在定制硬件上实现DNN近似算法,一文概述其过去、现在与未来
选自arXiv
作者:ERWEI WANG等
机器之心编译
参与:杜伟、淑婷
近似算法可以减少内存使用和计算复杂度,使 DNN 部署变得更加容易。近日,由英国皇家工程科学院 Research Chair、帝国理工大学电路与系统研究所主任 George A. Constantinides 领导的一个团队发布了一篇题为《Deep Neural Network Approximation for Custom Hardware: Where We've Been, Where We're Going》的综述论文。本文评估了几大 DNN 近似算法,包括量化、权重减少,以及由此衍生出的输入计算减少和近似激活函数,并展示了定制硬件在实现 DNN 近似算法过程中的优势。
引言
来自社交媒体和物联网等多个渠道的可用数字数据(如图像、视频和语音)呈指数级增长,这驱动了对高性能数据分析的需求。与其它机器学习算法相比,深度神经网络(DNN)在过去十年里实现了巨大的准确率提升。它的应用领域很广,如图像分类、目标检测、自动驾驶和无人机导航等。其中卷积神经网络和循环神经网络这两种深度神经网络尤其受欢迎。CNN 在学习空间特征方面很强,而 RNN 则更适合涉及时间序列的问题。
随着任务的复杂度加深,推理架构变得越来越深,所耗费的计算量也越来越大。例如,针对简单 MNIST 手写数字分类任务的小型 LeNet-5 模型需要 680 kop/cl(每次分类需上千次算术运算,其中算术运算是加法或乘法),而执行 1000 类 ImageNet 任务的 VGG16 实现需要 31 Gop/cl 以及 32 位浮点权重存储的 550 MiB。因此,对于注重吞吐量、延迟和能量的应用来说,开发能够减少 DNN 推理所需计算量和存储成本的算法至关重要。最近的研究表明,使用近似算法后,由于减少了内存使用和计算复杂度,DNN 部署变得更容易了。
深度神经网络近似算法可分为两大类:量化和权重减少(weight reduction)。量化方法分别降低权重、激活(神经元输出)的精度或同时降低二者的精度,而权重减少则通过剪枝和结构简化来删除冗余参数。如此以来,后者通常也会减少每个网络中的激活数量。这两种方法都有助于 DNN 加速,因而该论文对它们进行了评估。
多年来,通用处理器(GPP),尤其是多核 CPU 和 GPU,一直是 DNN 推理的主要硬件平台。对于未压缩 DNN 模型,层操作被映射到密集浮点矩阵乘法(dense floating-point matrix multiplication),其可以由 GPP 按照单指令流多数据流(SIMD)或者单指令多线程(SIMT)并行处理范式进行并行处理。但是,随着 DNN 近似算法的出现,利用现场可编程门阵列(FPGA)和特殊应用积体电路(ASIC)等定制硬件平台来加速推理的趋势正在兴起。尽管 GPU 依然擅长密集浮点计算,但研究者发现使用低精度定点量化可为定制硬件带来更高吞吐量和能量效率。此外,SIMD 和 SIMT 架构在稀疏数据上操作时通常表现不佳;通过细粒度权重减少压缩后的 DNN 在定制硬件上的执行效率更高。与使用 GPP 相比,逻辑和内存层次结构的可定制性通常使得定制硬件 DNN 推理更快也更高效。
很多全球领先的信息技术公司选择定制硬件而不是 GPP,来实现其下一代 DNN 架构。这些定制硬件包括 ASIC(如谷歌的 TPU,英伟达的 Nervana 和 IBM 的 TrueNorth)和基于 FPGA 的设计(如微软的 Brainwave 和赛灵思的 Everest)。一般来说,ASIC 设计架构可以达到当前最佳的吞吐量和能效。然而,它耗时较长、设计和制造过程需要耗费大量资源,这导致它很难跟上 DNN 算法的快速发展。
高级实现工具(包括英特尔的 OpenCL 软件开发工具包、赛灵思的 Vivado 高级综合)和 Python-to-netlist 神经网络框架(如 DNNWeaver)使得面向 FPGA 和 ASIC 的 DNN 硬件设计过程变得更快、更简单。这类软件允许不熟悉硬件开发的 DNN 架构师可以相对容易地将其设计迁移到定制硬件上。同时,可重构性支持快速的设计迭代,使 FPGA 成为顶尖 DNN 的理想原型制作和部署设备。
在这篇综述论文中,作者旨在为刚进入该领域的研究人员提供关于 DNN 近似算法的全面基础,展示定制硬件如何比 GPP 实现更好的推理性能。具体来讲,本文的贡献如下:
作者通过比较不同规模 FPGA、ASIC、CPU 和 GPU 平台的 roofline 模型,来说明定制硬件更适合 DNN 近似算法。
作者综述了当前最佳 DNN 近似的主要趋势,详细讨论了低精度量化和权重减少方法,介绍了最近的算法发展并评估了它们的优缺点。
作者评估了每种方法定制硬件实现的性能,重点关注准确率、压缩、吞吐量、延迟和能效。
基于本文确定的趋势,作者提出了一些有前景的未来研究方向。
目前已有一些关于 DNN 近似的综述。Cheng 等人 [25]、Guo 等人 [49]、Cheng 等人 [24]、Sze 等人 [136] 综述了 DNN 压缩和加速算法。在这些综述中,Cheng 等人 [24] 简要评估了 FPGA 实现的系统级设计。Guo 等人仅综述了量化方法,没有提到权重减少。Nurvitadhi 等人将英特尔的 FPGA 与用于 CNN 推理基准的 GPU 平台的性能进行了比较。本文不仅综合评估了 DNN 高效推理的近似算法,还深入分析和对比了这些算法在定制硬件中的实现,包括 CNN 和 RNN。
量化
作者认为,DNN 近似算法的第一个关键主题是量化。FPGA 和 ASIC 的灵活性允许低精度 DNN 的实现,从而通过并行化和减少对慢速片外存储的依赖来增加吞吐量。
这部分主要介绍了三种量化方法:
定点表征
二值化和三值化
对数量化
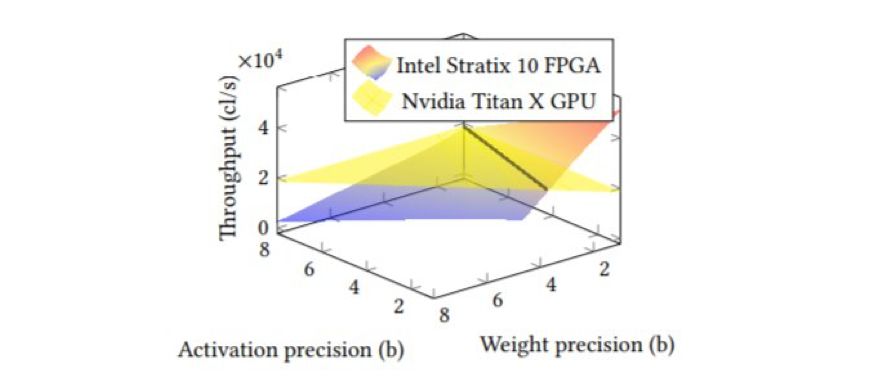
图 2:基于英特尔 Stratix 10 FPGA 和英伟达 Titan X GPU 实现的 AlexNet 模型在使用多种定点权重和激活数据表征时对 ImageNet 数据集执行分类的吞吐量对比。
权重减少
DNN 近似算法的第二个关键主题是权重减少,即被认为不重要的参数会被完全消除。权重减少通过减少工作负载和片外内存流量来提高硬件推理的性能。
这部分主要介绍了权重减少的五种方法:
剪枝
权重共享
低秩分解
结构化矩阵
知识蒸馏
输入计算减少
与权重减少同理,处于不同空间区域的输入数据亦会对推理的结果产生不同程度的贡献,因而可以通过评估输入数据的相对重要性来分配算力。
近似激活函数
对于诸如 sigmoid 和 tanh 的非线性激活函数,许多计算如取幂和除法将会占用大量片上资源。通过使用分段线性函数来近似和量化这些复杂函数,可以使复杂计算简化为一系列的表查找操作。
权衡和当前研究趋势
这部分中,作者使用常规 DNN 模型和数据集作为基准,量化评估了这些工作的硬件和软件性能。通过这样做,作者分析了近似技术的压缩-准确率权衡以及它们对定制硬件的设计空间探索,并据此说明了当前的研究趋势。
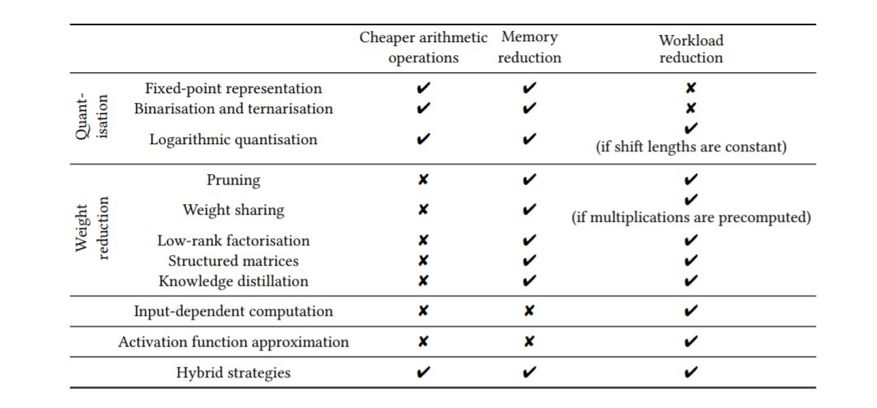
表 1:每个近似算法对在定制硬件中加速 DNN 推理的作用。
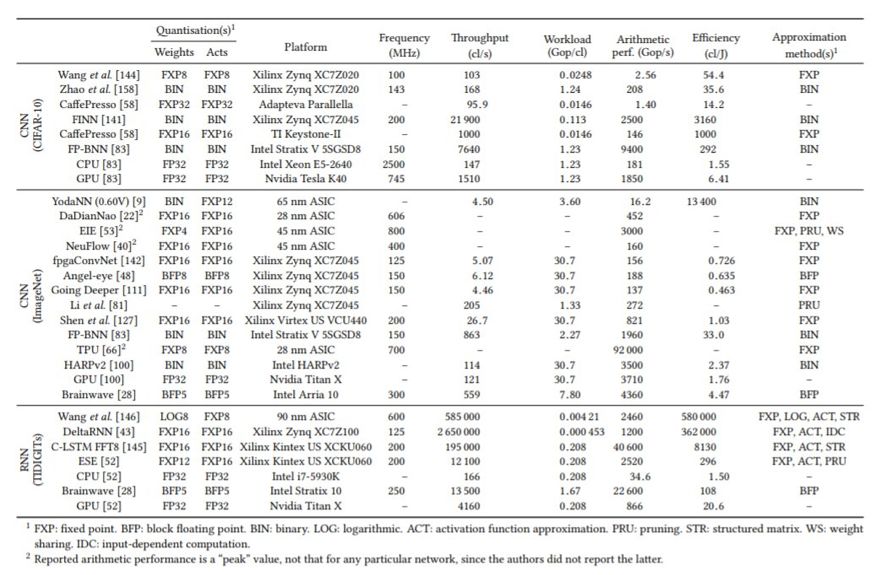
表 2:大规模 DNN 推理的性能对比。以上实现根据功耗排序,功耗最低者排序最高。
未来研究方向
上文已经评估了 DNN 近似算法领域的当前研究趋势及其实现,接下来作者将介绍该领域一些有前景的未来研究方向。
1. 评估方法
2. 研究目的
收敛保证和最优设计选择
自适应超参数微调
FPGA-ASIC 异构系统
不规则数据模式的硬件推理
参数硬化
论文:Deep Neural Network Approximation for Custom Hardware: Where We've Been, Where We』re Going

论文地址:https://arxiv.org/pdf/1901.06955.pdf
摘要:深度神经网络已证明在视觉和音频识别任务中特别有效。但是,现有模型往往计算成本高昂且对内存的需求较高,所以面向硬件的近似算法成为热门话题。研究显示,基于定制硬件的神经网络加速器在吞吐量和能量效率两个方面均超过通用处理器。当使用基于近似的网络训练方法协同设计时,针对特定应用的加速器将大型、密集和计算成本高昂的网络转换为小型、稀疏和硬件资源消耗少的网络,增强网络部署的可行性。在本论文中,作者对高性能网络推理的近似法提供了全面评估,并就其定制硬件实现的有效性进行了深入探讨。作者还深入分析了当前趋势,为未来研究提供建议。本论文首次深入分析和对比了 CNN 和 RNN 等算法在定制硬件中的实现,希望能够激发该领域出现令人兴奋的新进展。

本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com




