在知乎专栏——BI学习大纲中写过,贴过来仅供参考:https://zhuanlan.zhihu.com/p/22543073
相关性分析(相关系数r、皮尔逊相关系数、余弦相似度、互信息)
回归分析(线性回归、L1/L2正则、PCA/LDA降维)
聚类分析(K-Means)
分布(正态分布、t分布、密度函数)
指标(协方差、ROC曲线、AUC、变异系数、F1-Score)
显著性检验(t检验、z检验、卡方检验)
A/B测试
推荐阅读:李航 —《统计学习方法》
如果以上知识都具备了,再往后的路就可以开得很快了,可以一直冲刺到 Deep Learning。但在这之前我们还是需要了解不少机器学习的基础:
关联规则(Apriori、FP-Growth)
回归(Linear Regression、Logistics Regression)
决策树(ID3、C4.5、CART、GBDT、RandomForest)
SVM(各种核函数)
推荐(User-CF、Item-CF)
推荐阅读:《集体智慧编程》、Andrew Ng — Machine Learning Coursera from Stanford
此时的你或许已经有一块可以用的敲门砖了,但离工业界实际应用还有比较大的距离,主要差距就在于 Feature Engineering,这也是我在面试考察有经验的人面前比较注重的点。这一块中有一些比较基础的知识点,简单罗列如下:
可用性评估:获取难度、覆盖率、准确率
特征清洗:清洗异常样本
采样:数据不均衡、样本权重
单个特征:无量纲化(标准化、归一化)、二值化、离散化、缺失值(均值)、哑编码(一个定性特征扩展为N个定量特征)
数据变换:log、指数、Box-Cox
降维:主成分分析PCA、线性判别分析LDA、SVD分解
特征选择:Filter(相关系数、卡方检验)、Wrapper(AUC、设计评价函数A*、Embedded(L1-Lasso、L2-Ridge、决策树、DL)
衍生变量:组合特征
特征监控:监控重要特征,fa特征质量下降
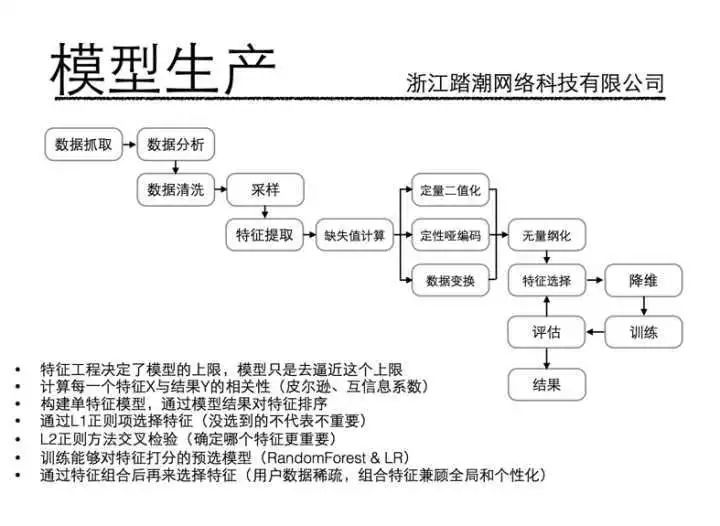
我放一张公司内部算法培训关于特征工程的 PPT,仅供学习参考:
再往后你就可以在技能树上点几个酷炫的了:
提升
Adaboost
加法模型
xgboost
SVM
软间隔
损失函数
核函数
SMO算法
libSVM
聚类
K-Means
并查集
K-Medoids
聚谱类SC
EM算法
Jensen不等式
混合高斯分布
pLSA
主题模型
共轭先验分布
贝叶斯
停止词和高频词
TF-IDF
词向量
word2vec
n-gram
HMM
前向/后向算法
Baum-Welch
Viterbi
中文分词
数据计算平台
Spark
Caffe
Tensorflow
推荐阅读:周志华——《机器学习》
可以看到,不管你是用 TensorFlow 还是用 Caffe 还是用 MXNET 等等一系列平台来做高大上的 Deep Learning,在我看来都是次要的。想要在这个行业长久地活下去,内功的修炼要比外功重要得多,不然会活得很累,也很难获得一个优秀的晋升空间。
最后,关注你所在行业的最新 paper,对最近的算法理论体系发展有一个大致印象,譬如计算广告领域的几大经典问题:
相关 paper 的 gitlist 仅供参考:wnzhang/rtb-papers - https://github.com/wnzhang/rtb-papers
最最后,也要时刻关注能帮你偷懒的工具,它将让你拥有更多的时间去调参: Python 网页爬虫 & 文本处理 & 科学计算 & 机器学习 & 数据挖掘兵器谱 - Python - 伯乐在线 - http://python.jobbole.com/81153/
原文链接:https://www.zhihu.com/question/51039416/answer/126821822
案例三
作者 | hahakity
说说我学习深度学习的经历吧,从开始学习到现在大概有4个月,刚好可以回答新手问题。
先说编程:自认会用C++, 熟悉Python
英语水平:中等,能很快读懂英文科学文献
最开始对人工智能/深度学习感兴趣是因为想用它试一试自然语言生成,后来想到一个物理方面的题目,预计可以用深度学习技术解决,开始接触深度神经网络。记录一下学习历程,
1. 安装 Tensorflow(google 开源的深度学习程序), 尝试里面最简单的例子MNIST 获得激励。
2. 之后尝试通过读书(看视频)理解最简单的全连接神经网络
先搜索找到答案:为什么要Go Deep?
(1) 神经网络中输入层,隐藏层,输出层之间矩阵乘积的维度变化。
(2) Weight, Bias 这些是什么,改变它们有什么结果。
(3) 激励函数是什么,有什么作用,有哪些常用的激励函数
(4)误差如何向后传递,网络如何通过最小化误差函数更新,有哪些常用的优化方法
以上这些在一本交互式电子书中可以找到答案:
Neural networks and deep learning
https://link.zhihu.com/?target=http%3A//neuralnetworksanddeeplearning.com/index.html
(5) 如何对权重正规化,L1, L2, BatchNormalization, (这些在以后真正应用的时候再看)
Deep Learning chapter 7 for L1, L2 regulation.
http://www.deeplearningbook.org
Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift (2015) original paper for BN
https://arxiv.org/abs/1502.03167
why does batch normalization help? Quora
https://www.quora.com/Why-does-batch-normalization-help
Note for BN in Chinese
http://blog.csdn.net/happynear/article/details/44238541
Implementing Batch Normalization in Tensorflow from R2RT
https://r2rt.com/implementing-batch-normalization-in-tensorflow.html
Layer normalization (2016) Replace Batch Normalization in RNN
https://arxiv.org/pdf/1607.06450v1.pdf
Why Does Unsupervised Pre-training Help Deep Learning?
http://www.jmlr.org/papers/volume11/erhan10a/erhan10a.pdf
Summary and discussion on pre training
http://www.stat.cmu.edu/~ryantibs/journalclub/deep.pdf
3. 选择一种比较比较底层的神经网络开源库,tensorflow 或 theano
(1) 读官方文档 https://www.tensorflow.org/versions/r0.11/tutorials/index.html
https://www.tensorflow.org/tutorials/
(2) 看周莫凡的网络教程 https://www.youtube.com/user/MorvanZhou
https://www.youtube.com/user/MorvanZhou
(3) 重复敲代码,重复实现例子程序
4. 开始理解各种不同神经网络架构所能处理的问题
CNN 图像识别,图像处理,语音处理
RNN,LSTM 自然语言理解与生成
增强学习,玩游戏
5. 尝试各种开源的有意思的神经网络项目,新手可以从下面这个列表开始
Andrej Karpathy blog char-rnn, Deep Reinforcement Learning: Pong from Pixels- http://karpathy.github.io
Neural Style In tensorflow - https://github.com/anishathalye/neural-style
6. 如果能翻墙,注册 twitter, facebook 账号,follow 那些文章中经常出现的大牛的名字。他们每天提供很多新动向及最新技术,很多时候有很 Fancy的应用。试试从这个大牛follow的人开始follow - https://twitter.com/karpathy
当你对这些都很熟悉的时候,开始阅读艰深的文献:
1. CNN 的原始文献
2. RNN 和 LSTM 的原始文献
3. Reinforcement Learning 的原始文献
4. Google DeepMind 发表在 Nature 上的几篇经典
最后推荐一个高级点的库: Keras Documentation - https://keras.io
虽然这个库还在发展阶段,里面仍有不少bug,但前途不可限量,可以很容易实现你之前读文章时候见到的那些复杂的构架。作为例子,这里有个教程:
Deep learning book in ipython-notebook and Keras Many example code in Keras - http://ml4a.github.io/guides/
这些学习历程中遇到的资料都记录在了我的个人note里,希望大家共勉:
http://web-docs.gsi.de/~lpang/ - http://web-docs.gsi.de/~lpang/
最后强调一个最最重要的事情:要有自己的想法,有将这种新技术用到自己项目中的强烈愿望,从开始就要Coding,不断尝试才能不断进步。
(看了很多其他的回答,在这里想补充一段)
说实话,作为一个其他行业(物理,工程,化学,医学,农业,卫星地图识别,网络安全领域,社会科学)的普通程序员,在本行业有比较深的理论和实验背景,能接触到海量数据(无论是传感器数据,互联网数据还是蒙特卡洛模拟数据),想做处一些创新性,交叉性的工作,这一轮人工智能的风绝对是要跟的。
作为一个计算机专业的人,可能觉得机器学习,人工智能,深度学习已经炒的过热了。但是对于其他领域,可能大部分人还没有想到把最基本的机器学习算法如:PCA,SVM,k-means...运用到本行业积累的大数据上, 更不要说最近的深度学习。
作为其他行业的普通程序员(除了数学与理论物理),我们不要指望从理论上彻底解决深度学习现存的问题。我们的优势不在这里,我们的优势是计算机专业的人所没有的专业知识,行业大数据。我们需要做的是把机器学习,深度神经网络当作工具,知道它们能做什么,如何去做。参考Andrew Ng 的机器学习笔记:Machine Learning - complete course notes - http://www.holehouse.org/mlclass/
举几个简单的例子:
1. 使用深度学习中生成风格化图片的技术,制备具有特定功能的抗癌药物
The cornucopia of meaningful leads: Applying deep adversarial autoencoders for new molecule development in oncology - http://www.oncotarget.com/index.php?journal=oncotarget&page=article&op=view&path%5B%5D=14073&path%5B%5D=44886
2. 使用反常探测,寻找网络攻击 Cyber-attacks prediction
3. 对于国家来说,更加聪明的互联网关键词过滤
4. 自动探测卫星地图上道路,建筑,车辆,河流。
5. 环境科学中寻找雾霾与众多可能因素的非线性关联
安利我们最近放到预印文本库的文章,
我们用卷积神经网络来区分量子色动力学相变是crossover还是一阶相变。
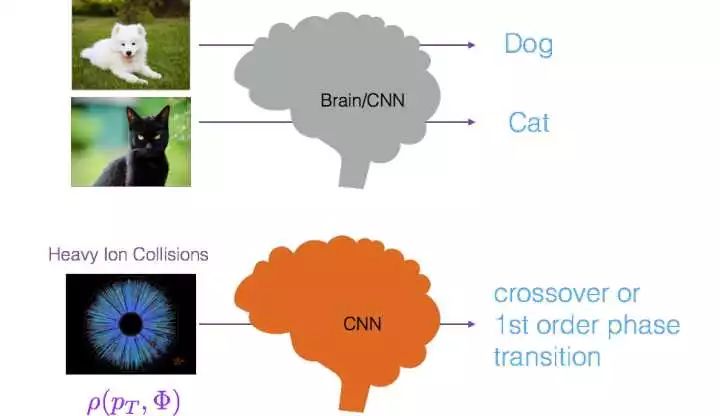
paper: https://arxiv.org/pdf/1612.04262.pdf
talk: http://starmeetings.physics.ucla.edu/sites/default/files/pang.pdf
原文:https://www.zhihu.com/question/51039416/answer/126717678

限时干货下载
Step 1:长按下方二维码,添加微信公众号“数据玩家「fbigdata」”
Step 2:回复【2】免费获取完整数据分析资料「包括SPSS\SAS\SQL\EXCEL\Project!」